인덱스란?
데이터를 빨리 찾기 위해 특정 컬럼을 기준으로 정렬해놓은 표
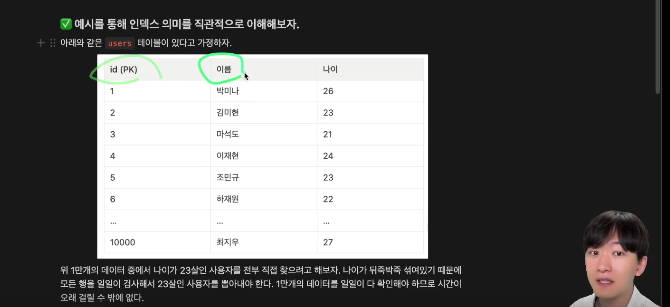
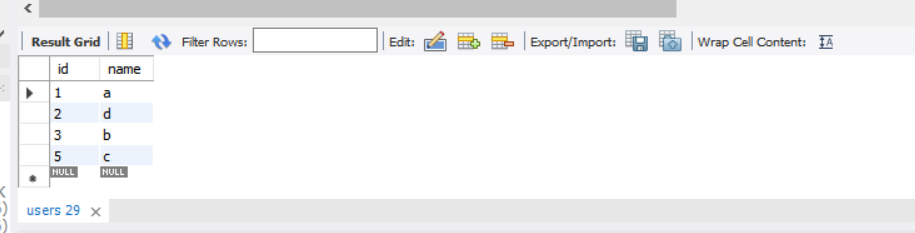
여기서 나이가 23살인 이용자를 모두 찾는다고 해보자. 나이가 뒤죽박죽 섞여 있어서, 모든 행을 일일이 검사해서 나이가 23살인지를 체크한다. 1만개의 데이터를 모두 확인해야 한다.
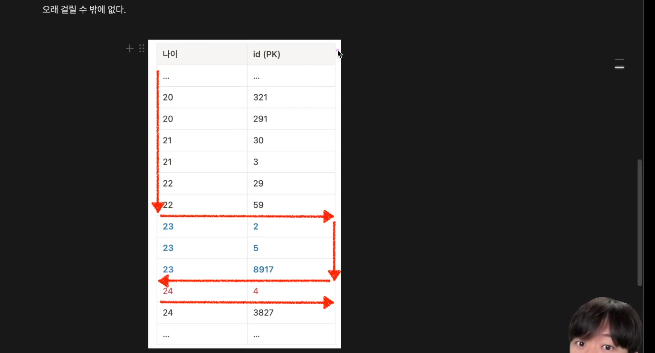
만약에 이런 표가 있다면?
나이순으로 정렬해놓고, 데이터를 가리키는 id값을 포함한다.
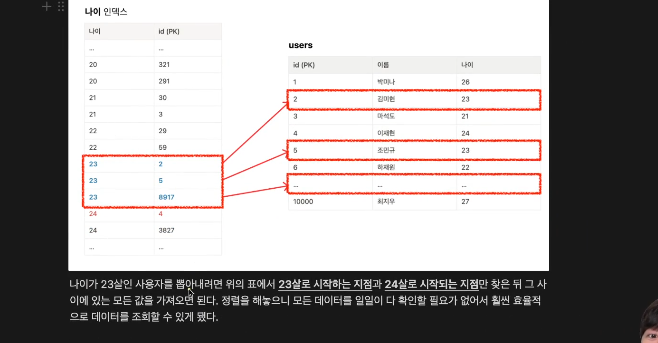
이미 정렬돼 있어서 23로인 지점을 찾고, 그 사이에 있는 모든 값을 다 가져온다.
실습
DROP TABLE IF EXISTS users; # 기존 테이블 삭제
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
age INT
);
-- 높은 재귀(반복) 횟수를 허용하도록 설정
-- (아래에서 생성할 더미 데이터의 개수와 맞춰서 작성하면 된다.)
SET SESSION cte_max_recursion_depth = 1000000;
-- 더미 데이터 삽입 쿼리
INSERT INTO users (name, age)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
CONCAT('User', LPAD(n, 7, '0')), -- 'User' 다음에 7자리 숫자로 구성된 이름 생성
FLOOR(1 + RAND() * 1000) AS age -- 1부터 1000 사이의 랜덤 값으로 나이 생성
FROM cte;
-- 잘 생성됐는 지 확인
SELECT COUNT(*) FROM users;

인덱스를 걸기 전 성능이다.
create index ide_age on users(age);
show index from users;

인덱스를 거니까 걸리는 시간이 줄었다.
기본으로 설정되는 인덱스(PK)
PK는 이걸 기준으로 데이터가 정렬돼서 저장된다.
PK를 변경하면, 이거에 맞춰서 데이터로 다시 정렬된다.
이렇게 원본데이터가 정렬되는 인덱스를 보고 클러스터링 인덱스라고 한다.(pk) pk= 클러스터링 인덱스라고 생각해도 된다. 클러스터링 인덱스에는 pk밖에 없다.
제약조건을 추가하면 자동으로 생성되는 인덱스
UNIQUE 제약조건을 추가하면 자동으로 인덱스가 생성된다.
인덱스를 많이 추가하는 게 좋을까?
인덱스를 추가하면 조회 성능이 생기지만 이에 따른 기회비용이 생긴다.
데이터 쓰기 작업의 성능이 저하된다.
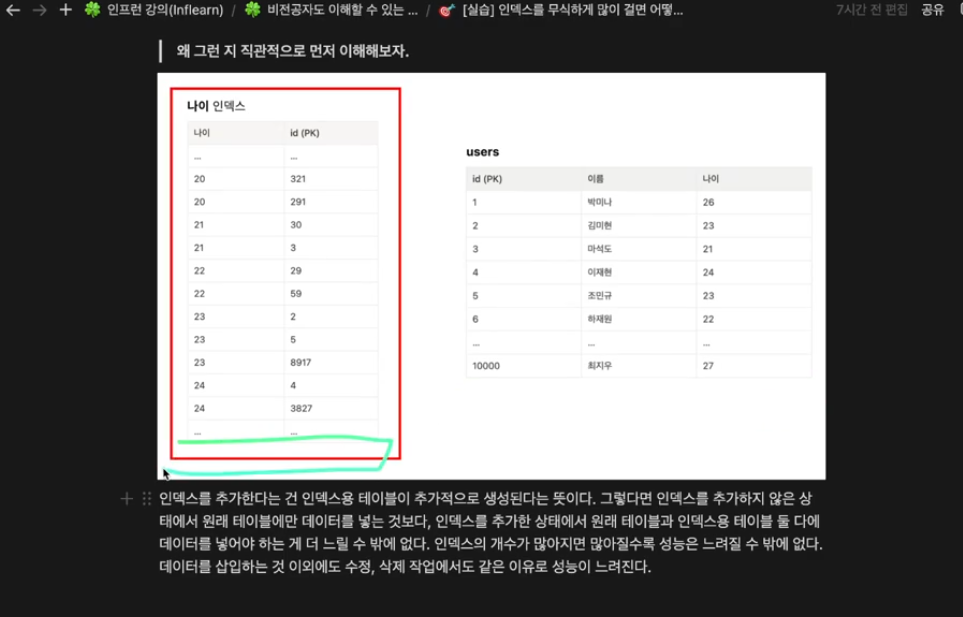
데이털르 추가할 땐 원본 데이터 뿐 아니라, 인덱스 테이블에도 추가를 해줘야 한다.
인덱스 개수가 많아질수록 성능이 느려질수밖에 없다.
-- 테이블 A: 인덱스가 없는 테이블
CREATE TABLE test_table_no_index (
id INT AUTO_INCREMENT PRIMARY KEY,
column1 INT,
column2 INT,
column3 INT,
column4 INT,
column5 INT,
column6 INT,
column7 INT,
column8 INT,
column9 INT,
column10 INT
);
-- 테이블 B: 인덱스가 많은 테이블
CREATE TABLE test_table_many_indexes (
id INT AUTO_INCREMENT PRIMARY KEY,
column1 INT,
column2 INT,
column3 INT,
column4 INT,
column5 INT,
column6 INT,
column7 INT,
column8 INT,
column9 INT,
column10 INT
);
-- 각 컬럼에 인덱스를 추가
CREATE INDEX idx_column1 ON test_table_many_indexes (column1);
CREATE INDEX idx_column2 ON test_table_many_indexes (column2);
CREATE INDEX idx_column3 ON test_table_many_indexes (column3);
CREATE INDEX idx_column4 ON test_table_many_indexes (column4);
CREATE INDEX idx_column5 ON test_table_many_indexes (column5);
CREATE INDEX idx_column6 ON test_table_many_indexes (column6);
CREATE INDEX idx_column7 ON test_table_many_indexes (column7);
CREATE INDEX idx_column8 ON test_table_many_indexes (column8);
CREATE INDEX idx_column9 ON test_table_many_indexes (column9);
CREATE INDEX idx_column10 ON test_table_many_indexes (column10);-- 높은 재귀(반복) 횟수를 허용하도록 설정
-- (아래에서 생성할 더미 데이터의 개수와 맞춰서 작성하면 된다.)
SET SESSION cte_max_recursion_depth = 100000;
-- 인덱스가 없는 테이블에 데이터 10만개 삽입
INSERT INTO test_table_no_index (column1, column2, column3, column4, column5, column6, column7, column8, column9, column10)
WITH RECURSIVE cte AS (
SELECT 1 AS n
UNION ALL
SELECT n + 1 FROM cte WHERE n < 100000
)
SELECT
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000)
FROM cte;
인덱스 없는 테이블에 삽입할 떄 속도
-- 인덱스가 많은 테이블에 데이터 10만개 삽입
INSERT INTO test_table_many_indexes (column1, column2, column3, column4, column5, column6, column7, column8, column9, column10)
WITH RECURSIVE cte AS (
SELECT 1 AS n
UNION ALL
SELECT n + 1 FROM cte WHERE n < 100000
)
SELECT
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000),
FLOOR(RAND() * 1000)
FROM cte;
인덱스가 많은 테이블에 넣을 땐 속도가 확실히 느리다.
멀티 컬럼 인덱스
멀티 컬럼 인덱스란 2개 이상의 컬럼을 묶어서 설정하는 인덱스를 뜻한다. 데이터를 빨리 찾기 위해 2개 이상의 컬럼을 기준으로 정렬해놓은 표다.
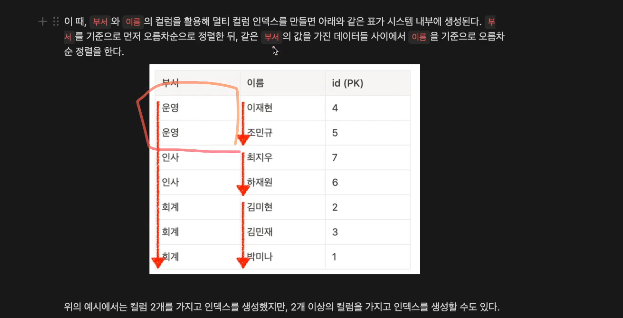
부서가 있다면, 부서를 기준으로 정렬하고 같은 부서에서 이름을 기준으로 정렬할 수 있다.
CREATE INDEX idx_부서_이름 ON users (부서, 이름);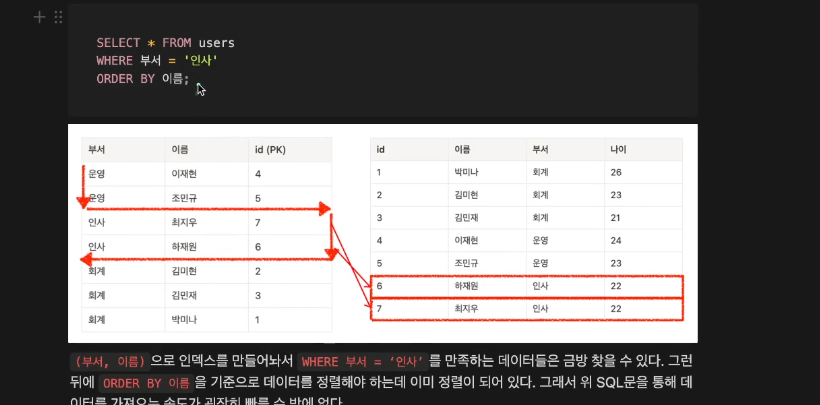
부서별로 정렬이 돼 잇으니까, 인사팀만 빠르게 찾는다.
인사팀 내에서 이름이 정렬돼 있으니까 빠르게 가져올 수 있다.
멀티 컬럼 인덱스 생성 시 주의점
'부서, 이름' 순으로 인덱스를 미리 만들어놨다면
'부서' 인덱스를 별도로 만들지 않고도 부서와 관련된 조회 시 멀티 인덱스를 쓸 수 있다.
멀티 컬럼 인덱스를 일반 인덱스처럼 활용하지 못하는 경우도 있다.
이 멀티 컬럼 인덱스는 '이름' 컬럼의 인덱스처럼 쓸 수는 없다.

이 테이블을 보면 이름을 중심으로 정렬된 것이 아니다.
김씨가 중간에 들어가 이씀. 부서를 중심으로 1차 정렬되고 그 안에서 2차 정렬된 것이라서.
멀티 컬럼 인덱스에서 일반 인덱스처럼 사용할 수 있는 건 처음에 배치된 인덱스뿐이다.
멀티 컬럼 인덱스를 구성할 땐 '대분류'-> '중분류' -> '소분류' 컬럼순으로 구성하는 게 좋다.
10층짜리 회사에서 '박미나'를 찾아야 한다고 해보자.
박미나가 속한 부서를 먼저 찾은 뒤, 그 부서에서 박미나를 찾는 게 편할까
아니면 박미나를 먼저 찾고, 어떤 부서냐고 물어보는 게 편할까?
전자가 훨씬 빠르다. 컴퓨터도 이 특성이 동일하다.
친구의 집을 간다고 해보자. 어떤 역 근처에 살아? 아파트 이름은 뭐야? 몇 동이야? 몇 호야? 이런식으로 하면 빠르게 찾는다.
배치 순서를 (부서, 이름)으로 해야 더 빠르다. 일반적으로, 데이터 중복도가 높은 컬럼이 앞으로 오는 게 좋다. 그만큼 큼지막하게 분류돼있다는 뜼이기 때문이다.
(항상 그런 건 아니니 성능을 측정하고 판단해야 한다)
커버링 인덱스란
SQL을 실행시킬 때 필요한 모든 컬럼을 갖고 있는 인덱스를 커버링 인덱스라고 한다.
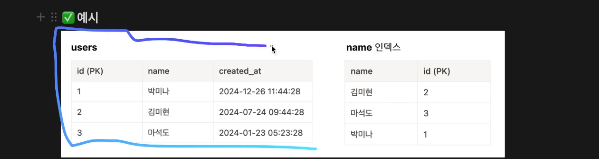
SELECT id, created_at FROM users; //실제 테이블에 접근해야 한다.
SELECT id, name FROM users;두번째 쿼리는 인덱스 테이블만 조회해도 정보를 가져올 수 있음
실제 테이블에 접근 X 그게 더 빠르기 때문이다.
