RateLimiter는 단위 시간동안 얼마만큼의 실행을 허용할 것인지 제한할 수 있는 메커니즘을 말한다.
채팅의 경우 메시지를 한번에 여러번 보낼 수 있다.
이 경우 너무 많은 메시지를 보내면 스프리 서버, DB부하가 커질 수밖에 없다.
지난번 CircuitBreaker 구현에 사용한 Rejillence4에서 이 기능을 제공한다.
그래서 한번 설정을 확인해보니
서버 전체에 들어오는 API 횟수를 막는 방식이지
이용자별로 API 호출량을 제한하는 방식은 아니었다.
이용자별로 rateLimiter 인스턴스를 만들면 되지만...굳이? 싶긴하다
설계를 어떻게 해야할까?
지금 레디스를 캐시서버로 쓰고 있으니 이거 활용하기로 했다.
1)레디스에서 초당 3번 이상의 메시지가 왔는지 체크한다.
2)레디스에 문제가 생기면, rateLimiter를 통해서 전체 서버에 들어오는 트래픽을 조절한다.
근데, 이렇게 하려니 고민이 되는 지점이 있다.
메시지 한 개마다 레디스에 요청이 가는 게 괜찮을까?.
그러다가 어차피 레디스에 메시지를 버퍼링할 계획이 있으니
괜찮을 거 같다는 생각이 들었다.
지금은 채팅 메시지 건건으로 DB에 저장을 하고 있어서 부하가 생길 수 밖에 없다. 레디스에 버퍼링 해두고 나중에 저장을 할 계획이다.
다만, 이렇게 하면 레디스에 장애가 생겼을 때 메시지가 유실될 수 있다는 문제가 있다.... 이걸 어떻게 해결해야 할까...흠..
그래서 레디스를 사용하지 않기로 했다.
그냥 in-momery 구조로 rate limiter를 만들어서 쓰기로 했다.
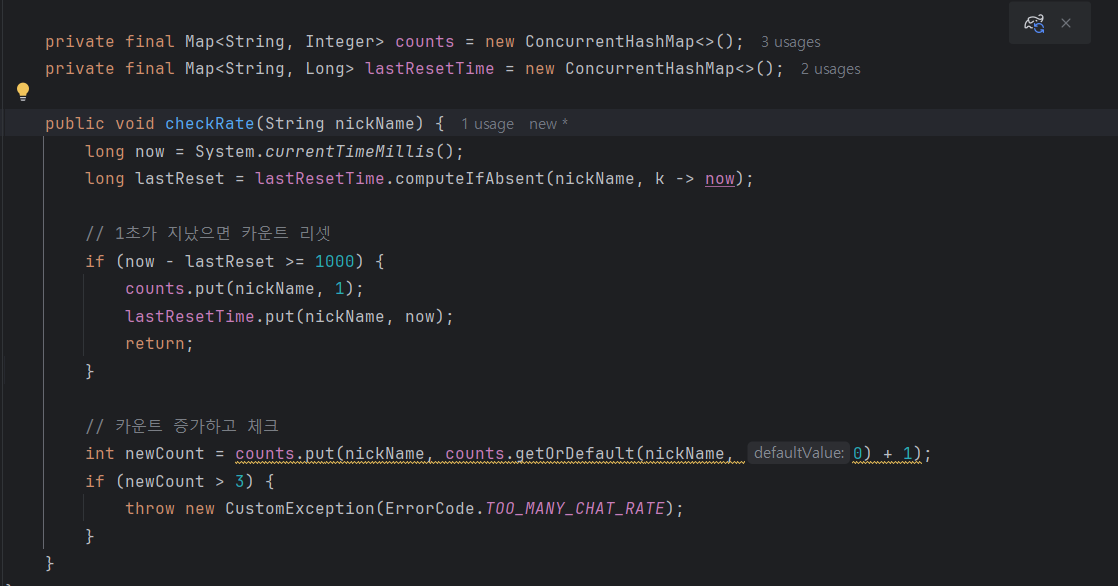
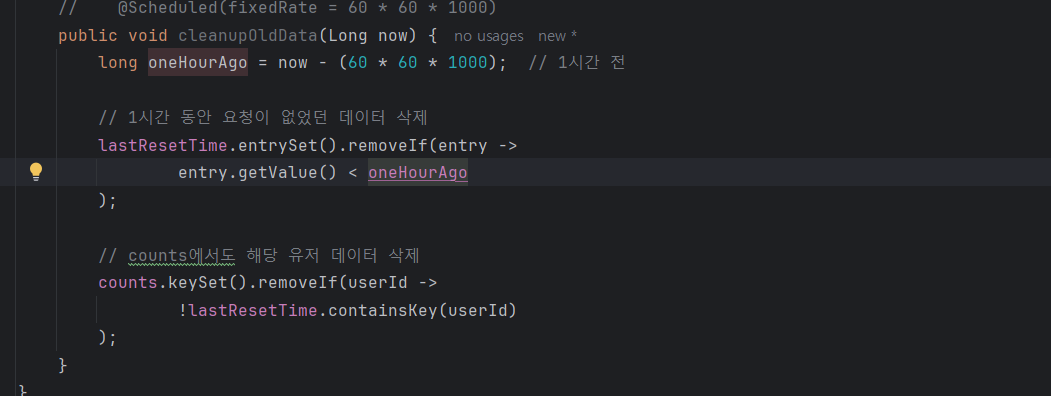
데이터들은 1시간마다 지워준다
테스트는 다음과 같이 진행헀다.
@Test
void test() throws ExecutionException, InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(5);
List<Future<?>> futures = new ArrayList<>();
AtomicInteger exceptionCount = new AtomicInteger(0);
for (int i = 0; i < 10; i++) {
futures.add(executor.submit(() -> {
try {
chatRateLimiter.checkRate("testUser");
} catch (CustomException e) {
exceptionCount.incrementAndGet();
}
}));
}
// 모든 태스크 완료 대기
for (Future<?> future : futures) {
future.get();
}
executor.shutdown();
assertEquals(7, exceptionCount.get());
}map의 put과 merge?
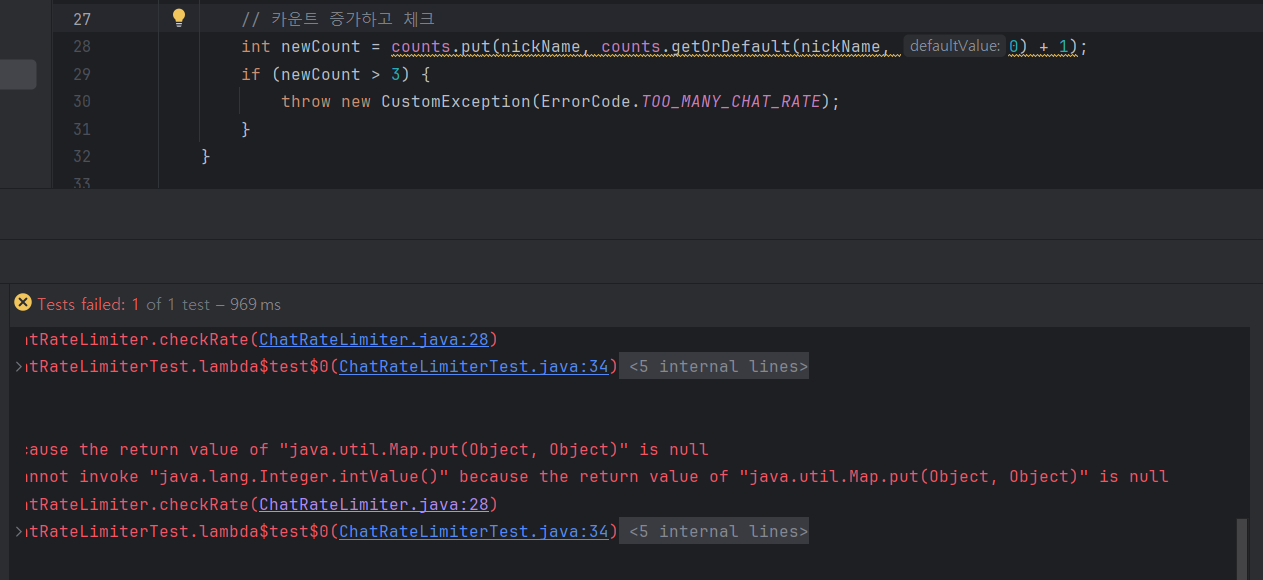
이 부분에서 null이 발생했다.
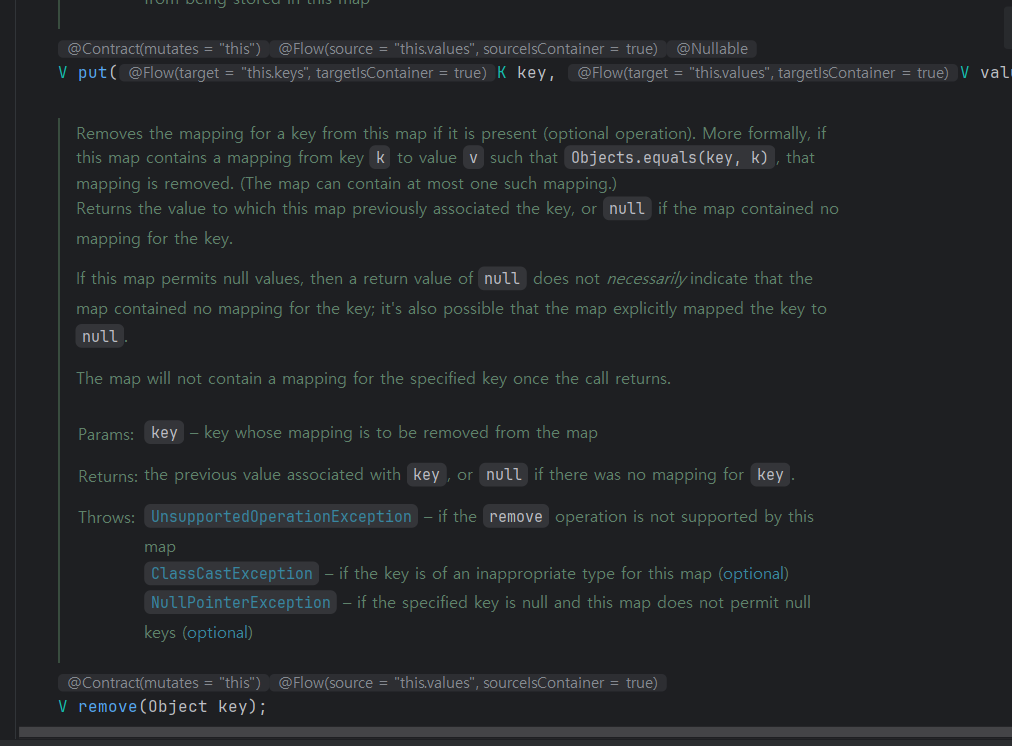
코드를 보니 이전값을 return하기 때문이었다.
그니까 key를 처음 넣을 때 값을 return하는데, 이때는 null이라서 예외가 발생한 것.
이때는 map의 merge를 쓸 수 있는 것으로 보인다.
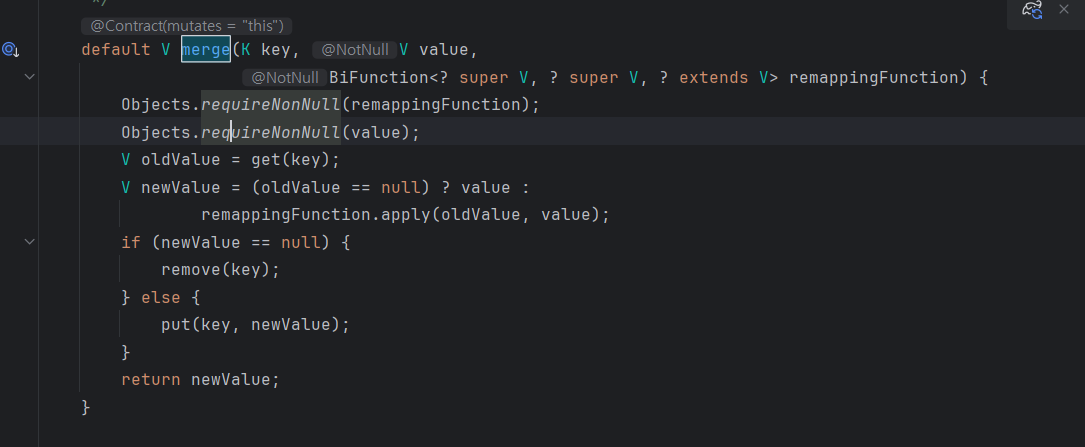
이 메서드를 쓰면
key가 map에 있는지 확인하는 과정을 안 해도 된다.
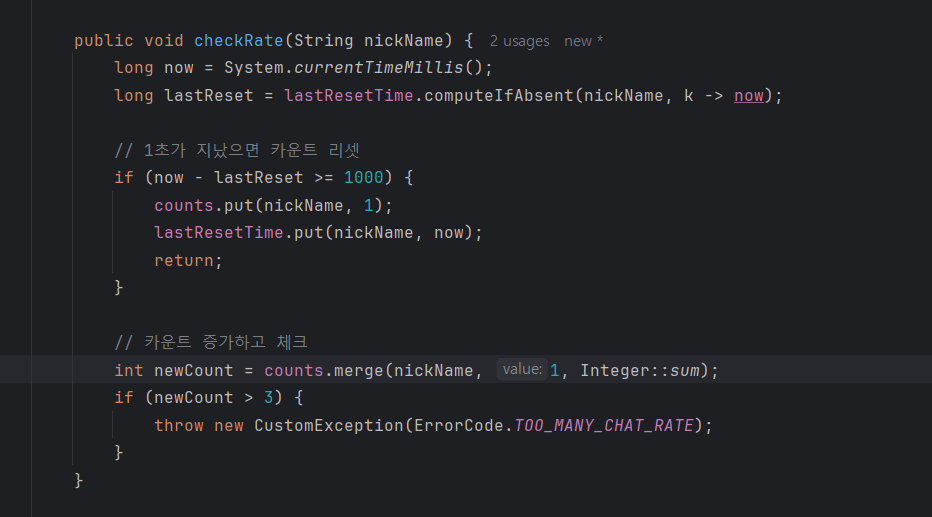
이렇게 하면 2번째 인자인 1이 (oldValue가 null인 경우) oldValue가 된다.
ConcurrentHashMap이란?
이번에 이 자료구조를 처음 사용해본다.
어떤 내용인지 정리해보자.
참고:https://javaconceptoftheday.com/hashmap-vs-concurrenthashmap-in-java/
우선, ConcurrentHashMap은 Thread-safe하다. 대신 읽기 작업은 synchronized되지 않고, add와 delete만 그러하다. 그래서 읽기 작업은 일반 Hashmap과 속도면에서 차이가 없다.
put의 작동원리
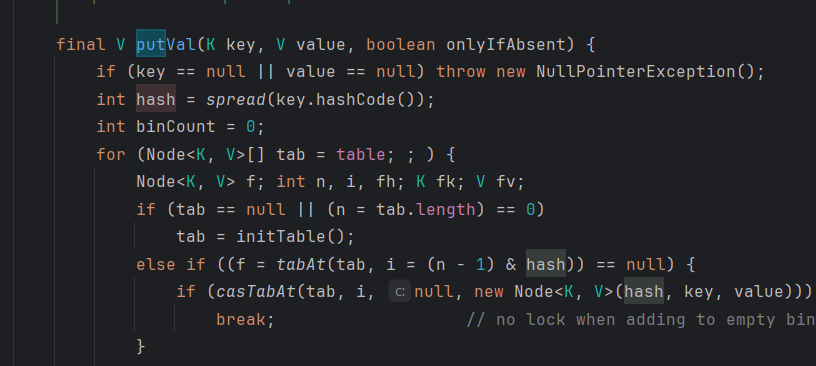
이렇게 처음에 비어있는 key에 값을 넣을 때는 lock을 걸지 않는다.
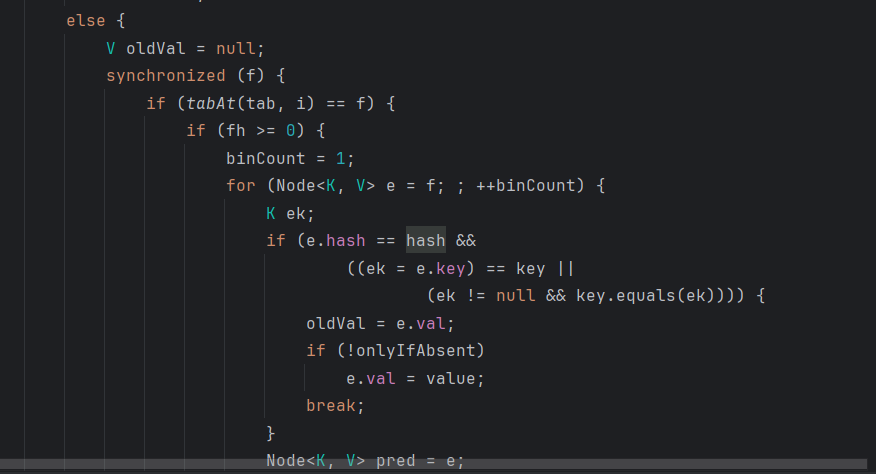
이미 버킷에 노드가 존재하면, synchronized를 통해서 락을 걸고 다른 스레드가 접근하지 못하게 한다.
참고:[Java] ConcurrentHashMap 이란 무엇일까?
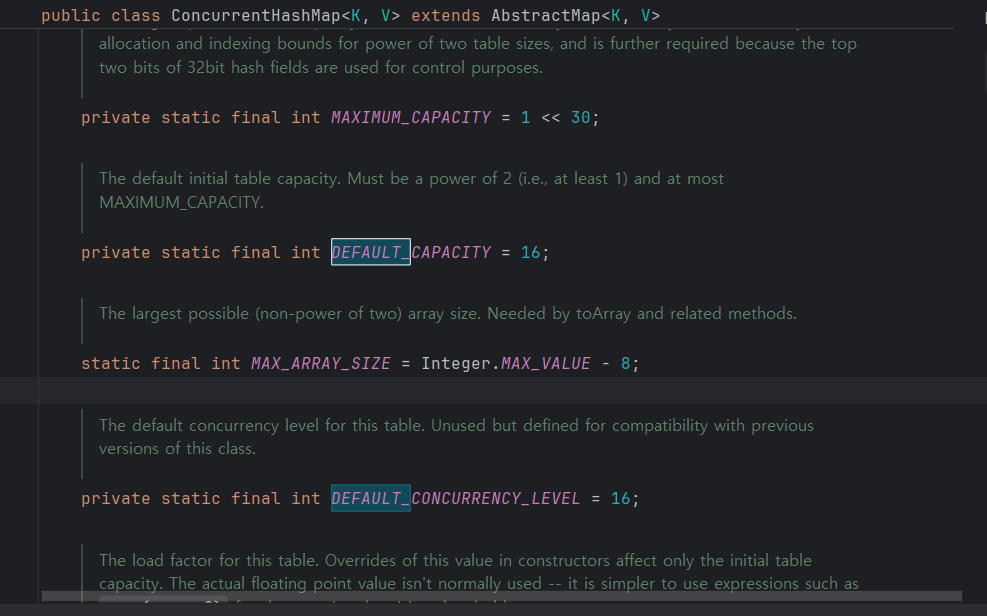
여기보면 버킷의 수를 16개로 설정하고 있다. DEFAULT_CONCURRENCY_LEVEL는 동시에 작업 가능한 쓰레드 수라고 한다.
버킷의 수 == 동시작업 가능한 쓰레드 수인 이유는 ConcurrentHashMap은 버킷 단위로 lock을 사용하기 때문에 같은 버킷만 아니라면 Lock을 기다릴 필요가 없다는 특징이 있다.(버킷당 하나의 Lock을 가지고 있다라고 생각하면 될 것 같다고 한다)
즉, 여러 쓰레드에서 ConcurrentHashMap 객체에 동시에 데이터를 삽입, 참조하더라도 그 데이터가 다른 세그먼트에 위치하면 서로 락을 얻기 위해 경쟁하지 않는다.
(버킷은 그냥 분리된 공간으로, 데이터를 분산해서 저장하는 용도로 쓴다고 이해했다)
성능은 어떨까?
@Test
void test2() throws ExecutionException, InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(5);
List<Long> executionTimes = new ArrayList<>();
for (int k = 0; k < 10; k++) {
List<Future<?>> futures = new ArrayList<>();
AtomicInteger exceptionCount = new AtomicInteger(0);
long start = System.currentTimeMillis();
// 태스크 제출
for (int i = 0; i < 100; i++) {
for (int j = 0; j < 50; j++) {
int finalI = i;
futures.add(executor.submit(() -> {
try {
chatRateLimiter.checkRate("testUser" + finalI);
} catch (CustomException e) {
exceptionCount.incrementAndGet();
}
}));
}
}
// 모든 태스크 완료 대기
for (Future<?> future : futures) {
future.get();
}
long executionTime = System.currentTimeMillis() - start;
executionTimes.add(executionTime);
}
executor.shutdown();
// 평균 실행 시간 계산
double averageTime = executionTimes.stream()
.mapToLong(Long::valueOf)
.average()
.orElse(0);
System.out.println("Average execution time: " + averageTime + "ms");
}ConcurrentHashmap을 쓸 때는

5000개의 메시지를 처리할 때 36ms로 굉장히 빠르다 ㅎㅎ..
일반 Hashmap은 어떨까
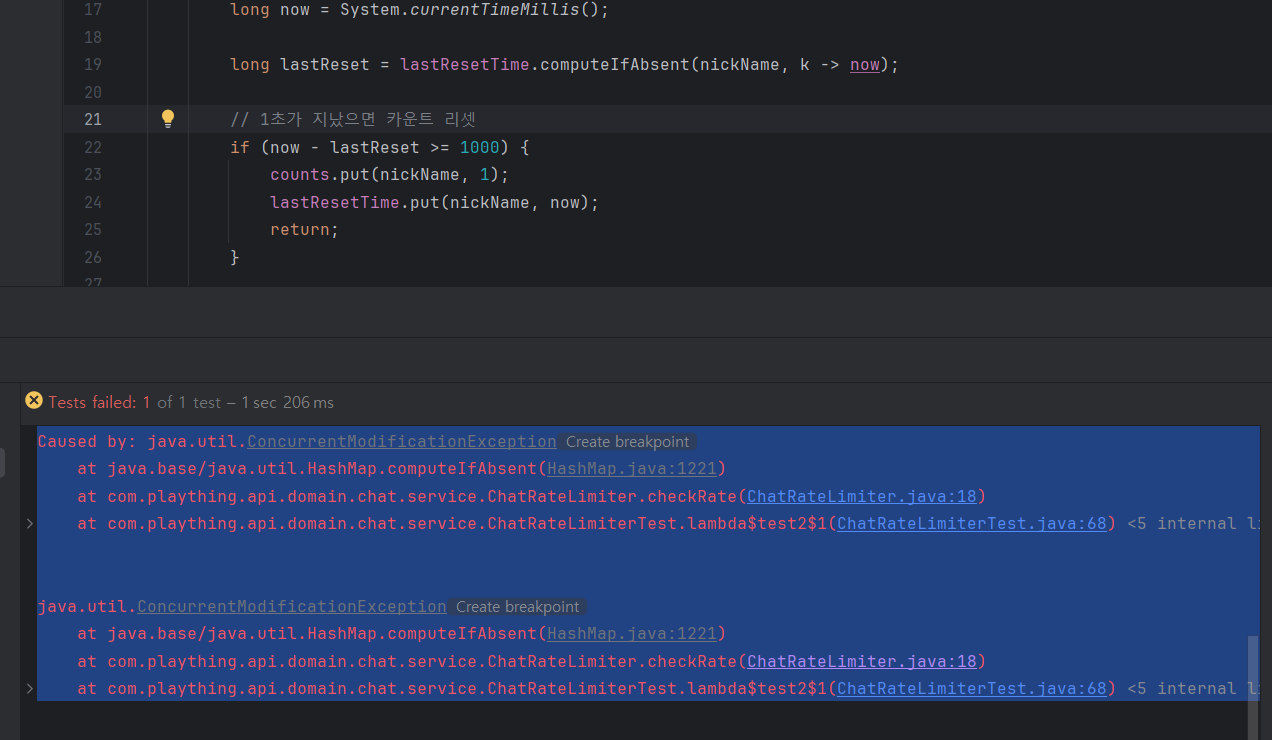
멀티스레드에 세이프하지 않아서 문제가 생겼다.
그럼 그냥 하나의 스레드로 처리를 해보자.

90ms 정도가 걸리는데
멀티스레드를 안 쓰기 떄문인것으로 보인다.
ConcurrentHashmap도 성능적으로 이슈는 없을 것 같다.
