1. 변수 선택
1) 변수 Feature
- 데이터 모델에서 사용하는 예측을 수행하는데 사용되는 입력 변수
- 머신러닝에서는 RDBMS에서 속성(열)이라 부르는 것을 통계학의 영향으로 변수 Feature 라고 한다.
(1) 범주형 Categorical
조사 대상을 특성에 따라 범주로 구분하여 측정된 변수
① 명목형 Norminal
- 명칭으로 변수나 변수의 크기가 순서와 상관 없고 의미 없이 이름만 의미를 부여할 수 있는 경우
② 순서형 Norminal
- 변수가 어떤 기준에 따라 순서에 의미를 부여할 수 있는 경우
(2) 수치형 Measure
몇 개인가를 세어 측정하거나 측정 길이, 무게와 같이 양적인 수치로 측정되는 변수
① 이산형 Discrete
- 변수가 취할 수 있는 값을 하나하나 셀 수 있는 경우
② 연속형 Continuous
- 변수가 구간 안의 모든 값을 가질 수 있는 경우
2) 변수 선택 Feature Selection
- 데이터의 독립변수(x) 중 종속변수(y)에 가장 관련성이 높은 변수 Feature 만을 선정하는 방법
- 변수 선택은 사용자가 해석하기 쉽게 모델을 단순화 + 훈련 시간 축소 + 차원의 저주 방지 + 과적합을 줄임 → 일반화
- 변수를 선택하면 모델의 정확도 향상 및 성능 향상을 기대할 수 있다.
- 변수 선택은 예측 대상이 되는 분류를 참고하지 않고 변수들로만 수행하는 비지도 학습 방식 과 분류를 참고하여 변수를 선택하는 지도 학습 방식으로 분류할 수 있다.
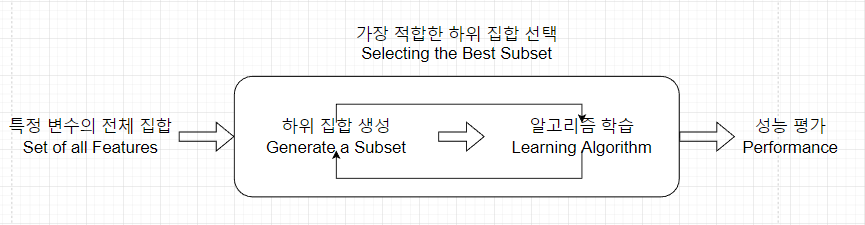
(1) 필터 기법 Filter Method
특정 모델링 기법에 의존하지 않고 데이터의 통계적 특성으로부터 변수를 선택하는 기법
| 순서 | 설명 |
|---|---|
| 1 | 특징 변수의 전체 집합 Set of all Features |
| 2 | 가장 적합한 하위 집합 선택 Selecting the best subset |
| 3 | 알고리즘 학습 Learning Algorithm |
| 4 | 성능 평가 Performance |
- 데이터의 통계적 측정방법을 사용하여 변수 Feature들의 상관관계를 알아낸다
① 정보 소득 Information Gain
- 가장 정보 소득이 높은 속성을 선택하여 데이터를 더 잘 구분할 수 있게 하는 방법
- 정보 이득, 정보 이득량, 정보 소득, 정보 증가량 등으로 다양하게 불림
② 카이제곱 검정 Chi-Squre Test
- 카이제곱 분포에 기초한 통께적 방법
- 관찰된 빈도가 기대되는 빈도와 의미있게 다른지 여부를 검증하기 위해 사용되는 기법
③ 피셔 스코어 Fisher Score
- 최대 가능성 방정식을 풀기 위해 통계에서 사용되는 뉴턴의 방법
④ 상관 계수 Correlation Coefficient
- 두 변수 사이의 통계적 관계를 표현하기 위해 특정한 상관관계의 정도를 수치적으로 나타낸 계수
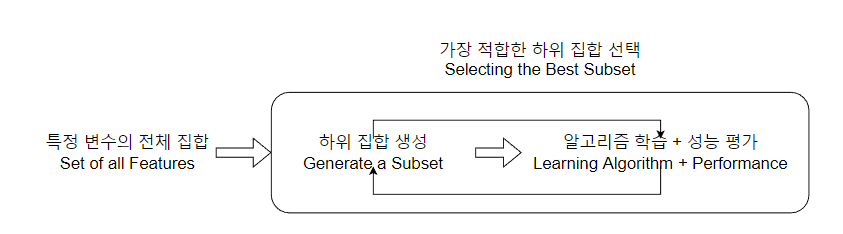
(2) 래퍼 기법 Wrapper Method = 그리디 알고리즘
변수의 일부만을 모델링에 사용하고 그 결과를 확인하는 작업을 반복하면서 변수를 선택하는 기법
- 검색 가능한 방법으로 하위 집합을 반복해서 선택하여 테스트하는 것 ; 그리디 알고리즘에 속한다.
- 반복해서 선택하는 방법 → 시간이 오래 걸림 + 부분 집합 수가 기하급수적으로 늘어
∴ 과적합의 위험 발생 可
① 변수 선택을 위한 알고리즘 유형
| 기법 | 설명 |
|---|---|
| a) 전진 선택법 Forward Selection | - 모형을 가장 많이 향상시키는 변수를 하나씩 점진적으로 추가하는 방법 - 비어있는 상태에서 시작, 변수 추가 시 선택기준이 향상되지 않으면 변수 추가를 중단 |
| b) 후진 소거법 Backward Elimination | - 모두 포함된 상태에서 시작, 가장 적게 영향을 주는 변수부터 하나씩 제거 - 더 이상 제가할 변수가 없다고 판단될 때 변수의 제거 중단 |
| c) 단계적 방법 Stepwise Method | - 전진 선택과 후진 소거를 함께 사용하는 방법 |
② 래퍼 기법
| 기법 | 설명 |
|---|---|
| RFE = Recursive Feature Elimination | - 서포트 벡터 머신을 사용하여 재귀적으로 제거하는 방법 - 전진선택, 후진소거, 단계별 선택법을 사용 |
| SFS = Sequential Feature Selection | - 그리디 알고리즘으로 빈 부분집합에서 특성 변수를 하나씩 추가하는 기법 |
| 유전 알고리즘 Genetic Algorithm | - 존 홀랜드에 의하 1975년에 개발된 전역 최적화 기법으로 최적화 문제를 해결하는 기법 - 자연 세계의 진화 과정에 기초한 계산 모델 |
| 다변량 선택 Univariate Selection | - 하나의 변수 선택법으로 각 피처를 개별적으로 검사하여 피처와 반응변수 간의 관ㄱ계의 강도를 결정하는 기법 - 실행 및 이해가 간단하며 일반적으로 데이터에 대한 이해를 높일 때 사용 |
| mRMR = Maximum Redundancy Maximum Relevance | - 특성 변수의 중복성을 최소화 하는 방법 - 종속 변수를 잘 예측하면서 독립 변수들과도 중복성이 적은 변수들을 선택하는 기법 |
② 임베디드 기법 Embeded Method
모델 자체에 변수 선택이 포함된 기법
- 모델의 정확도에 기여하는 변수를 학습
- 좀 더 적은 계수를 가지는 회귀식을 찾는 방향으로 제약조건을 주어 이를 제어한다
a) 라쏘 LASSO = Least Absolute Shrinkage and Selection Operator
- 가중치의 절대값의 합을 최소화하는 것을 추가적인 제약조건으로 하는 방법
- L1-norm을 통해 제약을 주는 방법 ; 벡터의 각 원소들의 차이의 절대값의 합
b) 릿지 Ridge
- 가중치들의 제곱 합을 통해 최소화하는 것을 추가적인 제약조건으로 하는 방법
- L2-norm 을 통해 제약 ; 두 벡터의 유클리디안 거리(직선거리)
c) 엘라스틱 넷 Elastic Net
- 가중치 절대값의 합과 제곱 합을 동시에 추가적인 제약조건으로 하는 방법
- 라쏘와 릿지 두 개를 선형 결합한 방법
d) SelectFromModel
- 의사결정나무 기반 알고리즘에서 피처 추출
2. 차원 축소 Demensionality Reduction
- 분석 대상이 되는 여러 변수의 정보를 최대한 유지하면서 데이터 세트 변수의 개수를 줄이는 탐색적 분석 기법
- 원래의 데이터를 최대한 효과적으로 축약하기 위해 목표 변수(y) 는 사용하지 않고 특성 변수(설명 변수)만 사용
→ 비지도 학습 머신 러닝 기법
1) 주성분 분석 PCA = Principal Component Analysis
- 원래의 데이터 세트의 변수들을 선형 변환하여 서로 직교하도록 선택된 새로운 변수들을 생성, 이를 통해 서로 연관 가능성 있는 고차원 공간의 표본들을 선형 연관성이 없는 저차원 공간(주성분)의 표본으로 차원을 추고하는 기법
- By 차원의 단순화 → 서로 상관된 변수 간의 복잡한 구조를 분석하는 것을 목적으로 함
- 변수들의 공분산 행렬이나 상관 행렬 이용
- 행의 수와 열의 수가 같은 정방행렬에서만 사용
2) 특이값 분해 SVD = Singular Value Decomposition
- MxN 차원의 행렬 데이터에서 특이값을 추출하고 이를 통해 주어진 데이터 세트를 효과적으로 축약할 수 있는 기법
3) 요인 분석 Factor Analysis
- 모형을 세운 뒤 관찰 가능한 데이터를 이용하여 해당 잠재 요인을 도출하고 데이터 안의 구조를 해석하는 기법
- 데이터 안에 관찰할 수 없는 잠재적 변수 Latent Variable 가 존재한다고 가정
- 주로 사회과학이나 설문 조사 등에서 많이 활용
4) 독립 성분 분석 ICA = Independent Component Analysis
- 주성분 분석과 달리 다변량의 신호를 통계적으로 독립적인 하부 성분으로 분리, 차원을 축소하는 기법
- 비정규분포를 따르게 되는 차원 축소 기법
5) 다차원 척도법 MDS = Multi-Dimensional Scaling
- 개체들 사이의 유사성, 비유사성을 측정 → 2차원 혹은 3차원 공간 상에 점으로 표현 → 개체들 사이의 집단화를 시각적으로 표현하는 분석 방법
3. 파생 변수 생성 및 변환
1) 파생 변수 Derived Variable
기존 변수에 특정 조건 혹은 함수 등을 사용하여 새롭게 정의한 변수
- 데이터에 들어있는 변수만을 이용해서 분석할 수도 있으나 변술를 조합하거나 함수를 적용해서 새 변수를 만들어 분석
- 변수를 생성할 때는 논리적 타당성과 기준을 가지고 생성
2) 변수 변환 Variable Transformation
- 분석을 위해 불필요한 변수는 제거하고 변수를 반환하며 새로운 변수를 생성시키는 작업
- 선형 관계가 아닌 로그, 제곱, 지수 등의 모습을 보일 때 변수 변환을 통해 선형 관계로 만들면 분석하기 쉽다
(1) 단순 기능 변환 Simple Functions
- 한 쪽으로 치우친 변수를 변환하여 분석 모형을 적합하게 만드는 방법
- 변수를 단순한 함수로 변환하는 기능
① 로그 Logarithm
- 변수의 분포를 변경하기 위해 사용하는 변환 방법
- 변수들의 분포가 오른쪽으로 기울어진 것을 감소
- log 특성상 0과 음수 값은 적용 불가
② 제곱 / 세제곱 루트 변환 Square / Cube Root
- 로그에 비해서 많이 사용되지 않은 방법
- 세제곱 루트 변환은 음수와 0의 값에 적용 가능
- 제곱 루트 변환은 0을 포함한 양수 값이 가능
(2) 비닝 Binning
- 기존 데이터를 범주화하기 위해 사용하는 기법
- 비닝은 데이터 값은 몇 개의 Bin (혹은 Bucket) 으로 분할하여 계산하는 방법
- 데이터 평활화에도 사용되는 기술이며 기존 데이터를 범주화 하기 위해서도 사용
- 두 개 이상 변수 값에 따라 공변량 비닝 Co-variate Binning 을 수행한다.
(3) 정규화 Normalization
- 정규화는 데이터를 특정 구간으로 바꾸는 척도법
- 최소 최대 정규화, z-score 정규화 유형이 있다.
- 최소-최대 정규화 :
(4) 표준화 Standardization
- 0을 중심으로 양 쪽으로 데이터를 분포시키는 방법
- 표준화와 정규화는 데이터 전처리에서 상호 교환하여 사용
- z-score 정규화 :
4. 불균형 데이터 처리
- 탐생하는 타깃 데이터 수가 매우 극소수인 경우에 불균형 데이터 처리를 한다.
- 불균형 데이터 처리 기법 :
언더 샘플링, 오버 샘플링, 임계값 이동 Cut-off Value Moving, 앙상블 Ensenble
1) 과소 표집 Under-sampling = Down-sampling
- 다수의 클래스의 데이터를 일부만 선택하여 데이터의 비율을 맞추는 방법
- 데이터 소실이 매우 크고 때로는 중요한 정상 데이터를 잃을 수 있다.
- 과소 표집의 대표적 기법 :
랜덤 과소 표집, ENN, 토멕 링크 방법, CNN, OSS
| 기법 | 설명 |
|---|---|
| (1) 랜덤 과소 표집 Random Under-Sampling | 무작위로 다수 클래스의 데이터의 일부만 선택하는 방법 |
| (2) ENN = Edited Nearest Neighbor | 소수 클래스 주위에 인접한 다수 클래스 데이터를 제거하여 데이터 비율을 맞추는 방법 |
| (3) 토맥 링크 방법 Tomek Link Method | - 토멕 링크 Tomek Link = 클래스를 구분하는 경계선 가까이에 존재하는 데이터 - 토멕 링크 방법은 다수 클래스에 속한 토멕 링크를 제거하는 방법 |
| (4) CNN = Condensed Nearest Neighbor | 다수 클래스에 밀집된 데이터가 없을 때까지 데이터를 제거하여 데이터 분포에서 대표적 데이텀만 남도록 하는 방법 |
| (5) OSS = One Sided Selection | - 토멕 링크 방법과 CNN 기법의 장점을 섞은 방법 - 다수 클래스의 데이터를 토멕 링크 방법으로 제거한 후 CNN을 이용하여 밀집된 데이터를 제거한다. |
2) 과대 표집 Over-sampling = Up-sampling
- 과대 표집은 소수 클래스의 데이터를 복제 혹은 생성하여 데이터의 비율을 맞추는 방식
- 정보가 손실되지 않는다는 장점이 있으나 과적합 Over-Fitting 을 초래할 수 있다.
- 알고리즘의 성능은 높으나 검증의 성능은 나빠질 수 있다.
- 과대 표집의 대표적 기법:
랜덤 과대 표집, SMOTE, Borderline-SMOTE, ADASYN 등
| 기법 | 설명 |
|---|---|
| (1) 랜덤 과대 표집 Random Over-Sampling | 무작위로 소수 클래스의 데이터를 복제하여 데이터릐 비율을 맞추는 방식 |
| (2) SMOTE = Synthetic Minority Over-samppling TEchnique | SMOTE 는 소수 클래스에서 중심이 되는 데이터와 주변 데이터 사이에 가상의 직선을 만든 후 그 위에 데이터를 추가하는 방법 |
| (3) Borderline-SMOTE | SMOTE에서 다른 클래스의 데이터 영역까지 데이터 생성 분포를 확장한 방법 |
| (4) ADASYM = ADAptive SYNthetic Sampling Approach | 모든 소스 클래스에서 다수 클래스의 관칙 비율을 계산하여 SMOTE를 적용하는 방법 |
3) 임계값 이동 Cutt-Off Value Moving
- 임곗값을 데이터가 많은 쪽으로 이동시키는 방법
- 학습 단계에서 변화 없이 학습하고 테스트 단계에서 임곗값을 이동
4) 앙상블 기법 Ensenble
- 서로 같거나 서로 다른 여러가지 모형들의 예측 / 분류 결과를 종합하여 최종적인 의사결정에 활용하는 기법
- 과소 표집, 과대 표집, 임곗값 이동을 조합한 앙상블을 만들 수 있다.
- 앙상블 예측 중 가장 많은 표를 받은 클래스를 최종적으로 선택

공부