이 글은 '딥러닝을 이용한 자연어처리 입문'을 참고하여 작성하였습니다.
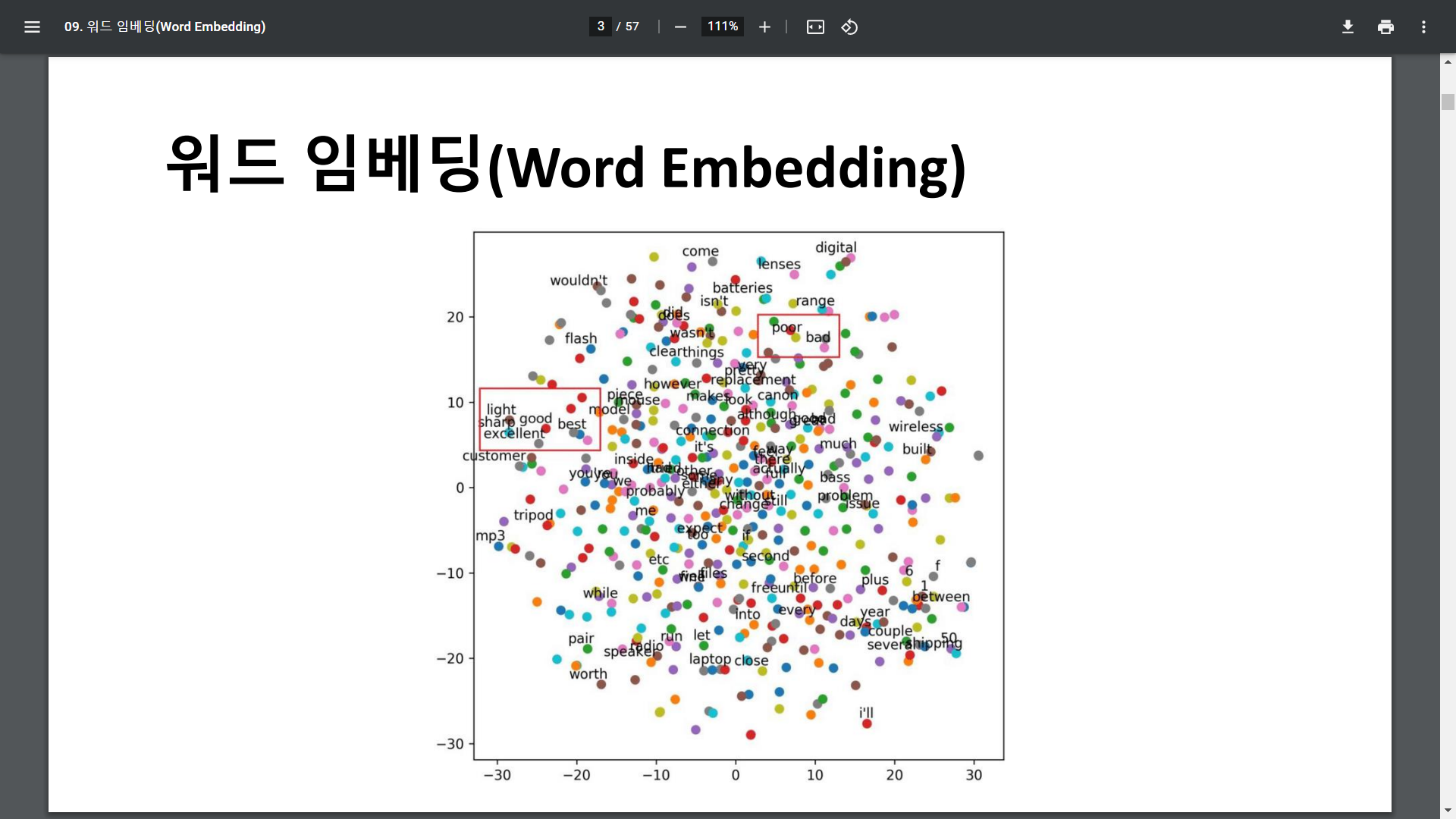
 워드 임베딩이란 텍스트를 컴퓨터가 이해할 수 있도록 숫자로 변환하는 방법입니다. 단어를 표현하는 방법에 따라 자연어처리의 성능이 달라지기 때문에 효율적으로 처리하기 위한 방법이 많이 연구되고 있습니다. 현재까지는 각 단어를 인공 신경망 학습을 통해 벡터화하는 워드 임베딩이 가장 많이 사용되고 있습니다.
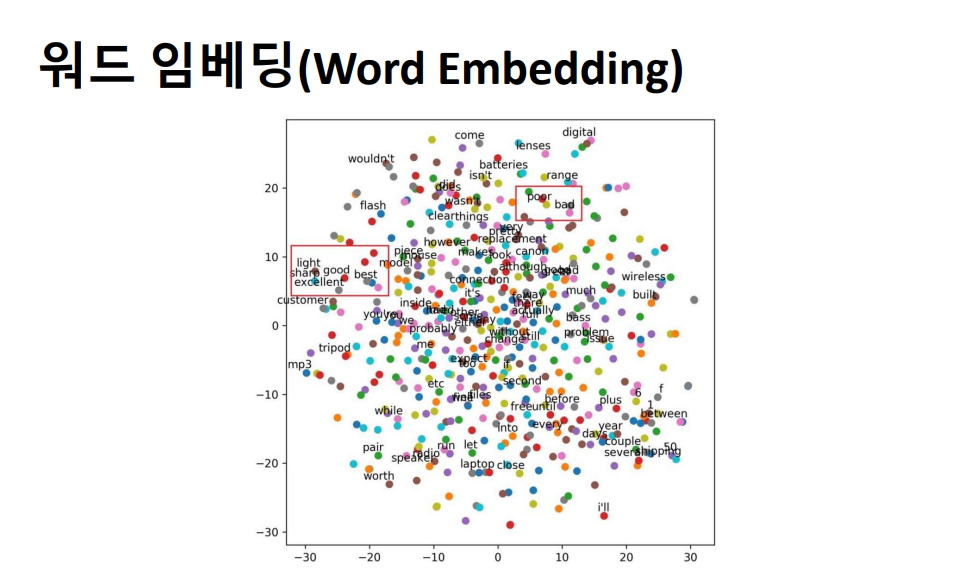
워드 임베딩이란 텍스트를 컴퓨터가 이해할 수 있도록 숫자로 변환하는 방법입니다. 단어를 표현하는 방법에 따라 자연어처리의 성능이 달라지기 때문에 효율적으로 처리하기 위한 방법이 많이 연구되고 있습니다. 현재까지는 각 단어를 인공 신경망 학습을 통해 벡터화하는 워드 임베딩이 가장 많이 사용되고 있습니다. 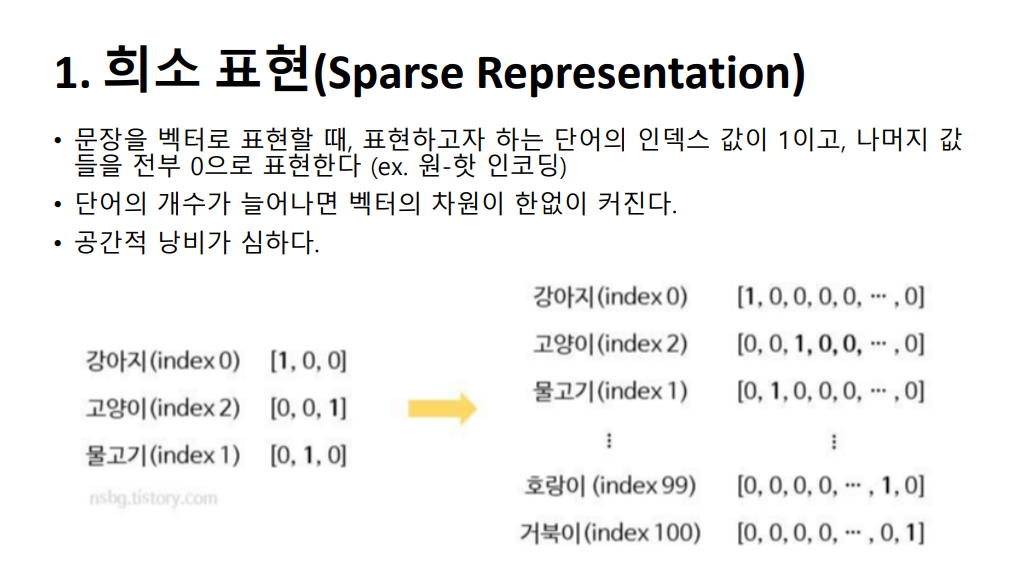 워드 임베딩을 이해하기에 앞서 관련된 개념 몇가지를 알아야하는데요, 먼저 희소 표현입니다. 앞서 배웠던 원-핫 인코딩을 떠올리시면 됩니다. 표현하고자 하는 단어의 인덱스 값을 1, 나머지는 0으로 표현한 원-핫 벡터는 희소 벡터인거죠.
워드 임베딩을 이해하기에 앞서 관련된 개념 몇가지를 알아야하는데요, 먼저 희소 표현입니다. 앞서 배웠던 원-핫 인코딩을 떠올리시면 됩니다. 표현하고자 하는 단어의 인덱스 값을 1, 나머지는 0으로 표현한 원-핫 벡터는 희소 벡터인거죠.
예시를 보시면 강아지, 고양이, 물고기 일 때 벡터의 차원은 3이지만, 단어의 개수가 1000개, 10000개로 늘어나면 벡터의 차원이 한없이 커집니다. 즉, 공간의 낭비가 심하다는 단점을 가지고 있습니다.
 그래서 나온 것이 밀집 표현인데요, 이는 희소 표현과 반대되는 개념이고 워드 임베딩 또한 밀집 표현 방식을 사용합니다. 여기서는 단어 집합의 크기가 아닌 사용자가 설정한 차원의 수로 단어 벡터의 차원이 맞춰집니다. 또한 단어 벡터는 원-핫 벡터에서처럼 0과 1만이 아니라 실수값을 가지게 됩니다. 이미지에서 보시는 바와 같이 차원이 조밀하게 표현되고 공간의 낭비도 줄인다고 하여 이를 밀집 벡터라고 합니다.
그래서 나온 것이 밀집 표현인데요, 이는 희소 표현과 반대되는 개념이고 워드 임베딩 또한 밀집 표현 방식을 사용합니다. 여기서는 단어 집합의 크기가 아닌 사용자가 설정한 차원의 수로 단어 벡터의 차원이 맞춰집니다. 또한 단어 벡터는 원-핫 벡터에서처럼 0과 1만이 아니라 실수값을 가지게 됩니다. 이미지에서 보시는 바와 같이 차원이 조밀하게 표현되고 공간의 낭비도 줄인다고 하여 이를 밀집 벡터라고 합니다. 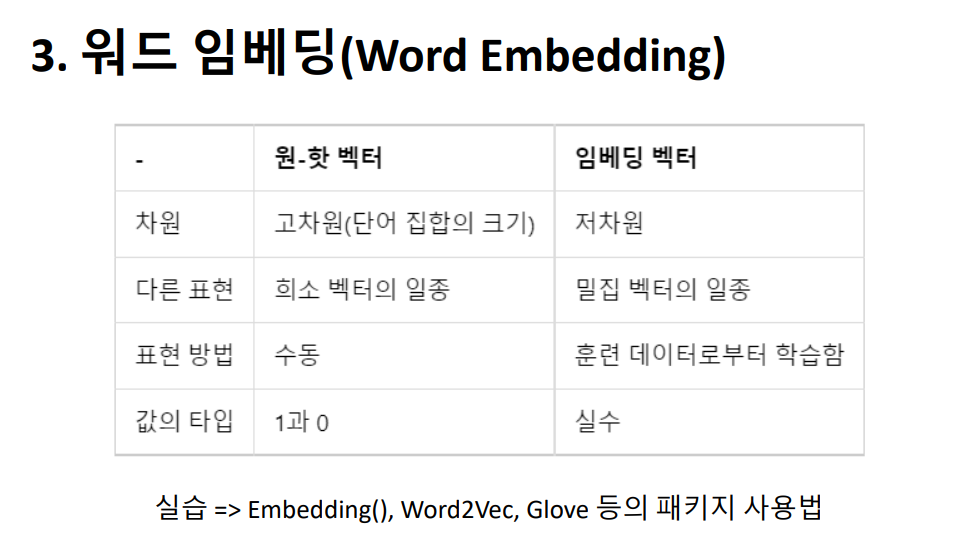 다음은 워드투벡터 입니다. 이는 각 단어의 특징을 N차원의 임베딩 벡터로 만드는 기법입니다. 앞서 언급한 원-핫 벡터의 경우 단어 벡터 간의 유사성을 계산할 수 없다는 단점이 있습니다. 원-핫 인코딩으로 표현된 단어 벡터에는 의미를 담을 수 없기 때문에 단어 간의 유사도를 반영하려면 의미까지도 수치화 할 수 있는 방법이 필요해진 것이죠. 그래서 나온 방법이 워드투벡터이고, 이는 앞뒤 단어를 모두 고려하여 문맥상 의미까지 벡터로 표현합니다.
다음은 워드투벡터 입니다. 이는 각 단어의 특징을 N차원의 임베딩 벡터로 만드는 기법입니다. 앞서 언급한 원-핫 벡터의 경우 단어 벡터 간의 유사성을 계산할 수 없다는 단점이 있습니다. 원-핫 인코딩으로 표현된 단어 벡터에는 의미를 담을 수 없기 때문에 단어 간의 유사도를 반영하려면 의미까지도 수치화 할 수 있는 방법이 필요해진 것이죠. 그래서 나온 방법이 워드투벡터이고, 이는 앞뒤 단어를 모두 고려하여 문맥상 의미까지 벡터로 표현합니다. 예시를 보시면, 한국에서 서울을 빼고 뉴욕을 더했더니 미국이 나오고, 박찬호에서 야구를 빼고 축구를 더하면 호날두가, 사랑에서 이별을 뺐더니 추억이 나옵니다. 마치 각 단어가 가진 의미들을 가지고 연산을 하는 것처럼 보이는데요, 워드투벡터에서는 각 단어 벡터들 간의 유사도까지 계산할 수 있기에 가능한 것입니다.
예시를 보시면, 한국에서 서울을 빼고 뉴욕을 더했더니 미국이 나오고, 박찬호에서 야구를 빼고 축구를 더하면 호날두가, 사랑에서 이별을 뺐더니 추억이 나옵니다. 마치 각 단어가 가진 의미들을 가지고 연산을 하는 것처럼 보이는데요, 워드투벡터에서는 각 단어 벡터들 간의 유사도까지 계산할 수 있기에 가능한 것입니다. 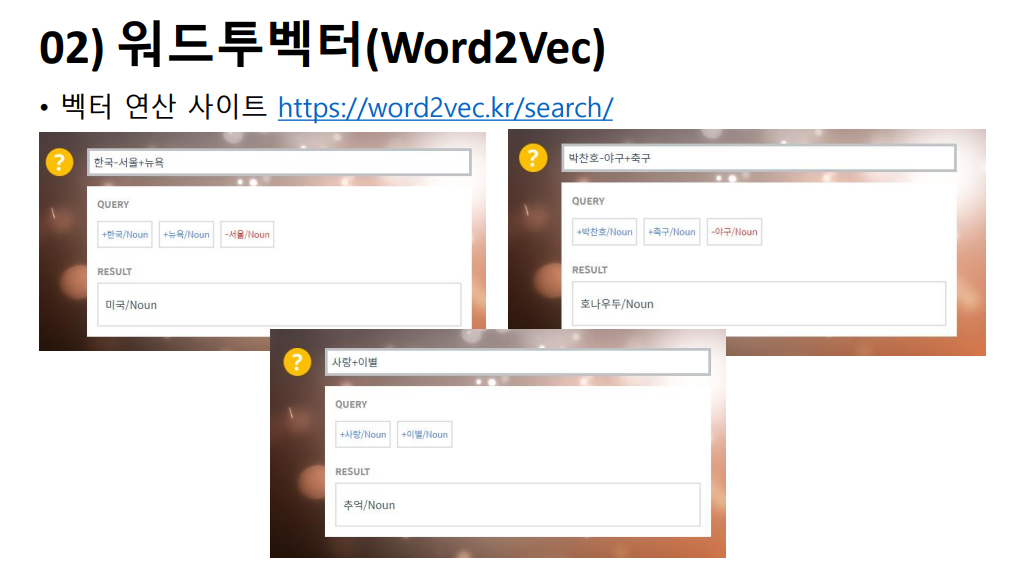 희소표현은 원-핫 인코딩을 떠올리시면 되구요, 대안으로 분산 표현이 나옵니다. 분산 표현을 이요하면 단어 간 의미적 유사성을 다차원 공간에 벡터화할 수 있게 됩니다.
희소표현은 원-핫 인코딩을 떠올리시면 되구요, 대안으로 분산 표현이 나옵니다. 분산 표현을 이요하면 단어 간 의미적 유사성을 다차원 공간에 벡터화할 수 있게 됩니다. 분산 표현 방법은, ‘비슷한 문맥에 등장하는 단어들을 비슷한 의미를 가진다’는 분포 가설을 바탕으로 하고 있습니다. 강아지는 예쁘다와 강아지는 귀엽다에서, 예쁘다와 귀엽다는 비슷한 위치에 등장하며 비슷한 의미를 가진다고 볼 수 있습니다. 또한 강아지와 고양이는 귀엽다, 예쁘다, 애교 등의 단어가 함께 등장하는 단어인데, 이를 분산 표현으로 벡터화했을 때 실제로 매우 유사한 값이 나오는 것을 확인하실 수 있습니다.
분산 표현 방법은, ‘비슷한 문맥에 등장하는 단어들을 비슷한 의미를 가진다’는 분포 가설을 바탕으로 하고 있습니다. 강아지는 예쁘다와 강아지는 귀엽다에서, 예쁘다와 귀엽다는 비슷한 위치에 등장하며 비슷한 의미를 가진다고 볼 수 있습니다. 또한 강아지와 고양이는 귀엽다, 예쁘다, 애교 등의 단어가 함께 등장하는 단어인데, 이를 분산 표현으로 벡터화했을 때 실제로 매우 유사한 값이 나오는 것을 확인하실 수 있습니다.  Word2Vec의 학습 방식에는 CBOW(Continuous Bag of Words)와 Skip-Gram 두 가지 방식이 있습니다. 먼저 소개드릴 CBOW는 주변에 있는 단어들을 입력으로 중간에 있는 단어들을 예측하는 방법입니다. The fat cat sat on the mat이라는 문장에서, 네번째 예시를 보시면 빨간색으로 되어있는 sat은 예측해야 할 중심단어이고, fat, cat, on, the는 예측을 위해 사용할 주변단어입니다.
Word2Vec의 학습 방식에는 CBOW(Continuous Bag of Words)와 Skip-Gram 두 가지 방식이 있습니다. 먼저 소개드릴 CBOW는 주변에 있는 단어들을 입력으로 중간에 있는 단어들을 예측하는 방법입니다. The fat cat sat on the mat이라는 문장에서, 네번째 예시를 보시면 빨간색으로 되어있는 sat은 예측해야 할 중심단어이고, fat, cat, on, the는 예측을 위해 사용할 주변단어입니다.  앞서 중심단어 sat을 예측하기 위해 사용하게 될 중심단어가 앞뒤로 2개가 있었는데요, 이를윈도우 크기라고 합니다. 슬라이딩 윈도우는 윈도우를 양옆으로 움직이며 주변 단어와 중심단어를 변경해가며 학습할 데이터 셋을 만드는 방법을 말합니다.
앞서 중심단어 sat을 예측하기 위해 사용하게 될 중심단어가 앞뒤로 2개가 있었는데요, 이를윈도우 크기라고 합니다. 슬라이딩 윈도우는 윈도우를 양옆으로 움직이며 주변 단어와 중심단어를 변경해가며 학습할 데이터 셋을 만드는 방법을 말합니다. 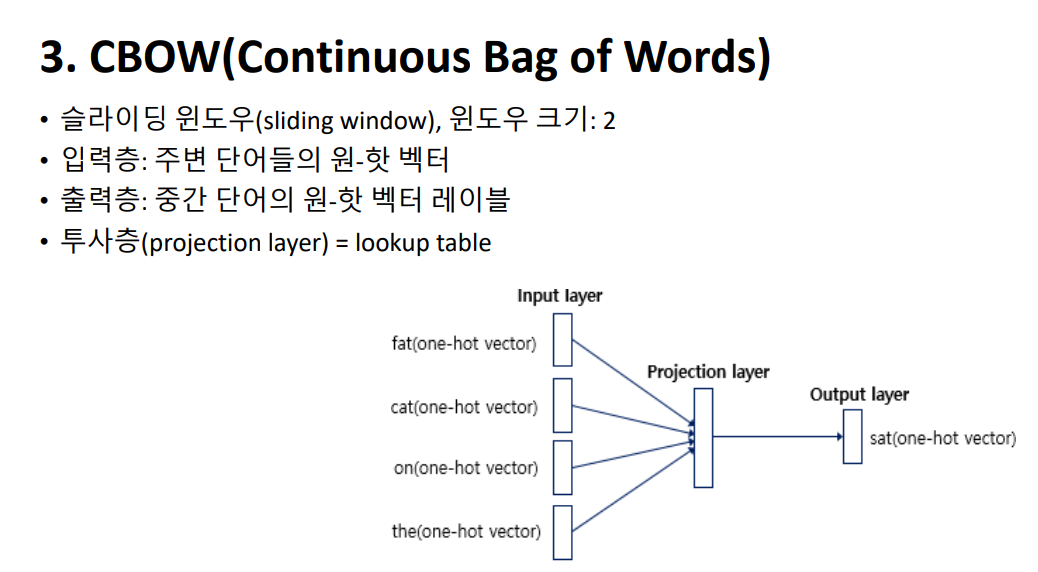 CBOW의 인공 신경망을 보시면 주변 단어들의 원-핫 벡터를 입력으로 받는 입력층, 중간 단어의 원-핫 벡터의 레이블과 비교할 출력층, 그리고 은닉층이자 투사층인 projection layer가 있습니다. 투사층에서는 룩업 테이블 연산이 이루어집니다.
CBOW의 인공 신경망을 보시면 주변 단어들의 원-핫 벡터를 입력으로 받는 입력층, 중간 단어의 원-핫 벡터의 레이블과 비교할 출력층, 그리고 은닉층이자 투사층인 projection layer가 있습니다. 투사층에서는 룩업 테이블 연산이 이루어집니다.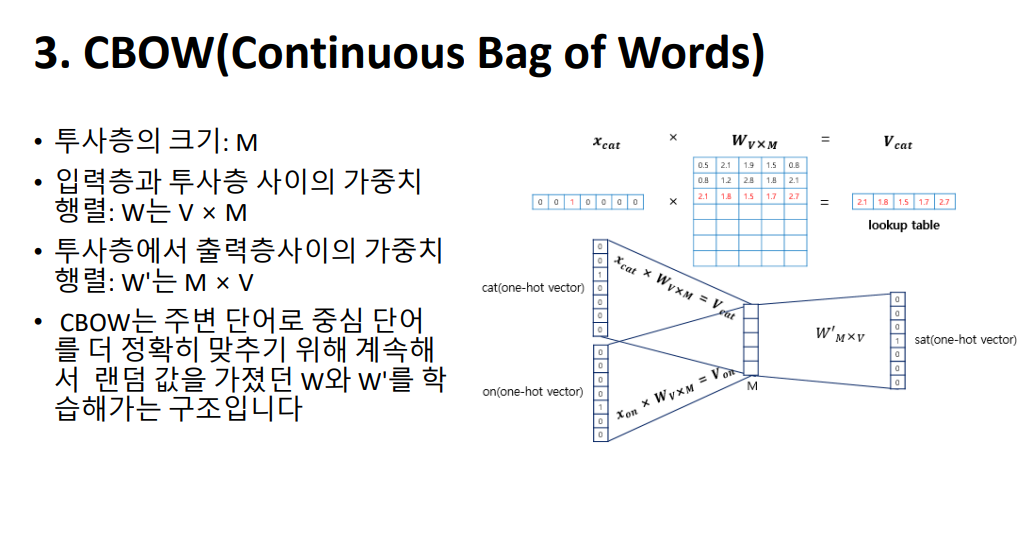 먼저 투사층의 크기 M을 설정하게 됩니다. 이는 CBOW를 수행하고 나서 임베딩하고 난 단어 벡터의 차원이 됩니다. 다음으로, 입력층과 투사층의 가중치 행렬 W는 V by M의 크기를 가지고 있고, 투사층에서 출력층 사이의 가중치 행렬 W 프라임은 M by V임을 보실 수 있습니다. 여기서 V는 단어 집합의 크기를 의미하고, M은 투사층의 크기입니다. 위의 그림에서 투사층의 크기는 M=5이므로 CBOW를 수행하고나서 얻는 각 단어의 임베딩 벡터의 차원은 5가 될 것입니다. 여기서 W프라임은 W 행렬을 전치한 것이 아니라, 출력층의 크기를 입력층의 크기와 맞춰주기 위한 M by V 행렬입니다.
먼저 투사층의 크기 M을 설정하게 됩니다. 이는 CBOW를 수행하고 나서 임베딩하고 난 단어 벡터의 차원이 됩니다. 다음으로, 입력층과 투사층의 가중치 행렬 W는 V by M의 크기를 가지고 있고, 투사층에서 출력층 사이의 가중치 행렬 W 프라임은 M by V임을 보실 수 있습니다. 여기서 V는 단어 집합의 크기를 의미하고, M은 투사층의 크기입니다. 위의 그림에서 투사층의 크기는 M=5이므로 CBOW를 수행하고나서 얻는 각 단어의 임베딩 벡터의 차원은 5가 될 것입니다. 여기서 W프라임은 W 행렬을 전치한 것이 아니라, 출력층의 크기를 입력층의 크기와 맞춰주기 위한 M by V 행렬입니다.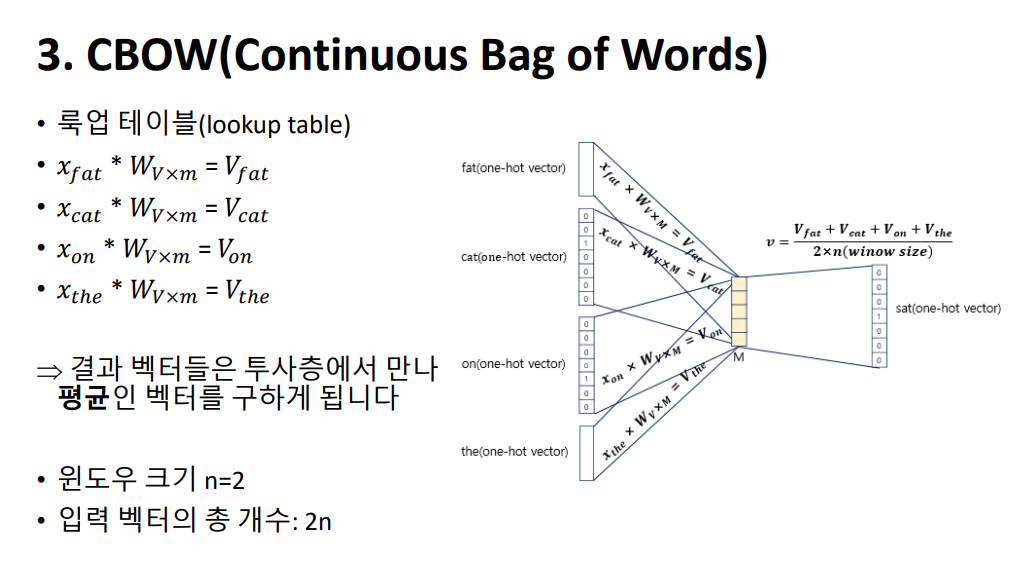 입력으로 들어오는 주변 단어의 원-핫 벡터와 가중치 W행렬의 곱이 어떻게 이루어지는지 보겠습니다. 화면의 이미지에서는 각 주변 단어의 원-핫 벡터를 x로 표기하였습니다. 입력 벡터는 원-핫 벡터입니다. 표현하고자 하는 단어의 i번째 인덱스는 1이라는 값을 가지고 그 외의 0의 값을 가지는 입력 벡터와 가중치 W 행렬의 곱은 사실 W행렬의 i번째 행을 그대로 읽어오는 것과 동일하므로 룩업 테이블이라고 합니다.
입력으로 들어오는 주변 단어의 원-핫 벡터와 가중치 W행렬의 곱이 어떻게 이루어지는지 보겠습니다. 화면의 이미지에서는 각 주변 단어의 원-핫 벡터를 x로 표기하였습니다. 입력 벡터는 원-핫 벡터입니다. 표현하고자 하는 단어의 i번째 인덱스는 1이라는 값을 가지고 그 외의 0의 값을 가지는 입력 벡터와 가중치 W 행렬의 곱은 사실 W행렬의 i번째 행을 그대로 읽어오는 것과 동일하므로 룩업 테이블이라고 합니다. 여기서 나온 결과를 소프트맥스 함수에 넣어 벡터의 각 원소들의 값은 0과 1사이의 실수로, 총 합은 1이 되도록 하는 스코어 벡터 y hat이 됩니다. 스코어 벡터 𝑦^와 중심 단어의 원-핫 벡터 y값의 오차를 줄이기위해 CBOW는 손실 함수(loss function)로 크로스 엔트로피(cross-entropy) 함수를 사용합니다.
여기서 나온 결과를 소프트맥스 함수에 넣어 벡터의 각 원소들의 값은 0과 1사이의 실수로, 총 합은 1이 되도록 하는 스코어 벡터 y hat이 됩니다. 스코어 벡터 𝑦^와 중심 단어의 원-핫 벡터 y값의 오차를 줄이기위해 CBOW는 손실 함수(loss function)로 크로스 엔트로피(cross-entropy) 함수를 사용합니다.
그리고 랜덤한 값을 가졌던 W와 W프라임을 역전파를 통해 최소한의 loss가 나오도록 학습을 시키는 것이죠. 이때, 임베딩 벡터로 W와 W`을 사용하게 됩니다. 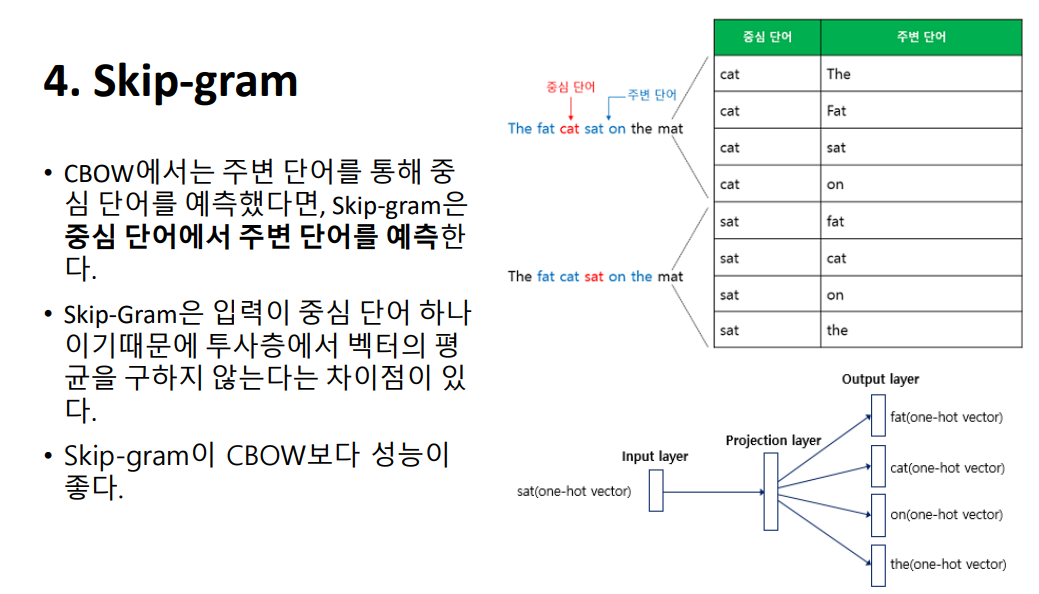 반대로, Skip-Gram은 중간 단어를 입력으로 받아 주변 단어들을 예측하는 방법입니다. 메커니즘 자체는 거의 동일하지만, 입력이 중심 단어 하나이기때문에 투사층에서 벡터의 평균을 구하지 않는다는 차이점이 있습니다. 결과를 먼저 말씀드리자면, Skip-gram이 CBOW보다 성능이 좋습니다.
반대로, Skip-Gram은 중간 단어를 입력으로 받아 주변 단어들을 예측하는 방법입니다. 메커니즘 자체는 거의 동일하지만, 입력이 중심 단어 하나이기때문에 투사층에서 벡터의 평균을 구하지 않는다는 차이점이 있습니다. 결과를 먼저 말씀드리자면, Skip-gram이 CBOW보다 성능이 좋습니다. 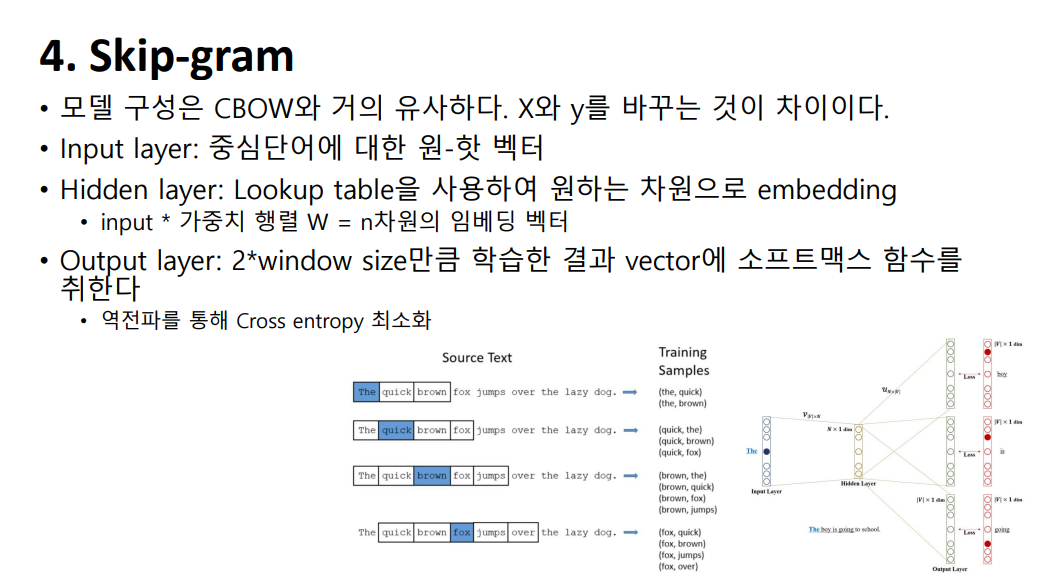 모델 구성은 CBOW와 비슷합니다. Input layer: 중심단어에 대한 원-핫 벡터가 들어갑니다. Hidden layer: Lookup table을 사용하여 원하는 차원으로 embedding한 벡터가 들어갑니다. Output layer에는 2*window size만큼 학습한 결과 vector에 소프트맥스 함수를 취하고, 역전파를 통해 Cross entropy 최소화하는 방식입니다.
모델 구성은 CBOW와 비슷합니다. Input layer: 중심단어에 대한 원-핫 벡터가 들어갑니다. Hidden layer: Lookup table을 사용하여 원하는 차원으로 embedding한 벡터가 들어갑니다. Output layer에는 2*window size만큼 학습한 결과 vector에 소프트맥스 함수를 취하고, 역전파를 통해 Cross entropy 최소화하는 방식입니다. 
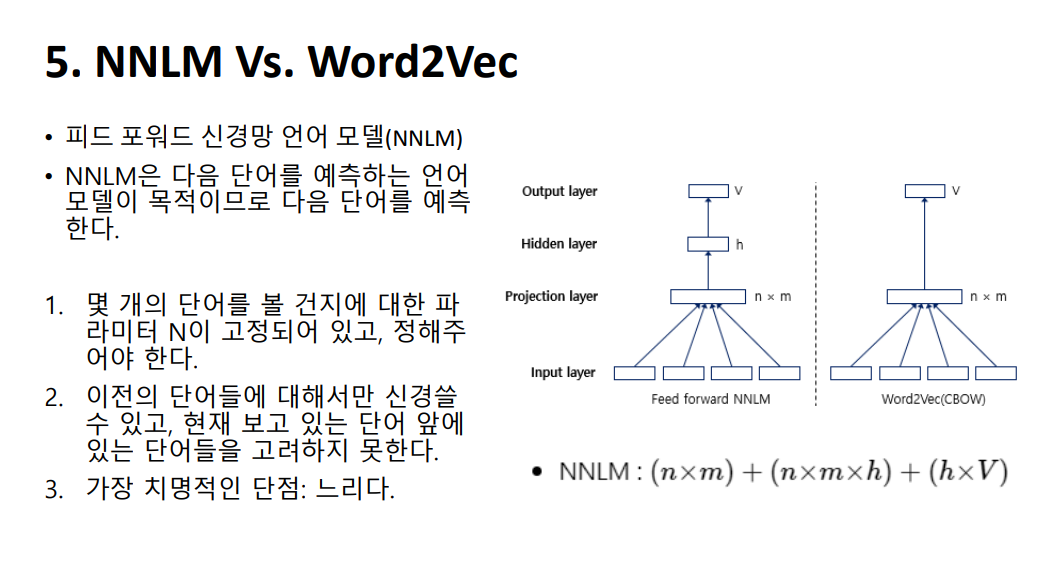 1. 먼저 NNLM을 Input Layer, Projection Layer, Hidden Layer, Output Layer로 이루어진 Neural Network이며, 현재 존재하는 모든 Neural Network 기반 단어 학습 모델은 거의 모두 이 모델의 컨셉을 계승하여 발전시킨 모델이라고 할 수 있다. 그러나 초창기의 모델인 만큼 위와 같이 몇 가지 단점들이 존재한다.
1. 먼저 NNLM을 Input Layer, Projection Layer, Hidden Layer, Output Layer로 이루어진 Neural Network이며, 현재 존재하는 모든 Neural Network 기반 단어 학습 모델은 거의 모두 이 모델의 컨셉을 계승하여 발전시킨 모델이라고 할 수 있다. 그러나 초창기의 모델인 만큼 위와 같이 몇 가지 단점들이 존재한다. 
