Udemy의 강의 내용 정리
Deploying Models to Real-Time System
App에서 모델 사용법?
- 외부의 app들을 jupyter notebook에서 사용 할 수 없음
- 모델 학습을 위해 jupyter notebook을 사용할 수 있지만, 학습된 모델은 다른 곳에서 써야함
- 모델은 offline에서 train
- 모델 (학습된 모델)은 web service로 보냄
- app이 web 서비스 호출
예시) Google Cloud ML
- 학습된 모델을 sklearn.externals를 이용하여 넣음
from sklearn.externals import joblib joblib.dump(clf, 'model.joblib') - scikit-learn 프레임 워크를 이용하여 model.joblib를 구글 클라우드에 업로드
- Cloud ML Engine에서 REST API를 사용해서 예측을 실시간으로 수행함
- REST API : 클라이언트와 서버간의 통신 담당, url을 사용하여 통신(요청)을 함
( 자세한건 따로 보기)

예시) AWS (recommender system )
- 많은 데이터를 처리해야하는 ML인 경우 사용
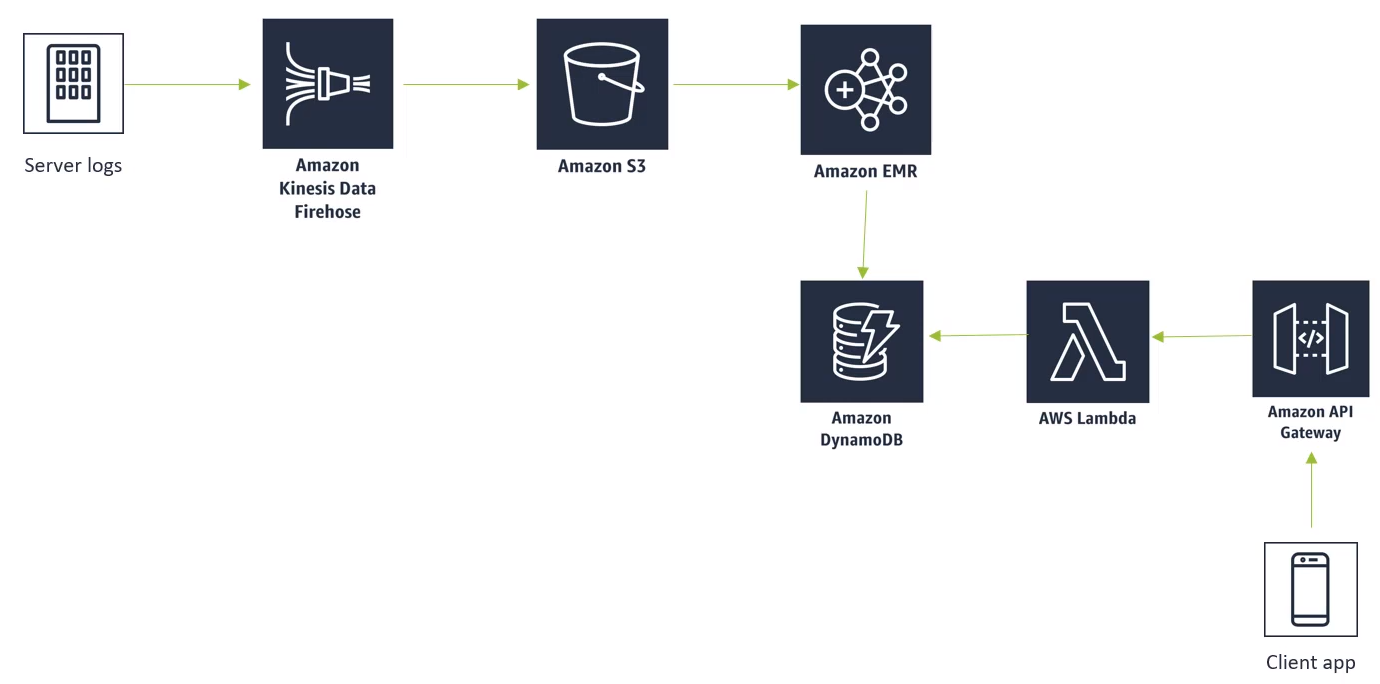
- Amazon Kinesis Data Firehose : 로그 데이터들을 Amazon S3로 보내는 역할
- Amazon EMR(Elastic MapReduce)서비스에서 S3에 있는 log data들을 가져와 사용
- log data → 추천 시스템 예시 : 구매 정보, 조회 정보, 평가 정보
- Apache Spark에서 모든 cluster로 돌려서 예측 값을 S3에서 받은 데이터를 토대로 만듦
- 미리 output들을 Amazon DynamoDB에 저장하여 빠르게 유저들에게 추천 목록을 보여주게 함
- Dynamo DB → 수직적으로 scalable, 높은 transaction 비율을 낮은 latency로 다룰 수 있음
- AWS Lambda는 간단한 함수를 통해 Dynamo DB를 접근할 수 있게 하여 유저들이 사용 가능하도록 함
- end - to - end 기법을 통해 많은 데이터를 처리할 수 있음
다른 플랫폼들
- Flask 등등..

A/B Testing Concept
A/B Test
- 통제된 실험으로 주로 웹사이트 context에서 사용
- 변경된 웹사이트와 변경 전 웹사이트의 성능을 평가하기 위함
- 성능 평가의 데이터를 통해 변경의 유효함을 체크함
평가 항목
- 디자인 변경
- UI 플로우
- 알고리즘 변경
- 가격 변동
- 등등... 유저의 사용과 연관된 항목들을 testing 할 수 있음
평가 방법
- 영향을 주는 것을 고름
- 구매 량
- 이익
- 광고 클릭 수 등 등..
- 변화에 대해 기여하고 있는 액션을 찾기 어려움
- 특히 두개 이상의 실험을 진행 중일때
변화(variance)에 주의
- 공통적인 실수
- 짧은 기간 (적은 sample 수)에 의한 실수 → 적은 양의 데이터로 분서
- 짧은 기간동안의 분석은 랜덤 변화와 같으므로 분석하면 X
- 예시: 구매량 vs 구매 소비량
How long Do I Run an Experiment?
- 중요성을 충분히 판단할 수 있을 때 (positive, negative)
- 더 이상 p-value의 의미있는 변화가 관측되지 않을 때
- plot을 통해 알 수 있음
- 시간이 중요 → 시간을 정해놓고 실험을 진행
A/B Test 문제들
상관 관계는 결과의 원인이 될 수 없다
- 낮은 p-value 점수는 잘 설계된 실험의 원인이 되지 않는다
- 랜덤 찬스(원인)이 존재할 수 있음
- 다른 요인이 적용될 수 있음
Novelty 효과
- 웹사이트의 변화는 기존 사용자들에게 관심을 끔
- 단순히 새로워서 기능을 사용할 수 있음
- 이러한 관심은 영원히 가지 않음
- 실험을 다시 수행하여 임펙트를 확인함
- 옛 웹사이트가 한동안 새로운 웹사이트 보다 성능이 더 좋을 수 있음
Seasonal Effects
- 짧은 기간동안 수행한 실험은 그 기간동안에만 유효한 결과일 수 있음
- 예시) 소비자의 행동은 크리스마스와 가까울때 소비가 증가한다
- 이러한 행위는 한 해의 모든 소비를 대표하지 않음
Selection Bias
- 가끔씩 A, B를 위한 랜덤 추출은 실제로 랜덤이 아닐 수 있음
- A/A 테스트를 주기적으로 체크
- Audit segment assignment 알고리즘
Data 오염
속성 에러
- 실험을 위한 변환에 문제
- "gray" 영역 주의
- 여러개의 실험을 동시에 진행 중인가 ? 등등..
T-test와 P-Value
중요성 판단
- 결과 값이 랜덤 값인지 실제와 같은 값인지 판별
- T-test와 P-value 사용
T-Statistic
- 두 set에 대해 standard error관련 측정 수행
- 데이터의 변화량의 차이가를 나타냄
- 높은 t-value ⇒ 두 set에 대해 차이가 있음
- 낮은 t-value ⇒ 두 set에 차이가 없음
P-Value
- 실험군과 대조군의 차이가 거의 없는 것을 만족하는 확률
- low P-value ⇒ 변화가 실제로 효과가 있음을 나타냄
- 높은 T-Statistic과 낮은 P-value ⇒ 효과가 있음
P-value 사용
- threshold 지정
- 실험이 종료 → P value 측정
- threshold보다 낮은 경우 차이가 없다는 가정 (null-hypothesis)를 거부할 수 있음

No coffee, No coding