Artificial Intelligence
1.Why is artificial intelligence a hype?

완벽주의를 내려놓고 블로그 작성을 시작해보고자 한다. 뭐든지 완벽하게 이해하고 나서 글로 남겨야한다는 강박이 있었는데 ... 지금으로썬 공부해가는 과정이니까 그럴 필요가 없는듯 하다 ?! 너무 늦게 깨달았나 싶지만 ... 아니다 지금부터 해야징 후후 이번 포스팅은 q
2.인공지능, 머신러닝, 딥러닝의 본질
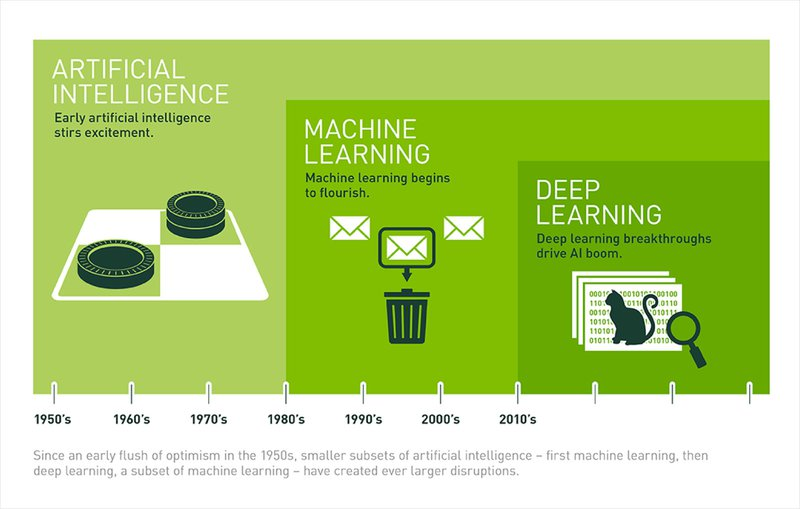
출처: https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/위 사진에서 알 수 있듯이, 인공지능이 가장
3.인공지능, 머신러닝, 딥러닝 관련 참고 자료
https://youtu.be/kYB8IZa5AuE 머신러닝 https://www.stechstar.com/user/zbxe/index.php?mid=studySQL&page=14&documentsrl=63467 딥러닝 https://www.stechstar.com
4.비지도학습(Unsupervised Learning) 클러스터링(Clustering) - (1) K-means
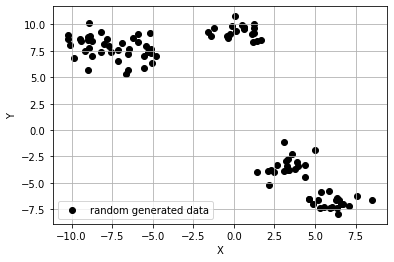
지도학습과 달리 training data로 정답(label)이 없는 데이터가 주어지는 학습방법이다. 라벨링이 되어있지 않은 데이터셋이 많은 경우, 각각 라벨을 달아주는 인간의 수고를 덜기 위해 제시된 <span style='background-color: 비지도학
5.비지도학습(Unsupervised Learning) 클러스터링(Clustering) - (2) DBSCAN
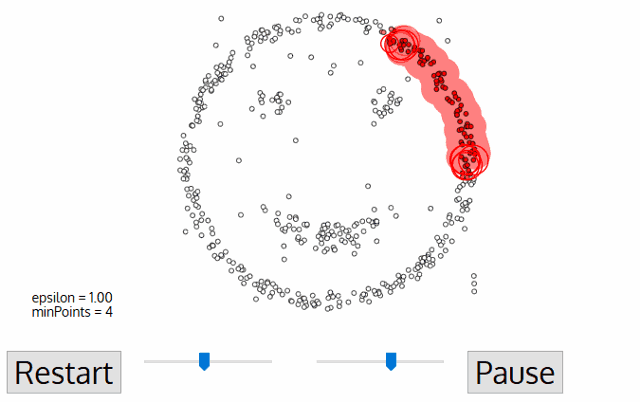
가장 널리 알려진 밀도(density) 기반의 군집 알고리즘이다. 지난 포스팅에서 언급한 K-means 알고리즘을 사용하여 해결하기 어려웠던 문제들을 <span style='background-color: 군집의 개수, 즉 K-means 알고리즘에서의 K 값을
6.The Promise of Generative AI
AWS에서 공개한 "The World's first musical keyboard powered by Generative AI"에 관한 유튜브 영상입니다. 여태껏 인공지능은 '창조성'과 '창의성'의 영역에서 한계점을 지니고 있었는데요, 이번 영상에서는 AI가 이를 극복
7.PCA 차원축소를 하는 이유?

PCA 주성분 분석은 차원축소의 방법 중 하나이다.시각화 (Visualization)3차원이 넘어간 시각화는 우리 눈으로 볼 수 없으므로 차원 축소를 통해 시각화를 해야 한다. 시각화는 데이터를 한눈에 볼 수 있게끔 해주므로 필요하다.노이즈 제거 (Reduce Nois
8.머신러닝: MLE, MAP
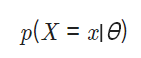
데이터들의 likelihood 값을 최대화하는 방향으로 모델을 학습시키는 방법만약 prior 분포를 고정시킨다면, 주어진 파라미터 분포에 대해서 우리가 갖고 있는 데이터가 얼마나 '그럴듯한지' 계산한 값.즉, 파라미터의 분포 $p(\\mathbf{\\theta})$가
9.BERT
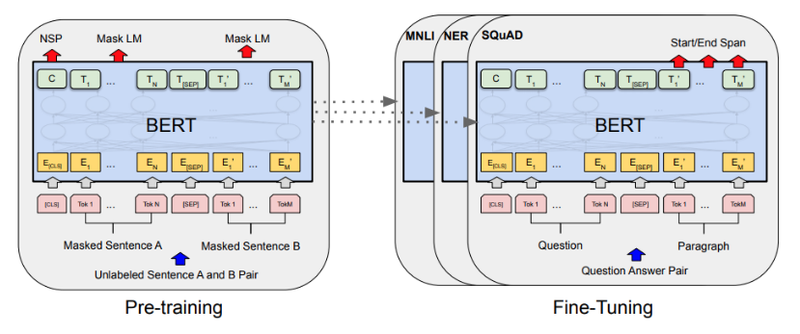
BERT의 모델 구조BERT 모델 공부 시급 !!
10.GAN & cGAN 생성모델 개념
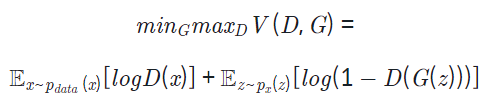
⚓ Aiffel Exploration 17 을 참고하여 작성하였습니다. GAN 구조는 Generator 및 Discriminator라 불리는 두 신경망이 minimax game을 통해 서로 경쟁하며 발전합니다. 이를 아래와 같은 식으로 나타낼 수 있으며 Generato