
타이타닉 생존 예측
타이타닉에 승선한 사람들의 객실 등급, 생존 여부, 성별, 여객운임요금 등등의 데이터를 사용하여 영화 주인공 레오나르도 디카프리오의 생존 확률을 예측해보자
데이터 분석
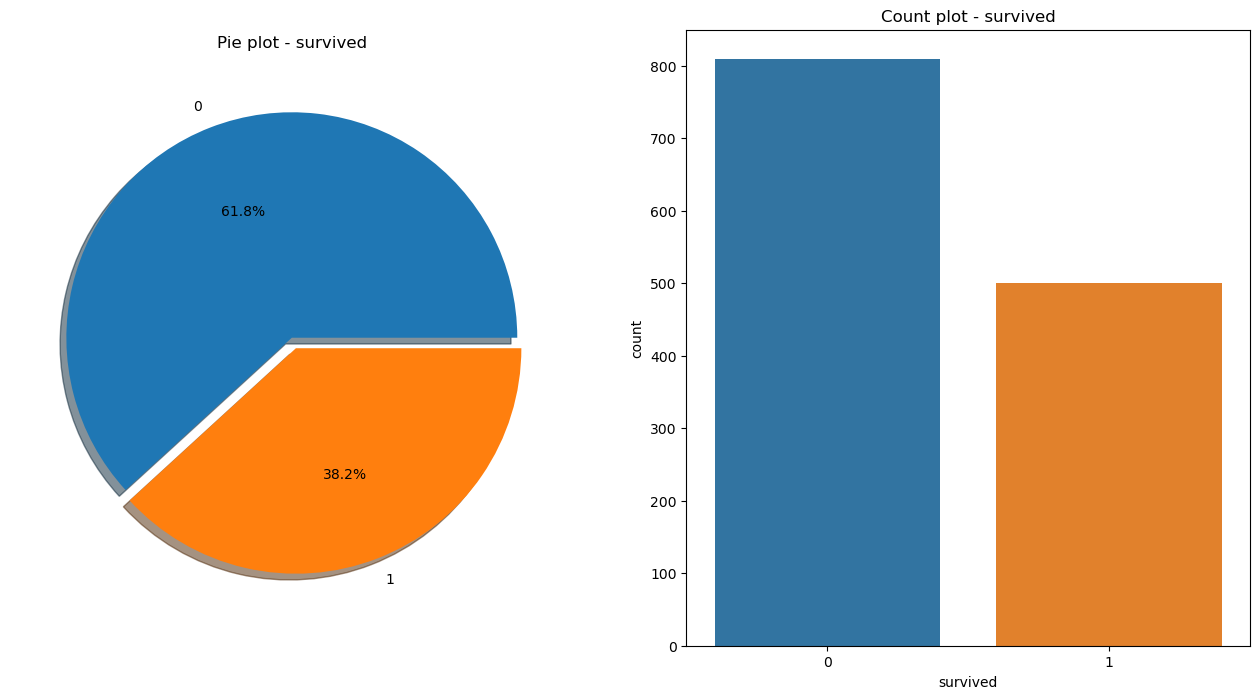
우선 생존자와 사망자의 비율을 확인해 보면 38.2% 밖에 생존하지 못한것을 알 수 있는데
성별을 기준으로 데이터를 나눠보면
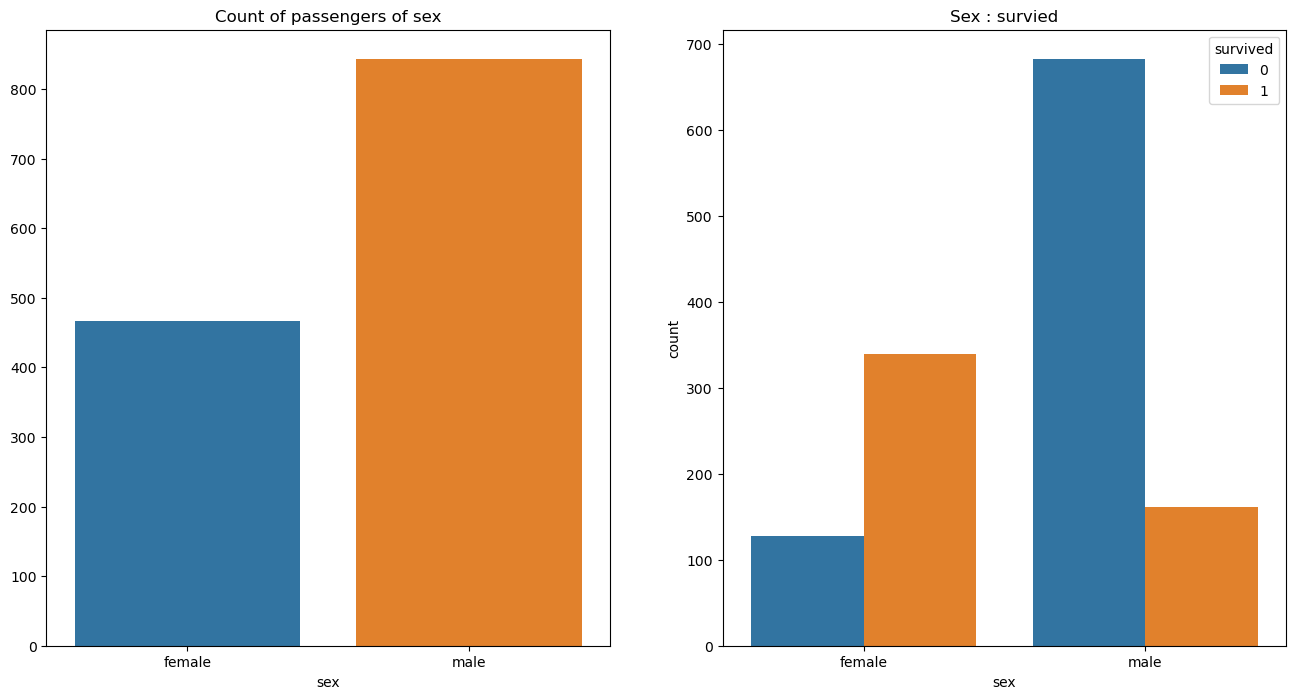
남자 생존자가 더 많아 남성이 더 생존율이 높구나!! 라는 결론을 내릴수도 있지만 사망자 데이터와 생존자 데이터를 성별 기준으로 나눠보면 남성 사망자가 압도적으로 많은것을 알수있다.
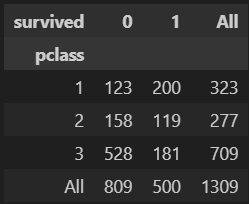
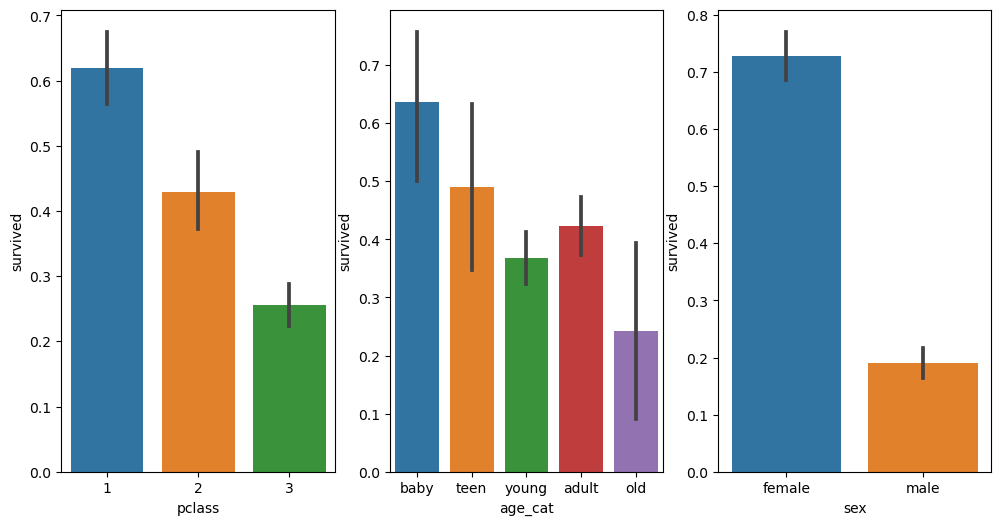
다음은 객실을 기준으로 생존 여부를 나타낸 데이터프레임이다. 1,2등 객실 이용자의 생존율이 압도적으로 높은걸 알 수 있다.
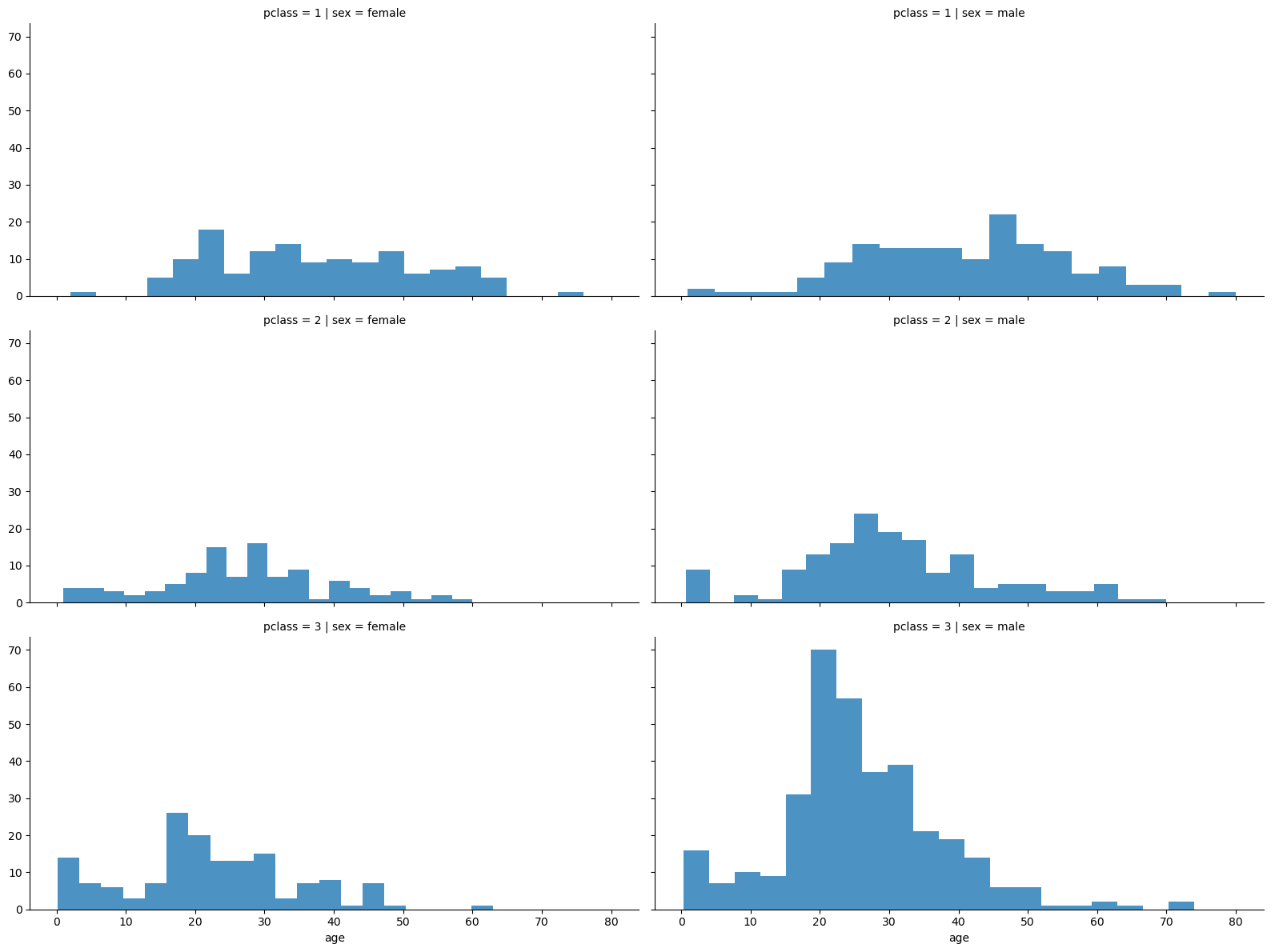
다음은 나이와 객실을 성별 기준으로 타이타닉호 탑승자 수를 시각화 한 것인데 3등 객실에 2,30대 남성이 다른 구간에 비해 압도적으로 많은 것을 알 수 있다.
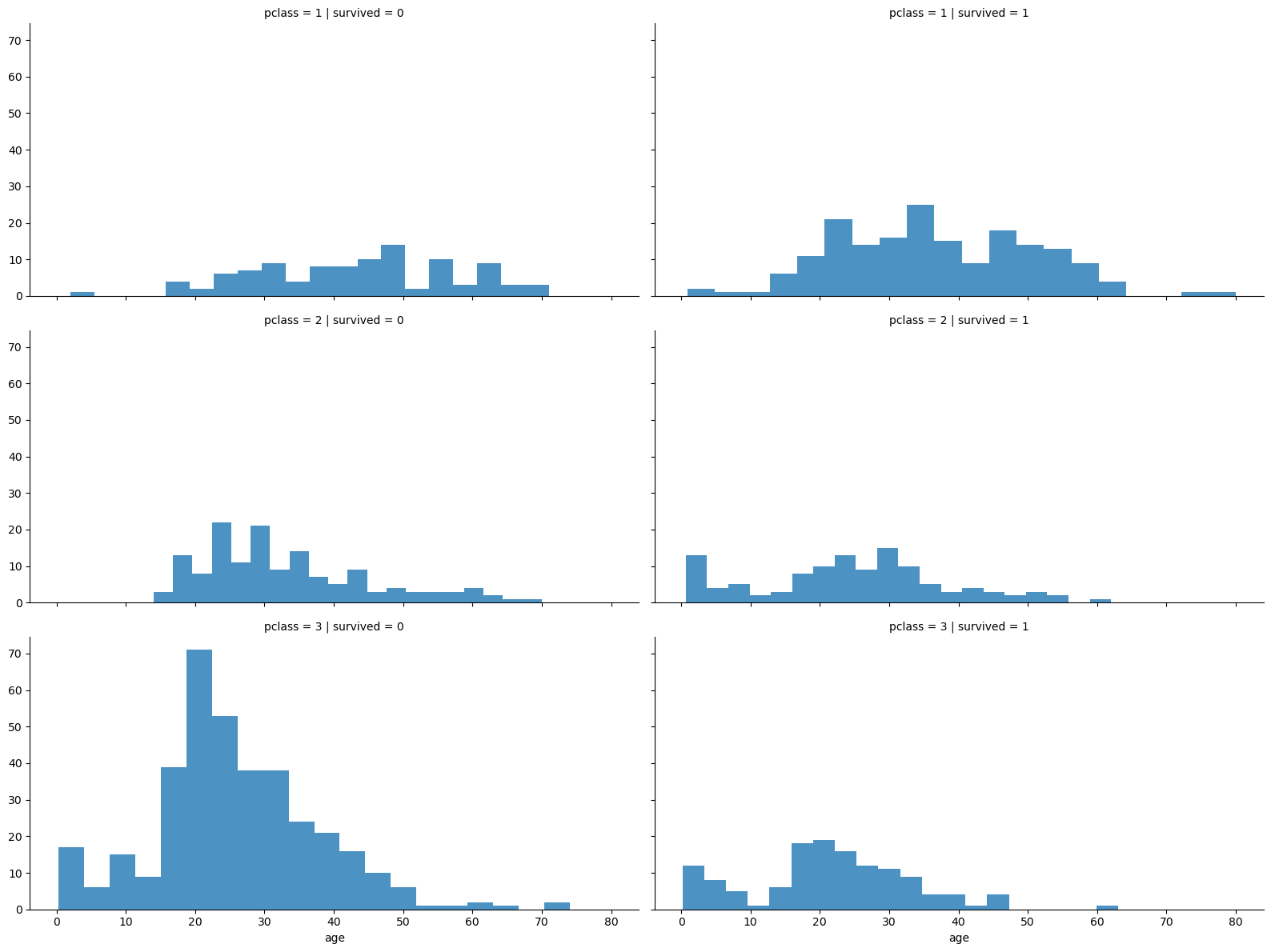
다음은 나이와 생존여부를 나이를 기준으로 시각화한 것인데 위의 탑승자 데이터와 비교했을 때 3등 객실에 젊은 층들이 대부분 생존하지 못했고 어린 아이들은 대부분 생존한 것으로 보인다.
생존비율을 전체비율로 나타내면 다음과 같다.
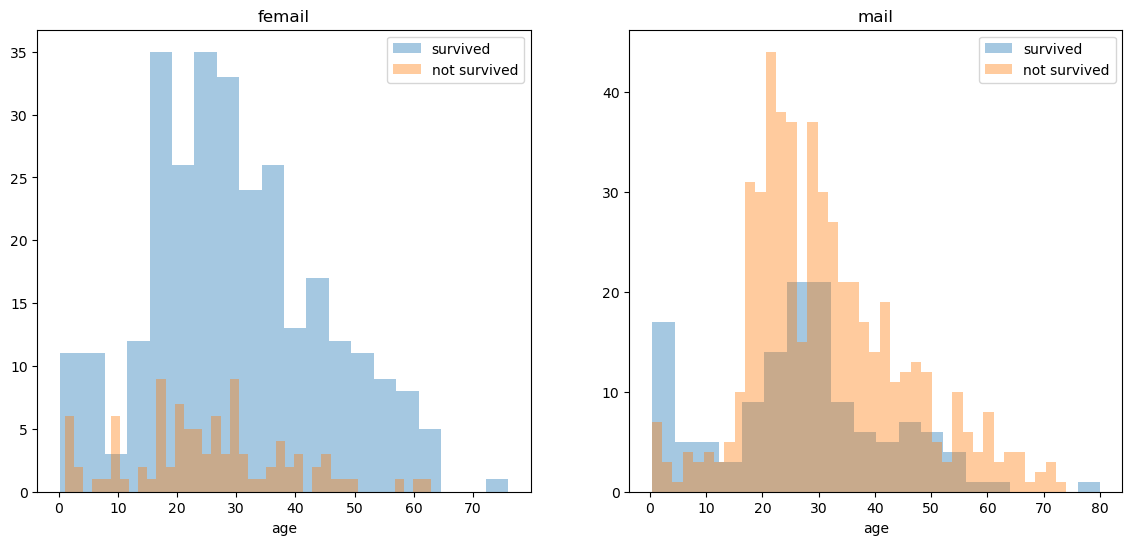
나이별 남녀 생존 데이터
생존 여부 확인 모델
나이, 객실등급, 함께 탑승한 부모 또는 자녀의 수, 여객 운임 요금, 성별을 기반으로 생존여부를 측정하는 모델을 만들어 보겠습니다.
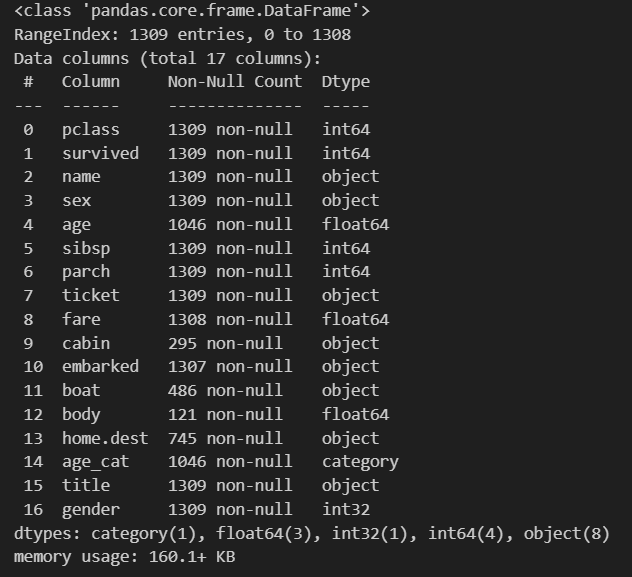
타이타닉 데이터를 확인해보면 다음과 같은데 나이와 지불요금에 NAN값이 있어 NAN 값이 있는 데이터를 정리하는 것 부터 진행하였습니다.
titanic = titanic[titanic['age'].notnull()]
titanic = titanic[titanic['fare'].notnull()]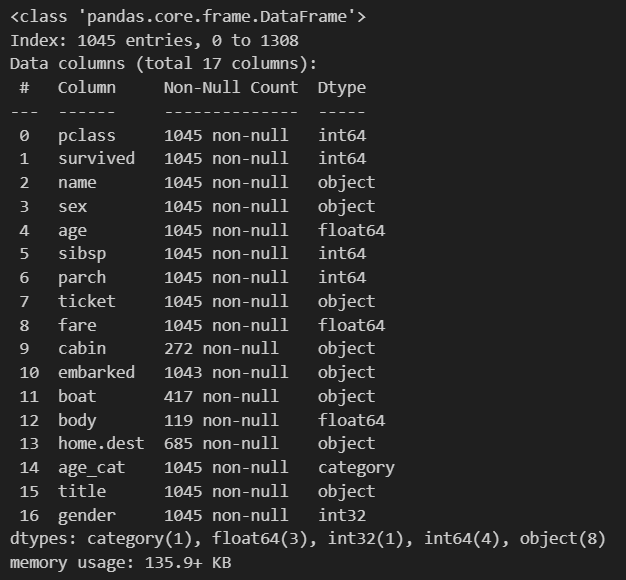
이후 x, y에 각각 데이터를 선언하고 지난번에 사용했던 테스트세트와 학습세트로 분류하였습니다.
from sklearn.model_selection import train_test_split
x = titanic[['pclass','age', 'sibsp', 'parch', 'fare','gender']]
y = titanic['survived']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.8, random_state=13)DecisionTreeClassifier 모델을 max_depth 4로 하여 타이타닉 데이터를 학습시켜 생존율을 예측해 보았습니다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt = DecisionTreeClassifier(max_depth=4, random_state=13)
dt.fit(x_train,y_train)
pred = dt.predict(x_test)
print(accuracy_score(y_test, pred))0.7655502392344498
이제 이 모델을 사용하여 디카프리오의 생존율을 확인해 보겠습니다.
import numpy as np
Dicaprio = np.array([[3, 18, 0, 0, 5, 1]])
Dicaprio = pd.DataFrame(Dicaprio,columns = ["pclass","age","sibsp","parch", "fare", "gender"])3등 객실을 사용하였으며 18살에 동행인은 없었고 성별은 남성이며 요금은 임의로 5달러로 하였습니다. 해당 데이터를 이 모델에 넣어보면
print('Dicaprio : ', dt.predict_proba(dicaprio)[0, 1])Dicaprio : 0.22950819672131148
생존율은 매우 희박하다...
주요 코드
2개의 차트를 그릴때 사용되고 세세한 위치 정하기
f, ax = plt.subplots(1,2, figsize=(16,8))
titanic['survived'].value_counts().plot.pie(ax=ax[0], autopct='%1.1f%%', shadow=True, explode=[0, 0.05])
ax[0].set_title('Pie plot - survived')
ax[0].set_ylabel('')
sns.countplot(x='survived', data=titanic, ax=ax[1])
ax[1].set_title('Count plot - survived')subplots의 매개변수로 1행 2열의 차트를 만들겠다고 선언하고
f에는 차트의 정보를 저장하고 ax변수에는 차트의 위치를 선언 할 수 있다.
value_counts() 데이터의 합계를 집계할 수 있음
crosstab
pd.crosstab(titanic['pclass'], titanic['survived'], margins=True)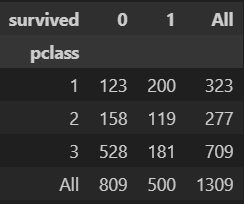
위 그림처럼 두가지 데이터의 합계를 세부적으로 확인 할 수있다.
margins은 합계를 나타낼지 여부
sns.FacetGrid
grid = sns.FacetGrid(titanic, row='pclass', col = 'sex', height=4, aspect=2)
grid.map(plt.hist, 'age', alpha=0.8, bins=20)
grid.add_legend();다양한 범주를 가지고있는 데이터를 비교할 때 사용하는 그레프
plotly.express
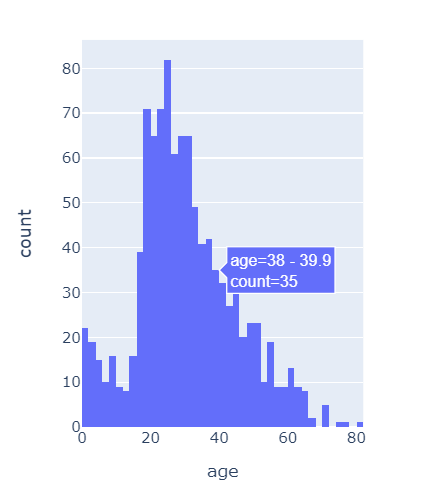
파이썬 차트를 다음과 같이 동적 시각화해주는 라이브러리
fig = px.histogram(titanic, x='age')
fig.show()pd.cut
titanic['age_cat'] = pd.cut(titanic['age'], bins=[0, 7, 15, 30, 60, 100],
include_lowest=True,
labels = ['baby', 'teen', 'young', 'adult', 'old'])
titanic.head()bins 내부의 기준으로 데이터를 새로 라벨링 해주는 기능
predict 오류
강의에서 디카프리오의 생존율을 확인할때 데이터프레임으로 바꾸고 바로 예측값을 확인하는데 오류가 발생하는데 해당사이트를 참고하여 디카프리오 데이터에 컬럼데이터를 추가하여 오류를 해결하였다.
dicaprio = np.array([[3, 18, 0, 0, 5, 1]])
dicaprio = pd.DataFrame(dicaprio,columns = ["pclass","age","sibsp","parch", "fare", "gender"])LabelEncoder()
LabelEncoder는 주로 범주형 데이터를 수치형으로 변환하기 위해 사용합니다. 여러 머신러닝 모델은 데이터를 수치로 처리해야 하기 때문에, 범주형 변수(문자열 또는 클래스)를 수치형으로 변환해야 합니다. 이런 상황에서, LabelEncoder가 유용하게 사용됩니다.
LabelEncoder는 문자열이나 클래스와 같은 범주형 데이터를 숫자로 매핑하는 데 사용됩니다. 예를 들어, "고양이", "개", "새"와 같은 동물의 종을 0, 1, 2와 같은 숫자로 매핑할 수 있습니다.
df = pd.DataFrame({'A':['a','b','c','a','b'],
'B':[1,2,3,1,0]})
다음과 같은 데이터 프레임이 존재할 때 라벨프린터를 사용하면
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df['A'])
df['le_A'] = le.transform(df['A'])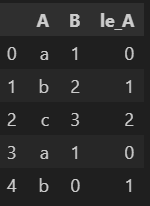
이와 같이 문자열 a, b, c를 0, 1, 2로 변환 한것을 확인할수있다.
le.fit_transform(df['A']) 데이터 변환
le.inverse_transform(df['le_A']) 데이터 되돌리가
스케일
MinMaxScaler
최소-최대 스케일링을 수행합니다. 주어진 특성의 최솟값은 0, 최댓값은 1로 변환됩니다.
MinMaxScaler는 아웃라이어에 민감하게 반응하지 않습니다.
데이터의 분포가 정규 분포를 따르지 않거나, 이상치(outlier)가 있을 때 사용하기 적합합니다.
StandardScaler
Z-점수 정규화를 수행합니다. 특성의 평균은 0, 표준편차는 1로 변환됩니다.
StandardScaler는 정규 분포를 따르는 데이터에 적합합니다.
아웃라이어에 민감할 수 있기 때문에, 이상치가 있는 경우 조심해서 사용해야 합니다.
RobustScaler
중앙값(median)과 IQR(Interquartile Range)을 사용하여 스케일링을 수행합니다. 이는 아웃라이어의 영향을 줄입니다.
RobustScaler는 데이터의 분포에 영향을 받지 않고 안정적으로 스케일링할 수 있습니다.
특히, 이상치가 있는 데이터에 적합합니다.
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
mm = MinMaxScaler()
ss = StandardScaler()
rs = RobustScaler()
df_scaler = df.copy()
df_scaler['MinMax'] = mm.fit_transform(df)
df_scaler['Standard'] = ss.fit_transform(df)
df_scaler['Robust'] = rs.fit_transform(df)
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style='whitegrid')
plt.figure(figsize=(16,6))
sns.boxplot(data=df_scaler, orient='h');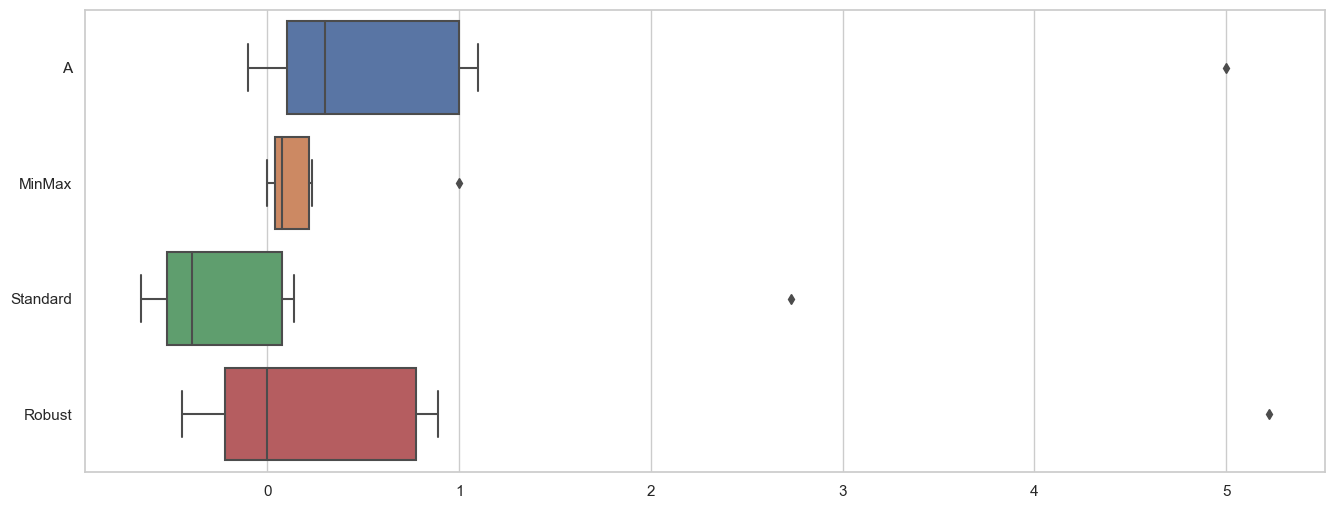
MinMaxScaler는 최대 최소가 1, 0으로 바뀐걸 확인할 수 있고,RobustScaler는 중앙값에 0이 있는걸 확인할수있다.
전체코드
