1. 다중 분류 신경망
다중 분류 신경망을 만들기 위해서는 소프트맥스 함수를 활성 함수로 사용한다. 출력 강도를 정규화하여 전체 출력값의 합을 1로 만들어야 비교가 가능하기 때문이다.
다중 분류 신경망 만들기
class MultiClassNetwork:
def __init__(self, units=10, batch_size=32, learning_rate=0.1, l1=0, l2=0):
self.units = units # 은닉층의 뉴런 개수
self.batch_size = batch_size # 배치 크기
self.w1 = None # 은닉층의 가중치
self.b1 = None # 은닉층의 절편
self.w2 = None # 출력층의 가중치
self.b2 = None # 출력층의 절편
self.a1 = None # 은닉층의 활성화 출력
self.losses = [] # 훈련 손실
self.val_losses = [] # 검증 손실
self.lr = learning_rate # 학습률
self.l1 = l1 # L1 손실 하이퍼파라미터
self.l2 = l2 # L2 손실 하이퍼파라미터
def forpass(self, x):
z1 = np.dot(x, self.w1) + self.b1 # 첫 번째 층의 선형 식을 계산합니다
self.a1 = self.sigmoid(z1) # 활성화 함수를 적용합니다
z2 = np.dot(self.a1, self.w2) + self.b2 # 두 번째 층의 선형 식을 계산합니다.
return z2
def backprop(self, x, err):
m = len(x) # 샘플 개수
# 출력층의 가중치와 절편에 대한 그래디언트를 계산합니다.
w2_grad = np.dot(self.a1.T, err) / m
b2_grad = np.sum(err) / m
# 시그모이드 함수까지 그래디언트를 계산합니다.
err_to_hidden = np.dot(err, self.w2.T) * self.a1 * (1 - self.a1)
# 은닉층의 가중치와 절편에 대한 그래디언트를 계산합니다.
w1_grad = np.dot(x.T, err_to_hidden) / m
b1_grad = np.sum(err_to_hidden, axis=0) / m
return w1_grad, b1_grad, w2_grad, b2_grad
def sigmoid(self, z):
z = np.clip(z, -100, None) # 안전한 np.exp() 계산을 위해
a = 1 / (1 + np.exp(-z)) # 시그모이드 계산
return a
def softmax(self, z):
# 소프트맥스 함수
z = np.clip(z, -100, None) # 안전한 np.exp() 계산을 위해
exp_z = np.exp(z)
return exp_z / np.sum(exp_z, axis=1).reshape(-1, 1)
def init_weights(self, n_features, n_classes):
self.w1 = np.random.normal(0, 1,
(n_features, self.units)) # (특성 개수, 은닉층의 크기)
self.b1 = np.zeros(self.units) # 은닉층의 크기
self.w2 = np.random.normal(0, 1,
(self.units, n_classes)) # (은닉층의 크기, 클래스 개수)
self.b2 = np.zeros(n_classes)
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
np.random.seed(42)
self.init_weights(x.shape[1], y.shape[1]) # 은닉층과 출력층의 가중치를 초기화합니다.
# epochs만큼 반복합니다.
for i in range(epochs):
loss = 0
print('.', end='')
# 제너레이터 함수에서 반환한 미니배치를 순환합니다.
for x_batch, y_batch in self.gen_batch(x, y):
a = self.training(x_batch, y_batch)
# 안전한 로그 계산을 위해 클리핑합니다.
a = np.clip(a, 1e-10, 1-1e-10)
# 로그 손실과 규제 손실을 더하여 리스트에 추가합니다.
loss += np.sum(-y_batch*np.log(a))
self.losses.append((loss + self.reg_loss()) / len(x))
# 검증 세트에 대한 손실을 계산합니다.
self.update_val_loss(x_val, y_val)
# 미니배치 제너레이터 함수
def gen_batch(self, x, y):
length = len(x)
bins = length // self.batch_size # 미니배치 횟수
if length % self.batch_size:
bins += 1 # 나누어 떨어지지 않을 때
indexes = np.random.permutation(np.arange(len(x))) # 인덱스를 섞습니다.
x = x[indexes]
y = y[indexes]
for i in range(bins):
start = self.batch_size * i
end = self.batch_size * (i + 1)
yield x[start:end], y[start:end] # batch_size만큼 슬라이싱하여 반환합니다.
def training(self, x, y):
m = len(x) # 샘플 개수를 저장합니다.
z = self.forpass(x) # 정방향 계산을 수행합니다.
a = self.softmax(z) # 활성화 함수를 적용합니다.
err = -(y - a) # 오차를 계산합니다.
# 오차를 역전파하여 그래디언트를 계산합니다.
w1_grad, b1_grad, w2_grad, b2_grad = self.backprop(x, err)
# 그래디언트에서 페널티 항의 미분 값을 뺍니다
w1_grad += (self.l1 * np.sign(self.w1) + self.l2 * self.w1) / m
w2_grad += (self.l1 * np.sign(self.w2) + self.l2 * self.w2) / m
# 은닉층의 가중치와 절편을 업데이트합니다.
self.w1 -= self.lr * w1_grad
self.b1 -= self.lr * b1_grad
# 출력층의 가중치와 절편을 업데이트합니다.
self.w2 -= self.lr * w2_grad
self.b2 -= self.lr * b2_grad
return a
def predict(self, x):
z = self.forpass(x) # 정방향 계산을 수행합니다.
return np.argmax(z, axis=1) # 가장 큰 값의 인덱스를 반환합니다.
def score(self, x, y):
# 예측과 타깃 열 벡터를 비교하여 True의 비율을 반환합니다.
return np.mean(self.predict(x) == np.argmax(y, axis=1))
def reg_loss(self):
# 은닉층과 출력층의 가중치에 규제를 적용합니다.
return self.l1 * (np.sum(np.abs(self.w1)) + np.sum(np.abs(self.w2))) + \
self.l2 / 2 * (np.sum(self.w1**2) + np.sum(self.w2**2))
def update_val_loss(self, x_val, y_val):
z = self.forpass(x_val) # 정방향 계산을 수행합니다.
a = self.softmax(z) # 활성화 함수를 적용합니다.
a = np.clip(a, 1e-10, 1-1e-10) # 출력 값을 클리핑합니다.
# 크로스 엔트로피 손실과 규제 손실을 더하여 리스트에 추가합니다.
val_loss = np.sum(-y_val*np.log(a))
self.val_losses.append((val_loss + self.reg_loss()) / len(y_val))패션 MNIST 데이터 세트 불러오기
(x_train_all, y_train_all), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()imshow() 함수로 샘플 이미지 확인
plt.imshow(x_train_all[0], cmap='gray')
plt.show()
to_categorical 함수로 원 - 핫 인코딩
tf.keras.utils.to_categorical([0, 1, 3])
y_train_encoded = tf.keras.utils.to_categorical(y_train)
y_val_encoded = tf.keras.utils.to_categorical(y_val)MultiCalssNetwork 클래스로 다중 분류 신경망 훈련
fc = MultiClassNetwork(units=100, batch_size=256)
fc.fit(x_train, y_train_encoded,
x_val=x_val, y_val=y_val_encoded, epochs=40)손실 그래프 확인
plt.plot(fc.losses)
plt.plot(fc.val_losses)
plt.ylabel('loss')
plt.xlabel('iteration')
plt.legend(['train_loss', 'val_loss'])
plt.show()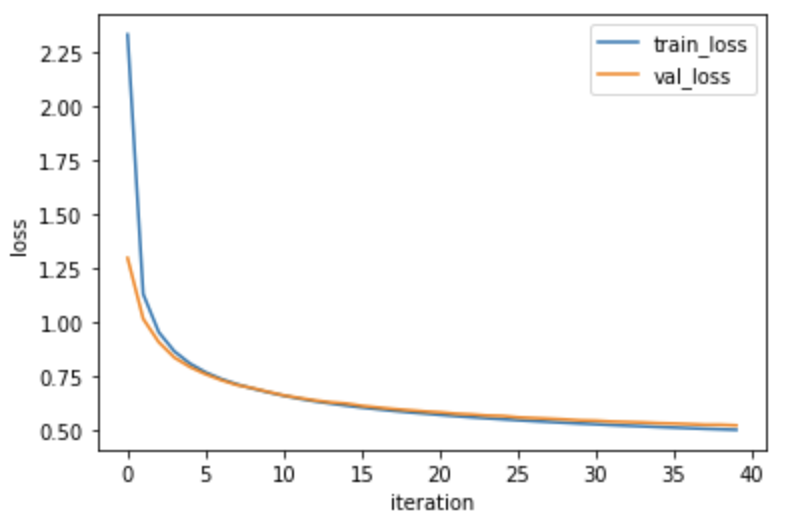
훈련 모델 점수 확인
fc.score(x_val, y_val_encoded)오차가 19%이기 때문에 실전 사용은 어려움. 성능을 위해서 텐서플로, 파이토치 등 패키지 사용.
2. 텐서플로 케라스 신경망
완전 연결 신경망을 위해 Sequential클래스, Dense클래스 사용.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense활성함수로 sigmoid, softmax 사용. 패션 MNIST 데이터는 28X28 크기의 이미지를 일렬로 펼쳤으므로 input_shape는 784로 지정.
model = Sequential()
model.add(Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(Dense(10, activation='softmax'))다중 분류 문제를 해결하기 위해 최적화 알고리즘으로 경사 하강법, 손실 함수로는 크로스 엔트로피 손실 함수 사용.
model.compile(optimizer='sgd', loss='categorical_crossentropy',
metrics=['accuracy'])fit 매서드를 통해 40번의 에포크 동안 훈련.
history = model.fit(x_train, y_train_encoded, epochs=40,
validation_data=(x_val, y_val_encoded))손실 그래프 확인
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train_loss', 'val_loss'])
plt.show()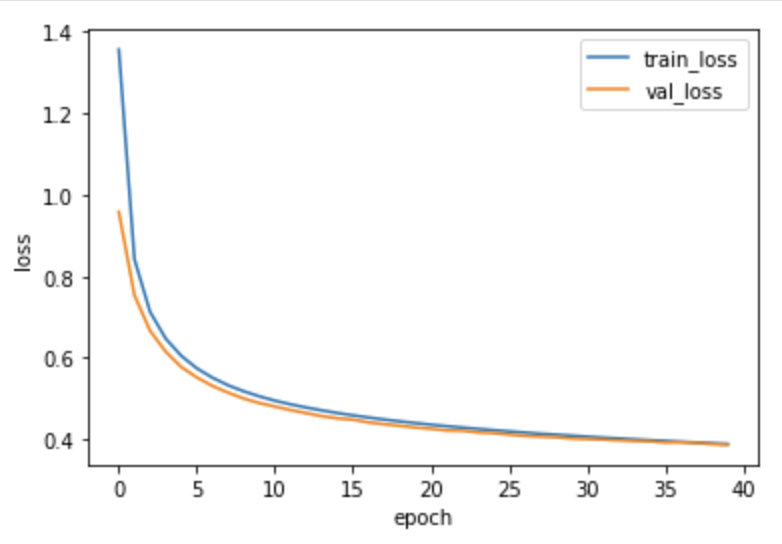
정확도 그래프 확인
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train_accuracy', 'val_accuracy'])
plt.show()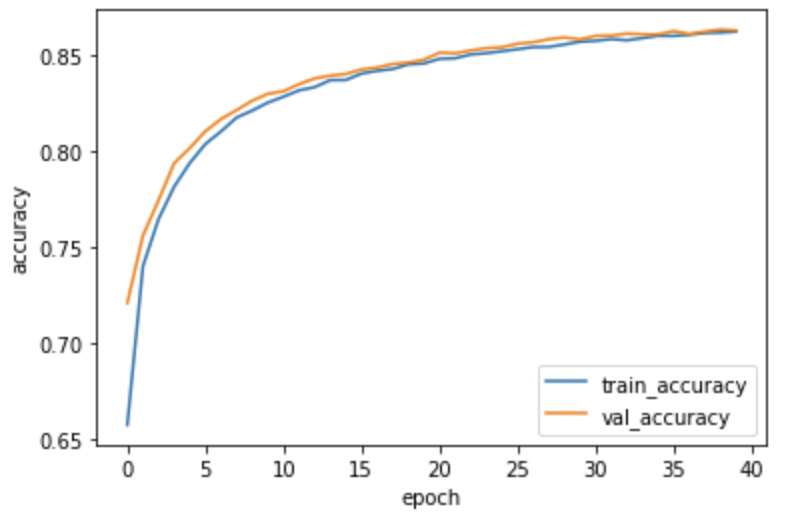
검증 세트 정확도 계산
loss, accuracy = model.evaluate(x_val, y_val_encoded, verbose=0)
print(accuracy)0.8629999756813049
