KNN 정의
새로운 데이터를 입력 받았을 때 이 데이터와 가장 근접한 데이터들의 종류가 무엇인지 확인하고 많은 데이터의 종류로 분류하는 알고리즘이다.
그림으로 설명하면
K-NN은 새로 들어온 "★은 ■ 그룹의 데이터와
가장 가까우니 ★은 ■ 그룹이다." 라고 분류하는 알고리즘이다.
여기서 k의 역할은 몇 번째로 가까운 데이터까지 살펴볼 것인가를 정한 숫자다.
KNN 특징
- feature의 수가 많거나, 이상치가 있으면 성능이 떨어진다.
- 서로 다른 값들의 비율(단위)이 일정하지 않으면 성능이 떨어지므로 스케일링(정규화,표준화)를 권장한다.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
x_train, x_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=66, stratify=cancer.target)
# stratify = 속성을 사용하면 편향을 방지한다. 분류의 경우에는 성능을 보장받기 위해 사용을 권장
train_acc = []
test_acc = []
k_setting = range(1,11) # 최적의 k개를 얻고자 후보 k를 결정
for n in k_setting:
clf = KNeighborsClassifier(n_neighbors=n, p=2, metric='minkowski')
clf.fit(x_train, y_train)
train_acc.append(clf.score(x_train, y_train)) # train 정확도
test_acc.append(clf.score(x_test, y_test)) # test 정확도
import numpy as np
print('train 분류 평균 정확도 : ', np.mean(train_acc))
print('test 분류 평균 정확도 : ', np.mean(test_acc))
# 최적의 k를 위한 시각화
plt.plot(k_setting, train_acc, label='훈련데이터 정확도')
plt.plot(k_setting, test_acc, label='검증데이터 정확도')
plt.xlabel('k값')
plt.ylabel('분류 정확도')
plt.legend()
plt.show()시각화를 통해 최적의 k개를 찾을 수도 있다.
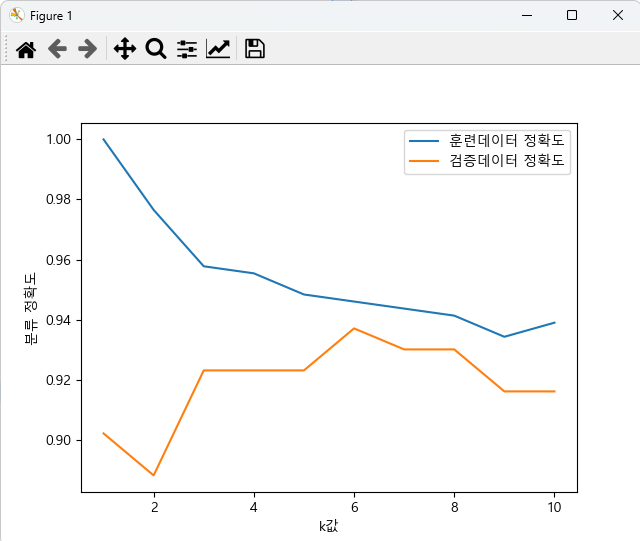
k값이 1일때는 과적합이 의심되고, 훈련데이터와 검증데이터의 차이가 적은 k값인 6이 최적의 k값이라고 생각할 수 있다.

남들과 함께 발자국을 남기는 까만호랭