
네이버 API를 사용하여 네이버 스토어 몰스킨 판매 업자 비율 시각화
1. 예제 코드
# 네이버 검색 API 예제 - 블로그 검색
import os
import sys
import urllib.request
client_id = "RPTEy__uwLe3Ht3MUnjy"
client_secret = "8y6R1SDjnA"
encText = urllib.parse.quote("파이썬")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)네이버 API에서 기본적으로 제공해주는 테스트 코드로 파이썬에 관한 블로그 검색 내역을 불러오는 코드이다. 이것을 이용하여 네이버 스토어에서 판매되고있는 몰스킨 판매 내역을 크롤링하여 판매자 비율을 시각화 할것이다.
1.gen_search_url()
def gen_search_url(api_node, search_text, start_num, disp_num):
base = 'https://openapi.naver.com/v1/search'
node = '/' + api_node + '.json'
param_query = '?query=' + urllib.parse.quote(search_text)
param_start = '&start=' + str(start_num)
param_disp = '&display=' + str(disp_num)
return base + node + param_query + param_disp + param_starAPI 예제를 참고하면 데이터를 불러오기 위해서는 뉴스, 백과사전, 블로그, 쇼핑, 영화, 웹 문서등과 같은 어떤 탭에서 데이터값을 가져올지를 선택하고 검색어를 지정해주고 몇번째 값을 몇개씩 불러올것인지가 들어가야한다 그것을 입력받는 함수를 만들어 주었다.
(2)get_search_url()
def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
print('[%s] Url Request Success' % datetime.datetime.now())
return json.loads(response.read().decode('utf-8'))
위에서 조합한 URL키를 request로 HTTP통신 하도록 하여 응답값을 UTF-8로 인코딩하여 받아오는 함수를 구성해줍니다.
응답 값은 다음과 같은 리스트 값들을 받아오는데
{'title': '스타벅스 2024년 몰스킨 다이어리 데일리 플래너 일기장 노트 스벅 카페 윈터 e프리퀀시',
'link': 'https://search.shopping.naver.com/gate.nhn?id=86963344737',
'image': 'https://shopping-phinf.pstatic.net/main_8696334/86963344737.41.jpg',
'lprice': '35000',
'hprice': '',
'mallName': '유니스스토어',
'productId': '86963344737',
'productType': '2',
'brand': '스타벅스',
'maker': '몰스킨',
'category1': '생활/건강',
'category2': '문구/사무용품',
'category3': '다이어리/플래너',
'category4': '다이어리'}
{kind=link}
여기서 필요한 상품명, 링크, 매장명, 가격을 크롤링 할 것입니다.
(3)get_fields()
def get_fields(json_data):
title = [delete_tag(each['title']) for each in json_data['items']]
link = [each['link'] for each in json_data['items']]
lprice = [each['lprice'] for each in json_data['items']]
mall = [each['mallName'] for each in json_data['items']]
result_pd = pd.DataFrame({
'title' : title,
'link' : link,
'lprice' : lprice,
'mall' : mall,
}, columns=['title', 'lprice', 'link', 'mall'])
return result_pd딕셔너리에서 필요한 값을 'KEY': '[value]' 형식으로 저장하여 저장한것들을 사용하여 데이터프레임을 만들어줍니다.
여기서 br태그가 상품명에 껴있는 경우가 생기는데 replace를 사용하여 br태그를 지워줍니다.
def delete_tag(input_str):
input_str = input_str.replace('<b>','')
input_str = input_str.replace('</b>','')
return input_str
(5) actMiain()
이제 5개만 가져왔던 데이터를 1000개를 불러오기 위해 100개씩 10번 불러올수있도록 해줍니다.
result_mol = []
for n in range(1, 1000, 100):
url = gen_search_url('shop', '몰스킨', n, 100)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
result_mol.append(pd_result)
result_mol = pd.concat(result_mol)
result_mol.reset_index(drop=True, inplace=True)
(6) to_excel()
이제 정리된 데이터프레임을 엑셀 파일로 저장해줍니다.
writer = pd.ExcelWriter('../06. Naver API/data/06_molskin_diary_in_naver_shop.xlsx', engine='xlsxwriter')
result_mol.to_excel(writer, sheet_name='sheet1')
workbook = writer.book
worksheet = writer.sheets['sheet1']
worksheet.set_column("A:A", 4)
worksheet.set_column("B:B", 60)
worksheet.set_column("C:C", 10)
worksheet.set_column("D:D", 10)
worksheet.set_column("E:E", 50)
worksheet.set_column("F:F", 50)
worksheet.conditional_format('C2:C1001', {'type' : '3_color_scale'})
writer.close()(7) 시각화
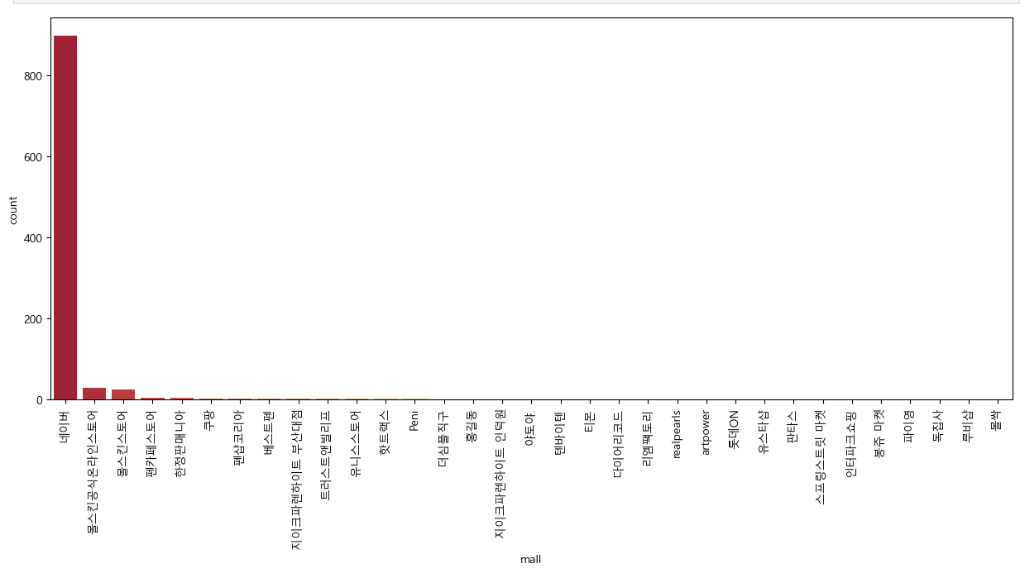
plt.figure(figsize=(15,6))
sns.countplot(
x = result_mol['mall'],
data=result_mol,
palette='RdYlGn',
order=result_mol['mall'].value_counts().index
)
plt.xticks(rotation=90)
plt.show()seaborn 라이브러리의 countplot을 사용하여 시각화 해주었습니다.
전체코드
