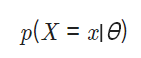
최대 가능도 추정(maximum likelihood estimation, MLE)
데이터들의 likelihood 값을 최대화하는 방향으로 모델을 학습시키는 방법
likelihood(가능도, 우도)
만약 prior 분포를 고정시킨다면, 주어진 파라미터 분포에 대해서 우리가 갖고 있는 데이터가 얼마나 '그럴듯한지' 계산한 값.
즉, 파라미터의 분포 가 정해졌을 때 라는 데이터가 관찰될 확률이다.
- 가능도 함수를 로 표기하기도 한다.
확률 분포 : prior (prior probability, 사전 확률)
prior는 일반적인 정규분포가 될 수도 있고, 데이터의 특성이 반영된 특정 확률 분포가 될 수도 있다.
⭐ 여기서 우리의 목표는 데이터의 집합 가 따르는 어떤 확률 분포 를 가장 잘 나타내는 일차함수 모델 를 찾는 것
posterior(posterior probability, 사후 확률)
이번엔는 반대로, 데이터 집합 가 주어졌을 때 파라미터 의 분포 를 생각해볼 때, '데이터를 관찰한 후 계산되는 확률'을 말한다.
⭐ 우리에게 필요한 값이 바로 '사후 확률'이다
그러나 데이터 포인트의 개수는 유한하기 때문에 데이터가 따르는 확률 분포 를 정확하게 알 수 없다.
머신러닝의 목표❓
를 직접 구할 수 없기 때문에 모델 파라미터 를 조절해가며 간접적으로 근사하는 것.
그래서 posterior를 직접 계산해서 최적의 \mathbf{\theta}θ 값을 찾는 것이 아니라, prior와 likelihood에 관한 식으로 변형한 다음, 그 식을 최대화하는 파라미터 \mathbf{\theta}θ를 찾아야 한다.
최대 사후 확률 추정(maximum a posteriori estimation, MAP)
Posterior를 최대화하는 방향으로 모델을 학습시키는 방법을 말한다.
posterior와 prior, likelihood 사이의 관계를 알아두자.
확률의 곱셈 정리에 의해 확률 변수 와 의 joint probability 는 다음과 같이 나타낼 수 있다.
p(X,θ)=p(θ∣X)p(X)=p(X∣θ)p(θ)
양변을 로 나누어주면 베이즈 정리(Bayes' theorem)와 같은 식이 나온다. 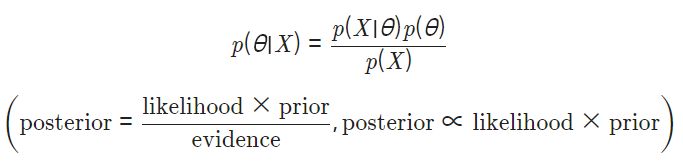
정리하자면,
- 데이터가 따르는 정확한 확률분포 를 알 수 없어서, posterior 의 값도 직접 구할 수 없다.
- 우변의 식에서도 로 나누는 부분이 있기 때문에 이 식으로도 값을 계산할 수는 없다.
- 다만 여기에서 는 고정된 값이고 (데이터가 바뀌지는 않으니) likelihood와 prior는 계산이 가능하기 때문에 우변을 최대화하는 파라미터 값은 구할 수 있다.
노이즈
머신러닝 모델은 어디까지나 한정된 파라미터로 데이터의 실제 분포를 근사하는 역할을 하기 때문에, 어떤 데이터가 들어와도 100%의 정확도를 내는 모델을 만들기는 불가능하다.
 그래서 모델이 입력 데이터로부터 예측한 출력 데이터(prediction)와 우리가 알고 있는 데이터의 실제 값(label) 사이에는 오차가 생기게 되는데, 우리에게 관찰되는 데이터에는 이미 노이즈가 섞여있어서 이런 오차가 발생한다고 해석한다.
그래서 모델이 입력 데이터로부터 예측한 출력 데이터(prediction)와 우리가 알고 있는 데이터의 실제 값(label) 사이에는 오차가 생기게 되는데, 우리에게 관찰되는 데이터에는 이미 노이즈가 섞여있어서 이런 오차가 발생한다고 해석한다.
일단 데이터셋 전체의 likelihood 대신 데이터 하나의 likelihood 을 생각해보자. 출력값의 분포를 어떻게 생각해야 할까? 모델을 선형 모델 로 잡았을 때, 출력값의 분포는 모델의 예측값 에다가 노이즈의 분포를 더한 값이 된다.
노이즈 분포를 평균이 0이고 표준편차가 인 정규분포로 가정한다면, 출력값의 분포는 평균이 이고 표준편차가 인 정규분포가 된다.
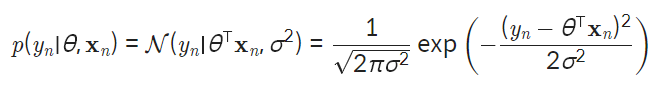
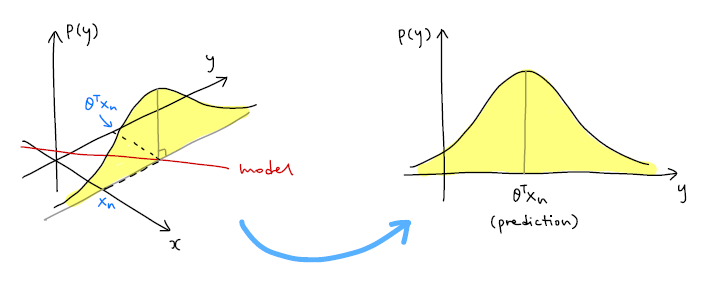
- 위 그래프는 입력 데이터가 일 때 모델의 예측값은 이고, 출력값의 분포 은 노란색으로 표시한 정규분포 그래프이다.
앞서서 말한 설명만으로는 Likelihood에 대한 감을 잡기가 어려울 것이다.
5개의 랜덤한 데이터 포인트를 생성하고 좌표평면 위에 표시해 주는 코드를 작성해보자.
import math
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(321)
input_data = np.linspace(-2, 2, 5)
label = input_data + 1 + np.random.normal(0, 1, size=5)
plt.scatter(input_data, label)
plt.show()  5개의 점(point)들이 생성이 되었다면, 일차함수 모델의 식이 바뀌어감에 따라 likelihood의 값이 어떻게 변하는지 확인해보자.
5개의 점(point)들이 생성이 되었다면, 일차함수 모델의 식이 바뀌어감에 따라 likelihood의 값이 어떻게 변하는지 확인해보자.
# model: y = ax + b
# a, b 값을 바꾸면서 실행해보세요
#-------------------------------#
a = 1
b = 1
#-------------------------------#
# 모델 예측값
model_output = a*input_data + b
likelihood = []
# x: 입력데이터, y: 데이터라벨
# 예측값과 라벨의 차이를 제곱해 exp에 사용
for x, y, output in zip(input_data, label, model_output):
likelihood.append(1/(math.sqrt(2*math.pi*0.1*0.1))*math.exp(-pow(y-output,2)/(2*0.1*0.1)))
model_x = np.linspace(-2, 2, 50)
model_y = a*model_x + b
fig, ax = plt.subplots()
ax.scatter(input_data, label)
ax.plot(model_x, model_y)
for i, text in enumerate(likelihood):
ax.annotate('%.3e'%text, (input_data[i], label[i]))
plt.show()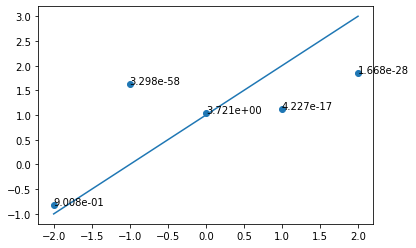 데이터 포인트 옆에 있는 숫자는 likelihood 값이고, 직선은 모델이 표현하는 함수의 그래프이다.
데이터 포인트 옆에 있는 숫자는 likelihood 값이고, 직선은 모델이 표현하는 함수의 그래프이다.
likelihood가 왜 중요한가?
likelihood를 구하는 식을 보면 모델 예측값과 데이터 라벨의 차이를 제곱해서 exponential 위에 올려놓은 것을 확인할 수 있을 것이다. 즉, 예측값과 라벨의 차이가 조금만 벌어져도 likelihood 값은 민감하게 반응한다는 말이다.
- likelihood 공식
- negative log likelihood
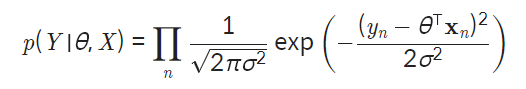
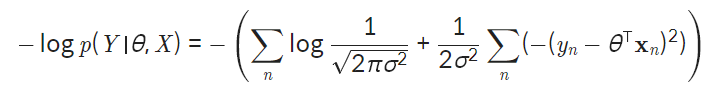
위 그래프를 보면, 데이터 포인트가 모델 함수에서 멀어질수록 데이터의 likelihood는 기하급수적으로 감소한다. 그러나 머신러닝의 목표가 데이터 포인트들을 최대한 잘 표현하는 모델을 찾는 것임을 기억할 때, 결국 데이터 포인트들의 likelihood 값을 크게 하는 모델을 찾아야 한다.
이때 데이터의 likelihood 값을 최대화하는 모델 파라미터를 찾는 방법이 초반에 언급했던 최대 가능도 추론(maximum likelihood estimation, MLE)이다.
MLE 최적해 구하기
데이터셋을 생선한 후, MLE를 이용해 최적의 파라미터를 찾아보고 데이터셋의 likelihood도 계산해보자.
아래 코드는 y=x+1 함수를 기준으로 랜덤한 노이즈를 섞어서 데이터 포인트 20개를 생성하고 시각화하는 코드이다. 데이터 생성 단계에서 지정한 노이즈의 분포는 평균이 0이고 표준편차가 0.5인 정규분포이다.
import math
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
num_samples = 20
input_data = np.linspace(-2, 2, num_samples)
labels = input_data + 1 + np.random.normal(0, 0.5, size=num_samples)
plt.scatter(input_data, labels)
plt.show()
MLE의 최적 파라미터 은 다음과 같이 계산된다.
식을 참고하여 코드로 구현해보자.
def likelihood(labels, preds):
result = 1/(np.sqrt(2*math.pi*0.1*0.1))*np.exp(-np.power(labels-preds,2)/(2*0.1*0.1))
return np.prod(result)
def neg_log_likelihood(labels, preds):
const_term = len(labels)*math.log(1/math.sqrt(2*math.pi*0.1*0.1))
return (-1)*(const_term + 1/(2*0.1*0.1)*np.sum(-np.power(labels-preds,2)))# X: 20x2 matrix, y: 20x1 matrix
# input_data 리스트를 column vector로 바꾼 다음 np.append 함수로 상수항을 추가합니다.
X = np.append(input_data.reshape((-1, 1)), np.ones((num_samples, 1)), axis=1)
y = labels
theta_1, theta_0 = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), y)
print('slope: '+'%.4f'%theta_1+' bias: '+'%.4f'%theta_0)
predictions = theta_1 * input_data + theta_0
print('likelihood: '+'%.4e'%likelihood(labels, predictions))
print('negative log likelihood: '+'%.4e'%neg_log_likelihood(labels, predictions))
model_x = np.linspace(-2, 2, 50)
model_y = theta_1 * model_x + theta_0
plt.scatter(input_data, labels)
plt.plot(model_x, model_y)
plt.show()slope: 0.8578 bias: 1.2847
likelihood: 2.9724e-54
negative log likelihood: 1.2325e+02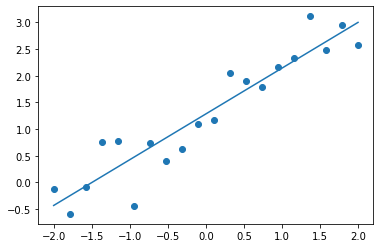 최적의 모델은 이다. 데이터 포인트들이 함수로부터 생성된 것을 생각하면 꽤 가까운 결과가 나오는 것을 볼 수 있다.
최적의 모델은 이다. 데이터 포인트들이 함수로부터 생성된 것을 생각하면 꽤 가까운 결과가 나오는 것을 볼 수 있다.
는 데이터셋 행렬이고, 는 라벨들을 모아놓은 벡터였다. 이 식에서 알 수 있는 것은, MLE의 최적해는 오로지 관측된 데이터 값에만 의존 한다는 사실이다. 물론 이런 접근법은 계산이 비교적 간단하다는 장점이 있지만, 관측된 데이터에 노이즈가 많이 섞여 있는 경우, 이상치(outlier) 데이터가 존재하는 경우에는 모델의 안정성이 떨어진다는 단점도 있다.
최대 사후 확률 추정 (maximum a posteriori estimation, MAP)에 대해 자세히 알아보자.
데이터셋이 주어졌을 때 파라미터의 분포, 즉 에서 확률 값을 최대화하는 파라미터 를 찾습니다. 직관적으로 이야기하면 '이런 데이터가 있을 때 파라미터의 값이 무엇일 확률이 제일 높은가?'의 문제이다.
MLE 모델보다 MAP 모델이 더 안정적이다.
- MLE와 비슷하지만 정규화 항에 해당하는 negative log prior 부분이 존재한다는 차이가 있다.
함수값에 랜덤한 노이즈를 더해서 데이터 포인트들을 생성해보도록 하자.
import math
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
num_samples = 10
input_data = np.linspace(-2, 2, num_samples)
labels = input_data + 1 + np.random.normal(0, 0.5, size=num_samples)
input_data = np.append(input_data, [0.5, 1.5])
labels = np.append(labels, [9.0, 10.0])
plt.scatter(input_data, labels)
plt.show()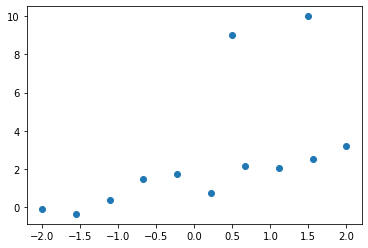 실험 결과 이상치 데이터 한 개를 데이터 포인트 20개에 추가하는 것으로는 모델에 큰 영향을 주지 못해서 데이터 포인트를 10개로 줄이고 이상치 데이터도 2개 추가한다.
실험 결과 이상치 데이터 한 개를 데이터 포인트 20개에 추가하는 것으로는 모델에 큰 영향을 주지 못해서 데이터 포인트를 10개로 줄이고 이상치 데이터도 2개 추가한다.
그래프에서 (0.5, 9), (1.5, 10) 위치의 이상치 데이터를 확인할 수 있다.
MLE와 MAP의 최적 파라미터는 각각 다음과 같다.
노이즈 분포의 표준편차 는 0.1로 가정하고, 파라미터 분포의 표준편차 는 0.04로 지정한다. 정규화 상수 가 에 반비례하는 값이다. 가 작을수록, 즉 파라미터 분포의 표준편차를 작게 잡을수록 파라미터 값에 대한 제약 조건을 강하게 걸어주는 것과 같습니다.
정규화 측면에서 봐도 값이 클수록 모델의 유연성은 감소하죠.
def likelihood(labels, preds):
result = 1/(np.sqrt(2*math.pi*0.1*0.1))*np.exp(-np.power(labels-preds,2)/(2*0.1*0.1))
return np.prod(result)
def neg_log_likelihood(labels, preds):
const_term = len(labels)*math.log(1/math.sqrt(2*math.pi*0.1*0.1))
return (-1)*(const_term + 1/(2*0.1*0.1)*np.sum(-np.power(labels-preds,2)))# X: 21x2 matrix, y: 21x1 matrix
# input_data 리스트를 column vector로 바꾼 다음 np.append 함수로 상수항을 추가합니다.
X = np.append(input_data.reshape((-1, 1)), np.ones((num_samples+2, 1)), axis=1)
y = labels
# MLE 파라미터 계산식
mle_theta_1, mle_theta_0 = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), y)
# MAP 파라미터 계산식
map_theta_1, map_theta_0 = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)+(0.1*0.1)/(0.04*0.04)*np.eye(2)), X.T), y)
print('[MLE result] (blue)')
print('slope: '+'%.4f'%mle_theta_1+' bias: '+'%.4f'%mle_theta_0)
mle_preds = mle_theta_1 * input_data + mle_theta_0
print('likelihood: '+'%.4e'%likelihood(labels, mle_preds))
print('negative log likelihood: '+'%.4e\n'%neg_log_likelihood(labels, mle_preds))
print('[MAP result] (orange)')
print('slope: '+'%.4f'%map_theta_1+' bias: '+'%.4f'%map_theta_0)
map_preds = map_theta_1 * input_data + map_theta_0
print('likelihood: '+'%.4e'%likelihood(labels, map_preds))
print('negative log likelihood: '+'%.4e'%neg_log_likelihood(labels, map_preds))
model_x = np.linspace(-2, 2, 50)
mle_model_y = mle_theta_1 * model_x + mle_theta_0
map_model_y = map_theta_1 * model_x + map_theta_0
plt.scatter(input_data, labels)
plt.plot(model_x, mle_model_y)
plt.plot(model_x, map_model_y)
plt.show()MLE result
slope: 1.4748 bias: 2.4784
likelihood: 0.0000e+00
negative log likelihood: 4.1298e+03
MAP result
slope: 1.1719 bias: 1.6628
likelihood: 0.0000e+00
negative log likelihood: 4.6645e+03
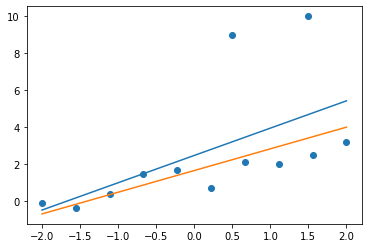
- 파란색 직선과 주황색 직선은 각각 MLE, MAP를 이용해 찾은 모델이다.
- MAP가 MLE에 비해 negative log likelihood 값이 크지만(likelihood가 작지만), 이상치 데이터가 추가되었을 때 모델 파라미터의 변화는 MLE보다 작습니다.
