01. 데이터 적재
1) 데이터 적재 기술
- 데이터 적재 = 데이터를 수집해서 전처리를 수행하기 전 원천 데이터를 저장해놓은 상태
① 데이터 적재 도구
| 종류 | 설명 |
|---|---|
| 플루언티드 Fluented | - 트레저 데이터 Treasure Data 에서 개발된 크로스 플랫폼 오픈 소스 데이터 수집 sw - 주로 루비 프로그래밍 언어로 작성 |
| 플럼 Flume | 많은 양의 로그데이터를 효율적으로 수집, 집계 및 이동하기 위해 이벤트 Event 와 에이전트 Agent를 활용하는 분산형 로그 수집 기술 |
| 스크라이브 Scribe | 다수의 서버로부터 실시간으로 스트리밍되는 로그데이터 를 수집하여 분산 시스템에 데이터를 저장하는 대용량 실시간 로그 수집 기술 |
| 로그 스태시 Logstach | 모든 로그 정보를 수집하여 하나의 저장소(DB, Elasticsearch 등)에 출력해주는 시스템 |
02. 데이터 저장
- 데이터 저장 = 목적에 맞게 데이터 전처리 작업 후 활용할 수 있도록 저장해놓은 상태
1) 데이터 저장
① 데이터 저장 기술
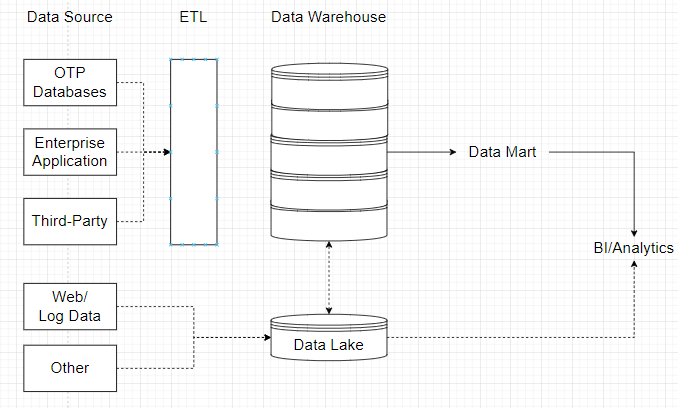
- 데이터 웨어하우스 DW = Data Warehouse
- For 사용자의 의사결정에 도움 give,
기간 시스템의 DB에 축적된 데이터 → 공동 형식으로 변환해서 관리하는 DB - 고도로 정제된 데이터 ; 스키마가 정의되어야 저장 가능
- 주제 지향적 Subject Oriented, 통합적 Integrated, 시계열적 Time-variant, 비휘발적 Nonvolatile 특징이 있다.
- 다양한 데이터 소스 Data Sources 로부터 데이터를 수집하여 ETL 과정을 거쳐 데이터 웨어하우스에 저장
- For 사용자의 의사결정에 도움 give,
- 데이터 마트 DM = Data Mart
- 전사적으로 구축된 데이터 속의 특정 주제, 부서 중심으로 구축된 소규모 단위 주제의 데이터 웨어하우스
- DW환경에서 정의된 접근 계층 ; DW에서 데이터를 꺼내 사용자에게 제공하는 역할
- 데이터 웨어하우스로부터 특정 주제별 혹은 특정 부서별로 데이터 마트를 생성
- By 데이터 마트 → 마케팅 Marketing, 금융 Finance 등의 의사결정 지원
- 데이터 레이크 Data Lake
- 정형, 반정형, 비정형 데이터를 비롯한 모든 가공되지 않은 다양한 종류의 데이터 (Raw data)를 저장할 수 있는 시스템 혹은 중앙 집중시 ㄱ데이터 저장소
- 저장할 때 스키마와 상관없이 저장 가능
- 웹/로그 데이터, 기타 데이터는 데이터 레이크에 저장;
저장된 데이터는 데이터 사이언스에 활용
② 빅데이터 저장 기술
-
구글 파일 시스템 GFS = Google File System
- 구글의 대규모 클러스터 서비스 플랫폼의 기반이 되는 파일 시스템
- 파일 ← 고정된 크기(64MB)의 청크로 split;
각 청크와 여러개의 복제본을 청크 서버에 분산하여 저장 - When 클라이언트 requests 파일 to GFS 마스터
→ 1) 마스터는 저장된 청크의 매핑 정보를 찾아 해당 청크 서버에 전송 요청
→ 2) 해당 청크 서버는 클라이언트에게 청크 데이터를 send
-
하둡 분산 파일 시스템 HDFS = Hadoop Distributed File System
- 수십 테라바이트 or 페타바이트 이상의 대용량 파일을 분산된 서버에 저장 & 그 저장된 데이터를 빠르게 처리할 수 있게 하는 파일 시스템
- 블록 구조의 파일 시스템 : 파일을 특정 크기의 블록으로 split, 분산된 서버에 저장
- 블록의 크기는 64MB에서 하둡 2.0에서부터는 128MB로 증가
-
러스터 Lustre
- 러스터 Luster = Linux + Cluster ; 고성능 컴퓨팅을 위한 대용량 파일 분산 파일 시스템
- 러스터 consist of
{ 네트워크로 연결된 1) 클라이언트 파일 시스템, 2) 메타데이터 서버 ,3) 객체 저장 서버들 } - 계층화된 모듈 구조 ; TCP/IP, 인피니 밴드 같은 네트워크 지원
-
데이터 베이스 클러스터
- 하나의 DB를 여러개의 서버 상에 분산하여 구축
- When 데이터 통합, For 성능&가용성 ↑ → 데이터 베이스 파티셔닝 혹은 클러스터링 이용
- 데이터베이스 파티셔닝 Database Partitioning
- 데이터베이스를 여러 부분으로 분할하는 것
; 각 분할된 요소는 파티션이라고 한다. - 각 파티션은 여러 노드로 분할 배치
∴ 여러 사용자가 각 노드에서 트랜잭션을 수행할 수 있다.
- 데이터베이스를 여러 부분으로 분할하는 것
- 데이터베이스 파티셔닝 Database Partitioning
-
NoSQL = Not Only SQL
- 전통적인 RDBMS 와 다른 DBMS를 지칭하기 위한 용어 :
데이터 저장에 고정된 테이블 스키마 필요 X + 조인 Join 연산 사용 X + 수평적으로 확장 可 - NoSQL 의 유형 : Key-Value Store, Column Family Data Store, Document Store, Graph Store
-
Key-Value Store
- Unique 한 key에 하나의 Value를 가지고 있는 형태의 DB
- 대표적 Key-Value Store DB : Redis, DynamoDB
종류 설명 Redis - REDIS = REmote Dictionary Server 는 메모리 기반의 Key-Value 구조의 데이터 베이스
- 모든 데이터를 메모리에 저장하고 조회 → 빠른 Read, Write 속도 보장DynamoDB AWS에서 개발한 Key-Value형 NoSQL DB로 원활한 확장성 + 빠른 성능 제공
-
Column Family Data Store
- Column Family Data Store 는 key 안에 (Column, Value) 조합으로 된 여러 개의 필드를 갖는 DB
- 대표적인 Column Family Data Store : HBase, Cassandra
종류 설명 HBase - Hadoop 의 HDFS 위에 만들어진 분산 칼럼 기반의 DB
- 구조화된 대용량의 데이터에 대한 실시간 읽기 및 쓰기 기능 제공Cassandra - 칼럼 기반의 분산형 NoSQL DB
- 단일 장애점 없이 고성능의 기능 제공
- 대용량의 데이터 관리 및 여러 데이터 센터에 걸쳐 클러스터 지원이 가능
-
Document Store
- Value 의 데이터 타입이 Document 라는 타입을 사용하는 DB
- Document 타입은 XML, JSON과 같이 구조화된 데이터 타입
; 복잡한 계층 구조를 표현 - 대표적 Document Store DB : MongoDB, CouchBase
종류 설명 MongoDB - NoSQL DB로 분류되고 크로스 플랫폼 도큐먼트 지향 데이터 베이스
- JSON 과 같은 동적 스키마형 도큐먼트들(MongoDB에서는 이러한 포맷을 BSON이라 부름)을 저장하는 DBCouchBase - 고성능의 NoSQL DB로 JSON Document 를 저장하는 Document DB
- 고정 DB 스키마의 제약 없이 쉽게 애플리케이션 수정 可
- 초고속 데이터 입출력 처리의 높은 성능 보장
-
Graph Store
- 시맨틱 웹과 온톨로지 분야에서 활용되는 그래프로 데이터를 표현하는 DB
- 온톨로지 Ontology
실세계에 존재하는 모든 개념과 개념들의 속성, 그리고 개념 간의 관계 정보를 컴퓨터가 이해할 수 있도록 서술해 놓은 지식 베이스 - 시맨틱 웹 Semantic Web
온톨로지 활용하여 서비스를 기술, 온톨로지의 의미적 상호운용성을 이용해서 서비스 검색, 조합, 중재 기능을 자동화하는 웹
- 온톨로지 Ontology
- 대표적인 Graph Store : Neo4j, AllegroGraph
종류 설명 Neo4j - Neo4j 사가 개발한 그래프 데이터베이스
- 네이티브 그래프 저장 및 처리 기능을 갖춘 ACID를 준수하는 트랜잭셔널 DBAllegroGraph - 미국 Franz 사의 제품으로 대표적인 상용 시맨틱웹 데이터베이스
- 시맨틱 웹 애플리케이션 구축하기 위한 DB 뿐만이 아니라 어플리케이션 FW도 포함 - 시맨틱 웹과 온톨로지 분야에서 활용되는 그래프로 데이터를 표현하는 DB
- 전통적인 RDBMS 와 다른 DBMS를 지칭하기 위한 용어 :

공부