
(수업을 듣고 있는 내 표정)
수업듣다가 힘들때마다 EDA테스트를 풀었는데 어느세 다 풀고 말았다...(아직 SQL 과제가 남았다..)
연속형 확률 분포
확률 밀도 함수
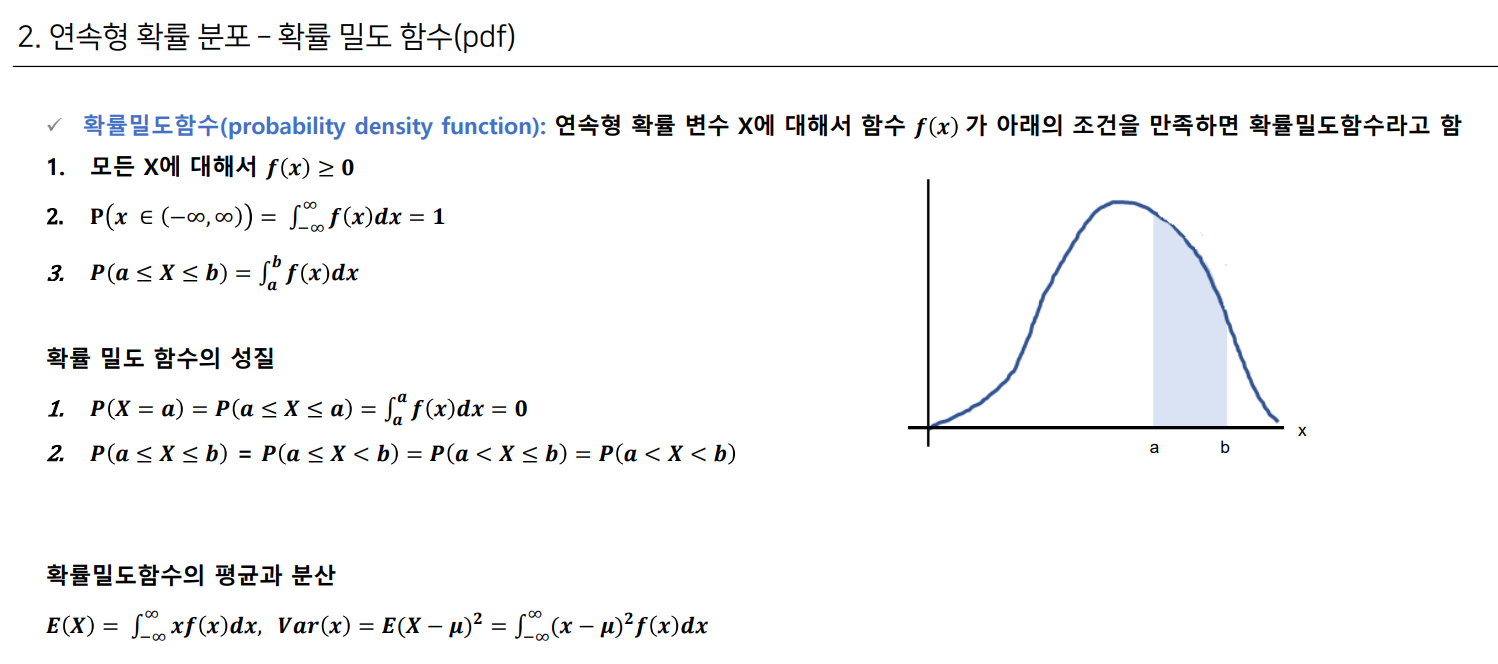
적분 개념이 들어간 것으로 확률을 함수로 표현하여 범위의 넓이를 확률로 한 것
누적 분포 함수
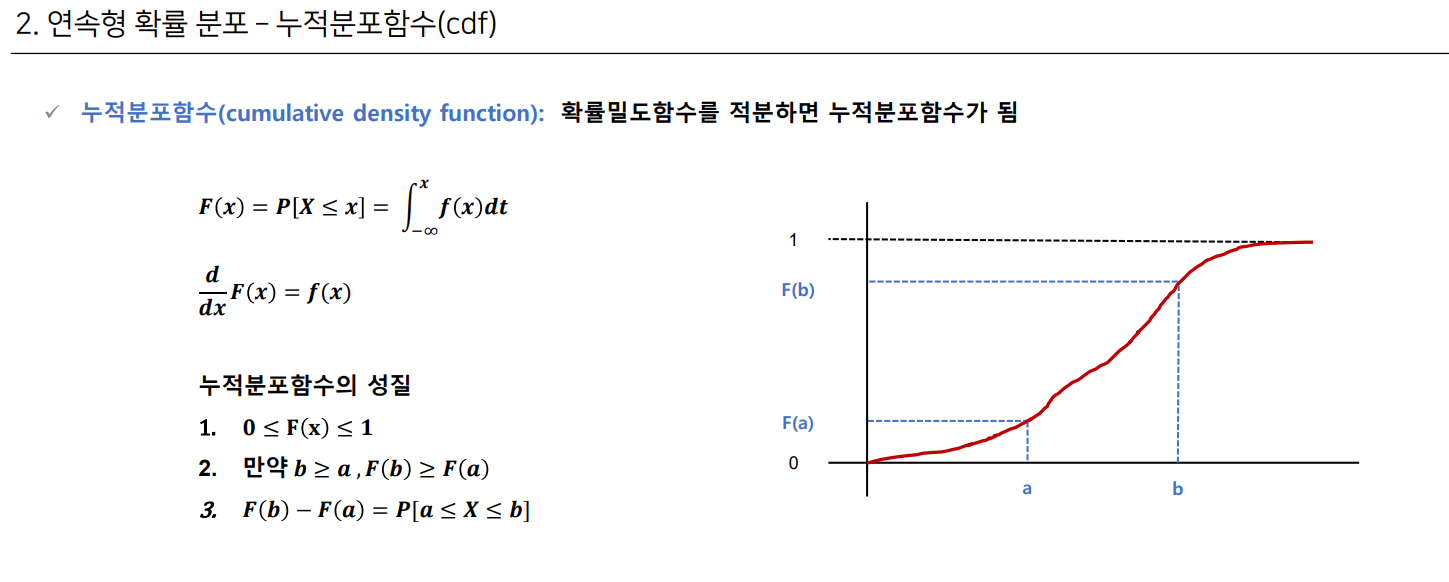
확률 밀도함수를 적분한 것으로 확률이 누적되어 0부터 1까지의 범위를 함수로 표현함
균일분포

특정 범위까지의 확률을 균일하다고 보는 함수
정규 분포
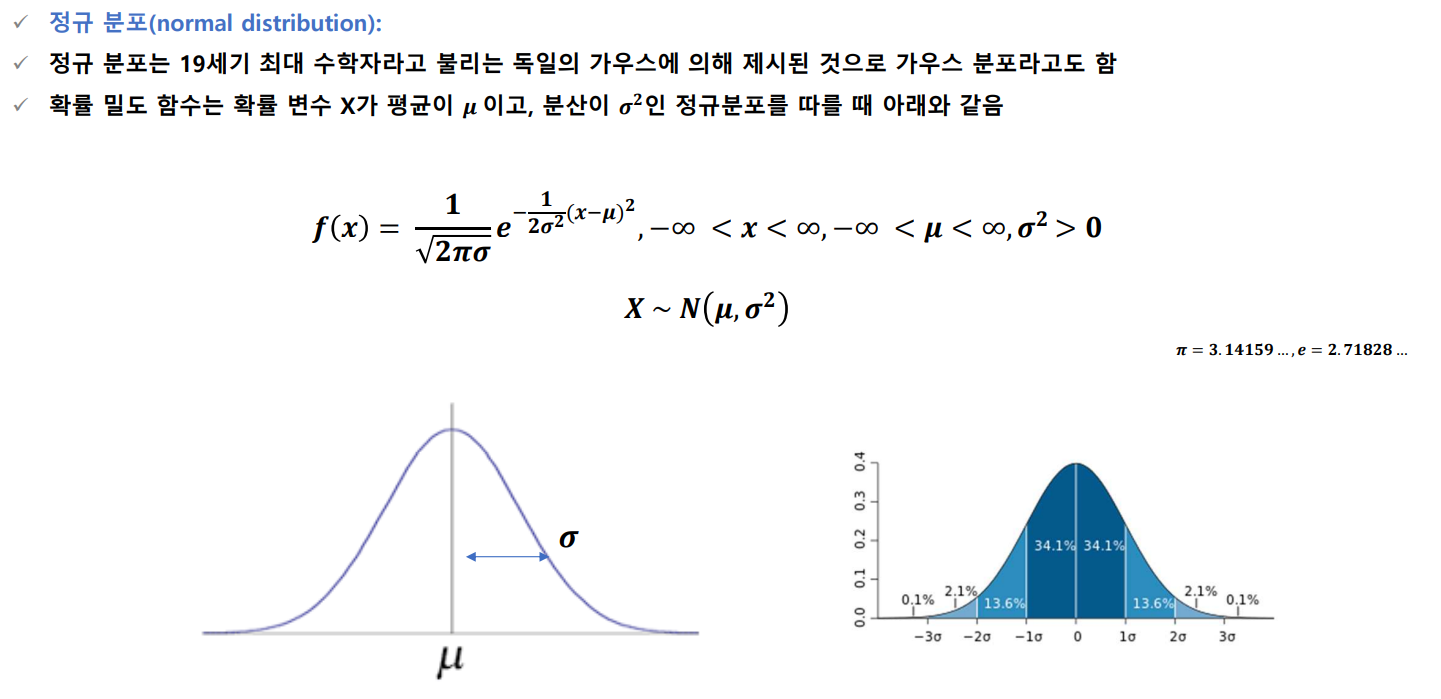
가장 중요하다는 정규 분포

정규분포의 성질은 다음과 같다.

연속형 확률 분포
지수 분포
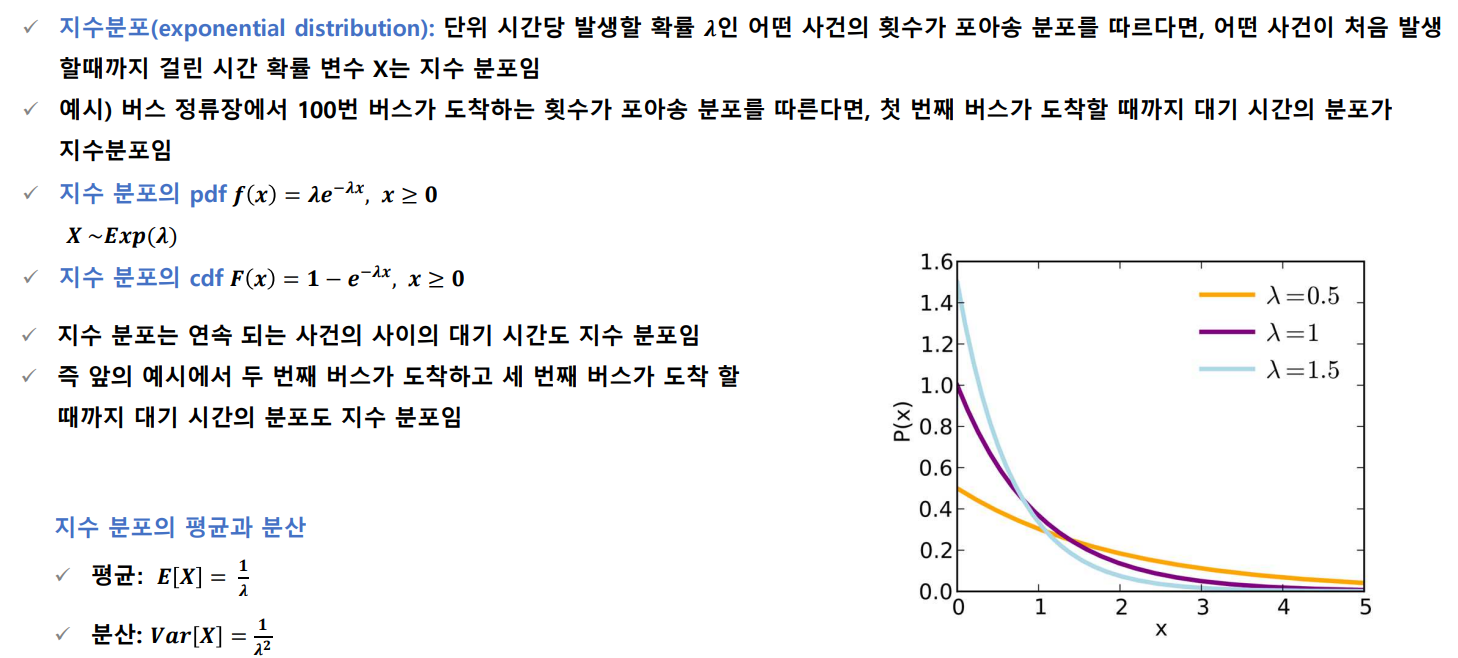
지수 분포의 무기억성

확률 분포의 관계도
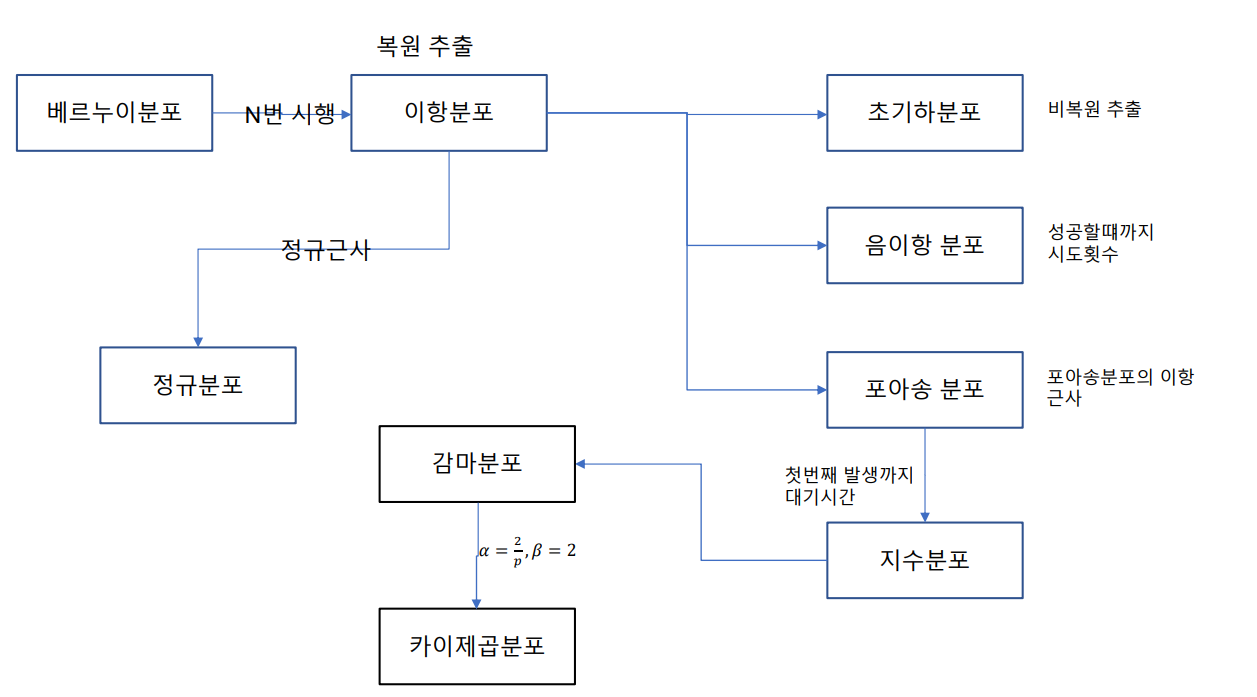
이런게 있구나 정도로 넘어가자...
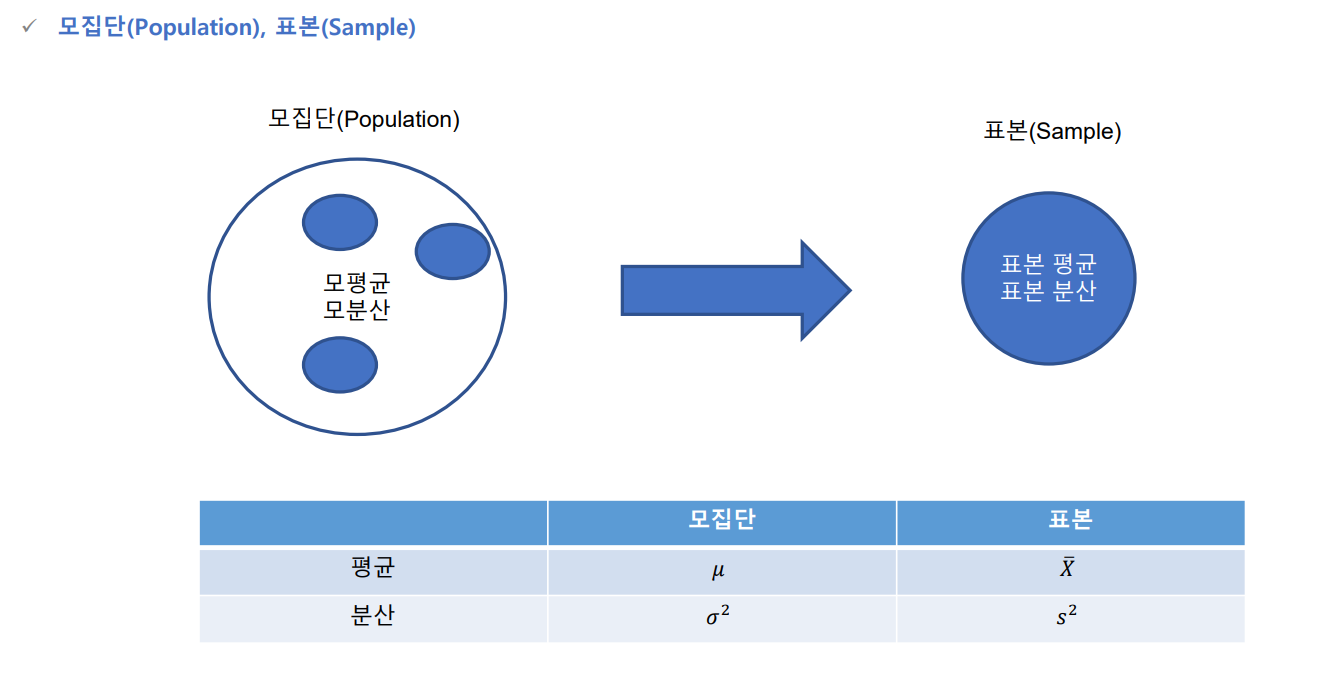
모집단과 표본
-
모집단 (Population)
모집단은 조사 대상 전체를 나타냅니다. 이는 연구자가 특정 관심을 가지고 있는 전체 집단 또는 모든 가능한 관측 대상을 포함합니다. 모집단은 종종 크고 다양한 데이터로 구성되어 있으며, 모든 통계적 분석의 기초가 됩니다. -
표본 (Sample)
표본은 모집단에서 선택된 일부분을 의미합니다. 모집단을 전체 조사하기 어려운 경우가 많기 때문에 일부 데이터만을 조사하여 모집단에 대한 정보를 얻게 됩니다. 표본의 크기와 특성은 연구의 목적과 통계적 신뢰성을 고려하여 결정됩니다.
- 모집단과 표본의 예시
예를 들어, 전체 국민의 키를 조사하려는 경우 국민 전체가 모집단이 되고, 이 중에서 무작위로 선택한 1000명의 사람들이 표본이 될 수 있습니다. 이 표본을 통해 모집단 전체의 평균 키를 추정할 수 있습니다.
- 표본추출(Sampling): 모집단으로 부터 표본을 추출 하는 것을 Sampling이라고 하며, 표본으로부터 그 특성을 찾아내고 모집단의 특성을 추론하고자 함
- 모집단에서 표본을 추출하는 방법에는 여러가지가 있음
- 복원추출(Sampling with replacement): 모집단에서 데이터를 추출 할 때 하나를 추출하고 다시 넣고 추출하는 방법으로 동일한 표본이 추출 될 수 있음
- 비복원추출(Sampling without replacement): 모집단에서 데이터를 추출 할 때 하나를 추출하고 다시 넣지 않고 추출하는 방법
- Random Sampling: 모집단에서 데이터를 추출할 때 주의할 점은 편향되지 않아야 함, 각 개체가 모두 동일한 확률로 추출하는 방법
- Over Sampling (과대 표집)
데이터셋에서 특정 클래스의 샘플이 부족한 경우, 이 클래스의 샘플을 증가시켜 데이터의 균형을 맞추는 방법입니다. Over Sampling을 통해 모델은 불균형한 클래스 간의 학습을 더 효과적으로 수행할 수 있습니다.
- Under Sampling (과소 표집)
데이터셋에서 특정 클래스가 지나치게 많아 학습에 불균형을 초래하는 경우, 이 클래스의 일부 샘플을 제거하여 균형을 맞추는 방법입니다. Under Sampling은 데이터 크기를 줄이는 단점이 있지만, 클래스 간 균형을 더 잘 유지할 수 있습니다.
표본 분포

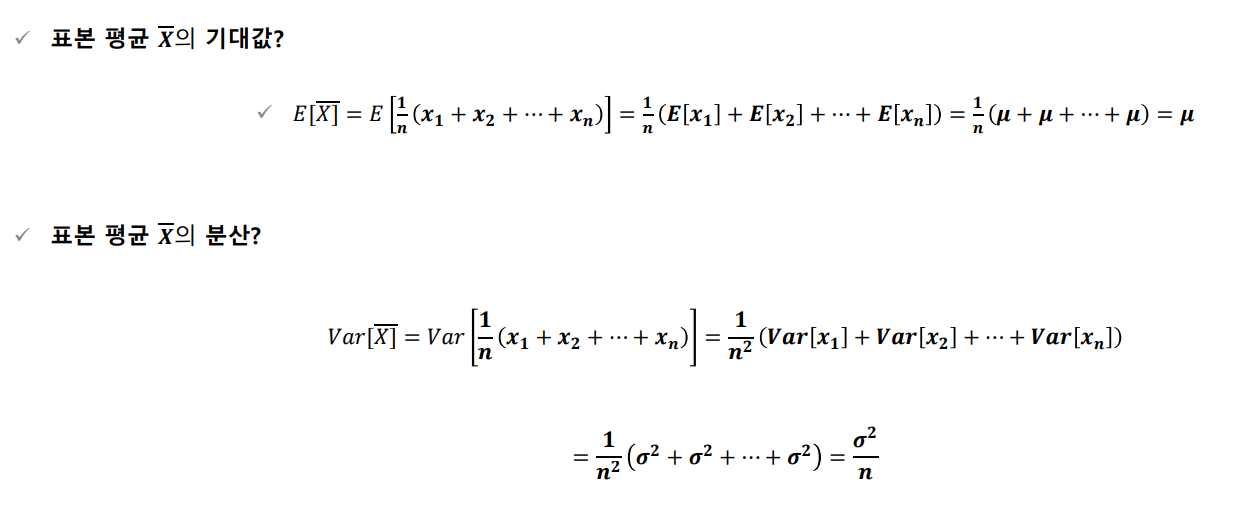
중심 극한 정리
중심극한정리는 무작위로 추출된 표본의 크기가 커질수록 표본 평균의 분포는 모집단의 분포 모양과는 관계없이 정규분포에 가까워진다는 정리입니다.
예를 들어, 키가 170cm인 사람들이 모인 모집단에서 10명을 무작위로 뽑아서 키의 평균을 구하면, 모집단의 평균인 170cm에 가까운 평균이 나올 것입니다. 그리고 100명을 뽑으면, 더 정확하게 모집단의 평균에 가까운 평균이 나올 것입니다.
중심극한정리는 표본의 크기가 커질수록 표본 평균이 모집단의 평균에 가까워진다는 가설을 정규분포로 설명한 것입니다. 즉, 표본의 크기가 커질수록 표본 평균은 정규분포의 모양을 닮아가게 된다는 것입니다.
중심극한정리는 통계학에서 매우 중요한 정리입니다. 왜냐하면, 많은 모집단의 분포가 정규분포를 따르기 때문입니다. 또한, 중심극한정리를 이용하면 모집단의 평균을 추정하거나, 모집단의 분포를 알지 못하는 상황에서도 모집단의 특성을 파악할 수 있습니다.
중심극한정리의 예를 몇 가지 들어보겠습니다.
공장에서 생산되는 제품의 무게를 측정한다고 가정해 보겠습니다. 공장에서 생산되는 제품의 무게는 정규분포를 따른다고 가정합니다. 만약 공장에서 10개의 제품을 무작위로 뽑아서 무게의 평균을 구하면, 모집단의 평균에 가까운 평균이 나올 것입니다. 그리고 100개의 제품을 뽑으면, 더 정확하게 모집단의 평균에 가까운 평균이 나올 것입니다.
시험을 본 학생들의 점수를 측정한다고 가정해 보겠습니다. 학생들의 점수는 정규분포를 따른다고 가정합니다. 만약 시험을 본 학생들 중 10명을 무작위로 뽑아서 점수의 평균을 구하면, 모집단의 평균에 가까운 평균이 나올 것입니다. 그리고 시험을 본 학생들 중 100명을 뽑으면, 더 정확하게 모집단의 평균에 가까운 평균이 나올 것입니다.
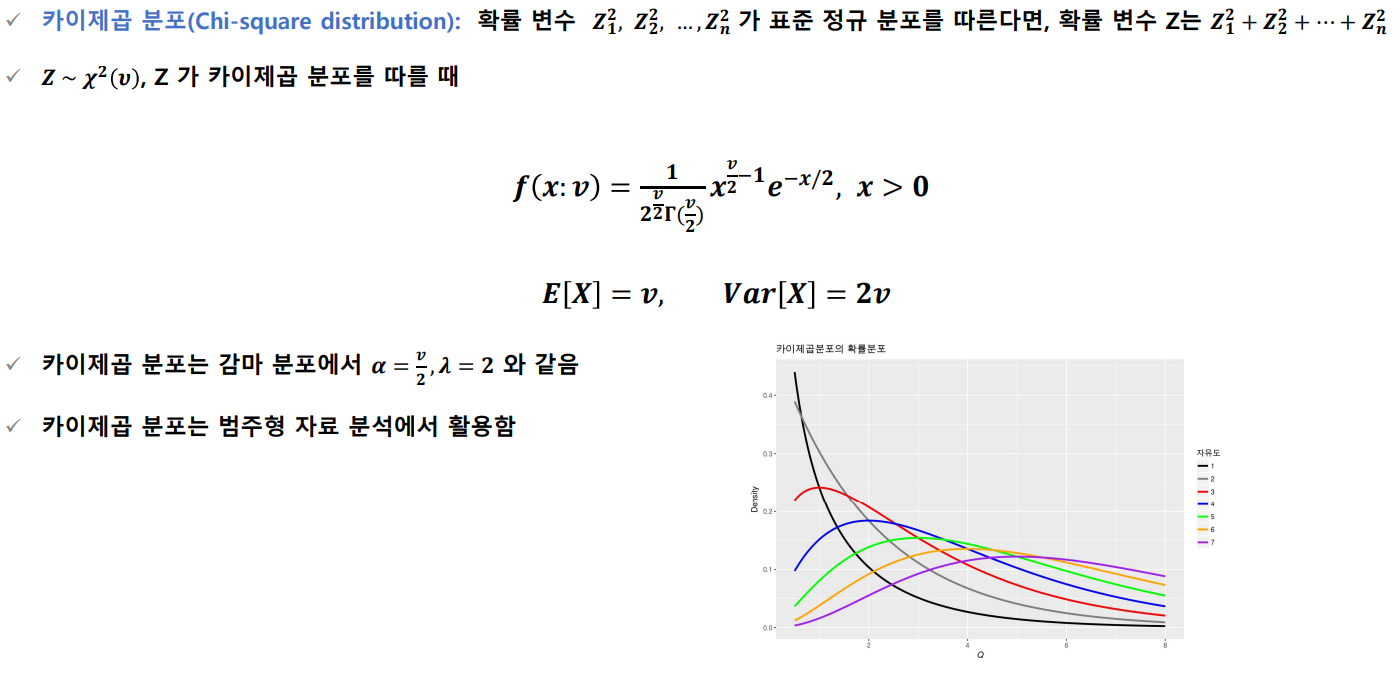
카이제곱분포
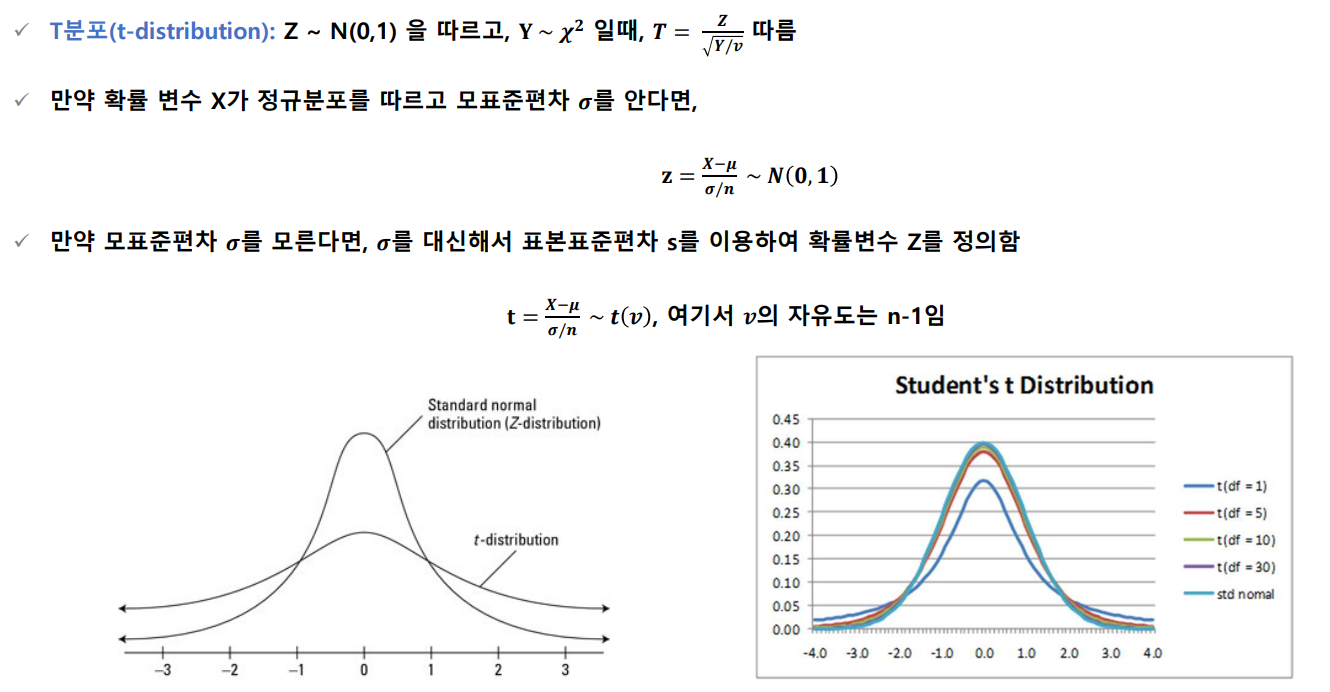
t분포
F분포

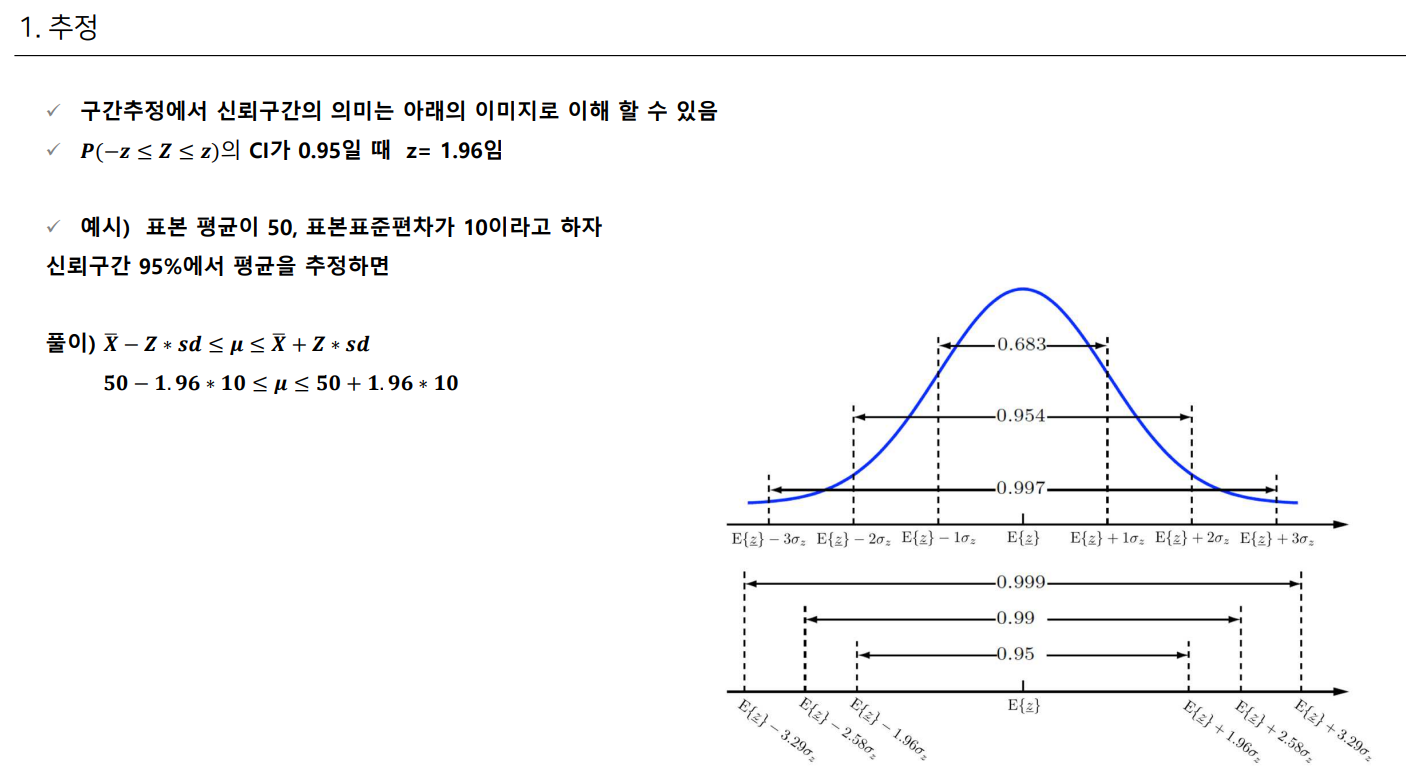
추정
추정(Estimation)의 주요 성질
-
일치성 (Consistency)
일치성은 표본의 크기가 커질수록 추정량이 모수에 접근하는 성질을 나타냅니다. 즉, 표본의 크기가 무한히 크면 추정량은 모수에 수렴해야 합니다. 일치성이 보장되면 표본의 크기가 충분하다면 추정값은 신뢰성이 높아집니다. -
불편성 (Unbiasedness)
불편성은 추정량의 기댓값이 실제 모수와 일치하는 성질을 나타냅니다. 즉, 추정량이 편향(bias)을 가지지 않아야 합니다. 편향이 없는 추정량은 임의의 표본을 통해 얻은 추정값의 평균이 실제 모수와 같아진다는 의미입니다. -
유효성 (Efficiency)
유효성은 추정량의 분산이 가능한 작아야 하는 성질을 의미합니다. 특정 모수에 대한 추정에 사용되는 추정량들 중에서 분산이 작은 것이 더 효율적인 추정량으로 간주됩니다. -
평균 오차 제곱 (Mean Squared Error, MSE)
평균 오차 제곱은 추정량의 편향과 분산을 종합적으로 평가하는 척도입니다. MSE는 불편성과 유효성을 동시에 고려하며, 작을수록 추정량의 성능이 우수하다고 판단됩니다.
모비율 추정



자료 출저 : 제로베이스
