
서울시 CCTV 배치 비율을 시각화 하자!
※주피터 노트북으로 진행 하여 head명령어 와 같은 명령어가 자주 나올수도 있습니다.
step1 데이터 읽기
CCTV_Seoul = pd.read_csv('data/01. Seoul_CCTV.csv')
CCTV_Seoul.head()
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace=True)
CCTV_Seoul.head()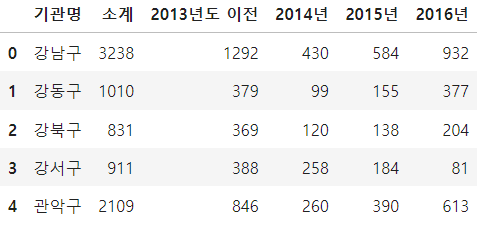
서울 구별 CCTV 개수 파일을 열어 주고 기관명 컬럼의 이름을 구별로 수정하였고 inplace 명령을 사용하여 변수 선언 없이 반영 하도록 하였음
pop_Seoul = pd.read_excel("data/01. Seoul_Population.xls")
pop_Seoul.head()
pop_Seoul = pd.read_excel(
"data/01. Seoul_Population.xls", header=2, usecols ='B, D, G, J, N'
)
pop_Seoul.head()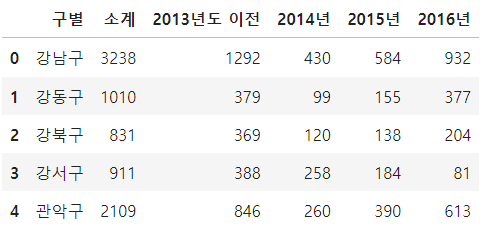
서울의 인구수 데이터를 불러온 뒤 확인하고 해당데이터의 필요한 부분을 골라 불러 올수 있도록 하였습니다. 0,1번 행의 데이터는 필요가 없고 인구수의 남여 비율이 필요한게 아니므로 합만 불러올 수있도록 header와 usecols을 사용하여 필요한 데이터만 가져왔습니다.

pop_Seoul.rename(
columns={
pop_Seoul.columns[0]:'구별',
pop_Seoul.columns[1]:'인구수',
pop_Seoul.columns[2]:'한국인',
pop_Seoul.columns[3]:'외국인',
pop_Seoul.columns[4]:'고령자'
},
inplace=True
)
pop_Seoul.head()
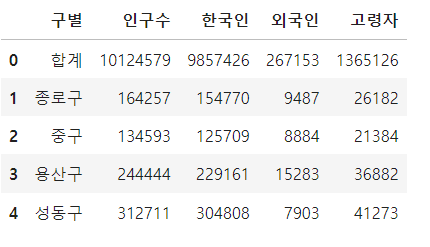
자치구, 계, 계1, 계2, 65세이상고령자 라고 되어있는 부분을 구별, 인구수, 한국인, 외국인, 고령자로 칼럼명을 바꿔주었습니다.
step2 CCTV 데이터 흝어보기
CCTV_Seoul.sort_values(by='소계', ascending=True).head(5)
CCTV_Seoul.sort_values(by='소계', ascending=False).head(5)
CCTV_Seoul['최근증가율'] = (
(CCTV_Seoul['2016년'] + CCTV_Seoul['2015년'] + CCTV_Seoul['2014년']) / CCTV_Seoul['2013년도 이전'] * 100)
CCTV_Seoul.sort_values(by='최근증가율', ascending=False).head(5)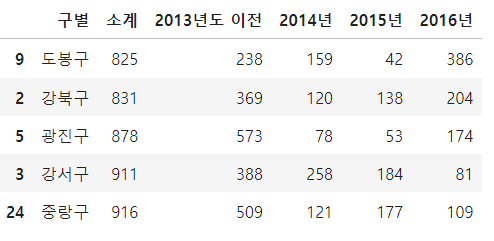
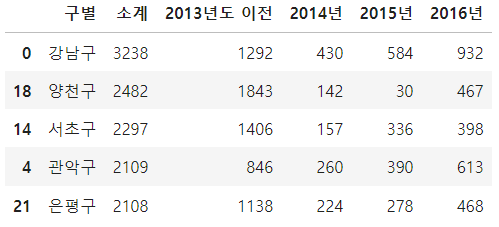
sort_values 라는 기능을 사용하여 소계 칼럼을 기준으로 오름차순, 내림차순으로 정렬 하였습니다.
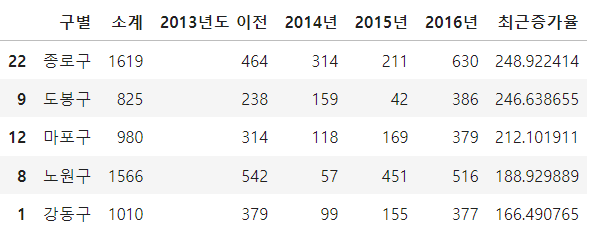
이후 최근증가율이라는 새로운 칼럼을 정의 하여 2016,2015,2014년도의 CCTV개수의 합을 2013년도 이전의 값으로 나누어 증가율 칼럼을 만들어 주었습니다.
step3 인구현황 데이터 흝어보기
pop_Seoul.head()
pop_Seoul.drop([0], axis=0, inplace=True)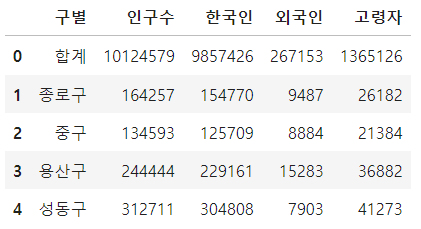
pop_Seoul 데이터와 CCTV_Seoul 데이터를 구별 칼럼을 기준으로 합칠려고 하는데 pop_Seoul의 구별 데이터에는 합계라는 열이 존재하여 이를 drop을 사용하여 제거하는 과정을 진행하였습니다.
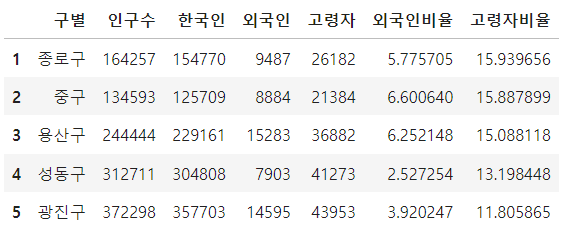
# 외국인비율, 고령자 비율
pop_Seoul['외국인비율'] = pop_Seoul['외국인'] / pop_Seoul['인구수'] * 100
pop_Seoul['고령자비율'] = pop_Seoul['고령자'] / pop_Seoul['인구수'] * 100
pop_Seoul.head()
pop_Seoul.sort_values(['외국인'], ascending=False).head(5)외국인비율과 고령자비율이라는 새로운 칼럼을 만들어 주었습니다.
step4 두 데이터 합치기
data_result = pd.merge(CCTV_Seoul, pop_Seoul, on='구별')
data_result.head(5)
del data_result['2013년도 이전']
del data_result['2014년']
data_result.drop(['2015년', '2016년'], axis=1, inplace=True)
data_result.corr()
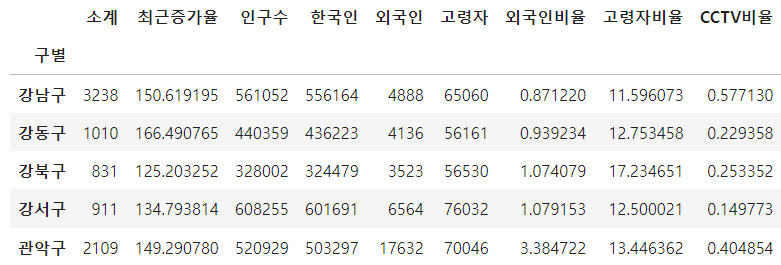
data_result['CCTV비율'] = result_Seoul['소계'] / result_Seoul['인구수'] * 100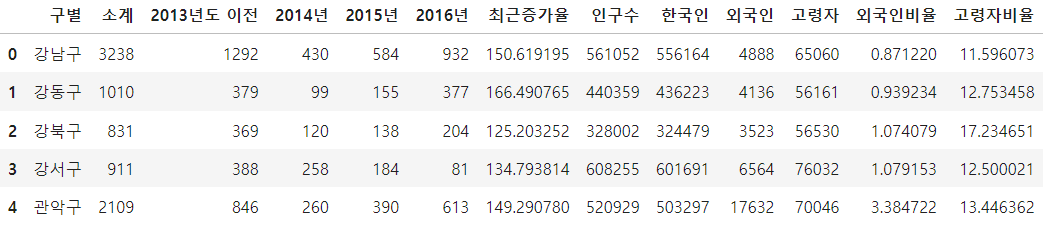
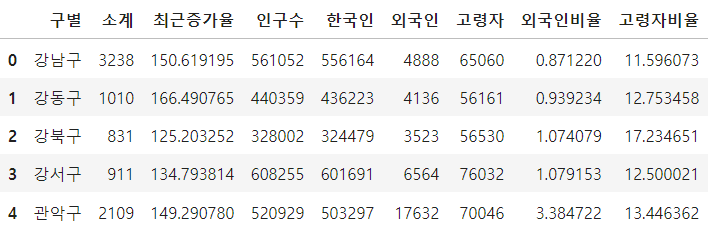
위에서 정리한 데이터프레임 2개를 merge 기능을 사용하여 합쳐주고 필요없는 데이터들을 추가로 삭제 하였습니다.
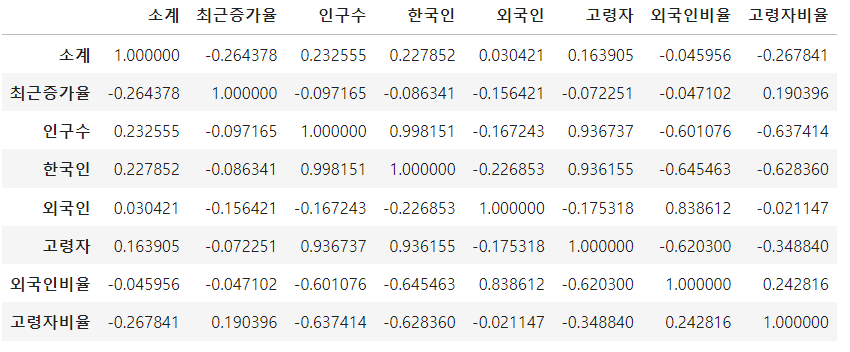
corr()기능을 사용하여 상관관계를 확인하였습니다. 아마도 머신러닝파트에서 자세하게 다룰것
또한 CCTV 비율이라는 컬럼을 새로 정의 해 줍니다.
step5 Pandas에서 plot 그리기
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams['axes.unicode_minus'] =False그래프 설명에 한글을 쓰기위한 설정을 해주고
result_Seoul['인구수'].plot(kind='bar',figsize=(10,10))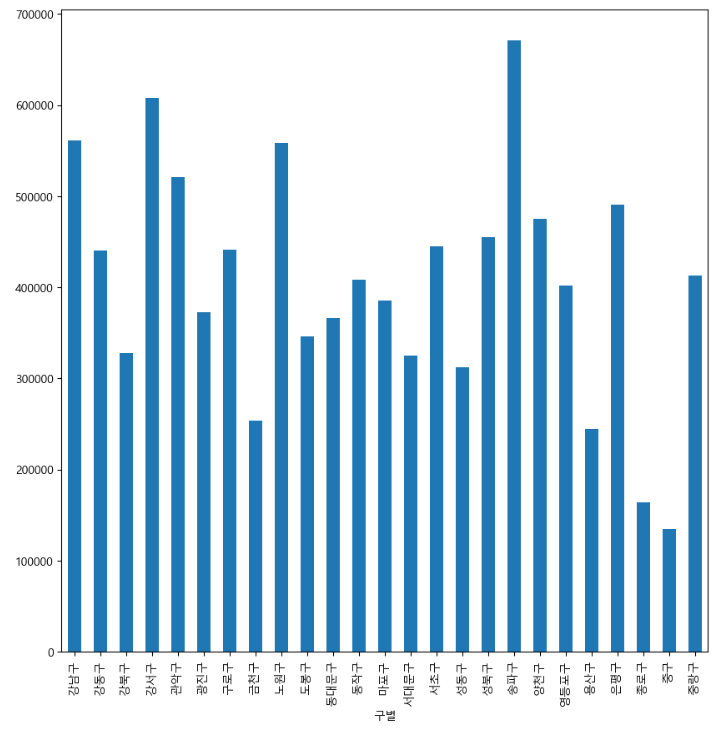
인구수를 기준으로 막대 그래프를 그려줍니다.
result_Seoul['인구수'].plot(kind='barh',figsize=(10,10));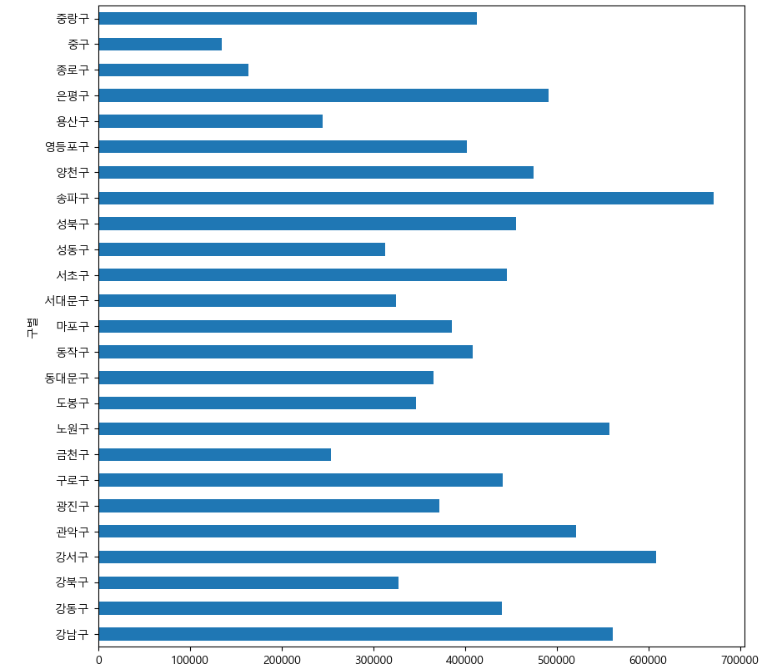
가로로 눕혀진 그래프 또한 그려줍니다.
def drawGraph():
data_result['소계'].sort_values().plot(
kind = 'barh', grid=True, figsize=(10,10), title='CCTV가 가장 많은 구')
drawGraph()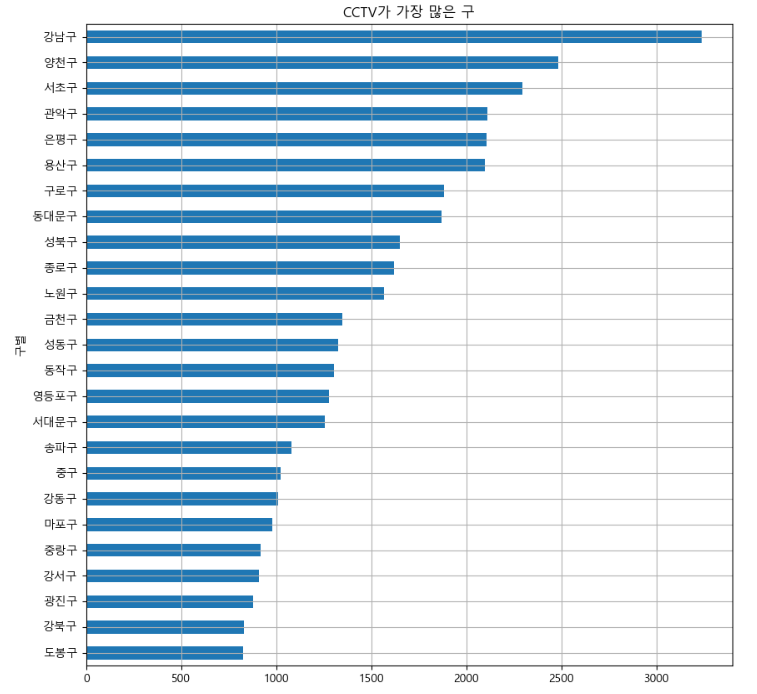
데이터를 sort_values 기능을 이용하여 소계기준으로 내림차순으로 정렬이후 그래프에 타이틀을 정의해주고 gird 기능을 추가하였습니다.
def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result['인구수'], data_result['소계'], s= 50)
plt.xlabel('인구수')
plt.ylabel('소계')
plt.show()
drawGraph()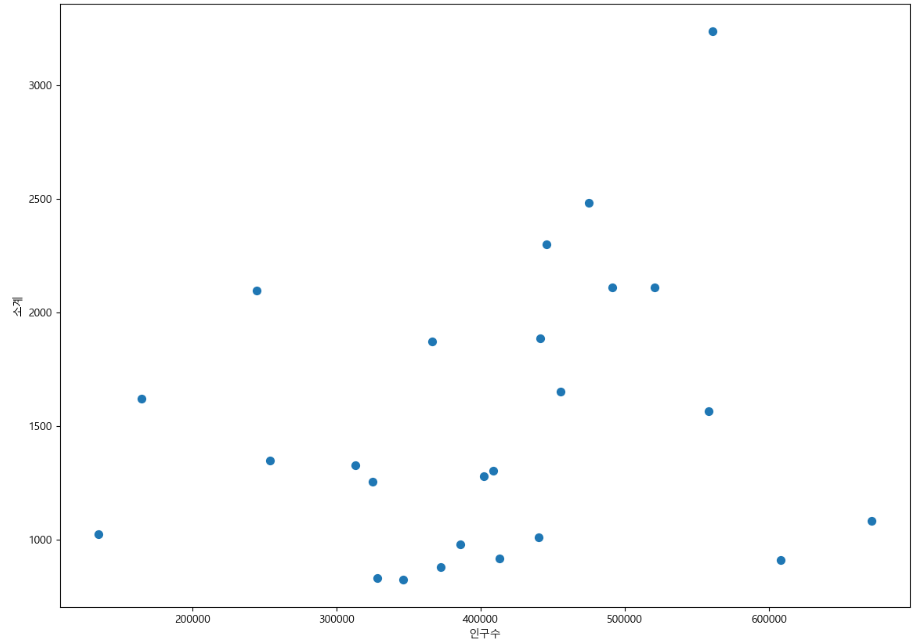
scatter 기능을 이용하여 각각의 수치가 어디에 위치하는지 표현하였습니다.
Numpy를 이용한 1차 직선 만들기
- np.polyfit() : 직선을 구성하기 위한 계수 (y절편, a계수)
- np.poly1d() : polyfit()으로 찾은 계수로 파이썬에서 사용할수있는 함수로 만들어주는 기능
# polyfit(x,y,n)을 이용하여 인구수, 소계로 그려지는 n차 함수의 계수와 y절편 정의
fpl = np.polyfit(data_result['인구수'], data_result['소계'], 1)
# poly1d(fpl) : polyfit()으로 찾은 계수로 파이썬에서 사용할수있는 함수
f1 = np.poly1d(fpl)
# linspace(a, b, n): a부터 b까지 n개의 균일한 데이터 리스트
fx = np.linspace(100000, 700000, 100)
def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result['인구수'], data_result['소계'], s= 50)
plt.plot(fx, f1(fx), ls='dashed', lw = 3, color='g')
plt.xlabel('인구수')
plt.ylabel('소계')
plt.show()
drawGraph()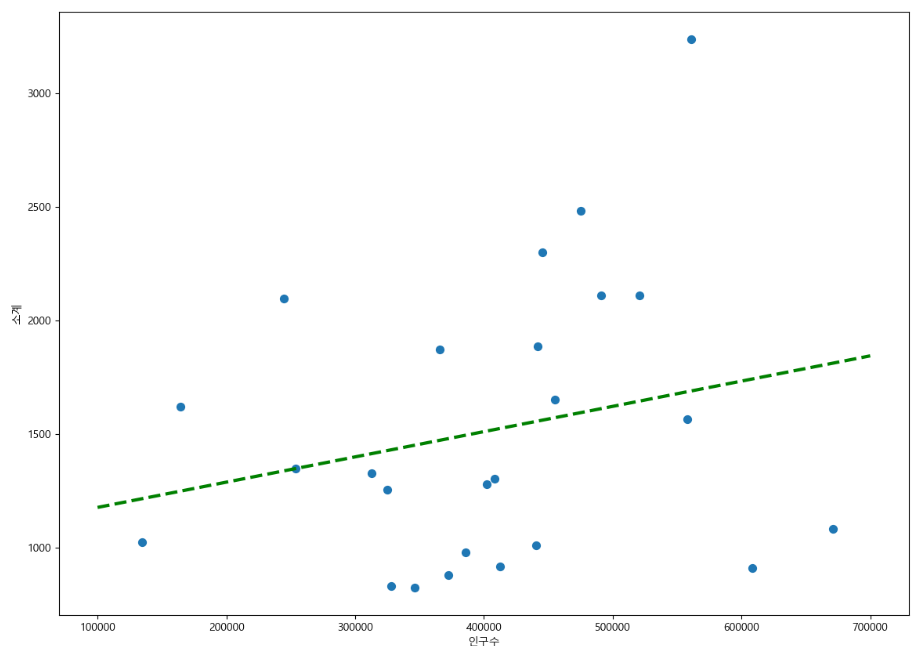
step6 강조하고싶은 데이터를 시각화 해보자
data_result['오차'] = data_result['소계'] - f1(data_result['인구수'])
data_result.head()
# 경향과 비교해서 오차가 너무 나는 데이터를 계산
df_sort_f = data_result.sort_values(by='오차', ascending=False)
df_sort_t = data_result.sort_values(by='오차', ascending=True)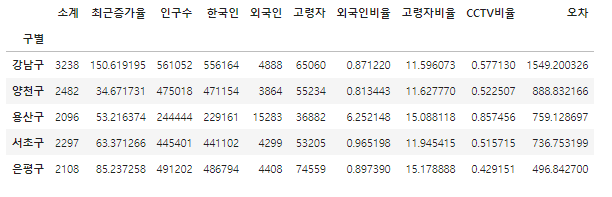
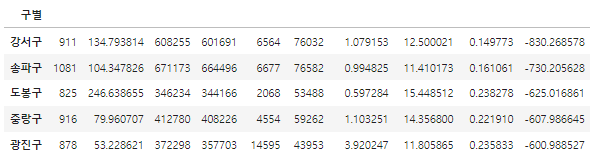
경향에서 많이 벗어난 데이터를 구하기 위해 오차 컬럼을 정의해주고 난 뒤 너무 적거나 너무 많은 경우를 구하기위해 sort_values를 사용하여 오름차순 내림차순을 각각해줍니다.
from matplotlib.colors import ListedColormap
# Colormap 를 사용자 정의(user define)로 세팅
color_step = ['#e74c3c', '#2ecc71', '#95a9a6', '#2ecc71', '#3498db', '#3498db']
my_cmap = ListedColormap(color_step)사용 할 그레프의 색상을 정의
def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result['인구수'], data_result['소계'], s= 50, c=data_result['오차'], cmap=my_cmap)
plt.plot(fx, f1(fx), ls='dashed', lw = 3, color='g')
for i in range(5):
plt.text(
df_sort_f['인구수'][i] * 1.02,
df_sort_f['소계'][i] * 0.98,
df_sort_f.index[i],
fontsize=15)
plt.text(
df_sort_t['인구수'][i] * 1.02,
df_sort_t['소계'][i] * 0.98,
df_sort_t.index[i],
fontsize=15)
plt.grid(True)
plt.colorbar()
plt.xlabel('인구수')
plt.ylabel('소계')
plt.show()
drawGraph()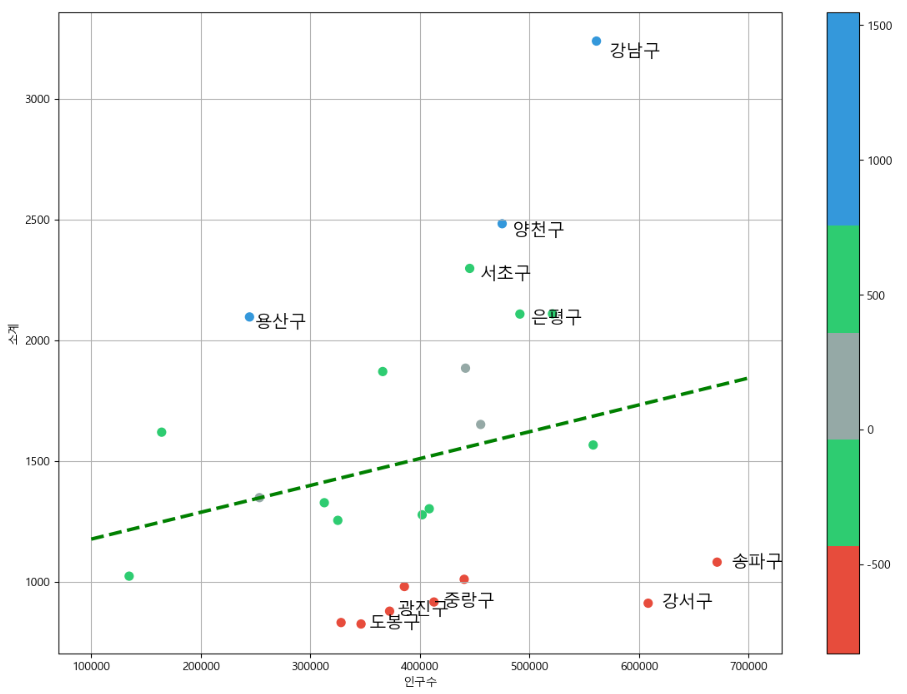
가장 적은 경우와 가장 많은 경우를 for문을 통해 찾아 이름을 표시해주고 cmap을 통해 벗어난 정도에 따라서 색상을 입혀 줍니다.
data_result.to_csv('data/01. Seoul_Population.csv', sep=',', encoding='utf-8')정리된 데이터프레임을 csv파일로 저장 해줍니다.
전체 코드
