
문제 1 DataFrame 불러오기 & 전처리
- 인덱스값을 정리하기
- 컬럼명 변경하기
- thousands=',' read_csv에 붙이기
1번문제 한줄요약 그림과 같은 데이터프레임을 분석하기 좋게 전처리 하기!

문제를 풀라고 주신 데이터가 txt 파일이라서 어떻게 해야하나 고민을 살짝했다. read_txt(?) 라는 기능이라도 있는건가 라는 고민을 하지만 구글링 결과 txt 파일도 read_csv로 해결할수있다는 사실을 알고 바로 실행
df = pd.read_csv('datas/report.txt', sep = "\t", engine='python', encoding = 'utf-8', header=2, thousands=',')
df.head()문제 2 원하는 정보 얻기
- 딕셔너리 정리하기(?)
- 피벗테이블 만들기
- 데이터프레임 연산 및 정렬
- 상관계수 구하기
region_dict = {'도심권': ['종로구', '중구', '용산구'],
'동북권': ['성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구', '도봉구', '노원구'],
'서북권': ['은평구', '서대문구', '마포구'],
'서남권': ['양천구', '강서구', '구로구', '금천구', '영등포구', '동작구', '관악구'],
'동남권': ['서초구', '강남구', '송파구', '강동구']
}개인적으로 이번 문제의 하이라이트를 뽑으라면 2-1번을 뽑을것 같다. 위의 딕셔너리를
col1 = []
col2 = []
for key, value in region_dict.items():
for i in value:
col1.append(key)
col2.append(i)
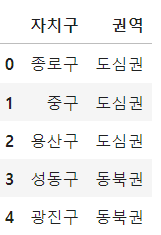
col1[:5], col2[:5]위 그림과 같은 {자치구 : 권역}의 형태로 만들어야 하는데 저와 같은 경우 중첩 for문을 돌려 col1, col2 리스트를 생성하여 딕셔너리의 key값을 가져올 때 마다 col1에 append하며 value은 col2에 append하도록 처리하였습니다.
df3 = pd.DataFrame(data= {'자치구' : col2, '권역': col1})
df3.head()이제 위에서 만든 리스트를 이용하여 데이터 프레임을 만들어 줍니다. 이것을 1번에서 만든 데이터프레임과 합친 후 권역을 기준으로 피벗테이블로 정리해줍니다.
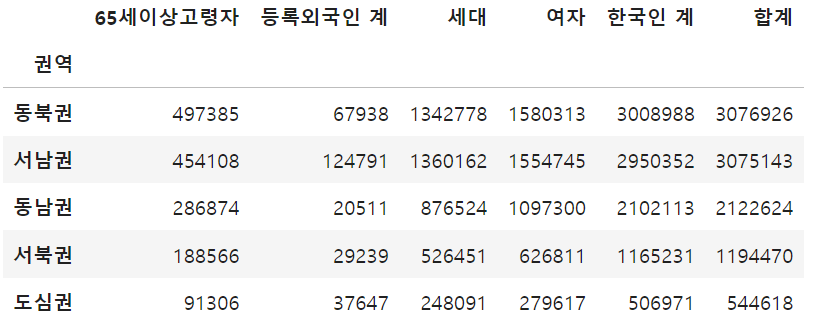
시각화를 용이하게 하기위해 비율을 구해줍니다.
df4['고령자비율'] = df4['65세이상고령자'] / df4['합계'] * 100
df4['외국인비율'] = df4['등록외국인 계'] / df4['합계'] * 100
df4['여성비율'] = df4['여자'] / df4['합계'] * 100 
이제 위에서 구한 비율들을 .corr()를 이용하여 상관관계를 구해줍니다.
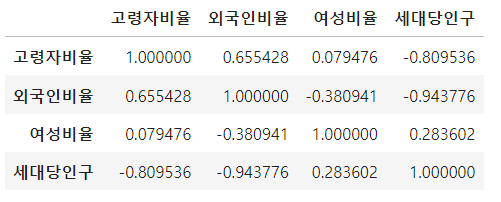
문제 3 시각화
- barh plt
- pie plot
- boxplot
- lmplot
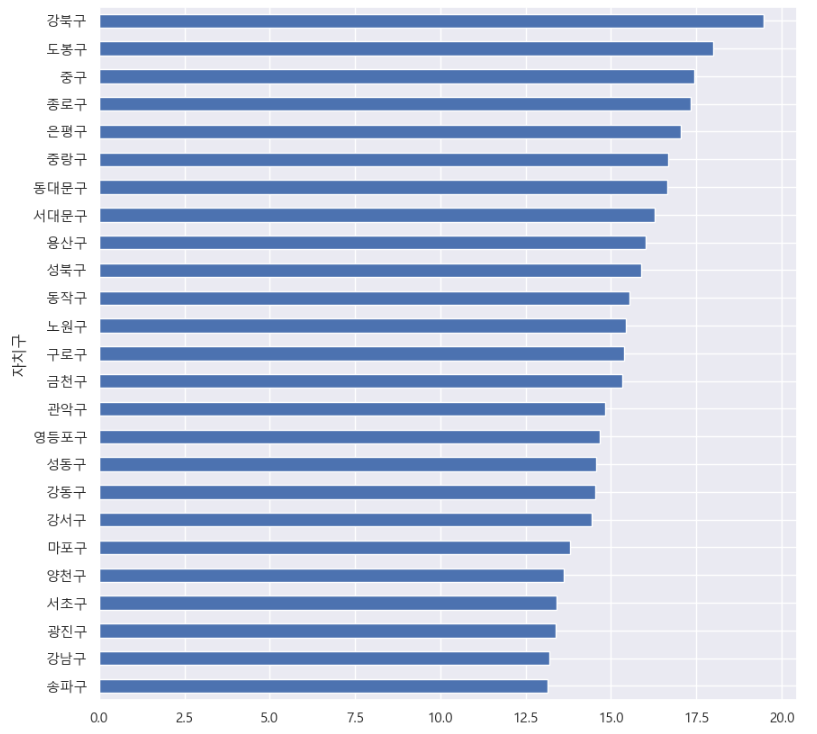
각 구별 고령자 비율을 차트화 하여 비교해 보았습니다.
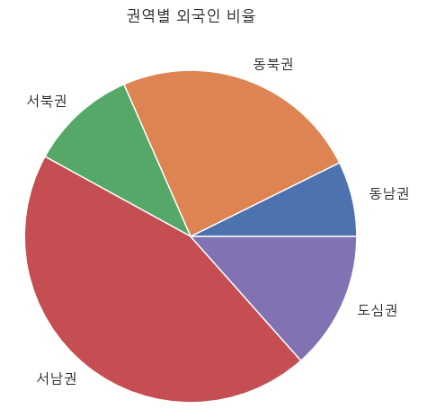
권역별 외국인 비율을 pie 차트로 비교하였습니다. pie 기능은 강의시간에 배운적이 없어서 구글링하여 포멧에 넣어 만들었습니다.
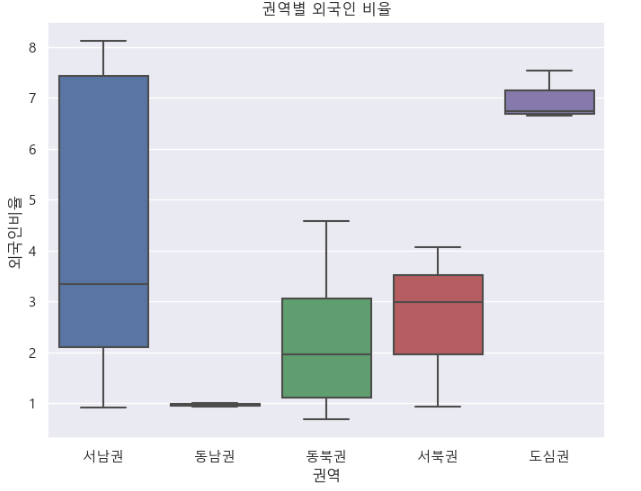
외국인 비율을 박스 플롯으로 시각화 하였습니다.
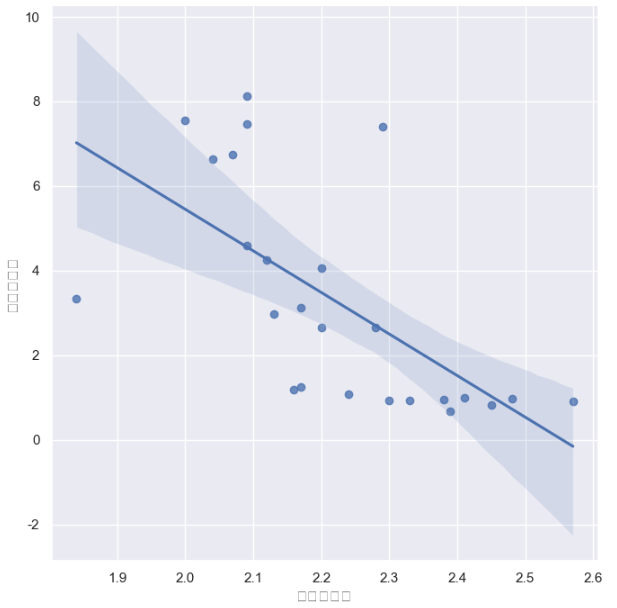
lmplot으로 세대당 외국인 비율의 상관관계를 선형회귀를 이용하여 시각화 하였습니다.
이 과정에서 한글이 깨지는 오류가 있는데 테스트를 다 끝내고 이 오류를 해결하는데에만 2시간정도를 소비하였으나 결국... 포기하여 제출하였습니다.
전체코드
