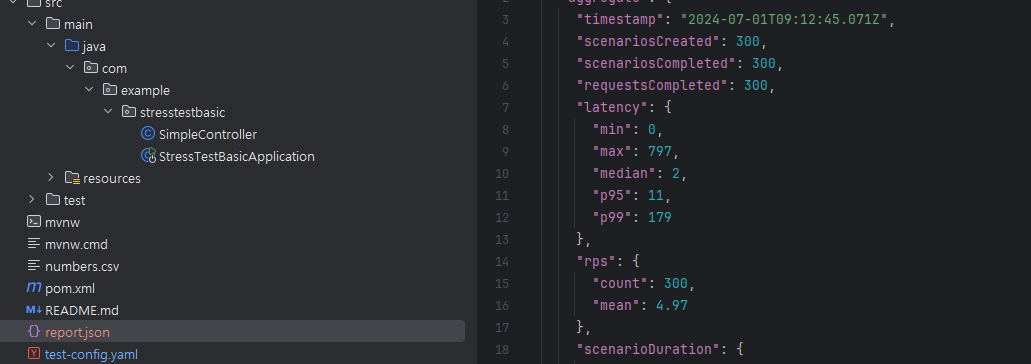
성능 개선
1.2.Artillery 사용
https://www.artillery.io/docs/get-started/get-artillery여기서 사용법을 확인하면 된다.우선, Artillery는 Node.js로 만들어졌기 때문에 노드를 설치해야 한다.강사님께서는 최신버전보다는npm install -
2.3.캐시 적용해 성능 개선하기
numbers라는 csv파일과이 테스트 시나리오를 이용해본다.캐시를 사용하지 않을 때는 위처럼 지연시간이 크게 치솟는 경우가 많았다.내 노트북 성능의 문제가 크겠지만, 이 작업을 하는데만 450초가 걸렸다.캐시를 사용하니 작업이 90초만에 끝났다.지연시간은 처음에만
3.4.ArrayList vs HashMap 검색 시간 확인
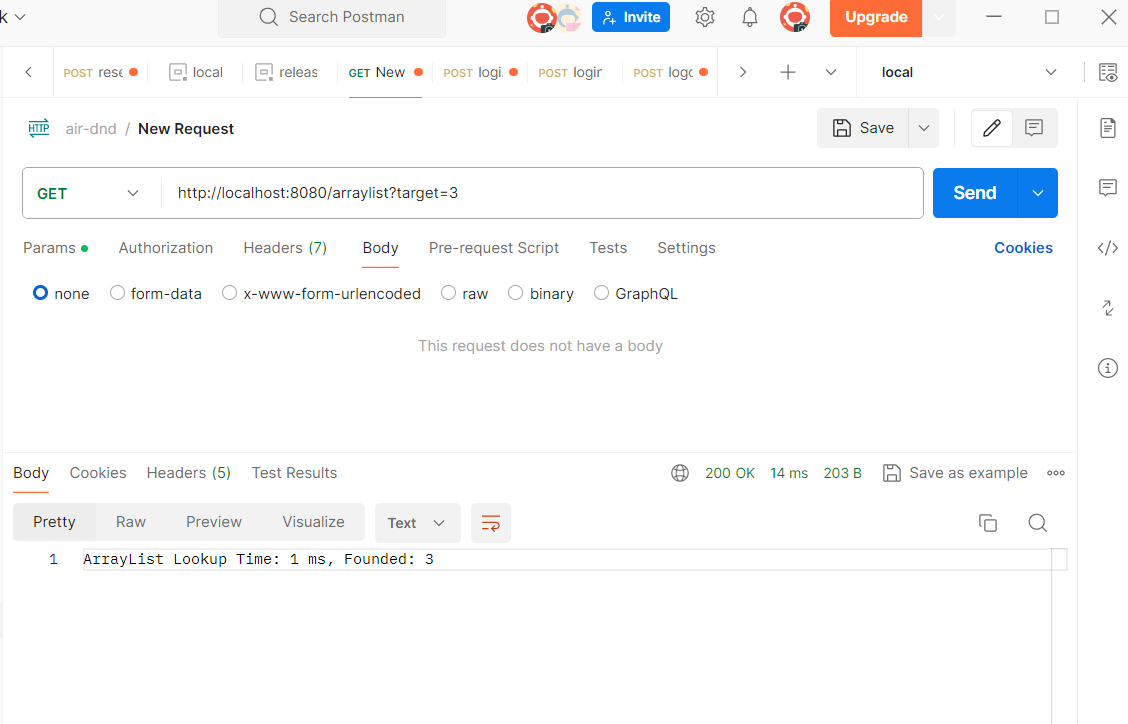
Arraylist는 모든 리스트를 돌면서 내가 찾으려는 것인지 확인하고Hashmap은 버킷을 만들고 그 버킷 내에 내가 찾으려는 값이 있는지 확인한다.파라미터의 값을 낮게하면 지연시간이 크지 않다.100만을 넣으니 지연시간이 크게 올라갔다.이제 해시맵을 확인해보자9백만
4.1.성능 테스트

인프런의 '백엔드 애플리케이션 성능 테스트하기'를 보면서 내용을 정리한다. 성능 테스트는 어떤 상황에서 왜 하는가? 일반 사용자에게 서비스를 오픈했을 때 서비스가 대박이 났다면? 트래픽이 폭주할 것이다. 이에 서버의 부하가 증가할 것이다. 이 트래픽을 감당하려면
5.5.성능 개선하기 - 조회 테스트
1)maven을 눌러서 clean-->pakage를 선택하고 jar파일을 만든다. (테스트를 안하고 하려면 toggle skip test mode를 누른다) 2)jar 파일이 있는 곳에서 shift +우클릭 한 뒤 powershell로 열기를 한다. 3) scp
6.7.프로젝트 성능 개선해보기
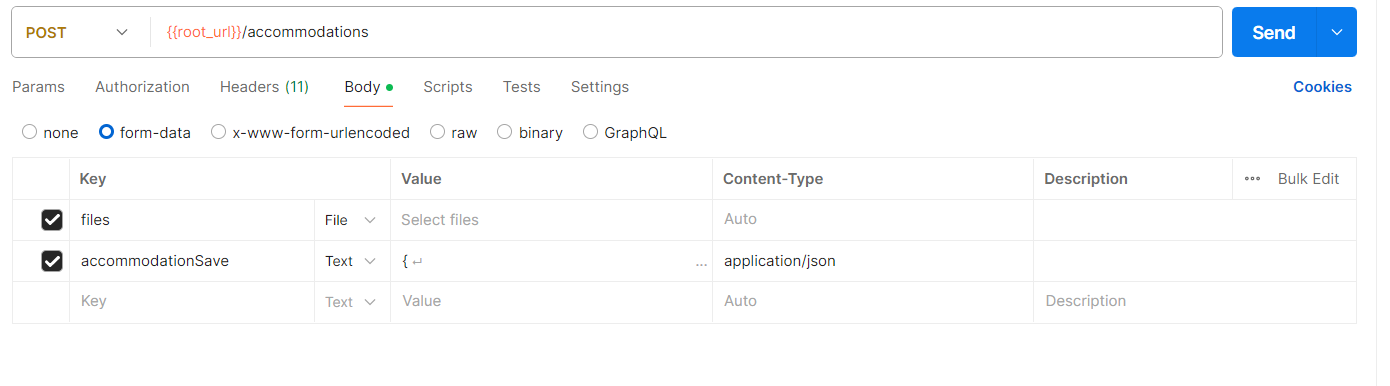
우선 파워셀에 를 입력해서 파이썬 더미데이터 생성에 필요한 라이브러리를 설치한다.gpt의 힘을 빌려서 python C:/Users/정연호/Desktop/테스트/ddd.py20만건의 데이터를 랜덤으로 생성하는 스크립트를 짰다.이 데이터는 csv 파일로 만들어진다.포스트맨
7.신입 백엔드 개발자에게 요구하는 DB 성능 개선이란?
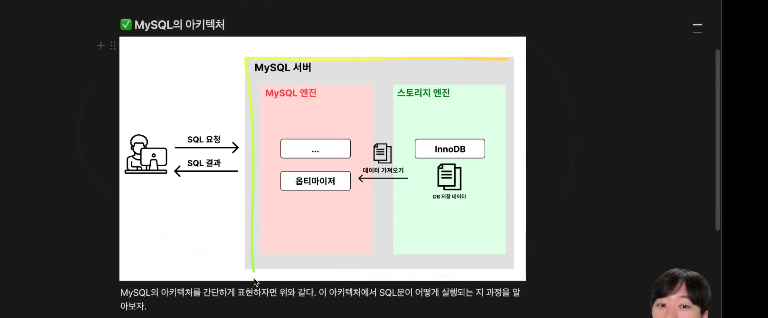
개인 프로젝트에서 DB 성능이 문제가 되는 일은 그렇게 많지 않다.다만, 현업에서는 이런 이슈가 있다고 한다.세가지 원인이 있는데1.동시 사용자 수의 증가2.데이터양이 증가3.비효율적인 SQL문을 작성했기 때문\-->데이터가 늦게 로딩, 서비스 사용자 입장에서는 답답.
8.인덱스란?
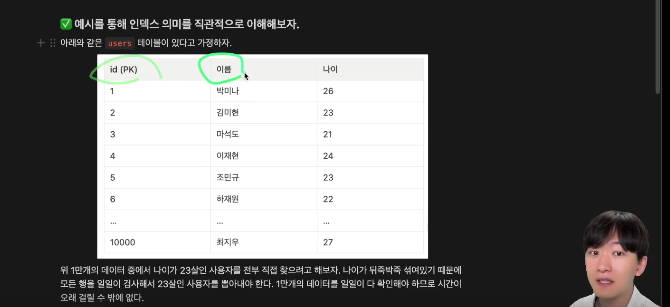
인덱스란?데이터를 빨리 찾기 위해 특정 컬럼을 기준으로 정렬해놓은 표여기서 나이가 23살인 이용자를 모두 찾는다고 해보자. 나이가 뒤죽박죽 섞여 있어서, 모든 행을 일일이 검사해서 나이가 23살인지를 체크한다. 1만개의 데이터를 모두 확인해야 한다.만약에 이런 표가 있
9.Artillery 시나리오
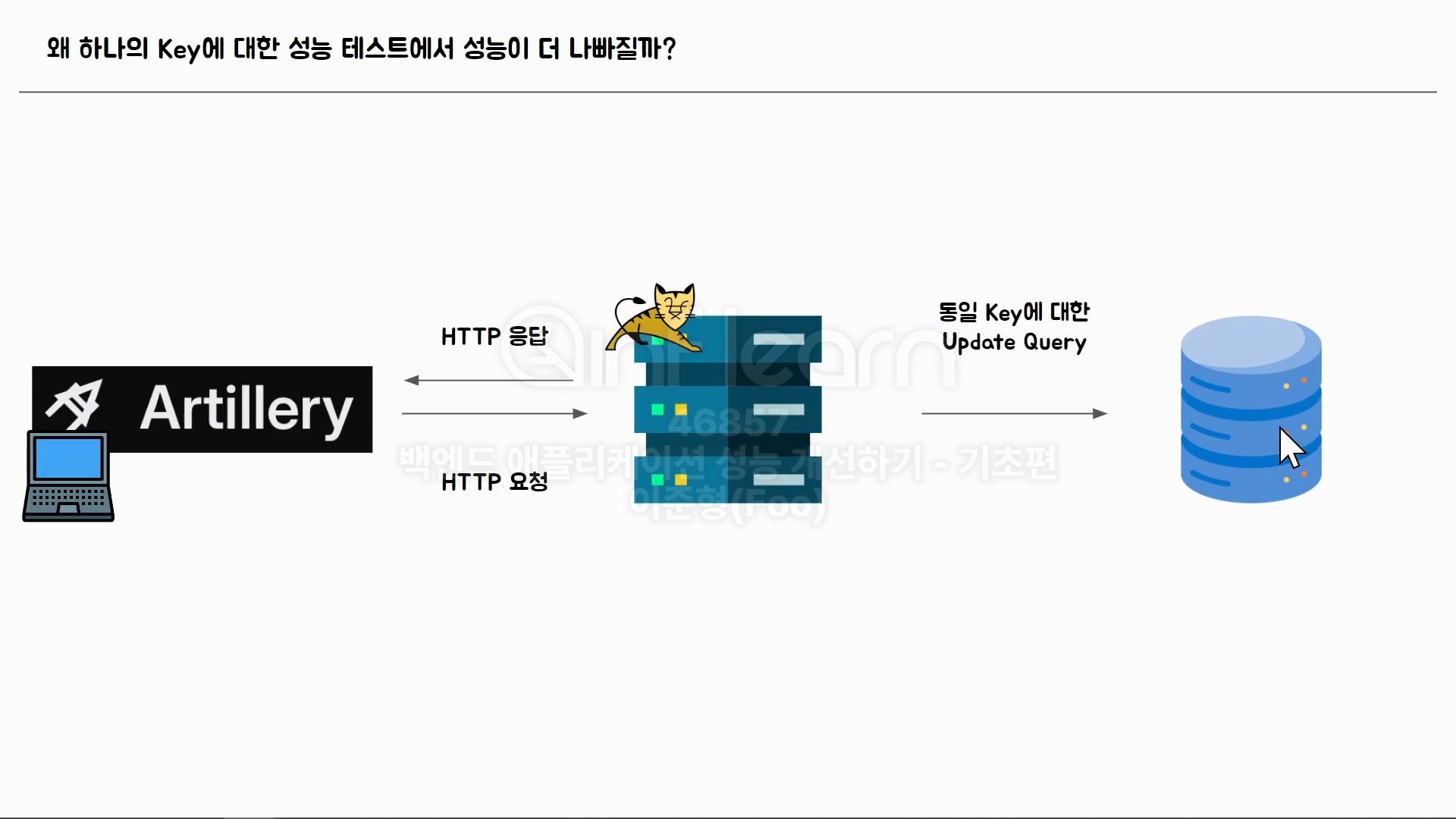
테스트를 초당 20번, 40번, 60번, 70번씩 API를 호출하도록 했는데 서버에서 OOM이 발생하지는 않았다.60초간 5000~6000번의 API 요청을 보내도 OOM이 뜨지 않았다. 우리 서버에서는 이 정도 규모의 API 호출이 발생하지 않는다. 그렇다면, 이게