
Beautifulsoup
Beautiful Soup은 파이썬의 HTML 및 XML 문서를 구문 분석하고 검색하기 위한 라이브러리입니다. 이를 사용하면 웹 스크레이핑(웹 페이지에서 데이터 추출) 및 데이터 마이닝(데이터에서 정보 추출) 작업을 수행할 수 있습니다. 주로 웹 스크레이핑에 많이 사용되지만, XML과 같은 다른 마크업 언어도 처리할 수 있습니다.
from bs4 import BeautifulSoup
# 'zero_base.html' 파일을 읽어와서 페이지 변수에 저장합니다.
page = open("zero_base.html", 'r').read()
# BeautifulSoup을 사용하여 HTML 문서를 파싱하고, 파싱된 결과를 soup 변수에 저장합니다.
soup = BeautifulSoup(page, 'html.parser')
# soup 객체를 사용하여 파싱된 HTML 문서를 예쁘게 출력합니다.
print(soup.prettify)
# 'class' 속성이 'outer-text first-item'인 <p> 태그를 찾고, 그 텍스트 내용을 출력합니다.
outer_text_first_item_text = soup.find('p', {'class':'outer-text first-item'}).text.strip()
print(outer_text_first_item_text)
# 모든 <p> 태그를 찾아서 리스트로 반환합니다.
all_paragraphs = soup.find_all('p')
print(all_paragraphs)예제 1-1-네이버 금융 (urllib)
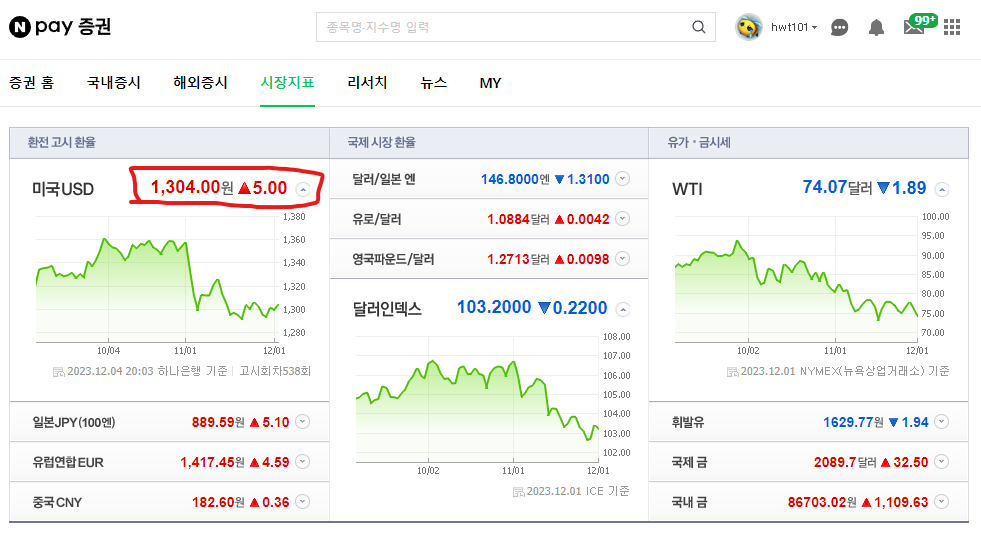
네이버 금융 사이트의 미국 USD 값을 크롤링 해보았습니다.
from urllib.request import urlopen
url = 'https://finance.naver.com/marketindex/'
# page = urlopen(url)
response = urlopen(url)
# response.status
soup = BeautifulSoup(response, 'html.parser')
print(soup.prettify())
soup.find_all('span', class_ = 'value')[0].text
첫번째 예제에서는 urllib 라이브러리를 사용하여 HTTP 요청을 보내 해당 사이트의 데이터를 BeautifulSoup으로 긁어왔고 이를 pretttify를 사용하여 이쁘게 정렬해줍니다.
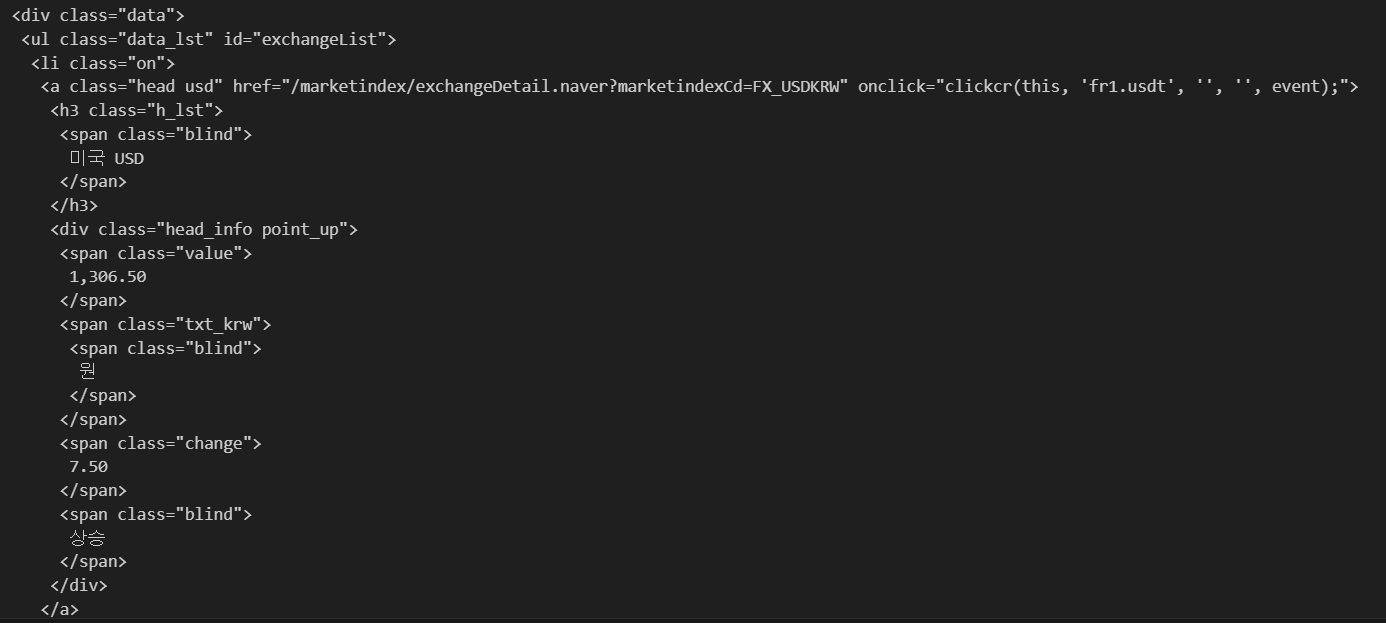
여기서 미국USD값은 id=span, class=value 안에 존재하므로 아래와 같이 테그 위치를 지정하여
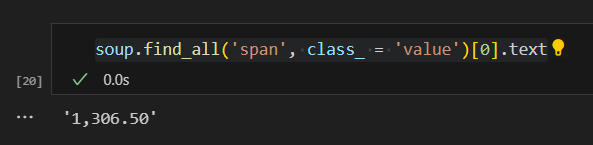
다음과 같이 값을 불러왔습니다.
예제 1-2-네이버 금융(requests)
이번에는 requests 라이브러리를 사용하여 데이터 크롤링을 하였습니다.
import requests
url = 'https://finance.naver.com/marketindex/'
response = requests.get(url)
# response.text
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
#id => #
# class => .
exchangelist = soup.select('#exchangeList > li')
len(exchangelist), exchangelist위에서와 거의 비슷하지만 request와 liburl의 가장 큰 차이는 특정 데이터를 파싱할때 find를 사용하지 않고 select를 사용하여 데이터를 크롤링합니다. 또한 class값은 '.'으로 id값은 '#'으로 표현합니다.
# 4개의 데이터 수집
exchange_datas = []
baseUrl = 'https://finance.naver.com'
for item in exchangelist:
data = {
'title' : item.select_one('.h_lst').text,
'exchange' : item.select_one('.value').text,
'change' : item.select_one('.change').text,
'undown' : item.select_one('div.head_info.point_up > .blind').text,
'link' : baseUrl + item.select_one('a').get('href')
}
exchange_datas.append(data)
df = pd.DataFrame(exchange_datas)
df
df.to_excel('naverfinance.xlsx')네이버 금융에 있는 환율의 추세를 전부 파싱하고 이를 엑셀 파일로 만들 수 있는 코드를 작성하였습니다.
title, exchange, change, undown
예제 2-위키백과 문서 정보 가져오기
여명의 눈동자 HTML을 가져와 BeautifulSoup을 사용하여 출력해줍니다. 그런데
 한글로 여명의 눈동자라 되어있던 URL이 VScode로 불러 오면서 utf-8 인코딩이 풀려
한글로 여명의 눈동자라 되어있던 URL이 VScode로 불러 오면서 utf-8 인코딩이 풀려

다음과 같이 변하게 됩니다. 이러한 점을 고려하여 변하지 않은 부분까지만 html로 선언해주고 뒤에 인코딩이 필요한 부분은 urllib.parse.quote 기능을 사용하여 인코딩시킨뒤에 붙여 이러한 문제를 해결해 줍니다.
import urllib
from urllib.request import urlopen, Request
html = 'https://ko.wikipedia.org/wiki/{serch_words}'
req = Request(html.format(serch_words = urllib.parse.quote('여명의_눈동자'))) # url 인코딩
response = urlopen(req)
# response.status
soup = BeautifulSoup(response, 'html.parser')
print(soup.prettify)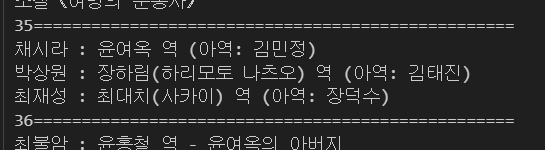
배우 정보가 나와있는 36번째 리스트 데이터를 불러와 불필요한 데이터를 제거하여 다음과 같이 출력 해줍니다.

전체 코드
