
머신러닝 시작
이제부터 시작이라는 느낌..!
큰 흐름
이번 강의에서는 머신러닝의 시작인 아이리스 꽃 데이터를 사용한다...
사이킷런에서 예제로 제공하는 해당 데이터를 확인하면 꽃잎과 꽃받침의 가로 세로 길이와 종류 데이터를 제공하는데 '꽃잎과 꽃받침의 길이만 가지고 종류를 구분 할 수 있을까?' 라는 것에서 부터 머신러닝이 시작됩니다.
seabron의 pairplot 기능으로 종을 기준으로 분류해보면
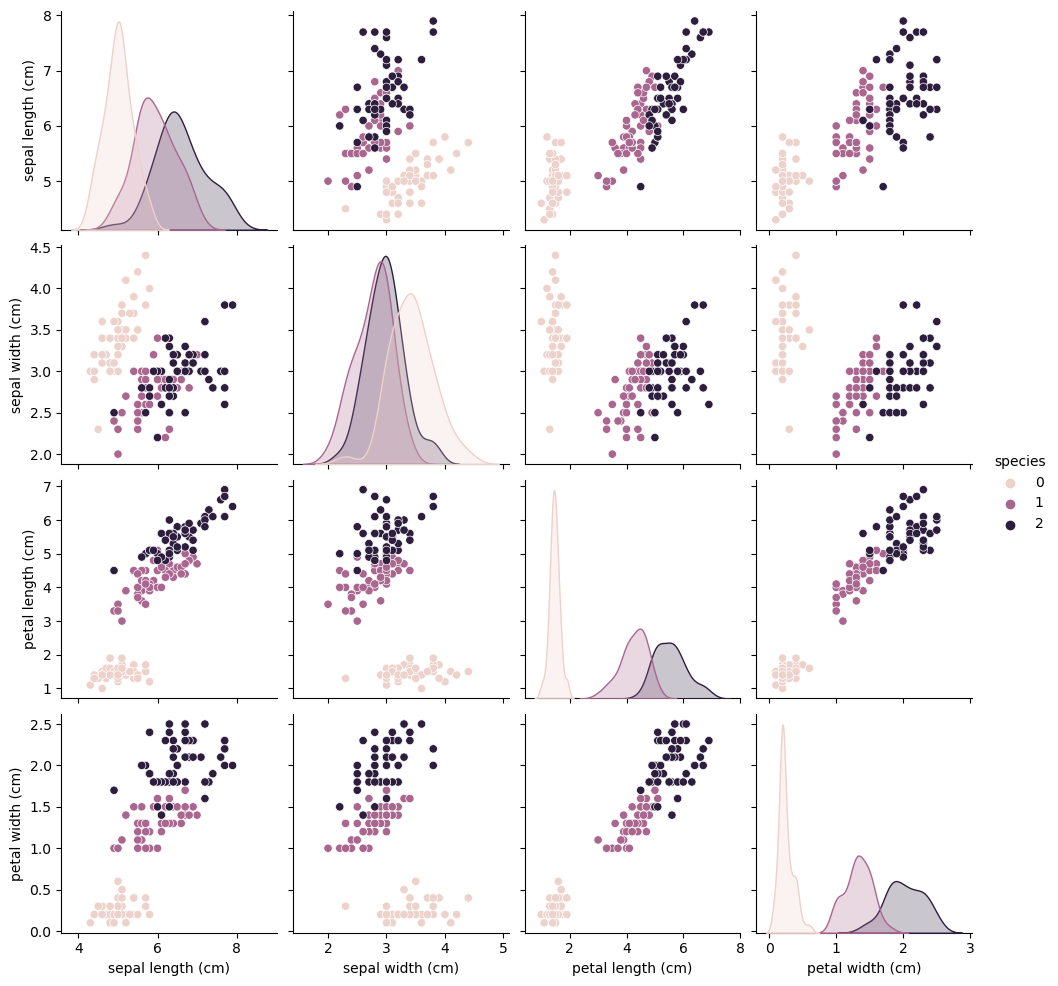
두 데이터 사이의 관계성이 나오게 되는데
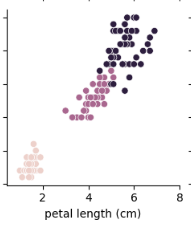
petal 길이에 대한 조건으로, 0번 종을 구분하기 위해 파이썬 코드를 사용한다면, if문을 활용하여 3cm 이하의 데이터를 추출하는 간단한 분류가 가능합니다. 이러한 방식으로 데이터를 다양한 조건문으로 이분할하는 방법을 파이썬으로 구현한 것 들 중 DecisionTreeClassifier를 예시로 들어 사용하면
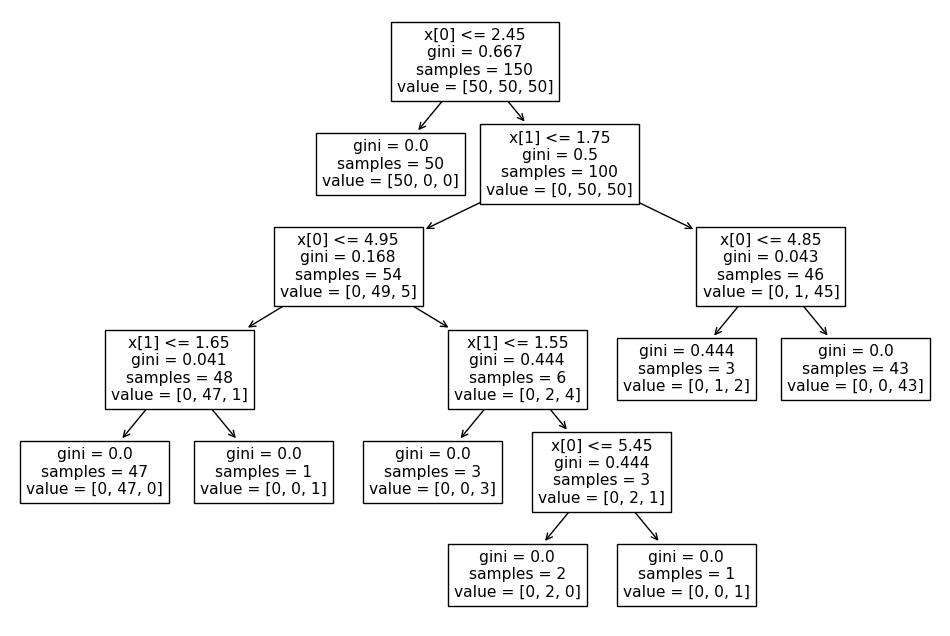
다음과 같이 150개의 데이터를 전부 나눠 분류 할 수 있다.
이렇게 분류한 데이터의 정확성은 다음과 같다.
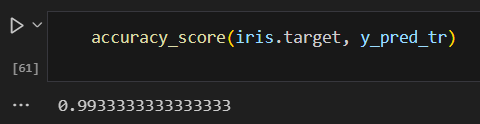
그런데 이렇게 구한 모델의 정확도가 주어진 데이터셋에 지나치게 적응되어 있어서, 새로운 데이터에 대한 일반화 성능이 감소할 수 있는 문제가 발생하는데, 이를 과적합(Overfitting)이라고 합니다.
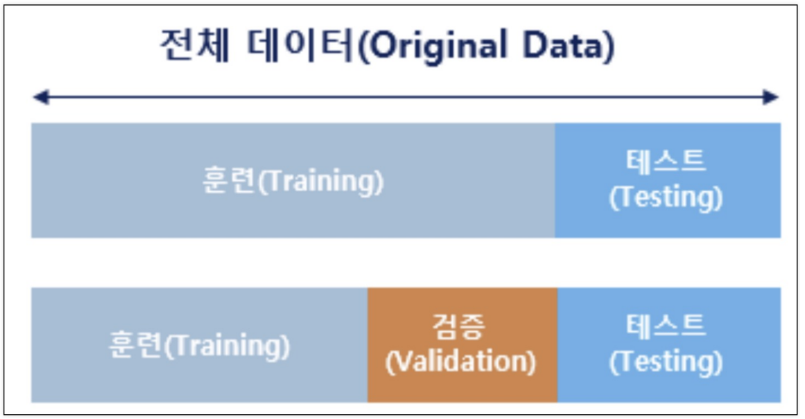
이러한 문제를 해결하고자 다음과 같이 학습데이터와 테스트데이터를 분리하여
학습데이터만 DecisionTreeClassifier 모델에 학습시켜줍니다.
또한 DecisionTreeClassifier에는 max_depth 파라메터가 있는데 이는 위에서 말한 조건문으로 이분하는 횟수를 의미합니다. max_depth 값이 크면 해당 데이터에 너무 맞혀진 과적합 모델이 생길수 밖에 없어 이를 조절하는데 사용됩니다.
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)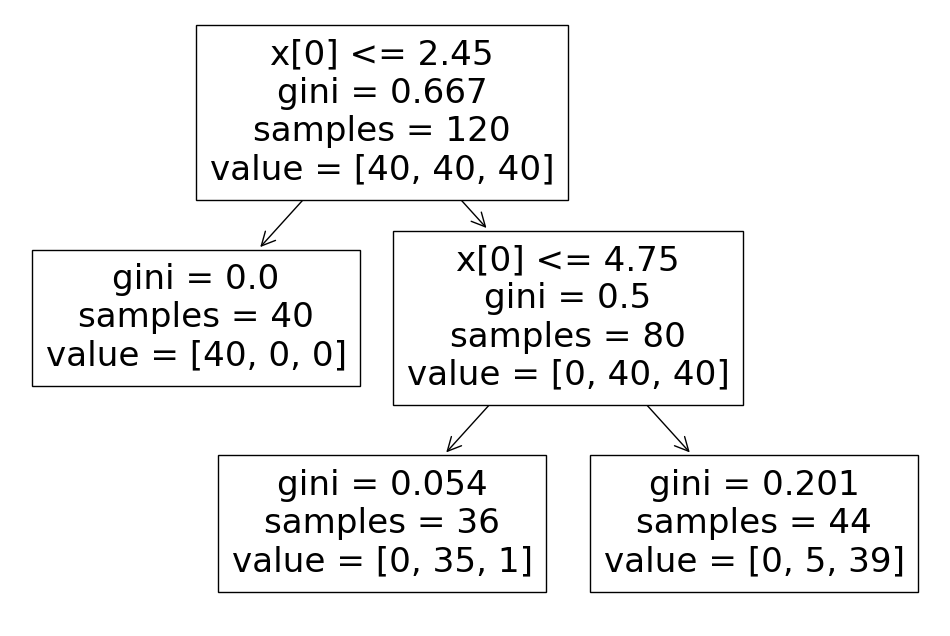
이렇게 모델을 만들어주면 조건이 단조로운 만큼 위의 모델보다 정확도는 떨어지지만
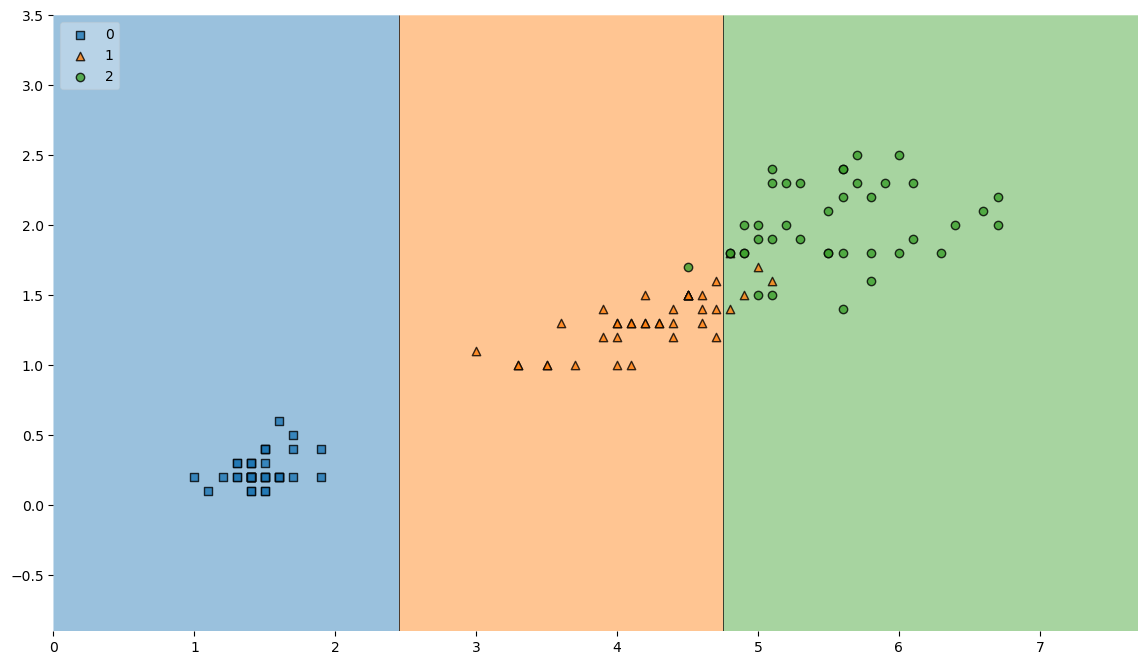
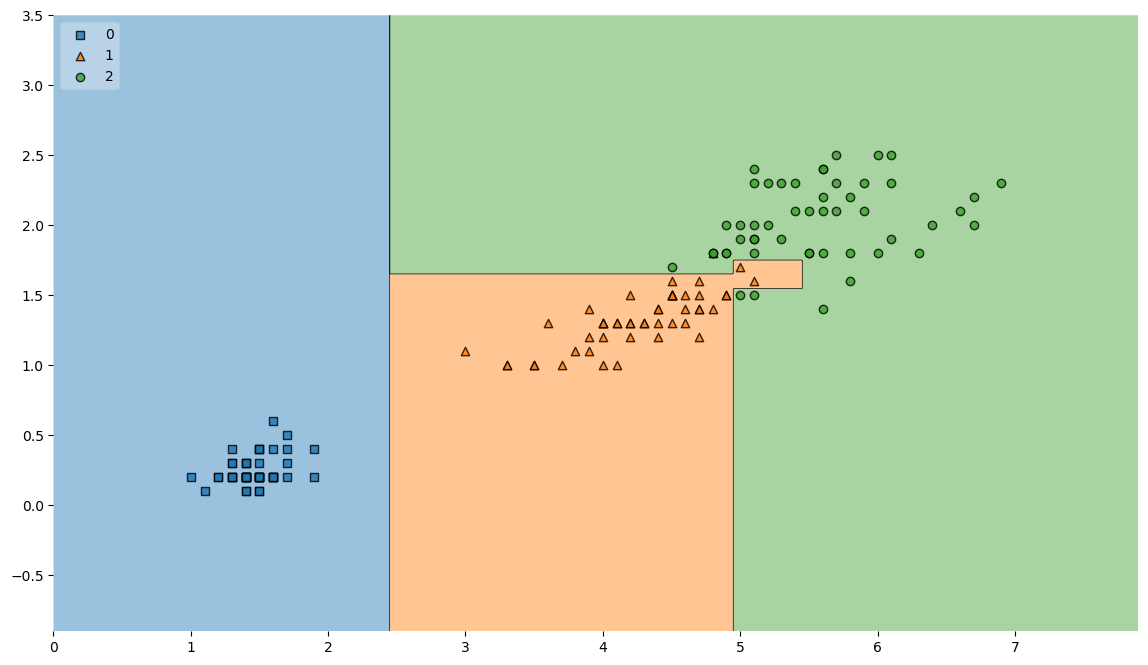
다음 그림과 같이 일반화된 모델을 만들어 낼 수 있습니다.
주요 코드
X_train, X_test, y_train, y_test = train_test_split(x, y,
test_size=0.2,
random_state=13,
stratify=labels)학습데이터와 테스트데이터를 분류 해주는 코드이며 x는 여러 feature를 y는 결과 test_size는 학습데이터와 테스트데이터의 분류 비율, stratify는 분류시의 비율을 정할 수있는 기능을 담당한다.
np.unique(y_test, return_counts=True)데이터가 잘 섞였는지 확인 하는 코드
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=X_train, y=y_train, clf=iris_tree, legend=2)
plt.show()잘 쓰이지는 않는다고 하셨지만 데이터 분리 기준을 시각화 시켜주는 코드
iris_tree.feature_importances_해당 데이터에서 분류시의 중요도를 나타내는 코드
pair2 = [pair for pair in zip(list1, list2)]
pair2[('a', 1), ('b', 2), ('c', 3)]
zip 코드 예제
전체파일
