💡 딥러닝이란?
인간의 신경망 원리를 모방한 심층 신경망 이론을 기반으로 머신러닝의 일종이다. 다만, 인간의 뇌를 기초로 설계했다는 점에서 머신러닝과 다르다.
딥러닝의 학습과정
-
데이터 준비
-
모델 정의 :
신경망을 생성 - (은닉층 개수가 많을수록 성능이 좋아지지만 과적합 발생확률이 높음) -
모델 컴파일 :
활성화함수, 손실함수, 옵티마이저를 선택
이때 train data가 연속형이라면 MSE(평균제곱오차)를 사용,
이진분류라면 크로스 엔트로피(cross-entropy)을 사용. -
모델 훈련 :
한 번에 처리할 데이터 양을 지정.(배치와 훈련 횟수인 epoch 지정)
ex) 훈련 데이터셋 100개에 대한 batch_size가 10이라면
👉 샘플 단위 10개마다 (100/10)인 모델 가중치를 한 번씩 업데이트 한다는 뜻 -
모델 예측 :
검증 데이터셋을 생성한 모델에 적용하여 실제로 예측을 진행
예측력이 낮다면 파라미터를 바꾸거나, 신경망을 재설정해야함
# 0. 데이터 수집 및 가공
x = np.array([[0,0],[0,1],[1,0],[1,1]])
y = np.array([0,1,1,1])
# 1. 모델구성(설정)
model = Sequential()
model.add(Dense(units=1, input_dim=2, activation='sigmoid')) # 이항분류일때 sigmoid, 다항분류일때 softmax
# 2. 모델 학습 과정 설정(컴파일)
model.compile(optimizer=Adam(learning_rate=0.001), loss='binary_crossentropy', metrics=['accuracy'])
# 3. 모델 학습시키기(train data) : 더 나은 표현(w-가중치 를 갱신)을 찾는 자동화 과정
model.fit(x, y, epochs=500, batch_size=1, verbose=0)
# 4. 모델 평가(test data)
loss_metrics = model.evaluate(x, y, batch_size=1, verbose=0)
print(loss_metrics) # [0.35304421186447144, 0.75] <-- 이 숫자들은 서로 반비례 관계
# 5. 학습결과 확인 : 예측값 출력
pred = model.predict(x, batch_size=1, verbose=0)
pred = (model.predict(x) > 0.5).astype('int32') # 0.5보다 크면 1, 작으면 0
print('예측 결과 : ', pred.flatten())신경망
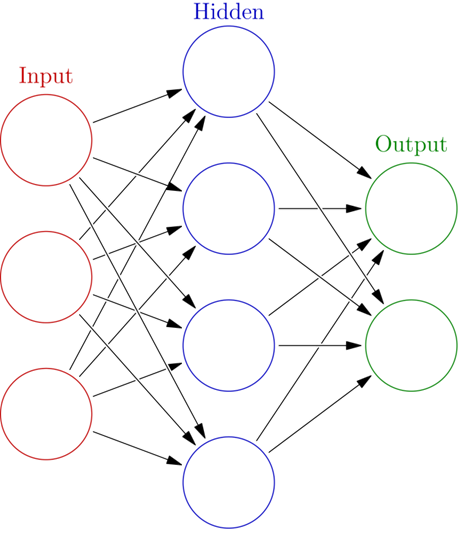
입력층(Input Layer)
- feature에 대한 정보(독립변수)를 입력받고 다음 층으로 전달한다.
- 입력층 노드의 수 = 독립변수의 수
은닉층(Hidden Layer)
- 종속변수를 예측하는데 중요한 특성이나 패턴을 추출한다.
- 입력 받은 데이터를 활성화 함수(activation function)를 거쳐서 변환해서 전달함
- 은닉층 노드의 수 = 사용자가 설정
출력층(Output Layer)
- 종속변수의 예측치를 출력한다.
회귀의 경우 종속변수의 값을 그대로 출력하고 분류는 각 종속변수 클래스의 확률을 출력함
회귀문제 : 출력 노드의 수 = 1
분류문제 : 출력 노드의 수 = 종속변수의 클래스 수
순전파
인공 신경망에서 입력 데이터가 네트워크를 통과하여 출력까지 계산되는 과정을 의미한다.
데이터는 입력층부터 출력층까지 순차적으로 전달되며, 각 층의 뉴런은 입력값과 가중치를 고려하여 활성화 함수를 통해 출력값을 생성한다.
역전파
인공 신경망에서 사용되는 학습 알고리즘 중 하나이며 신경망의 가중치를 조정하여 입력데이터와 기대 출력 값 사이의 오차를 최소화 하려고 한다.
- 순전파 단계에서 입력 데이터를 신경망에 통과시켜 예측 값을 계산한다.
- 예측 값과 실제 값 사이의 오차를 측정한다.
- 역전파 단계에서 이 오차를 역방향으로 전파하여 각 노드(뉴런)가 해당 오차에 얼마나 영향을 주는지 계산한다.
- 이 오차 기여도를 사용하여 가중치를 조정한다(경사 하강법 등을 사용하여).
경사하강법 : 함수의 기울기(경사)를 이용하여 함수의 최솟값(또는 최댓값)을 찾는 최적화 방법 중 하나
활성화 함수 : 입력 신호가 일정 기준 이상이면 출력 신호로 변환하는 함수 ex) sigmoid, Hyperbolic Tangent, relu 등이 있음.
손실함수 : 모델의 출력 값과 사용자가 원하는 출력 값의 차이
ex) 오차를 구하는 MSE와 cross-entropy가 있음
옵티마이저 : 손실함수의 최소값을 찾는 알고리즘(입력데이터와 손실함수를 업데이트하는 과정을 지니고 있음)
ex) Adam, RMSProp, SGD 등이 있음.
