Udemy 강의 내용 정리
Deep Learning: Pre-Requisites
Gradient Descent
가장 적당한 optimal set을 찾기 위한 방법

- 랜덤한 파라미터를 지정하여 시작
- 곡선에 따라서 다른 파라미터를 지정함 → 에러가 낮은 경우 같은 방향으로 계속 새로운 파라미터를 찾아감
- 에러가 낮아지다가 어느 지점에 높아지면 그 전 지점이 optimal set이 됨
- local optimal set이 있음 → NN에서 local minmum에 대해 처리함으로 크게 걱정 X
autodiff
완전 탐색을 통해 gradient값을 일일히 계산하는 것은 시간 낭비가 큼으로 autodiff라는 방식을 사용
(reverse mode auto diff)
- 모든 input을 위해 첫 partial derivative 들이 필요
- reverse-mode autodiff
- 많은 input과 적은 수의 output을 optimize함
- compute all partial derivatives in # of outputs + 1 graph traversals
- NN에 잘 통함
softmax
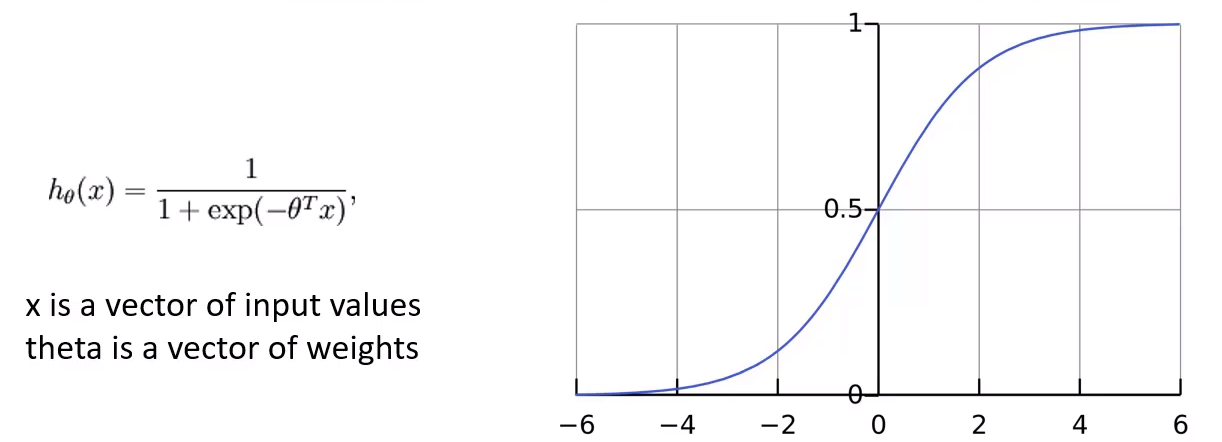
- 분류를 위해 사용
- 각 클래스에 대해 점수가 있음
- 각 클래스에 대한 확률을 나타냄→ 가장 높은 확률이 답이 됨
- NN에서 나온 결과 값에 대한 분류 수행
history of Neural Network
- NN → 뇌의 뉴런의 작동 방식을 컴퓨터에 옮기는 것과 같음
Cortical columns
- 뉴런이 stack으로 (columns) 쌓여서 정보를 병렬적으로 처리함
- "mini-columns"는 100개 정도의 뉴런이 있고, "hyper-column"은 1억개의 mini-columns로 구성
- GPU의 처리 방식과 같음
History
first artificial neurons (1943)
- AND, OR, NOT 신호를 이용
The Linear Threshold Unit (LTU)
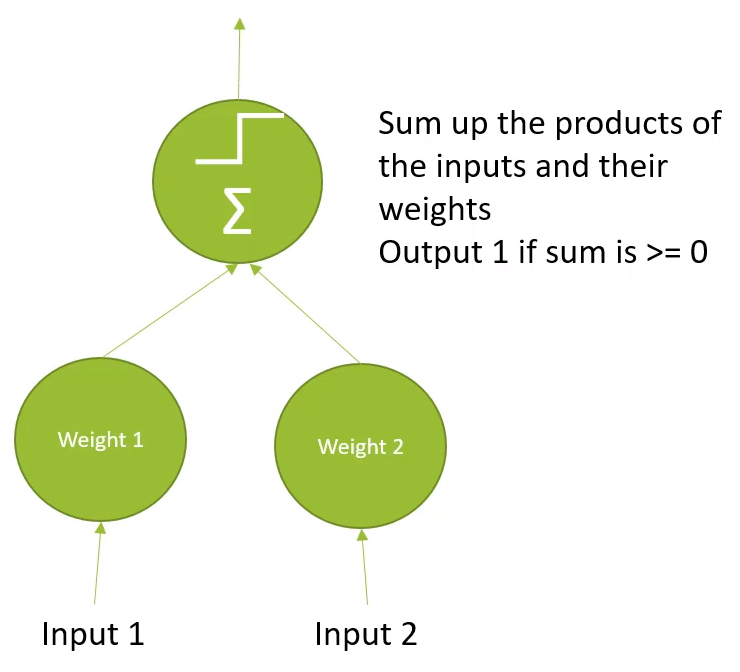
- input에 가중치를 넣음
- step function에 의해 output이 나옴
Perceptron
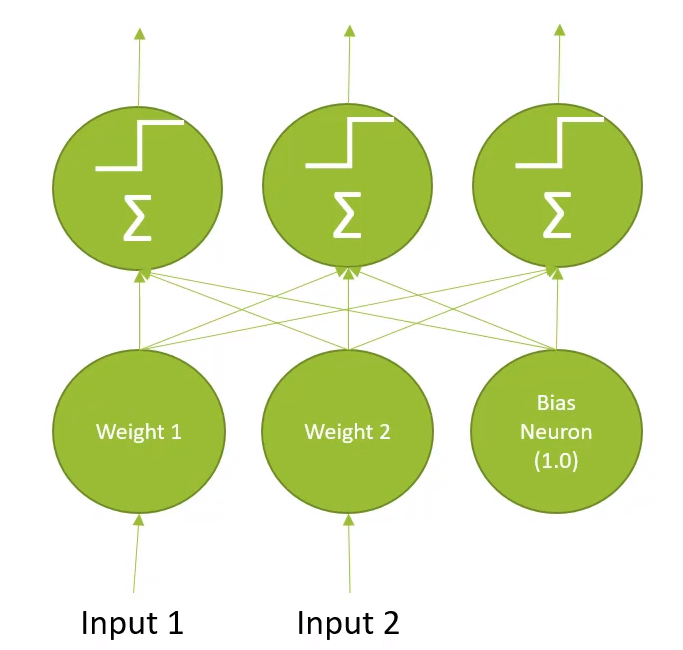
- multiple-layer of threshold unit
- 서로 간에 엃혀있음
Multi-Layer Perceptrons
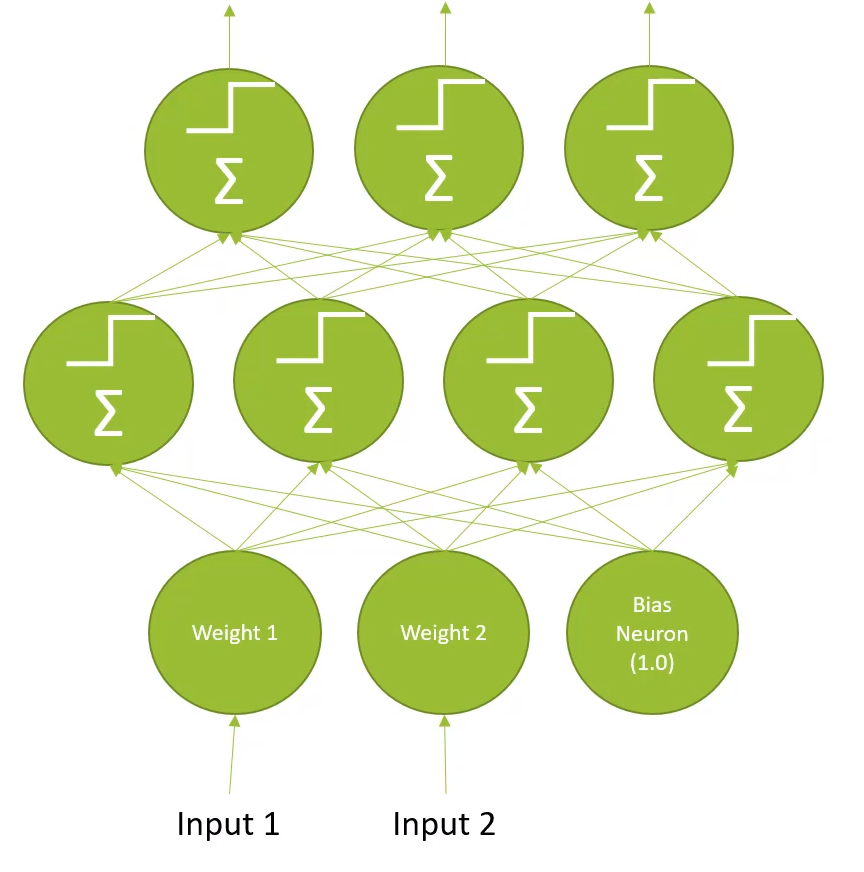
- 은닉층이 추가됨
- Deep neural network
- Modern Deep neural network → setp activation function 대신 다른 것으로 대체, softmax 추가, gradient descent 이용하여 학습 진행,
https://playground.tensorflow.org/
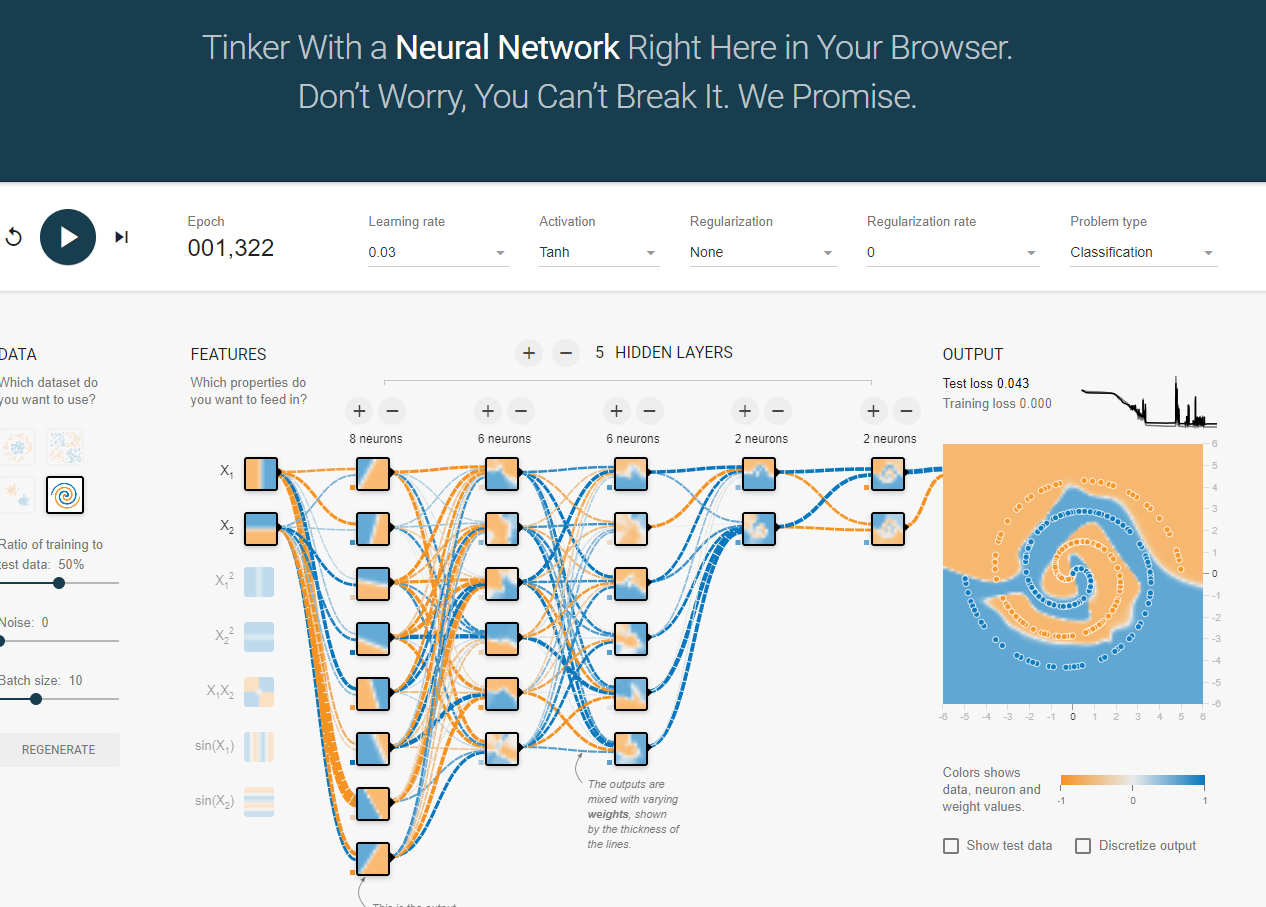
Deep learning details
Backpropagation(역전파)
- training step
- output의 에러를 계산
- 이전의 은닉층에서 뉴런들이 얼마나 기여했는지 확인
- 해당 에러에서 back-propagate하여 되돌아 감
- gradient descent를 이용하여 에러를 줄이기 위해 가중치를 바꿈
Activation functions (aka rectifier)
- Step function들이 gradient descent에서 작동 X
- 유용한 derivative가 없음
- 대안 들:
- Logistic fuction
- hyperbolic tangent function
- Exponential linear unit (ELU)
- ReLU function (Rectified Linear Unit)
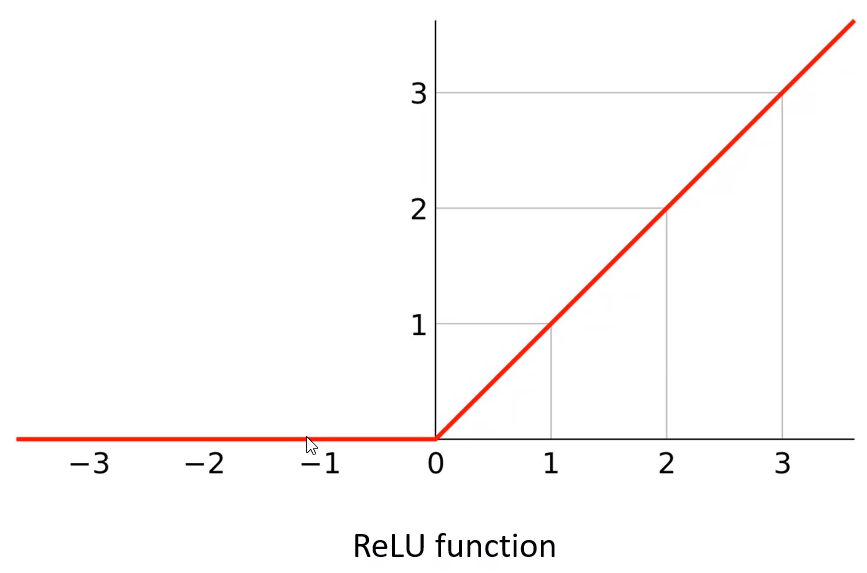
- simple, easy, 자원을 적게 소비함
- Leaky ReLU, Noisy ReLU
- ELU 가 가끔 성능이 더 나음 → 클라우드를 통한 clustering 된 경우
Optimization funcitons
gradient descent보다 더 빠른 optimizer들
- Momentum optimization
- momentum의 원리를 descent에 적용. 기울기가 평평할때는 slow, 가파를때는 fast
- Nesterov Accelerated Gradient
- RMSProp
- Adam ( 많이 사용)
- Adaptive moment estimation - momentum + RMASProp
Overfitting 피하기
- Early stopping (성능이 떨어질 때)
- 정규화 (training 도중)
- dropout - 예를 들어 모든 뉴런의 50프로 정도의 training step을 무시
Tuning your topology
- Trial & error
- 은닉층에 적은 뉴런의 수로 평가
- 더 많은 레이어를 이용하여 평가 - 진행하면서 각 레이어의 사이즈를 줄여본다
- 더 많으 레이어는 빠른 학습을 할 수 있음(더 많은 뉴런보단 레이어가 더 많은 것이 나음)
- 'model zoos' 사용

No coffee, No coding