01. 데이터 수집
1) 데이터 처리 기술
① 수집 데이터의 유형
- 내부 데이터
- 내부 데이터는 조직(인프라) 내부 에 데이터가 위치하며, 데이터 담당자와 수집 주기 및 방법 등을 협의하여 수집
- 내부 데이터는 내부 조직간 협의를 통해 데이터를 수집
- 주로 수집이 용이한 정형 데이터 이고 서비스의 수명 주기 관리가 용이
- 외부 데이터
- 조직(인프라) 외부에 데이터가 위치
; 특정 기관의 담당자 협의 혹은 데이터 전문 업체를 통해 수집 - 공공 데이터의 경우 공공 데이터 포털의 Open API 혹은 파일을 통해 수집
- 외부 조직과의 협의 필요 & 데이터 구매 및 웹 상의 오픈 데이터를 통해 데이터를 수집
- 조직(인프라) 외부에 데이터가 위치
② 데이터 수집 방식 및 기술
- ETL = Extract Transform Load
- 데이터 분석을 위한 데이터를 데이터 저장소인 DW (Data Warehouse) 및 DM (Data Mart) 으로 이동시키기 위해 다양한 소스 시스템으로부터 필요한 원본 데이터를 추출 Extract 하고 변환(변화, 정제) Transform 하는 기술
- 데이터 분석을 위한 데이터를 데이터 저장소인 DW (Data Warehouse) 및 DM (Data Mart) 으로 이동시키기 위해 다양한 소스 시스템으로부터 필요한 원본 데이터를 추출 Extract 하고 변환(변화, 정제) Transform 하는 기술
- 스크래파이 Scrapy
- 웹 사이트를 크롤링 하여 구조화된 데이터를 수집하는 파이썬 기반의 애플리케이션 프레임워크
- 데이터 마이닝, 정보 처리, 이력 기록 같은 다양한 애플리케이션에 사용되는 수집 기술
- 설정이 쉽고 크롤링 수행 후 바로 데이터 처리 가능
- 크롤링 Crawling
- 인터넷 상에서 제공되는 다양한 웹사이트로부터 소셜 네트워크 정보, 뉴스, 게시판 등의 웹 문서 및 콘텐츠 수집 기술
- 인터넷 상에서 제공되는 다양한 웹사이트로부터 소셜 네트워크 정보, 뉴스, 게시판 등의 웹 문서 및 콘텐츠 수집 기술
- RSS = Rich Site Summary
- 블로그, 뉴스, 쇼핑몰 등의 웹사이트에 게시된 새로운 글 을 공유하기 위해 XML 기반으로 정보를 배포하는 프로토콜을 활용하여 데이터를 수집하는 기술
- 블로그, 뉴스, 쇼핑몰 등의 웹사이트에 게시된 새로운 글 을 공유하기 위해 XML 기반으로 정보를 배포하는 프로토콜을 활용하여 데이터를 수집하는 기술
- Open API
- 응용프로그램을 통해 실시간 으로 데이터를 수신할 수 있도록 공개된 API 를 이용하여 데이터를 수집하는 기술
- API = Application Programming Interface
- 시스템간 연동을 통해 실시간으로 데이터를 수신할 수 있는 기능을 제공하는 인터페이스 기술
- API는 솔루션 제조사 및 3rd Party 가 sw 형태로 제공하기도 한다.
- Rsync = Remote Sync
- 서버, 클라이언트 방식 으로 로컬 혹은 원격의 수집 대상 시스템과 1:1로 파일과 디렉토리를 동기화하는 응용프로그램 활용 기술
- 서버, 클라이언트 방식 으로 로컬 혹은 원격의 수집 대상 시스템과 1:1로 파일과 디렉토리를 동기화하는 응용프로그램 활용 기술
- 센싱 Sensing
- 센서로부터 수집 및 생성된 데이터를 네트워크를 통해 수집 및 활용하는 기술
- 센서로부터 수집 및 생성된 데이터를 네트워크를 통해 수집 및 활용하는 기술
- 스트리밍 Streaming
- 네트워크를 통해 센서 데이터 및 오디오, 비디오 등의 미디어 데이터 를 실시간으로 수집하는 기술
- 네트워크를 통해 센서 데이터 및 오디오, 비디오 등의 미디어 데이터 를 실시간으로 수집하는 기술
- CEP = Complex Event Processing
- 여러 이벤트 소스로부터 발생한 이벤트 를 실시간 추출하여 대응되는 액션을 수행하는 처리 기술
- 실시간 상황에서 의미 있는 이벤트를 파악하고 가능한 빨리 대응할 수 있다.
-
EAI = Enterprise Application Integration
- 기업에서 운영되는 서로 다른 플랫폼 및 애플리케이션 간의 정보 전달, 연계, 통합을 가능하게 해주는 연계 기술
- 각 비즈니스 간 통합 연대성을 증대 → 효율성을 ↑ & 각 시스템간 확장성 ↑
-
CDC = Change Data Capture
- 데이터 백업이나 통합 작업을 할 경우 최근 변경된 데이터를 대상으로 다른 시스템으로 이동하는 처리 기술
- 실시간백업과 데이터 통합 가능 → 24시간 운영해야 하는 업무 시스템에 활ㄹ용
-
ODS = Operational Data Store
- 데이터에 대한 추가 작업을 위해 다양한 데이터 원천Source들로부터 데이터를 추출 및 통합한 데이터베이스
- ODS 내 데이터는 비즈니스 지원을 위해 타 시스템으로 이관되거나 보고서 생성을 위해 데이터 웨어하우스 DW 로 이관된다.
02. 데이터 유형 파악
1) 데이터 유형 구분
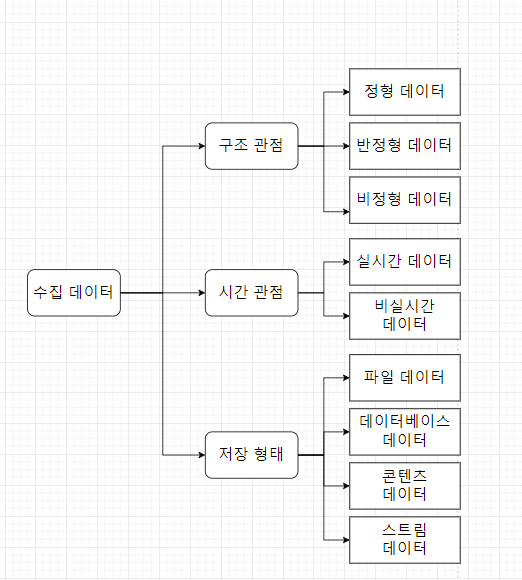
① 구조 관점 데이터 유형
- 정형 데이터 Structured Data
정형화된 스키마(형태) 구조기반의 형태를 가지고 고정된 필드에 저장되며 형식에서 일관성을 가지는 데이터
- 칼럼 Column 과 로우 Row 구조를 가지며 설계된 구조 기반 목적에 맞는 정보들을 저장하고 분석하는데 사용된다.
- 정형 데이터의 종류 : 관계형 데이터베이스 RDB, 스프레드시트
-
반정형 데이터 Semi-Structured Data
스키마(형태) 구조 형태를 가지고 메타데이터를 포함하며 값과 형식에서 일관성을 가지지 않는 데이터
- XML, HTML과 같은 웹 데이터가 Node 형태의 구조를 가진다.
- 반정형 데이터의 종류 : XML, 웹로그, 시스템 로그 , 제이슨, 센서 데이터
-
비정형 데이터 Unstructured Data
스키마 구조 형태를 가지고 있지 않고 고정된 필드에 저장되지 않는 데이터
- 비정형 데이터의 종류 : SNS, 텍스트/이미지/오디오/비디오 데이터 가 있다.
② 시간 관점 데이터 유형
| 데이터 종류 | 정의 | 종류 |
|---|---|---|
| 1. 실시간 데이터 RealTime Data | 실시간 데이터는 생성된 이후 수 초~ 수분 이내에 처리되어야 의미가 있는 현재 데이터 | 센서 데이터, 시스템 로그, 네트워크 장비 로그, 보안 장비 로그 |
| 2. 비실시간 데이터 Non-RealTime Data | 생성된 데이터가 수 시간 혹은 수 주 후에 처리되어야 의미가 있는 과거 데이터 | 통계, 웹로그, 구매 정보, 서비스 로그 |
③ 저장 형태 관점 데이터 유형
| 데이터 종류 | 정의 | 종류 |
|---|---|---|
| 파일 데이터 | - 파일 형식으로 파일 시스템에 저장되는 데이터 - 파일 크기가 대용량이거나 파일의 개수가 다수인 데이터 | 시스템 로그 파일, 텍스트 파일 |
| 데이터 베이스 데이터 | - 데이터의 종류나 성격에 따라 데이터베이스의 칼럼Column 혹은 테이블 Table 등에 저장된 데이터 | 관계형 데이터베이스 RDBMS, NoSQL(Not only SQL) |
| 콘텐츠 데이터 | 개별적으로 데이터 객체로 구분될 수 있는 미디어 데이터 | 텍스트, 이미지, 오디오, 비디오 |
| 스트림 데이터 | 네트워크를 통해서 실시간으로 전송되는 데이터 | 센서 데이터, HTTP 트랜잭션, 알람 |
03. 데이터 변환
데이터의 특정 변수를 정해진 규칙에 따라 바꾸어주는 것
1) 데이터 변환 기술
① 데이터 변환 기술 유형
(1) 평활화 Smoothing
- 데이터로부터 잡음을 제거하기 위해 데이터 추세에서 벗아나는 값들을 변환하는 기법
- 데이터 집합에 존재하는 잡음으로 인해 거칠게 분포된 데이터를 매끄럽게 만들기 위해 구간화, 군집화 등의 기법 적용
(2) 집계 Aggregation
- 다양한 차원의 방법으로 데이터를 요약하는 기법
- 복수개의 속성을 하나로 줄이거나 유사한 데이터 객체 Data Object 를 줄이고 스케일을 변경하는 기법 을 적용
(3) 일반화 Generalization
- 특정 구간에 분포하는 값으로 스케일을 변화시키는 기법
- 일부 특정 데이터만 잘 설명하는 것이 아니라 범용적인 데이터에 적합한 모델을 만드는 기법
- 잘 된 일반화는 이상값이나 노이즈가 들어와도 크게 흔들리지 않아야 한다.
(4) 정규화 Normalization
- 데이터를 정해진 구간 내에 들도록 하는 기법
- 최단근접분류와 군집화와 같은 거리 측정 등을 위해 특히 유용
- 데이터에 대한 최소-최대 정규화 등 통계적 기법을 적용한다.
(5) 속성 생성 Attribute / Feature Construction
- 데이터 통합을 위해 새로운 속성이나 특징을 만드는 방법
- 주어진 여러 데이터 분포를 대표할 수 있는 새로운 속성/특징을 활용하는 기법
- 선택한 속성을 하나 이상의 새 속성으로 대체하여 데이터를 변경 처리
② 데이터 변환 후 품질 검증
메타데이터를 통한 품질 검증, 정규 표현식을 통한 품질 검증, 데이터 프로파일링 등이 있다.
04. 데이터 비식별화
1) 개인 정보 처리 기술
① 데이터 비식별화 Data De-Identification 개념
특정 개인을 식별할 수 없도록 개인 정보의 일부 혹은 전부를 변환하는 일련의 방법
- For 데이터를 안전하게 활용
→ 수집된 데이터의 개인 정보 일부 혹은 전부를 삭제 or 다른 정보로 대체
∴ 다른 정보와 결합하여도 특정 개인을 식별하기 어렵게 해야 함
② 데이터 비식별화 처리 기법
(1) 가명 처리 Pseudonymisation
- 개인 식별이 가능한 데이터에 대하여 직접 식별할 수 없는 다른 값으로 대체하는 기법
- 그 자체로는 완전 비식별화가 가능 ; 데이터의 변형, 변질 수준 ↓
- 일반화된 대체 값으로 가명 처리 → 성명을 기준으로 하는 분석에 한계가 존재
ex) 홍길동, 한국대 재학 → 임꺽정, 외국대 재학
(2) 총계 처리
- 개인 정보에 대해 통계값을 적용 하여 특정 개인을 판단할 수 없도록 하는 기법
- 민감한 정보에 대해 비식별화 可 & 다양한 통계분석(전체, 부분) 용 데이터 세트 작성에 유리
- 집계 처리된 데이터를 기준으로 정밀한 분석이 어려움 +
집계 수량이 적을 경우 데이터 결합 과정에서 개인 정보 추출 혹은 예측 가능
ex) 임꺽정 180cm, 홍길동 170, 김콩쥐 160, 장길상 150
→ 물리학과 학생 키 합 : 660 / 평균키 165
(3) 데이터값 삭제 Data Reduction
- 개인 정보 식별이 가능한 특정 데이터 값을 삭제 처리
- 민감한 개인 식별 정보에 대하여 완전한 삭제 처리 가능 → 예측, 추론 등이 어렵게 한다.
- 데이터 삭제로 인한 분석의 다양성, 분석결과의 유효성, 분석 정보의 신뢰성↓
(4) 범주화 Data Suppression
- 단일 식별 정보를 해당 그룹의 대푯값으로 변환(범주화) or 구간 값으로 변환(범주화) 하여 고유 정보 추적 및 식별 방지
- 범주나 범위 → 통계형 데이터 ; 다양한 분석 및 가공 가능
- 범주, 범위로 표현 → 정확한 수치에 따른 분석, 특정한 분석 결과 도출이 어려움
- 데이터 범위 구간이 좁혀질 경우 추적, 예측이 가능
ex) 홍길동 31세 → 홍씨, 30~40세
(5) 데이터 마스킹
- 개인 식별 정보에 대하여 전체 혹은 부분적으로 대체 값으로 변환하는 기법
- 완전 비식별화 가능 + 원시 데이터의 구조에 대한 변형 小
- 과도한 마스킹 적용 → 필요한 정보로 활용하기 어려움
- 마스킹 수준 ↓ → 특정한 값의 추적 예측 가능
ex) 홍길동, 한국대 재학 → 홍ㅇㅇ, ㅇㅇ대학 재학
③ 개인 정보 익명 처리 기법
| 기법 | 설명 |
|---|---|
| 가명 Pseudonym | 개인 식별이 가능한 데이터에 대하여 직접 식별할 수 없는 다른 값으로 대체 |
| 일반화 Generalization | 더 일반화된 값으로 대체하는 것 ; 숫자 데이터의 경우 구간으로 정의하고 범주화된 속성은 트리의 계층적 구조에 의해 대체하는 기법 |
| 섭동 Perturbation | 동일한 확률적 정보를 가지는 변형된 값에 대하여 원래 데이터를 대체하는 기법 |
| 치환 Permutation | 속성값을 수정하지 않고 레코드 간에 속성값의 위치를 바꾸는 방법 |
④ 가명 정보
추가정보의 사용 없이 특정 개인을 알아볼 수 없게 조치한 정보
- 데이터 3법에서는 데이터 이용 활성화를 위해 가명 정보를 도입
- 개인정보 vs 가명 정보 vs 익명 정보
| 정보 | 설명 | 활용가능범위 |
|---|---|---|
| 개인정보 | - 특정 개인에 관한 정보 - 개인을 알아볼 수 있게 하는 정보 | 사전적이고 구체적인 동의를 받은 범위 내에서 활용 가능 |
| 가명정보 | - 추가 정보의 사용 없이는 특정 개인을 알아볼 수 없게 조치한 정보 | 다음 목적에 동의 없이 활용 가능(EU GDPR) i) 통계 작성(상업적 목적 포함) ii) 연구(산업적 연구 포함) iii) 공익적 기록 보존 목적 등 |
| 익명정보 | 더 이상 개인을 알아볼 수 없게(복원 불가능한 정도로)조치한 정보 | 개인정보가 아님 → 제한 없이 자유롭게 사용 가능 |
⑤ 프라이버시 보호 모델
(1) k- 익명성 = k-Anonymity
- 주어진 데이터 집합에서 같은 값이 적어도 k개 이상 존재하도록 하여 쉽게 다른 정보와 결합할 수 없도록 하는 프라이버시 보호 모델
- 공개된 데이터에 대한 연결 공격 취약점을 방어하기 위한 프라이버시 보호 모델
- 연결 공격 Linkage Attach
- 개인을 직접 식별할 수 있는 데이터는 삭제되어야 하나 활용 정보의 일부가 다른 공개 되어 있는 정보와 결합 → 개인을 식별하는 것을 악용
(2) l - 다양성 = l-Diversity
- 주어진 데이터 집합에서 함께 비식별되는 레코드들은(동질집합에서) 적어도 l개의 서로 다른 민감한 정보를 가져와야 하는 프라이버시 보호 모델
- 비식별 조치 과정에서 충분히 다양한(l개 이상) 서로 다른 민감한 정보를 갖도록 동질 집합을 구성하는 기법
- k 익명성의 두 가지 취약점 공격인 동질성 공격, 배경지식에 의한 공격을 방어하기 위한 프라이버시 모델
- 동질성 공격 Homogeneity Attack
k - 익명성에 의해 레코드들이 범주화 but 일부 정보들이 모두 같은 값을 가질 수 있음
→ 데이터 집합에서 동일한 정보를 이용하여 공격 대상의 정보를 알아내는 공격 - 배경지식에 의한 공격 Background Knowledge Attack
주어진 데이터 이외 공격자의 배경지식을 통해 공격 대상의 민감한 정보를 알아내는 공격
- 동질성 공격 Homogeneity Attack
(3) t-근접성 t-Closeness
- 동질 집합에서 특정 정보의 분포와 전체 데이터 집합에서 정보 분포가 t 이하의 차이를 보여야 하는 프라이버시 보호 모델
- l 다양성의 쏠림 공격, 유사성 공격을 보완하기 위한 프라이버시 보호 모델
- 쏠림 공격 Skewness Attack
정보가 특정 값에 쏠려있을 경우 l-다양성이 프라이버시를 보호하지 못하는 것을 악용 - 유사성 공격 Similarity Attack
비식별 조치된 레코드의 정보가 서로 비슷 → l-다양성 모델을 통해 비식별된다 할지라도 프라이버시가 노출될 수 있음을 악용한 공격
- 쏠림 공격 Skewness Attack
(4) m-유일성 m-Uniqueness
- 원본 데이터와 동일한 속성값의 조합이 비식별 결과 데이터에 최소 m개 이상 존재하도록 하여 재식별 가능성을 낮춘 프라이버시 모델
⑥ 마이데이터 My Data
- 개인이 자신의 정보를 관리, 통제할 뿐만이 아니라 이러한 정보를 신용이나 자산관리 등에 능동적으로 활용하느 ㄴ일련의 과정
- 개인은 데이터 주권인 자기 정보 결정권으로 개인 데이터의 활용과 관리에 대한 통제관을 개인이 가진다는 것이 핵심

공부