
스타벅스와 이디야커피의 관계 분석
문제 1 스타벅스 데이터 크롤링하기
driver = webdriver.Chrome('driver/chromedriver.exe')
driver.get('https://www.starbucks.co.kr/store/store_map.do')
driver.find_element(By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search > h3 > a').click()
driver.find_element(By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a').click()
driver.find_element(By.CSS_SELECTOR, '#mCSB_2_container > ul > li:nth-child(1) > a').click()
content = driver.page_source웹 드라이버를 사용하여 스타벅스 홈페이지의 매장 위치 정보가 있는 곳으로 가서 데이터를 전부 크롤링 해줍니다.
# BeautifulSoup을 사용하여 파싱
soup = BeautifulSoup(content, 'html.parser')BeautifulSoup으로 태그별로 값을 읽어 올수있게하고 매장명, 위도, 경도, 구, 주소 값을 불러와 줍니다. 스타벅스는 홈페이지에서 위도 경도 값도 제공 하므로 구글맵을 사용하지 않아도 되었다!!
# 주의 진행하는곳 위치 정보에 따라서 파라메터값 바꿔줘야함
address = soup.select('.result_details')[2].contents[0].text
dress = soup.find_all('p', class_ = 'result_details')
# 주의 진행하는곳 위치 정보에 따라서 파라메터값 바꿔줘야함
adr = soup.find_all('p', class_ = 'result_details')[2].text
tam = re.split(' ', adr)
tam[:4]
address = tam[0]+ ' ' + tam[1] + ' ' + tam[2] + ' ' + tam[3]스타벅스 데이터에서 가장 처리가 난해 하였던 것은 주소 데이터인데 find로 찾아오면 re 라이브러리로 복잡한 처리가 필요하여 저와 같은 경우 select 기능으로 데이터를 불러온 뒤 split으로 다시 붙이는 식으로 하여 tam[4]의 전화번호 부분을 제외하고 불러올수 있게 하였습니다.
# 홈페이지를 크롤링함
content = driver.page_source
# bs4를 사용하여 파싱
soup = BeautifulSoup(content, 'html.parser')
# for문 범위 설정용
dress = soup.find_all('p', class_ = 'result_details')
len(dress)
# 데이터 프레임 만들기 위한 컬럼 만들기
title = []
address = []
gu = []
lat = []
lng = []
for i in tqdm(range(2, len(dress))):
title.append(soup.find_all('li', class_ = 'quickResultLstCon')[i].get('data-name'))
lat.append(soup.find_all('li', class_ = 'quickResultLstCon')[i].get('data-lat'))
lng.append(soup.find_all('li', class_ = 'quickResultLstCon')[i].get('data-long'))
adr = soup.select('.result_details')[i].contents[0].text
tam = re.split(' ', adr)
dress = tam[0]+ ' ' + tam[1] + ' ' + tam[2] + ' ' + tam[3]
address.append(dress)
gu.append(tam[1])위 코드는 for문을 이용하여 스벅데이터를 한번에 크롤링하는 코드입니다
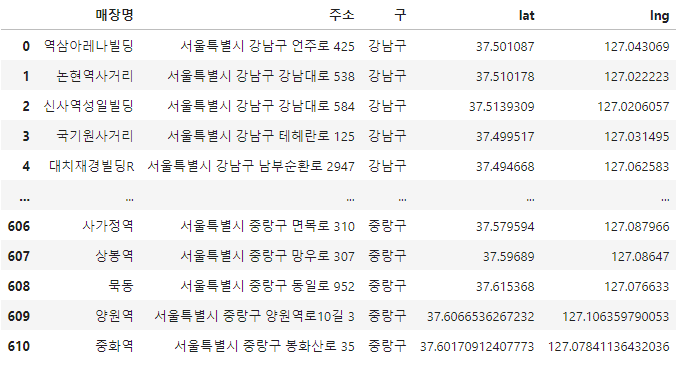
스타벅스 데이터프레임
문제 2 이디야 커피 데이터 크롤링하기
driver = webdriver.Chrome('driver/chromedriver.exe')
driver.get('https://ediya.com/contents/find_store.html')
driver.find_element(By.CSS_SELECTOR, '#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a').click()
keyword = driver.find_element(By.CSS_SELECTOR, '#keyword')
keyword.clear()
keyword.send_keys('xx구')
driver.find_element(By.CSS_SELECTOR, '#keyword_div > form > button').click()이디야 커피는 스타벅스와 달리 서울 전체의 매장 데이터를 불러올수가 없어서 서울 내의 구에대해서 한번씩 반복을 해야 했습니다.
content = driver.page_source
soup = BeautifulSoup(content, 'html.parser')
soup.find_all('dl')강북구를 예시로 홈페이지 데이터를 확인해 보았는데
<dt>매장주소</dt>
<dd>서울특별시 강남구 논현로 636</dd>
</dl>,
<dl>
<dt>전화번호</dt>
<dd>02-545-6467</dd>
</dl>,
<dl>
<dt>영업시간</dt>
<dd>평일 운영시간: 01:30~02:00<br/>주말 및 공휴일에는 변경될 수 있습니다.</dd>
</dl>,
<dl class="line">
<dt>매장위치</dt>
<dd>강남 논현동 221-17 이디야 빌딩에 위치. 9호선 언주역 3번 출구 도보 6분, 7호선 학동 3번 출구 도보 8분</dd>
</dl>,
<dl><dt>가오리역점</dt> <dd>서울 강북구 삼각산로 108 (수유동)</dd></dl>,
<dl><dt>광산사거리점</dt> <dd>서울 강북구 노해로 91 (수유동, 진흥빌딩)</dd></dl>,
<dl><dt>미아꿈의숲해링턴점</dt> <dd>서울 강북구 오현로 45 (미아동, 꿈의숲 해링턴 플레이스)</dd></dl>,
<dl><dt>미아역점</dt> <dd>서울 강북구 도봉로 207 -3(미아동)</dd></dl>,다음과 같이 이디야 커피는 강남 논현동에 있는 매장이 디폴트로 4개의 dl 태그를 가지는데 따라서 이디야커피의 데이터를 크롤링하기위해서는 [4]부터 크롤링 해야합니다.

위도 경도 데이터를 가져올려고 하면 다음과 같은 데이터를 가지게 되는데
# 위도 경도
t = soup.select('#placesList > li')[5].find('a').get('onclick')
place = re.search(r"(\d+\.\d+)',\s*'(\d+\.\d+)", t)
lat = place.group(1)
lng = place.group(2)
lat, lng다음과 같이 a태그 내부에서 onclick 값을 가져오고 re 라이브러리로 숫자 부분만 가져옵니다. 하지만 여기서 문제가 생기는데....
이디야커피는 위치정보가 반정도 비어있어 위 코드 그대로 돌리면 오류가 생깁니다. 따라서 if문으로 데이터가 없을때는 패스 하도록 짜줍니다.
# 데이터 프레임 만들기 위한 컬럼 만들기
ediya_title = []
ediya_address = []
ediya_gu = []
ediya_lat = []
ediya_lng = []
col = ['강남구', '강북구', '강서구', '관악구', '광진구', '금천구', '노원구', '도봉구', '동작구', '마포구', '서대문구', '서초구', '성북구',
'송파구', '양천구', '영등포구', '은평구', '종로구', '서울 중구', '강동구', '구로구', '동대문구', '성동구', '용산구', '중랑구', '123']
for i in col:
keyword = driver.find_element(By.CSS_SELECTOR, '#keyword')
keyword.clear()
keyword.send_keys(i)
driver.find_element(By.CSS_SELECTOR, '#keyword_div > form > button').click()
content = driver.page_source
# bs4를 사용하여 파싱
soup = BeautifulSoup(content, 'html.parser')
# for문 범위 설정용
ad = soup.find_all('dl')
ad
for i in tqdm(range(0, len(ad)-5)):
# 지점명, 주소
ediya_title.append(soup.find_all('dl')[i+4].find('dt').text)
ediya_address.append(soup.find_all('dl')[i+4].find('dd').text)
# 구
idya = soup.find_all('dl')[i+4].find('dd').text
gu2 = re.split(' ', idya)
ediya_gu.append(gu2[1])
# 위도 경도
t = soup.select('#placesList > li')[i].find('a').get('onclick')
place = re.search(r"(\d+\.\d+)',\s*'(\d+\.\d+)", t)
if place == None:
ediya_lat.append(0)
ediya_lng.append(0)
else:
lng = place.group(1)
lat = place.group(2)
ediya_lng.append(lng)
ediya_lat.append(lat)위 코드는 for문을 이용하여 이디야 커피 데이터를 한번에 크롤링하는 코드입니다

빈 값을 제외하고 불러 왔으니 이제 google map 라이브러리를 사용하여 빈 위도, 경도 값을 채워줍니다.
for idx, rows in tqdm(ediya_df[ediya_df['lat'] == 0].iterrows()):
station_name = rows.주소
# print(station_name)
tmp = gmaps.geocode(station_name, language='ko')
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
# print(lat)
ediya_df.loc[idx, 'lat'] = lat
ediya_df.loc[idx, 'lng'] = lng
구글 맵에 이디야 커피의 위도 데이터가 빈 곳만 찾아서 구글맵에 넣어 위도, 경도 값을 채워 넣어 줍니다.
3. 시각화
스타벅스 데이터프레임

이디야 커피 데이터프레임

스타벅스와 이디야 커피의 데이터 시각화
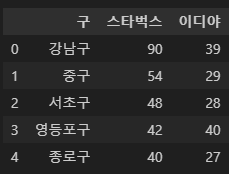
각 구별 스타벅스와 이디야 커피 매장 수의 데이터프레임
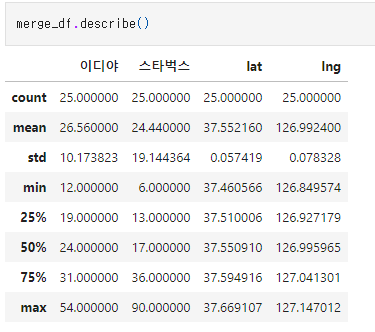
매장수의 디스크라이브 데이터
바 차트를 이용한 매장수 비교
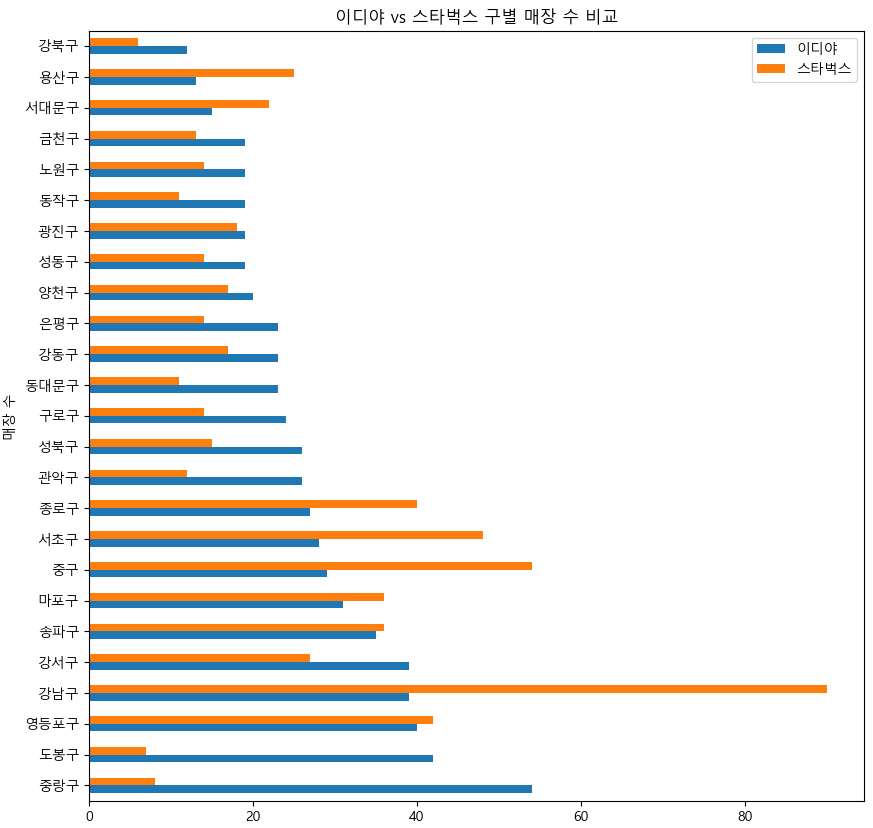
각 구별 매장수 시각화
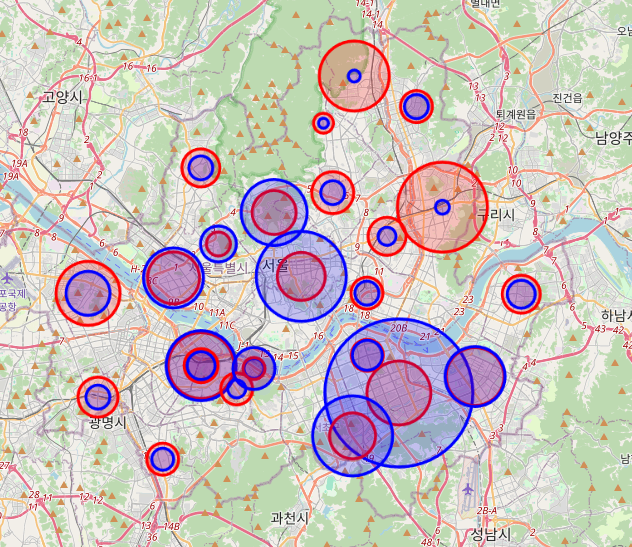
해당 데이터들을 사용하여 결론을 내보면 이디야 커피는 대체로 전국에 균일하게 분포하였으나 스타벅스는 회사가 많거나 유동인구가 많은곳에 분포 한것으로 보인다.
따라서 스타벅스 옆에 이디야 커피 매장이 많은것이 아닌 이디야 커피의 매장수가 전국에 많다 보니 우연히 스타벅스 옆에 매장이 생긴것이 아닐까 하는 생각을 해봅니다.
결론 : 스벅과 이디야커피 매장의 위치 관계는 없다!
전채코드
