
개요
이번 테스트는 1976년부터 2008년까지의 올림픽 메달리스트들의 데이터인데 이것을 이용해서 여러가지 작업을 수행하였습니다.
문제 1-1) Target Data 가져오기
read_csv에서 encoding을 'utf-8'로 수행하는데 예외가 있다는걸 보여주는 문제였다.
문제 1-2) Preprocessing: missing data 처리
nan값이 여기저기에 섞여있는데 이것을 제거하고 인덱스 값을 재정렬 하는 문제였다.
문제 1-3) Preprocessing: Data Type 정리
년도 값을 불러오는데 float 타입으로 정의되어있어 이를 astype을 이용해 int 타입으로 바꿔주었습니다.
문제 2-1) 2008년 대한민국 메달리스트 찾기
대한민국의 메달리스트를 찾는 문제인데 문제를 읽지않고 조건만 보았다가 문제 푸는시간을 대폭 늘린거 같다...
문제 2-2) 대한민국 역대(1976-2008) 하계 올림픽 메달 획득 내역 확인 🤣🤣🤣
2-1까지는 왜 이 문제가 별 2개짜리인지 몰랐는데 여기서 심하게 맨붕이 온거 같다. 보기에는 간단해 보이는 데이터프레임이 였으나 획득 개수를 표시하기때문에 단체전인 데이터들을 하나만 남기고 지워주는 작업을 drop_duplicates으로 하였는데 문제는 이제
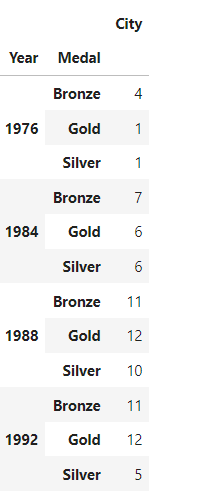
브론즈 골드 실버 순으로 정리되어있는 인덱스 값을 골드 실버 브론즈 순으로 정렬을 해야하는데 골드 실버 브론즈 순으로 정렬을 하면 연도까지 정렬되는 행복한 상황이 계속 연출되었다 ㅎㅎ...
sort_remaining이라는 기능을 사용하여 멀티 인덱스에서 각각의 레벨에 따라서 값을 섞지 않게 할수있었다.
문제 2-3) 1996년 애틀란타 올림픽 총 메달 개수 기준 상위 10개 국가 확인하기
2-2에서 별의별 코드들을 사용했더니 그거들을 조합했더니 비교적 간단히 풀수있었던 문제였다.
문제 2-4) 1996년 애틀란타 올림픽 금매달 개수 기준 상위 10개 국가 확인하기 🤣🤣
금 은 동 메달의 개수를 표시하는 컬럼을 새로 만들어야하는데 위에서 삽질을 했더니 멀티 인덱스를 사용해야할꺼 같은 생각이 들어 오래걸린거 같다. target 데이터프레임에서 itterows를 사용하여 금, 은, 동 데이터를 뽑아 각 경기별 획득 내역을 추가하였고 이 데이터를 피벗테이블을 사용하여 정리 하여 풀수있었다.
전체 코드
