
pandas pivot table
Pandas의 pivot_table() 함수는 데이터프레임을 피벗 테이블로 변환하는 함수입니다. 쉽게 말해 피벗 테이블은 데이터를 행과 열로 구성하여 요약한 표입니다.
index : 매개변수로 행 인덱스를 지정합니다.
values : 매개변수로 열 값을 지정합니다.
aggfunc : 매개변수로 집계 함수를 지정합니다.
ex) pd.sum() / pd.mean()
fill_value : 매개변수로 결측값을 대체할 값을 지정합니다.
margins=True : 매개변수로 모든 행과 열에 대한 합계를 추가합니다.
df = pd.read_excel('data/02. sales-funnel.xlsx')
df.head()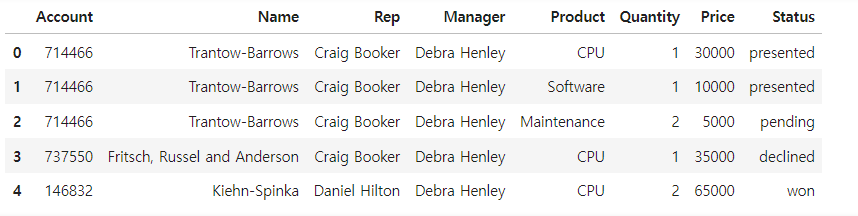
다음과 데이터프레임을 다양한 기준으로 요약 할 수 있습니다.
name 컬럼을 인덱스로 설정
# pd.pivot_table(df, index='Name')
df.pivot_table(index = 'Name', values=['Price', 'Quantity'])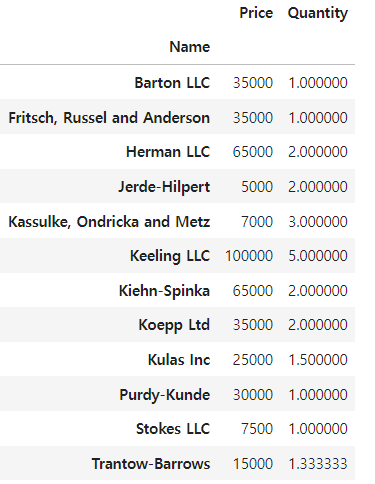
Name을 인덱스 값으로 하였을때
멀티 인덱스 설정
df.pivot_table(index = ['Name', 'Rep', 'Manager'], values = ['Account', 'Price', 'Quantity'])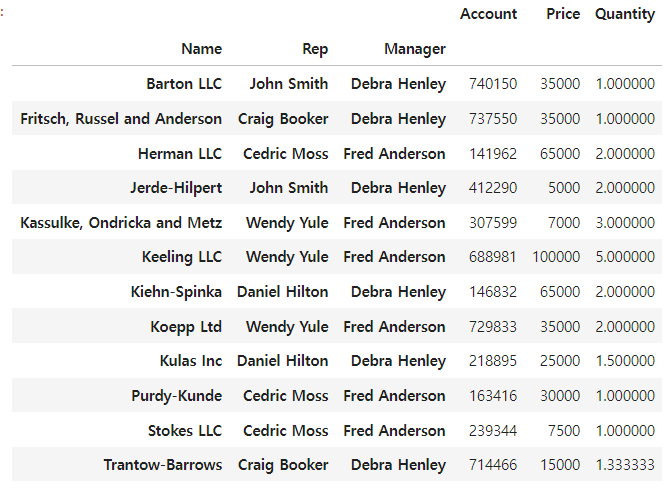
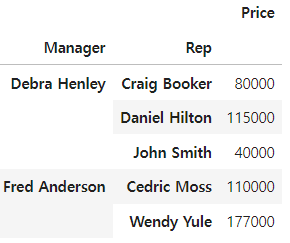
Price 컬럼에 sum 연산 적용
#
df.pivot_table(index = ['Manager', 'Rep'], values = ['Price'], aggfunc=np.sum)
columns 설정
df.pivot_table(index = ['Manager', 'Rep'], values = ['Price'], columns = 'Product' ,aggfunc=[np.sum])
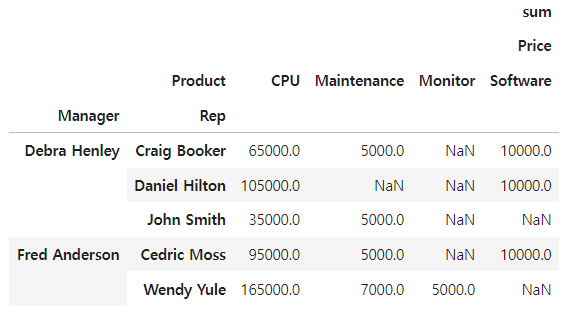
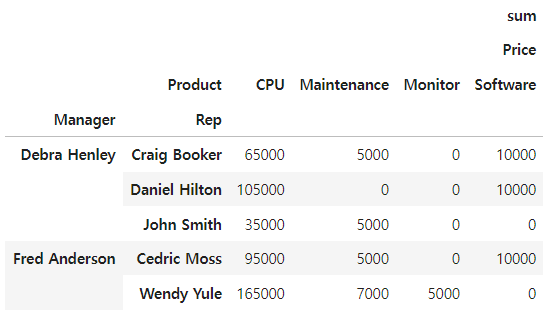
# nan값 채우기
df.pivot_table(index = ['Manager', 'Rep'], values = ['Price'], columns = 'Product' ,aggfunc=[np.sum], fill_value= 0)
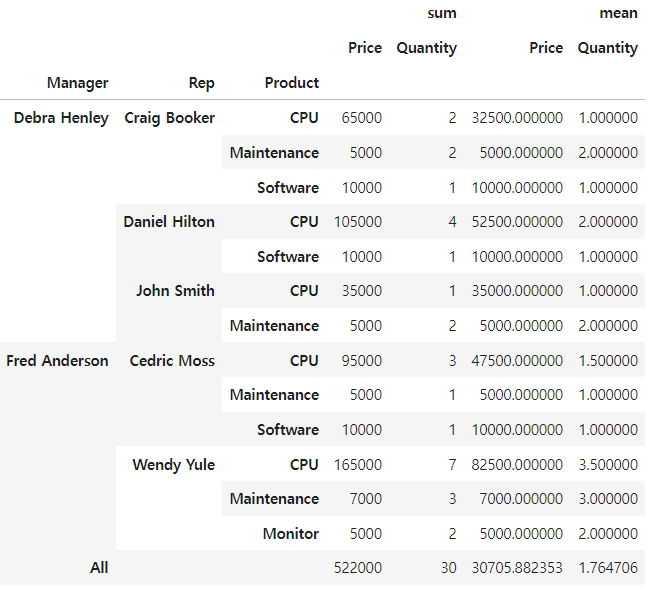
df.pivot_table(
index = ['Manager', 'Rep', 'Product'],
values = ['Price', 'Quantity'],
aggfunc=[np.sum, np.mean],
fill_value= 0,
margins=True # All 기능 추가
)
seabron
Seaborn은 Matplotlib을 기반으로 하는 Python 데이터 시각화 라이브러리입니다. Matplotlib은 강력한 데이터 시각화 기능을 제공하지만, Seaborn은 Matplotlib의 복잡한 설정을 간소화하고 다양한 시각화 스타일을 제공하여 데이터 시각화를 보다 쉽고 빠르게 할 수 있도록 합니다.
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams['axes.unicode_minus'] =False
matplotlib 라이브러리에 한글을 쓰기 위한 설정입니다.
예제1 : seaborn 기초
# 0부터 14까지 100개의 균등한 간격의 숫자를 생성합니다.
x = np.linspace(0, 14, 100)
y1 = np.sin(x)
y2 = 2 * np.sin(x + 0.5)
y3 = 3 * np.sin(x + 1.0)
y4 = 4 * np.sin(x + 1.5)
# sns.set_style()
# 'white', 'whitegrid', 'dark', 'darkgrid' 등 배경색을 바꿀수 있습니다.
sns.set_style('white')
# figsize= (10, 6)으로 그래프 크기를 설정합니다.
plt.figure(figsize= (10, 6))
# 위에서 선언한 변수들로 4개의 그래프를 그립니다.
plt.plot(x, y1, x, y2, x, y2, x, y3, x, y4)
plt.show()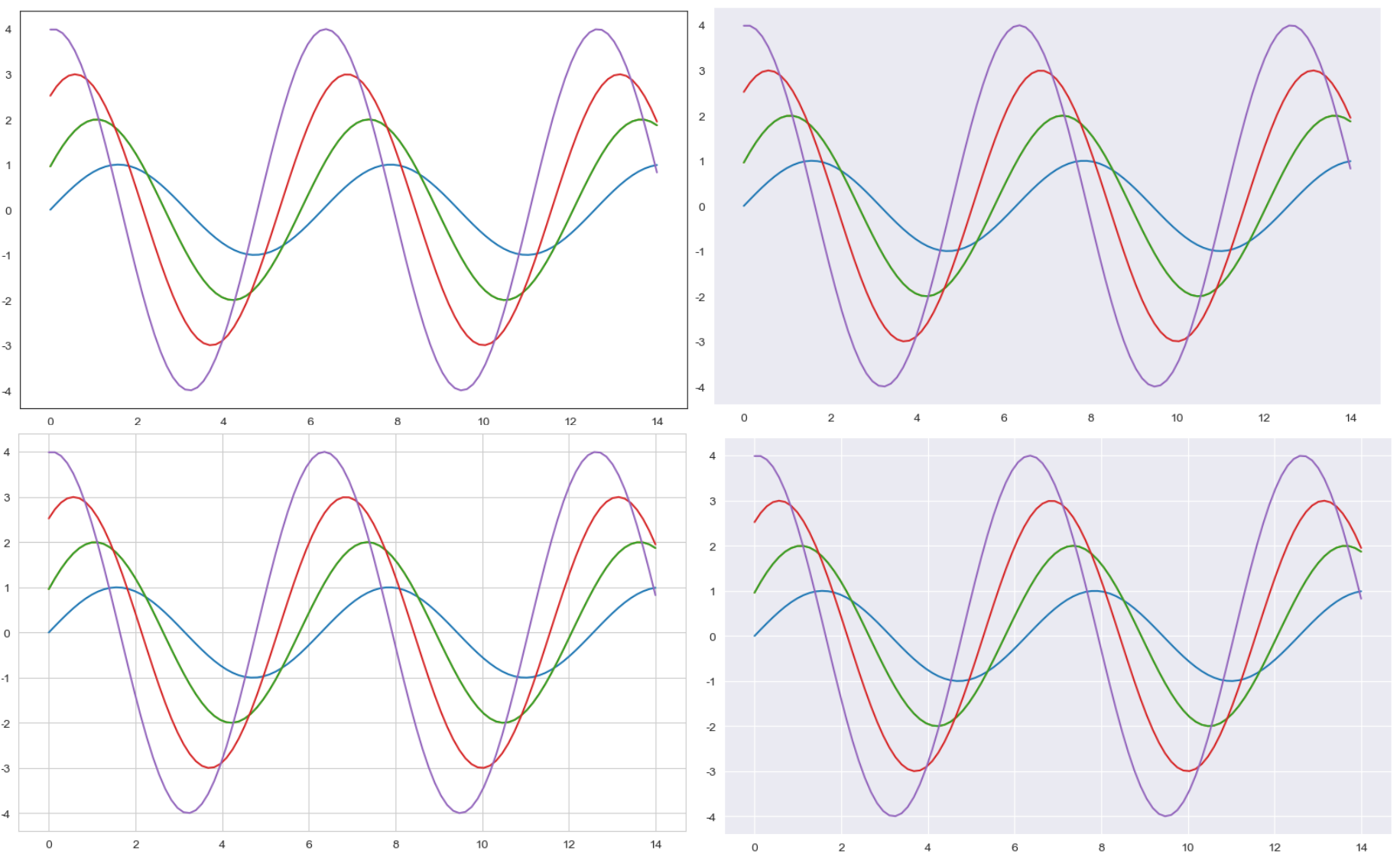
예제2 : seaborn tips data
사용 데이터 tips
tips = sns.load_dataset('tips')
tips.head()
seaborn은 다양한 머신러닝용 예제들을 가지고 있는데 그중에 tips라는 데이터를 불러와 예제를 수행하였습니다.
boxplot
# 그래프 크기 조절
plt.figure(figsize=(8,6))
# x값을 tips 데이터 프레임의 total_bill로 지정
sns.boxplot(x=tips['total_bill'])
plt.show()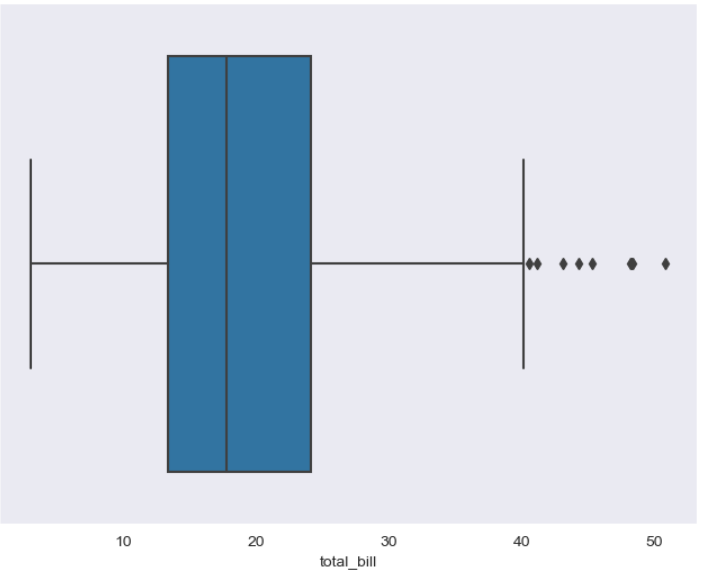
# 그래프 크기 조절
plt.figure(figsize=(8,6))
# tips 데이터 속의 day 값을 x로 두고 total_bill를 y로 둔 그래프 선언
sns.boxplot(x='day', y='total_bill', data=tips)
plt.show()
# hue : 데이터를 더욱더 분할 할 수 있으며 카테고리 옵션 표현기능
# palette : Set1, Set2, Set3 3가지 종류의 색상 타입으로 수정 가능
plt.figure(figsize=(8,6))
# 흡연 여부에 따라서 그래프를 2분할 하도록 설정
sns.boxplot(x='day', y='total_bill', data=tips, hue='smoker', palette='Set2')
plt.show()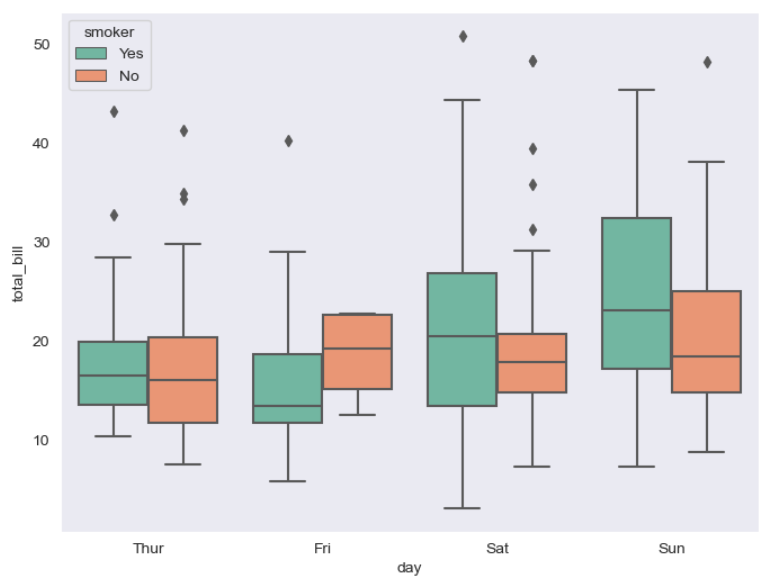
swarmplot
# color 0~1까지 0검 1흰
plt.figure(figsize=(8,6))
sns.swarmplot(x='day', y='total_bill', data=tips, color='0.5')
plt.show()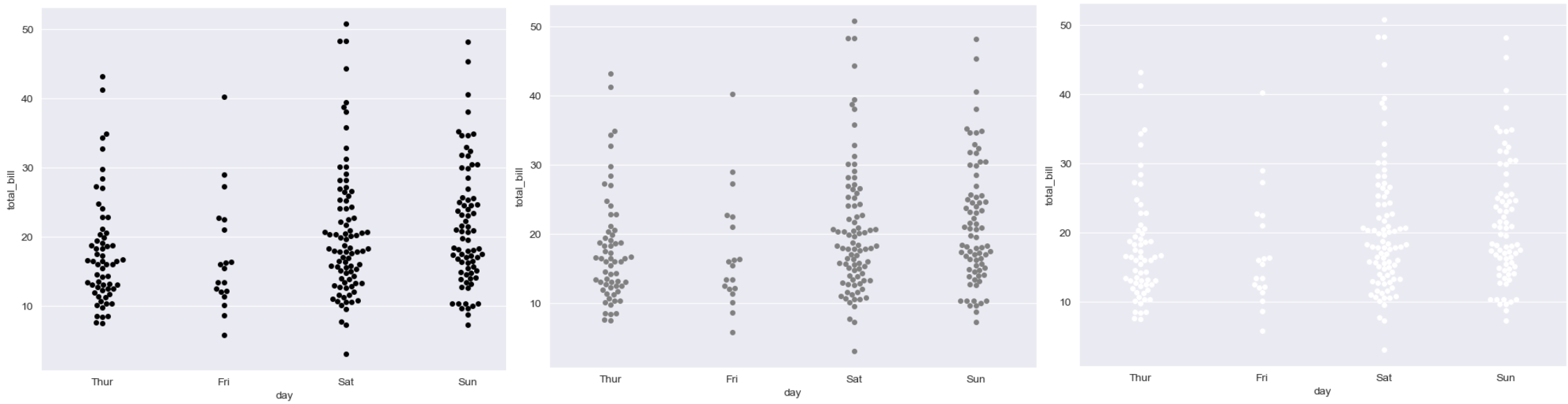
swarmplot & boxplot
# boxplot with swarmplot
plt.figure(figsize=(8, 6))
sns.boxplot(x='day', y='total_bill', data= tips)
sns.swarmplot(x='day', y='total_bill', data=tips, color='0')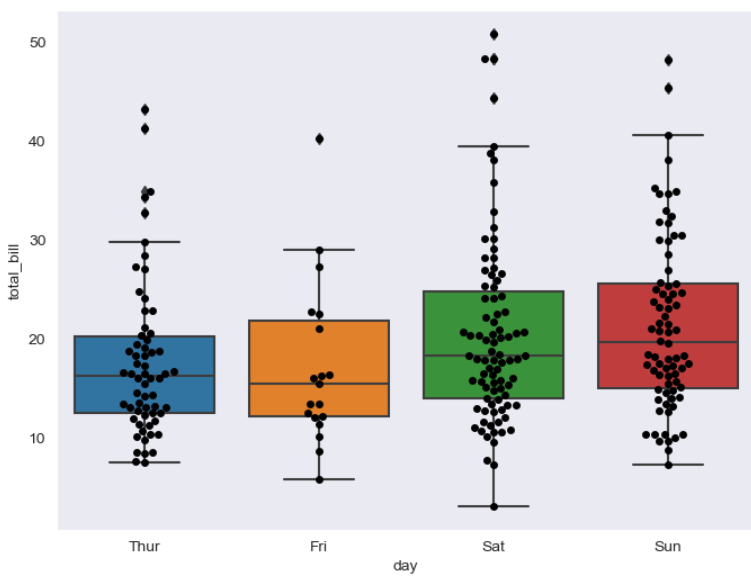
기본적으로는 동시에 수행하여 보다 더 시각적으로 표현한다.
lmplot
lmplot는 선형 회귀 모델(x값에 따른 y추정치를 함수로 표현)의 적합선을 데이터와 함께 시각화하는 함수입니다.
# total_bill 과 tip 사이의 관계 파악
sns.set_style('darkgrid')
sns.lmplot(x='total_bill', y='tip', data=tips, height=7)
plt.show()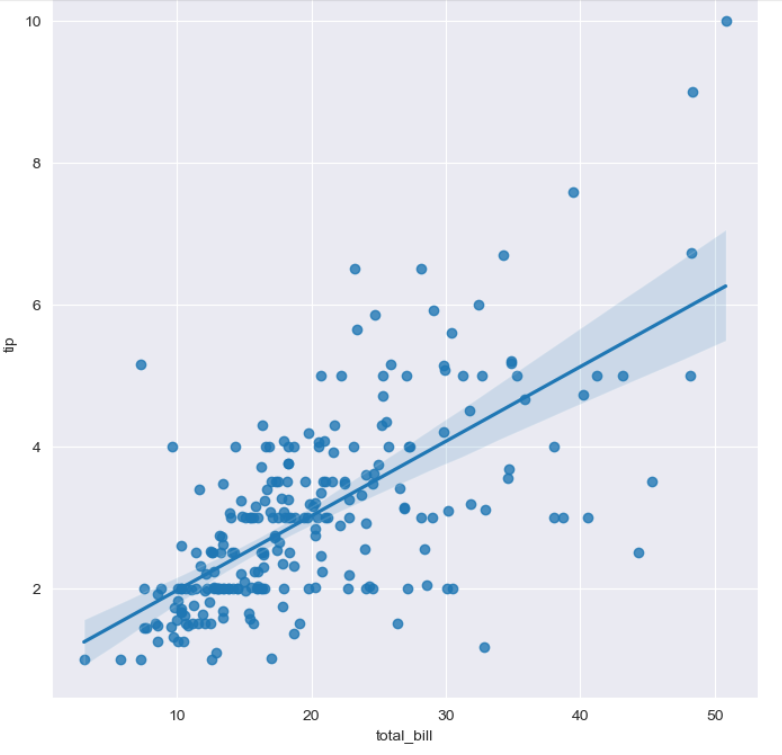
# hue option
sns.set_style('darkgrid')
sns.lmplot(x='total_bill', y='tip', data=tips, height=7, hue='smoker')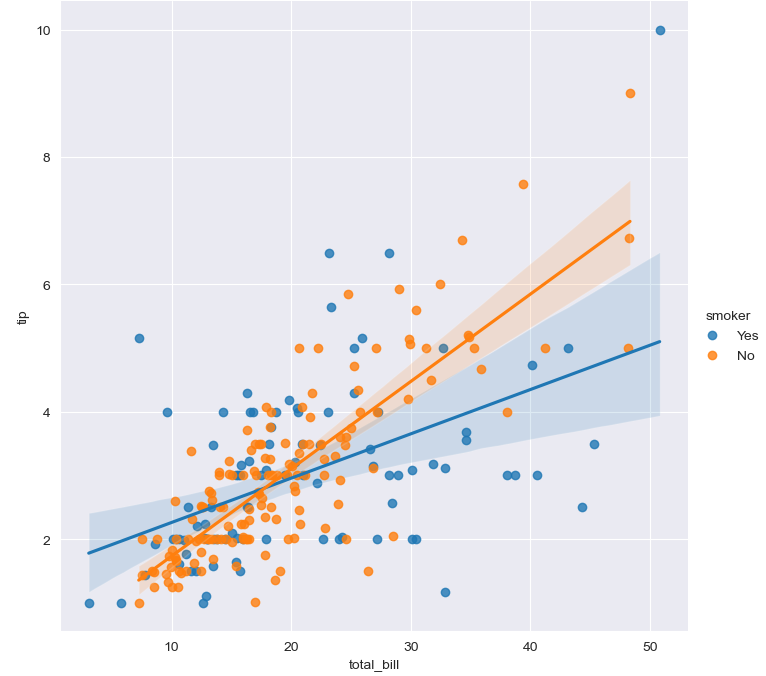
hue를 지정하여 boxplot 때와 같이 x값을 특정 조건에 따라 이분할 하였을때의 값을 그릴수 있다.
예제3 : heatmap
sns.heatmap() 함수는 데이터를 히트맵으로 시각화하는 함수입니다. 히트맵은 데이터를 색상으로 표현하여 데이터의 패턴과 분포를 시각화하는 데 유용한 도구입니다.
사용 데이터 filghts data
flights = sns.load_dataset('flights')
flights.head()
항공권에 관련된 데이터임을 알수있는데 이것을 일반 적인 그래프로 표현하기엔 어려움이 있는데 이럴때 heatmap 형식의 그래프로 나타내면 직관적인 분석이 가능하게 할 수 있다.
# pivot
# index, columns, values
flights = flights.pivot(index='month', columns='year', values='passengers')
flights.head()
plt.figure(figsize=(10,6))
# annot = True : 숫자를 표시 여부
# fmt : 정수 / 실수
sns.heatmap(data=flights, annot=True, fmt='d') d는 정수 f는 실수
plt.show()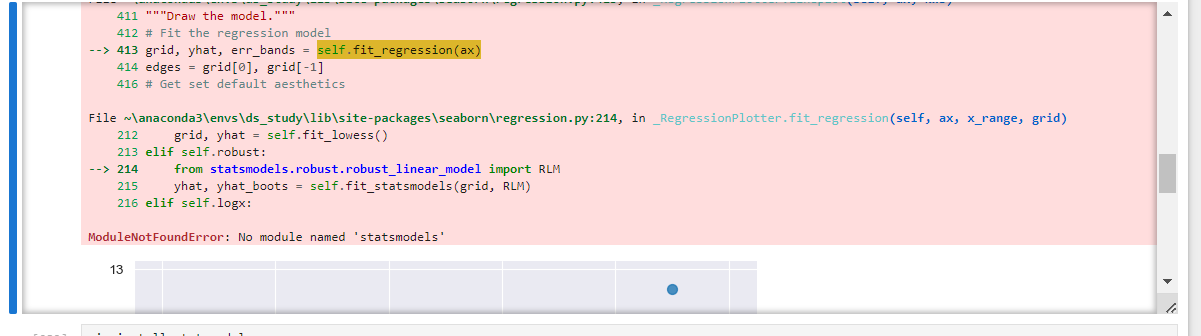
plt.figure(figsize=(10,8))
# cmap : 색상 지정 옐로우 그린 블루 순으로 그라데이션으로 표현 하라는 뜻
sns.heatmap(data=flights, annot=True, fmt='d', cmap='YlGnBu')
plt.show()
예제4 : pairplot
pairplot 기능은 데이터 프레임의 데이터를 사용하여 변수 간의 관계를 시각화합니다.
사용 데이터 iris data
머신러닝 파트에서 오래 볼 녀석의 등장
iris = sns.load_dataset('iris')
iris.tail()# pairplot
sns.set_style('ticks')
sns.pairplot(iris)
plt.show()
다음과 같이 데이터프레임 내부에 모든 데이터 간의 관계를 시각화 할수있습니다.
또 위에서 언급 하지 못한 스타일이 한종류가 더 있는데 ticks라고 하며 그래프에 틱 표시를 표시합니다.
sns.pairplot(iris, hue='species')
plt.show()위에서 사용한것과 마찬가지로 hue 기능 또한 사용이 가능한데 마찬가지로 특정 조건을 기준으로 분류 할 수 있습니다.
원하는 컬럼만 pairplot
sns.pairplot(iris,
x_vars = ['sepal_width', 'sepal_length'],
y_vars = ['petal_width', 'petal_length'],
hue = 'species'
)
plt.show()특정 칼럼만 뽑아서 해당 데이터들의 관계를 표현 할 수도 있습니다.
예제5 : lmplot
선형 회귀 모델의 적합선을 데이터와 함께 시각화하는 함수입니다
사용 데이터 anscombe
anscombe = sns.load_dataset('anscombe')
anscombe.tail()sns.set_style('darkgrid')
# 'dataset'이 'I'인 부분의 데이터를 사용
sns.lmplot(x='x', y='y', data=anscombe.query("dataset=='I'"), ci= None, height=7)
# ci : 신뢰구간 선택
plt.show()
'dataset'이 'I'인 부분의 데이터를 사용하여 'x'와 'y'의 관계를 나타내는 산점도와 회귀선을 생성합니다.
sns.set_style('darkgrid')
sns.lmplot(x='x', y='y', data=anscombe.query("dataset=='I'"), ci= None, height=7, scatter_kws ={'s': 100})
# scatter_kws : 점 크기를 선택 할수 있음
plt.show()sns.set_style('darkgrid')
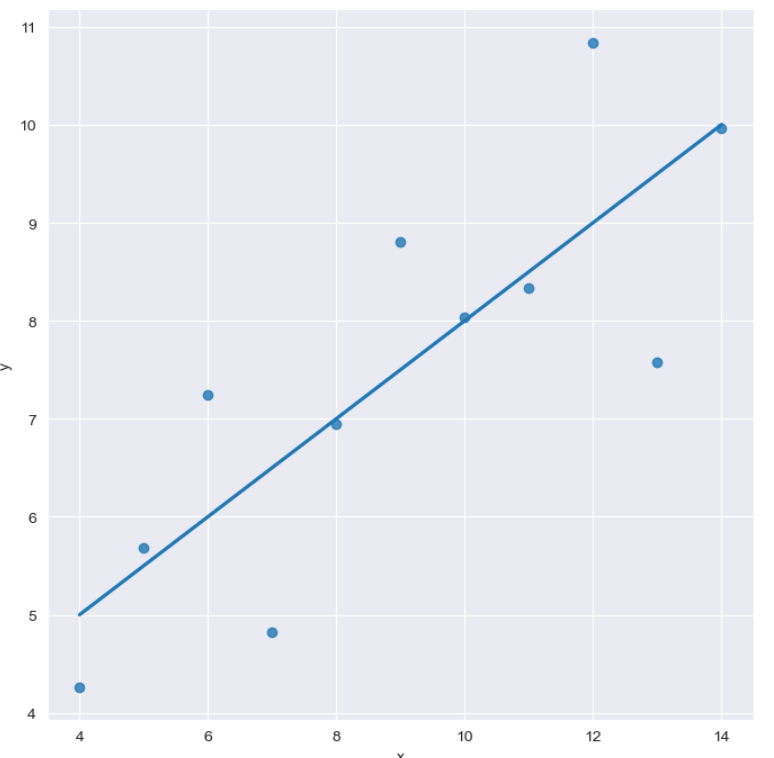
sns.lmplot(x='x',
y='y',
data=anscombe.query("dataset=='III'"),
ci= None,
robust=True,
height=7,
scatter_kws={'s': 50}
)
plt.show()robust=True를 사용하여 경향에서 심하게 벗어난 데이터가 반영되는것을 방지하여 보다 정확한 선형회귀 그래프를 작성하였습니다.
오류
robust=True를 선언 하면 다음과 같은 오류가 발생하는데 위에서와 마찬가지로
pip install statsmodels
를 한번 딸깍 해주면 해결됩니다.
