1. 데이터 정제 Data Cleaning
데이터 정제는 결측값을 채우거나 이상값을 제거하는 과정을 통해 데이터의 신뢰도를 높이는 작업 이다.
1) 데이터 오류의 원인
| 원인 | 설명 | 오류 처리 방법 예 |
|---|---|---|
| 결측값 Missing Value | 필수적인 데이터가 입력되지 않은 값 | - 중심 경향값 넣기(평균값, 중앙값, 최빈값) - 분포 기반(랜덤에 의해 자주 나타나는 값 넣기) |
| 노이즈 Noise | 실제는 입력되지 않았으나 입력되었다고 잘못 판단한 값 | - 일정 간격으로 이동하면서 주변보다 높거나 낮으면 평균값으로 대체 - 일정 범위 중간값 대체 |
| 이상값 Outlier | 데이터 값이 일반적인 값보다 편차가 큰 값 | - 하한보다 낮으면 하한값 대체 - 상한보다 높으면 상한값 대체 |
2) 데이터 정제 방법
- 데이터 정제는 오류 데이터 값을 정확한 데이터로 수정하거나 삭제하는 과정
- 정제 여부의 점검은 정제 규칙을 이용하여 위반되는 데이터를 검색하는 방법을 사용한다.
- 노이즈와 이상값은 특히 비정형 데이터에서 자주 발생
→ 데이터 특성에 맞는 정제 규칙을 수립하여 점검
① 삭제
- 오류 데이터에 대해 전체 혹은 부분 삭제를 통해 데이터 정제를 수행
- 무작위적인 삭제 → 데이터 활용의 문제 ∴ 주의를 요함
② 대체
- 오류 데이터를 평균값, 최빈값, 중간값으로 대체 하여 데이터 정제 수행
- 오류 데이터가 수집된 다른 데이터가 관계가 있는 경우 유용
그렇지 않을 경우 → 데이터 활용에 왜곡
③ 예측값 압입
- 회귀식 등을 이용한 예측값 생성, 삽입을 통하여 데이터 정제를 수행
- For 예측값 적용, 정상 데이터 구간에 대해서도 회귀식이 잘 성립되어야 한다.
3) 데이터 일관성 유지를 위한 정제 기법
다른 시스템으로부터 들어온 데이터에 대한 일관성 부여를 위해 정제 기법을 수행
| 정제 기법 | 설명 | 사례 |
|---|---|---|
| ① 변환 Conversion | 다양한 형태로 표현된 값을 일관된 형태로 변환하는 기법 | - 코드 변환(남/여 → M/F) - 형식 변환 (YYYYMMDD → YY/MM/DD) |
| ② 파싱 Parsing | 데이터를 정제 규칙에 적용하기 위한 유의미한 최소 단위로 분할하는 작업 | - 주민등록번호를 생년월일, 성별로 분류하는 작업 |
| ③ 보강 Enhancement | 변환, 파싱, 수정, 표준화 등을 통한 추가 정보를 반영하는 작업 | - 주민등록번호를 통해 성별을 추출한 후 추가 정보를 반영하는 방법 |
4) 데이터 세분화 Data Segmentation
데이터를 기준에 따라 나누고 선택한 매개변수를 기반으로 유사한 데이터를 그룹화 하여 효율적으로 사용할 수 있도록 사용하는 프로세스
① 계층적 방법
사전에 군집 수를 정하지 않고 단계적으로 단계별 군집 결과를 산출
a) 응집분석법
각 객체를 하나의 소집단으로 간주, 단계적으로 유사한 집단을 합쳐 새로운 소집단을 구성해가는 기법
b) 분할분석법
전체 집단으로부터 시작하여 유사성이 떨어지는 객체들을 분리해가는 기법
② 비계층적 방법
군집을 위한 소집단의 개수를 정해놓고 각 객체 중 하나의 소집단으로 배정하는 방법
a) 인공 신경망 모델
기계 학습에서 생물학의 신경망에서 영감을 얻은 통계학적 학습 모델
b) K-평균 군집화
K개의 소집단의 중심 좌표를 이용하여 각 객체와 중심 좌표 간 거리를 산출, 가장 근접한 소집단에 배정한 후 해당 소집단의 중심 좌표를 업데이트 하는 방식
2. 데이터 결측값 처리
1) 데이터 결측값의 종류
① 완전 무작위 결측 MCAR = Missing Completely At Random
- 변수 상 발생한 결측값이 다른 변수들과 아무런 상관이 없는 경우의 결측값
- 수입에서 결측 발생 시 응답자와 무응답자 간에 어떤 차이가 없다면 응답자의 수입에 관한 분포와 무응답자 수입에 관한 분포가 같음
② 무작위 결측 MAR = Missing At Random
- 무작위 결측은 누락된 자료가 특정 변수와 관련되어 일어나지만 그 변수의 결과는 관계가 없는 경우의 결측값이다.
- 누락이 전체 정보가 있는 변수로 설명이 될 수 있음을 의미
(누락이 완전히 설명될 수 있는 경우) 발생 - 남성은 우울증 설문 조사에 기재할 확률이 낮지만 우울함의 정도와는 상관이 없는 경우
③ 비무작위 결측 MANR = Missing Not At Random
- 누락된 결측값(변수의 결과)이 다른 변수와 연관이 있는 경우
- 이 값들이 통계에 영향을 주는 결측값
- 소득에 관한 무응답이 소득 자체와 관련(세금에 대한 정보가 주어졌더라도 소득이 높은 사람이 더 높은 무응답률을 보이는 경우)
2) 데이터 결측값 처리 절차
① 결측값 식별
- 원본 데이터에서 다양한 형태로 결측 정보가 표현 → 현황 파악
② 결측값 부호화
- 파악된 정보를 바탕으로 컴퓨터가 처리 가능한 형태로 부호화하는 단계
| 부호 | 설명 |
|---|---|
| NA (Not Available) | 기록되지 않은 값 |
| NaN (Not a Number) | 수학적으로 정의되지 않은 값 |
| inf (Infinite) | 무한대 |
| NULL | 값이 없음 |
③ 결측값 대체
- 결측값을 자료형에 맞춰 대체 알고리즘을 통해 결측값을 처리하는 단계
3) 데이터 처리 방법
데이터 결측값 처리 방법에는 단순 대치법(완전 분석법, 평균 대치법, 단순 확률 대치법)과 다중 대치법이 있다.
① 단순 대치법 Single Imputation
- 결측값을 그럴듯한 값으로 대체하는 통계적 기법
- 결측값을 가진 자료 분석에 사용하기 쉽고, 통계적 추론에서 사용된 통계량의 효율성 및 일치성 등의 문제를 부분적으로 보완
- 대체된 자료는 결측값 없이 완전한 형태를 지닌다.
- 단순 대치법은 완전 분석법, 평균 대치법, 단순 확률 대치법 등이 ㅣㅆ다.
a) 완전 분석법 Completes Analysis
- 불완전한 자료는 모두 무시하고 완전하게 관측된 자료만 사용하여 분석하는 방법
- 분석 Easy, 부분적으로 관측된 자료 무시 → 효율성 상실, 통계적 추론의 타당성 문제 발생
b) 평균 대치법 Mean Imputation
- 관측 혹은 실험되어 얻어진 자료의 평균값으로 결측값을 대치해서 불완전한 자료를 완전한 자료로 만드는 방법
- 대표적 방법 : 비 조건부 평균 대치법, 조건부 평균 대치법
c) 단순 확률 대치법 Single Stochastic Imputation
- 평균 대치법에서 관측된 자료를 토대로 추정된 통계량으로 결측치를 대치할 때, 어떤 적절한 확률값을 부여한 후 대치하는 방법
- 단순 확률 대치법의 종류 : 핫덱 대체, 콜드덱 대체, 혼합 방법
| 종류 | 설명 |
|---|---|
| 핫덱 Hot-Deck 대체 | - 무응답을 현재 진행 중인 연구에서 비슷한 성향을 가진 응답자의 자료로 대체 하는 방법 - 표본조사에서 흔히 사용된다. |
| 콜드덱 Cold-Deck 대체 | - 대체할 자료를 현재 진행 중인 연구에서 얻는 것이 아니라 외부 출처 혹은 이전의 비슷한 연구에서 가져오는 방법 |
| 혼합 방법 | - 몇 가지 다른 방법을 혼합하는 방법 - ex) 회귀 대체를 이용하여 예측값을 얻고, 핫덱 방법을 이용하여 잔차를 얻어 두 값을 더하는 경우 |
② 다중 대치법 Multiple Imputation
- 단순 대치법을 한 번 사용하지 않고 m 번 대치를 통해 m개의 가상적인 완전한 자료를 만들어서 분석하는 방법
- 여러 번의 대체표본으로 대체 내 분산과 대체 간 분산 구함
→ 추정치의 총 분산을 추정하는 방법 - 대치 → 분석 → 결합의 3 단계로 구성
a) 다중대치법의 적용 방식
- 다중 대치 방법은 원 표번의 결측값을 한 번 이상 대치하여 여러 개(D≥2)의 대치된 표본을 구하는 방법
- D 개의 대치된 표본을 만들어야 함 → 항상 같은 값으로 결측 자료를 대치할 수 없다.
| 적용방식 | 설명 |
|---|---|
| ① 대치 | - 각 대치 표본은 결측 자료의 예측 분포 혹은 사후 분포 에서 추출된 값으로 결측값을 대치하는 방법 활용 - 다중 대치 방법은 베이지안 방법 사용 |
| ② 분석 | - 같은 에측 분포로부터 대치 값을 구하여 D개의 대치 표본을 구하게 되면 이 D개의 대치 표본으로부터 원하는 분석을 각각 수행함 |
| ③ 결합 | - 모수 Θ 의 점추정과 표준 오차의 추정치를 D개 구한 후 이들을 결합한 후 하나의 결과를 제시 |
3. 데이터 이상값 처리
- 데이터 이상값은 관측된 데이터의 범위에서 많이 벗어난 아주 작은 값이나 아주 큰 값
- 데이터 이상값은 입력 오류, 데이터 처리 오류 등의 이유로 특정 범위에서 벗어난 데이터 값을 의미한다.
1) 데이터 이상값 발생 원인
① 표본추출 오류 Sampling Error
- 데이터를 샘플링하는 과정 에서 나타나는 오류
- 데이터 샘플링을 잘못한 경우의 오류
- ex) 대학 신입생들의 키를 조사하기 위해 샘플링하는데 농구 선수가 포함되었다면 농구 선수의 키는 이상값이 될 수 있음
② 고의적인 이상값 Intentional Outlier
- 고의적인 이상값은 자기 보고식 측정 Self Reported Measures 에 나타나는 오류
- 정확하게 기입한 값이 이상값으로 부일 수 있다
- ex) 음주량을 묻는 조사가 있다고 가정할 때 10대 대부분은 자신들의 음주량을 적게 기입할 것이고 오직 일부만 정확한 값을 적는 경우 발생
③ 데이터 입력 오류 Data Entry Error
- 데이터 입력 오류는 데이터를 수집, 기록 혹은 입력하는 과정에서 발생할 수 있는 인간의 실수로 인한 오류
- 전체 데이터 분포를 보면 쉽게 발견할 수 있다.
- ex) 100을 입력해야 하는데 1000을 입력하면 10배의 값으로 입력
④ 실험 오류 Experimental Error
- 실험 조건이 동일하지 않은 경우 발생
- ex) 100 m 달리기를 하는데 한 선수가 출발 신호를 못 듣고 출발했다면 그 선수의 기록은 다른 선수들 보다 늦을 것이고 그의 경기 시간은 이상값이 될 수 있다.
⑤ 측정 오류 Measurement Error
- 데이터를 측정하는 과정에서 발생하는 오류
- ex) 몸무게를 측정하는데 9개의 체중계는 정상 작동, 1개는 비정상 작동을 한다고 가정했을 때 한 사용자가 비정상적으로 작동하는 체중계를 이용할 경우 에러 발생
⑥ 데이터 처리 오류 Data Processing Error
- 데이터 마이닝을 할 때, 여러 개의 데이터에서 필요한 데이터를 추출하거나 조합해서 사용하는 경우 발생하는 오류
⑦ 자연 오류 Natural Error
- 인위적이 아닌, 자연스럽게 발생하는 이상값
- 데이터 마이닝을 하는 경우 작게 분리해서 처리해야 한다.
2) 데이터 이상값 검출
① 통계 기법을 이용한 데이터 이상값 검출
a) ESD(Extreme Studentized Deviation)을 이용한 방법
- 평균 으로부터 3 표준편차 떨어진 값(각 0.15%)을 이상값으로 판단하여 검출하는 기법
b) 기하 평균을 활용한 방법
- 기하 평균을 활용한 방법은 기하 평균으로부터 2.5 표준편차σ 떨어진 값을 이상값으로 판단하는 기법
c) 사분위수를 이용한 방법
- 제 1사분위, 제 3사분위를 기준으로 사분위 간 범위()의 1.5배 한 값과 떨어진 위치를 이상값으로 판단하는 기법이다.
d) 표준화 점수(Z-score)를 이용한 방법
- 평균이 이고 표준편차가 인 정규분포를 따르는 관측치들이 자료의 중심(평균)에서 얼마나 많이 떨어져 있는지를 파악해서 이상값을 검출하는 방법
e) 딕슨의 Q 검정 (Dixon Q-Test)
- 오름차순으로 정렬된 데이터에서 범위에 대한 관측치 간의 차이에 대한 비율을 활용하여 이상값 여부를 검정하는 방법
- 데이터의 수가 30개 미만인 경우 적절
f) 그럽스의 T 검정 (Grubbs T-Test)
- 정규분포를 만족하는 다변량 자료에서 이상값을 검정하는 방법
g) 카이제곱 검정 (Chi-Square Test)
- 데이터가 정규분포를 만족하나 자료의 수가 작은 경우에 이상값을 검정하는 방법
h) 마할라노비스 거리 (Mahalanobis Distance)
- 데이터의 분포를 고려한 거리 측도로 관측치가 평균으로부터 벗어난 정도를 측정하는 통계량 기법
- 데이터의 분포를 측정할 수 있는 마할라노비스 거리를 이용하여 평균으로부터 벗어난 이상값을 검출할 수 있다.
- 이상값 탐색을 위해 고려되는 모든 변수 간에 선형 관계를 만족하고 각 변수들이 정규분포를 따르는 경우에 적용할 수 있는 전통적인 접근법
② 시각화를 이용한 데이터 이상값 검출
| 검출기법 | 그래프 | 설명 |
|---|---|---|
| 확률밀도함수 | 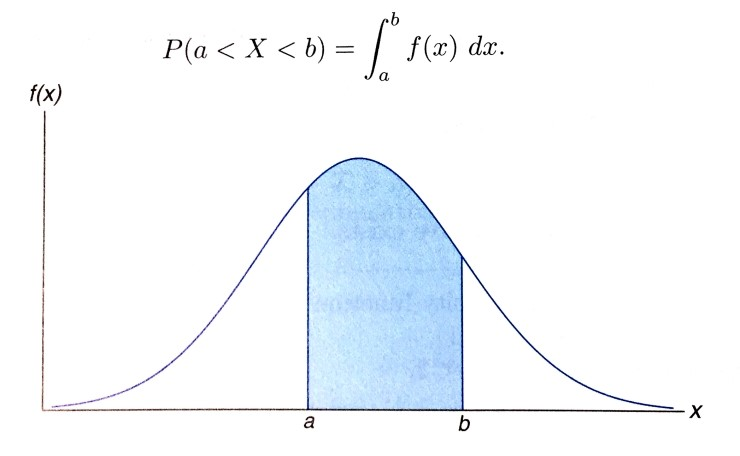 | 확률 변수의 분포를 보여주는 함수 |
| 히스토그램 | 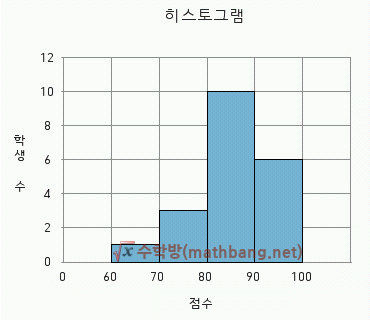 | 주로 x축에 계급 값을, y축에 각 계급에 해당하는 자료의 수치를 표시 |
| 시계열차트 | 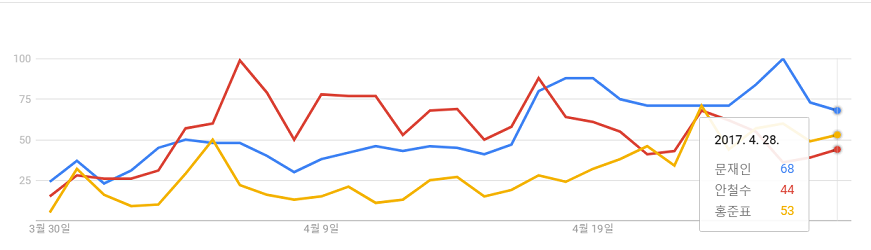 | 시간에 따른 자료의 변화나 추세를 보여주는 그래프 |
③ 군집 / 분류를 이용한 데이터 이상값 검출
a) k-평균 군집화
- 주어진 데이터를 k개의 클러스터로 묶는 군집 방법으로 각 클러스터와의 거리 차이의 분산을 최소화하는 방식의 군집 방법
b) LOF = Local Outlier Factor
- LOF 는 관측치 주변의 밀도와 근접한 관측치 주변의 밀도의 상대적인 비교를 통해 이상값을 탐색하는 기법이다
- LOF ↑ → 이상값 정도 ↑
c) iForest = Isolation Forest
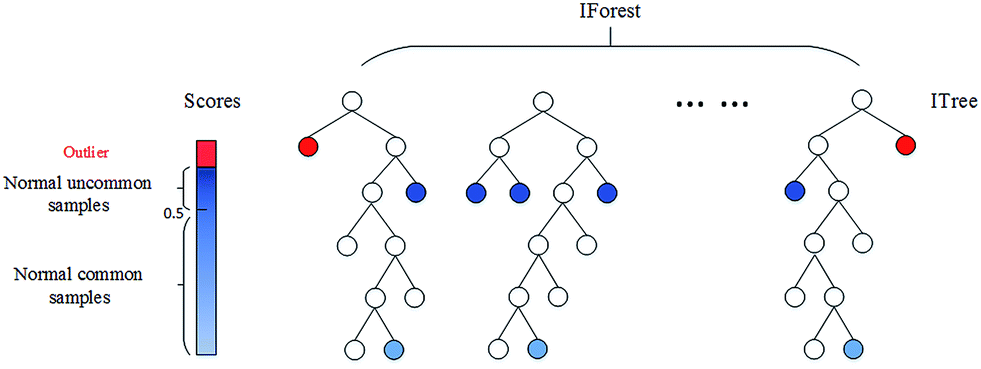
- 관측치 사이의 거리 혹은 밀도에 의존하지 않고 데이터마이닝 기법인 의사결정 나무를 이용하여 이상값을 탐지하는 방법
- 의사결정나무 기법으로 분류 모형을 생성하여 모든 관측치를 고립시켜나가면서 분할 횟수로 이상값을 탐지
- 데이터의 평균적인 관측치와 멀리 떨어진 관측치일수록 적은 횟수의 공간 분할을 통해 고립시킬 수 있다.
- 의사결정나무 모형에서 적은 횟수로 잎 Leaf 노드에 도달하는 관측치일수록 이상값일 확률이 높다.

공부