JPA-MySQL을 쓰면서 HiKariCP 설정을하게 된다.
HiKariCP는 데이터베이스 연결(Connection)을 관리해 주는 라이브러리다.
여기서 커넥션 풀의 숫자를 설정할 수 있다.
커넥션 풀의 원리는
커넥션을 미리 풀에 만들어놓고, 필요할 때마다 가져가서 쓰는 방식이다.
DB 연결이 필요할 때마다 커넥션을 만드는 방식은 TCP 3-way handshake 때문에 리소스를 많이 사용하게 된다. 그래서, 풀 방식을 활용하는 것이다.
그렇다면, 이 풀 사이즈를 어떻게 설정해야 할까? 더 많은 요청이 들어올 것을 대비해서 무조건 크게 하는 게 좋을까?
답은 'NO'이다.
About Pool Sizing이 자료를 봐보자.
A 웹 사이트에서 1만명의 유저가 동시에 DB요청을 보낸다고 해보자. 초당 2만개의 트랜잭션이 필요하다고 할 때, 커넥션 풀이 어느정도로 커져야 할까? 실제로는 그렇게 크지 않고 small한 편이다.
왜 커넥션 풀 사이즈가 작아도 되는거야?
엔진엑스와 아파치의 경우를 잠시 생각해보자. 스레드가 4개인 엔진엑스가 100개의 프로세서를 가진 아파치 서버보다 성능이 좋은 이유가 뭘까?
그 내용은 여기에 정리해두었다. 쉽게 생각하면, 논블로킹방식의 비동기를 사용하기 때문이다. 스레드가 작업하나에 묶여있지않고, 이벤트방식으로 수백~수천개의 작업을 처리한다.
코어 하나는 수천개의 스레드를 처리할 수 있다. 다만 이는 동시에 처리하는 것처럼 보이지만, 타임 슬라이싱 방식을 통해서 여러개를 돌아가면서 매우 빠른 속도로 처리하는 것이다.
일반적으로 DB의 병목지점은 CPU, Disk, 네트워크 그리고 메모리다. 8개의 코어가 있는 서버에서, 커넥션 수를 8로 지정해보면 적절한 퍼포먼스를 제공할 것이다. 이를 넘어서면 컨텍스트 스위칭으로 인해서 오히려 오버헤드가 늘어날 수 있다.
하지만, 디스크와 네트워크를 무시할 수는 없다. 데이터베이스는 데이터를 디스크에 저장한다. 디스크는 회전을 하면서 데이터를 읽고 쓰는데, 한번에 한 위치에서만 읽기/쓰기가 가능하다. 다른 데이터를 읽으려면 헤드가 물리적으로 이동해야 한다. 이때 seek time이 발생한다. 디스크가 회전해서 원하는 데이터가 헤드 아래로 오는 데도 시간이 걸린다.
이러한 I/O wait 타임동안에는 커넥션/스레드는 블로킹이 된다. 그래서, OS는 이 시간동안 CPU 리소스를 다른 작업에 활용할 수 있다. 그래서, 스레드가 I/O로 인해 블로킹이 될 수 있는 탓에 우리는 CPU보다 더 많은 커넥션/스레드를 만들어서 퍼포먼스를 향상시킬 수 있는 것이다.
그렇다면 얼마나 많은 커넥션을 만들어둬야 할까? 이는 디스크의 서브 시스템에 달려 있다. 최근에 SSD들은 seek time 코스트나 roational factor를 갖고 있지 않는다. 다만, 그렇다고 해서 SSD가 빠르니까 더 많은 스레드를 가질 수 있다고 생각해선 안된다.
빨라졌다고 하더라도 블록킹이 줄어든다는 것이지, 블록킹 영향은 여전히 존재하기 때문이다. 네트워크도 디스크와 유사하다. 네트워크를 통해서 데이터를 쓸 때 블록킹이 발생한다.(send, receiver 버퍼가 다 찼을 때 발생) 네트워크 속도가 빨라져서 블록킹 영향은 줄어들었지만, 여전히 퍼포먼스 계산에 참고할 필요는 있다.
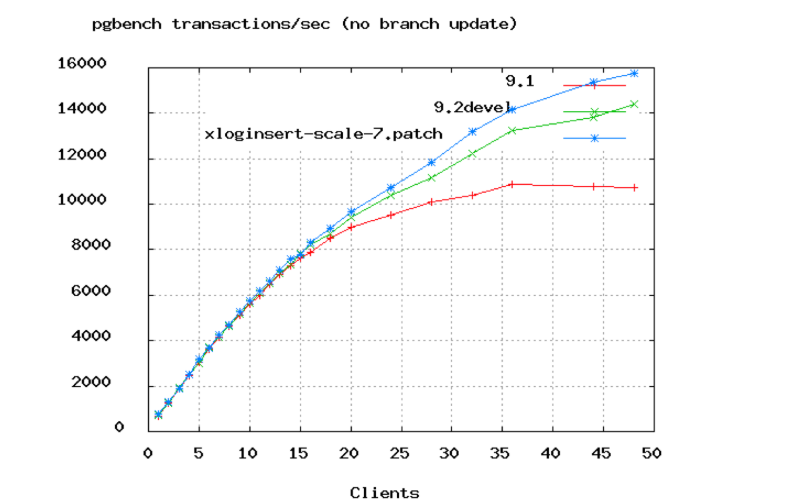
PostgreSQL 벤치마크에서, TPS가 50개의 커넥션에서부터 평평해지는 걸 볼 수 있다.
HikariCP에서 제시한 이상적인 커넥션풀의 숫자는
connections = ((core_count * 2) + effective_spindle_count)
라고한다.
10개의 커넥션을 만들었다고 할 때, 3000명의 사용자 초당 6천개의 쿼리도 거뜬하게 처리한다고 한다.
You want a small pool, saturated with threads waiting for connections.
If you have 10,000 front-end users, having a connection pool of 10,000 would be shear insanity. 1000 still horrible. Even 100 connections, overkill. You want a small pool of a few dozen connections at most, and you want the rest of the application threads blocked on the pool awaiting connections. If the pool is properly tuned it is set right at the limit of the number of queries the database is capable of processing simultaneously -- which is rarely much more than (CPU cores * 2) as noted above.
1만명의 클라이언트 유저가 있다고 해서 커넥션풀 사이즈를 1만으로 설정하는건 굉장히 미친(insane)짓이다. 심지어 1000개의 커넥션을 만드는 것도 너무 과하다.
풀 락킹현상은 뭐야?
하나의 스레드가 여러개의 커넥션을 동시에 필요로할 때 발생할 수 있는 문제다. 다만, 주로 애플리케이션 레벨의 문제로, 먼저 애플리케이션 단에서 해결 방법을 찾아야 한다.
데드락 방지를 위한 풀 크기 계산 공식은
pool size = Tn x (Cm - 1) + 1으로
Tn: 최대 스레드 수
Cm: 한 스레드가 동시에 사용하는 최대 커넥션 수를 말한다.
3개의 스레드가 있고, 각각 4개의 커넥션을 필요로 한다고 해보자.
pool size = 3 x (4 - 1) + 1 = 10
다만, 이 계산은 최적의 커넥션풀 숫자가 아니라 풀 locking을 피하기 위한 계산 방식이다.
이런 상황도 있다...
트랜잭션을 매우 길게 가져가는 것과, 짧게 가져가는 두 가지 경우를 처리하는 시스템도 있다. 이런 경우는 튜닝하기가 어려운데, 그냥 두개의 커넥션 풀을 만드는 게 베스트라고 한다.
참고자료
