1. 합성곱 연산이란
이미지 분류에 특화된 합성곱이란 두 함수에 적용하여 새로운 함수를 만드는 수학 연사자다. 사실 합성곱 신경망은 합성곱을 사용하지 않고 교차 상관을 사용한다. 가중치 배열이 무작위로 초기화 되어 있기 때문에 가중치를 뒤집어 합성곱을 적용하거나 뒤집지 않고 교차 상관을 적용하는것이나 동일하기 때문이다.
(1) 패딩
패딩은 원본 배열의 양 끝에 빈 원소를 추가하는 것을 말한다.
(1)-1 밸리드 패딩
원본 배열에 패딩을 추라하지 않고 미끄러지는 배열이 원본 배열의 끝으로 갈 때까지 교차 솽관을 수행함. 이로 인해 밸리드 패딩의 결과로 얻는 배열의 크기는 원본 배열보다 항상 작다.
(1)-2 풀 패딩
가상의 원소로 0을 양끝에 추가해 줌. 제로패딩이라고도 함. 모든 원소가 연산에 동일하게 참여하게 만들 수 있음.
(1)-3 세임 패딩
출력 배열의 길이를 원본 배열의 길이와 동일하게 만듦. 합성곱 신경망에서는 대부분 세임 패딩을 사용함.
(2) 스트라이드
스트라이드는 미끄러지는 간격을 조정한다.
2. 텐서플로 합성곱 수행
2차원 합성곱을 위해 텐서플로는 4차원 배열로 바꿔야 함. 합성곱 신경망의 입력은 일반적으로 4차원 배열.
import tensorflow as tf
x_4d = x.astype(np.float).reshape(1, 3, 3, 1)
w_4d = w.reshape(2, 2, 1, 1)
c_out = tf.nn.conv2d(x_4d, w_4d, strides=1, padding='SAME')
c_out.numpy().reshape(3, 3)correlate2d() 매개변수 값-> 2차원 배열
cov2d() 매개변수 값 -> 4차원 배열
array([[ 2., 4., 6.],
[ 8., 10., 12.],
[14., 16., 18.]])
3. 풀링
풀링 -> 특성 맵(feature map)을 스캔하며 최대값을 고르거나 평균값을 계산하는것을 말함
합성곱층 -> 풀링층 순서
x = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]])
x = x.reshape(1, 4, 4, 1)
p_out = tf.nn.max_pool2d(x, ksize=2, strides=2, padding='VALID')
p_out.numpy().reshape(2, 2)array([[ 6., 8.],
[14., 16.]], dtype=float32)
4. 합성곱 신경망 구조
활성함수
이진 분류 -> 시그모이드
다중 분류 -> 소프트맥스
합성곱층 -> 렐루
렐루 : 0보다 큰 값은 그대로 통과시키고 0보다 작은 값은 0 으로 만듦
렐루함수
def relu(x):
return np.maximum(x, 0)
x = np.array([-1, 2, -3, 4, -5])
relu(x)
r_out = tf.nn.relu(x)
r_out.numpy()array([0, 2, 0, 4, 0])
5. 합성곱 신경망 만들기
정방향(forpass) 매서드에 합성곱 conv2d() 적용
활성 함수로 렐루 함수 적용
역방향은 직접 구현하는 대신 자동 미분 사용
import tensorflow as tf
class ConvolutionNetwork:
def __init__(self, n_kernels=10, units=10, batch_size=32, learning_rate=0.1):
self.n_kernels = n_kernels # 합성곱의 커널 개수
self.kernel_size = 3 # 커널 크기
self.optimizer = None # 옵티마이저
self.conv_w = None # 합성곱 층의 가중치
self.conv_b = None # 합성곱 층의 절편
self.units = units # 은닉층의 뉴런 개수
self.batch_size = batch_size # 배치 크기
self.w1 = None # 은닉층의 가중치
self.b1 = None # 은닉층의 절편
self.w2 = None # 출력층의 가중치
self.b2 = None # 출력층의 절편
self.a1 = None # 은닉층의 활성화 출력
self.losses = [] # 훈련 손실
self.val_losses = [] # 검증 손실
self.lr = learning_rate # 학습률
def forpass(self, x):
# 3x3 합성곱 연산을 수행합니다.
c_out = tf.nn.conv2d(x, self.conv_w, strides=1, padding='SAME') + self.conv_b
# 렐루 활성화 함수를 적용합니다.
r_out = tf.nn.relu(c_out)
# 2x2 최대 풀링을 적용합니다.
p_out = tf.nn.max_pool2d(r_out, ksize=2, strides=2, padding='VALID')
# 첫 번째 배치 차원을 제외하고 출력을 일렬로 펼칩니다.
f_out = tf.reshape(p_out, [x.shape[0], -1])
z1 = tf.matmul(f_out, self.w1) + self.b1 # 첫 번째 층의 선형 식을 계산합니다
a1 = tf.nn.relu(z1) # 활성화 함수를 적용합니다
z2 = tf.matmul(a1, self.w2) + self.b2 # 두 번째 층의 선형 식을 계산합니다.
return z2
def init_weights(self, input_shape, n_classes):
g = tf.initializers.glorot_uniform()
self.conv_w = tf.Variable(g((3, 3, 1, self.n_kernels)))
self.conv_b = tf.Variable(np.zeros(self.n_kernels), dtype=float)
n_features = 14 * 14 * self.n_kernels
self.w1 = tf.Variable(g((n_features, self.units))) # (특성 개수, 은닉층의 크기)
self.b1 = tf.Variable(np.zeros(self.units), dtype=float) # 은닉층의 크기
self.w2 = tf.Variable(g((self.units, n_classes))) # (은닉층의 크기, 클래스 개수)
self.b2 = tf.Variable(np.zeros(n_classes), dtype=float) # 클래스 개수
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
self.init_weights(x.shape, y.shape[1]) # 은닉층과 출력층의 가중치를 초기화합니다.
self.optimizer = tf.optimizers.SGD(learning_rate=self.lr)
# epochs만큼 반복합니다.
for i in range(epochs):
print('에포크', i, end=' ')
# 제너레이터 함수에서 반환한 미니배치를 순환합니다.
batch_losses = []
for x_batch, y_batch in self.gen_batch(x, y):
print('.', end='')
self.training(x_batch, y_batch)
# 배치 손실을 기록합니다.
batch_losses.append(self.get_loss(x_batch, y_batch))
print()
# 배치 손실 평균내어 훈련 손실 값으로 저장합니다.
self.losses.append(np.mean(batch_losses))
# 검증 세트에 대한 손실을 계산합니다.
self.val_losses.append(self.get_loss(x_val, y_val))
# 미니배치 제너레이터 함수
def gen_batch(self, x, y):
bins = len(x) // self.batch_size # 미니배치 횟수
indexes = np.random.permutation(np.arange(len(x))) # 인덱스를 섞습니다.
x = x[indexes]
y = y[indexes]
for i in range(bins):
start = self.batch_size * i
end = self.batch_size * (i + 1)
yield x[start:end], y[start:end] # batch_size만큼 슬라이싱하여 반환합니다.
def training(self, x, y):
m = len(x) # 샘플 개수를 저장합니다.
with tf.GradientTape() as tape:
z = self.forpass(x) # 정방향 계산을 수행합니다.
# 손실을 계산합니다.
loss = tf.nn.softmax_cross_entropy_with_logits(y, z)
loss = tf.reduce_mean(loss)
weights_list = [self.conv_w, self.conv_b,
self.w1, self.b1, self.w2, self.b2]
# 가중치에 대한 그래디언트를 계산합니다.
grads = tape.gradient(loss, weights_list)
# 가중치를 업데이트합니다.
self.optimizer.apply_gradients(zip(grads, weights_list))
def predict(self, x):
z = self.forpass(x) # 정방향 계산을 수행합니다.
return np.argmax(z.numpy(), axis=1) # 가장 큰 값의 인덱스를 반환합니다.
def score(self, x, y):
# 예측과 타깃 열 벡터를 비교하여 True의 비율을 반환합니다.
return np.mean(self.predict(x) == np.argmax(y, axis=1))
def get_loss(self, x, y):
z = self.forpass(x) # 정방향 계산을 수행합니다.
# 손실을 계산하여 저장합니다.
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y, z))
return loss.numpy()데이터 세트 불러오기, 훈련 검증 세트 나누기
(x_train_all, y_train_all), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split(x_train_all, y_train_all, stratify=y_train_all,
test_size=0.2, random_state=42) 원-핫 인코딩
y_train_encoded = tf.keras.utils.to_categorical(y_train)
y_val_encoded = tf.keras.utils.to_categorical(y_val)입력 데이터 준비
높이와 너비 차원을 그대로 유지한 채 신경망에 주입. 대신 마지막에 컬러 채널을 추가.
x_train = x_train.reshape(-1, 28, 28, 1)
x_val = x_val.reshape(-1, 28, 28, 1)입력 데이터 표준화 전처리
x_train = x_train / 255
x_val = x_val / 255모델 훈련
합성곱 커널 10개
완전 연결층 뉴런 100개
배치 크기 128, 학습률 0.01
에포크 20
cn = ConvolutionNetwork(n_kernels=10, units=100, batch_size=128, learning_rate=0.01)
cn.fit(x_train, y_train_encoded,
x_val=x_val, y_val=y_val_encoded, epochs=20)훈련, 검증세트 손실 그래프 확인
plt.plot(cn.losses)
plt.plot(cn.val_losses)
plt.ylabel('loss')
plt.xlabel('iteration')
plt.legend(['train_loss', 'val_loss'])
plt.show()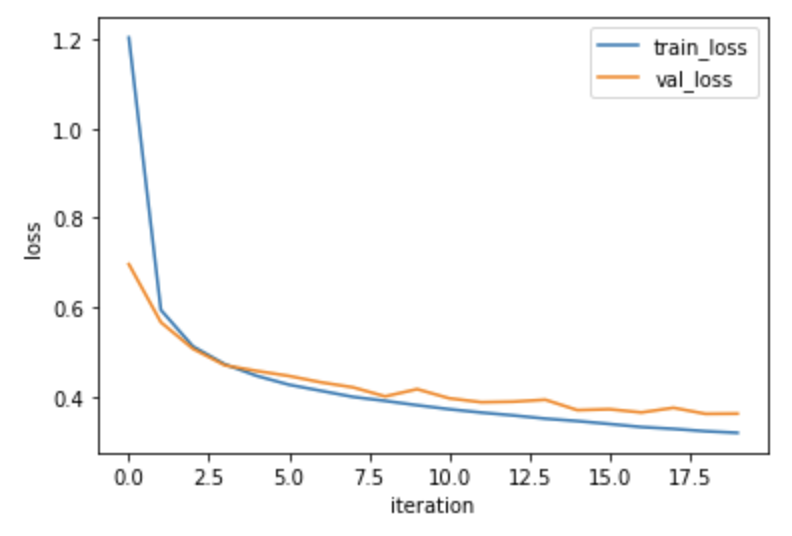
검증 세트 정확도 확인
cn.score(x_val, y_val_encoded)0.8745833333333334
6. 케라스 합성곱 신경망
케라스 합성곱층: Conv2D
최대 풀링: MaxPooling2D
특성 맵 펼치기: Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense합성곱층 커널로 3X3
activation 매개 변수에 렐루 함수
세임 패딩 -> 매개변수 대소문자 구분X
input_shape 입력 크기: 패션 MNIST 이미지의 높이, 너비, 컬러 채널
conv1 = tf.keras.Sequential()
conv1.add(Conv2D(10, (3, 3), activation='relu', padding='same', input_shape=(28, 28, 1)))풀링층 MaxPooling2D 첫번째 매개변수: 풀링의 높이와 너비
conv1.add(MaxPooling2D((2, 2)))완전 연결층에 주입할 수 있도록 특성 맵 펼치기
conv1.add(Flatten())완전 연결층 추가 첫번째 완전 연결층: 100개 뉴런, 렐루 함수
마지막 출력층: 10개 뉴런, 소프트맥스 함수
conv1.add(Dense(100, activation='relu'))
conv1.add(Dense(10, activation='softmax'))합성곱 신경망 모델 훈련
최적화 알고리즘으로 Adam 옵티마이저
conv1.compile(optimizer='adam', loss='categorical_crossentropy',
metrics=['accuracy'])
history = conv1.fit(x_train, y_train_encoded, epochs=20,
validation_data=(x_val, y_val_encoded))손실 그래프 확인
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train_loss', 'val_loss'])
plt.show()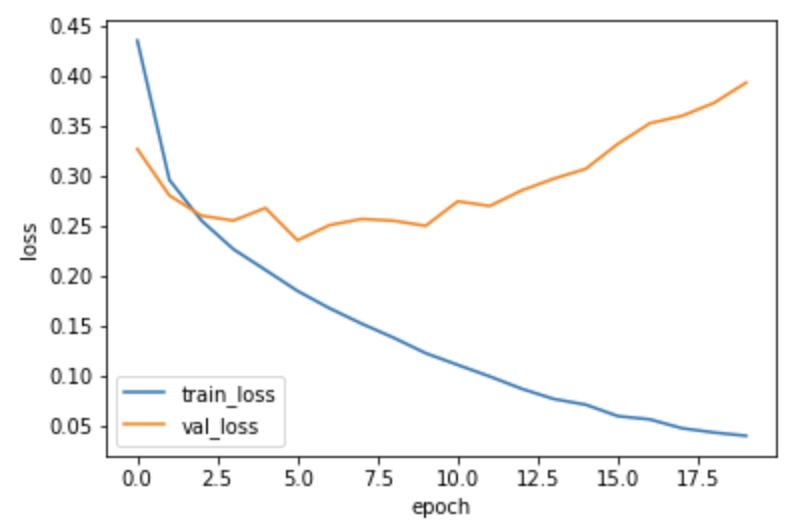
정확도 그래프 확인
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train_accuracy', 'val_accuracy'])
plt.show()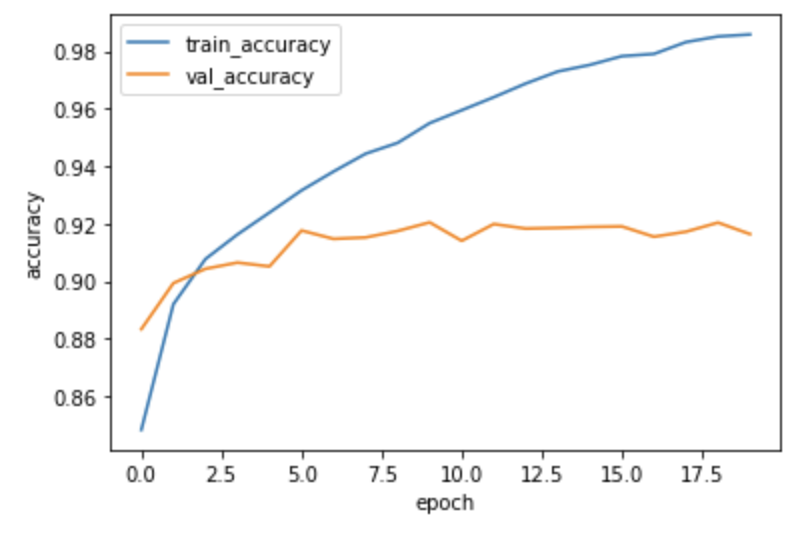
검증 데이터 정확도 확인
loss, accuracy = conv1.evaluate(x_val, y_val_encoded, verbose=0)
print(accuracy)0.9163333177566528
7. 드롭아웃 적용 후 합성곱 신경망 구현
과대적합을 줄이는 방법 중 하나인 드롭아웃은 무작위로 일부 뉴런을 비활성화 시킴. 무작위로 일부 뉴런을 비활성화시키면 특정 뉴런에 과도하게 의존하여 훈련하는 것을 막아줌.
케라스 합성곱 신경망에 드롭아웃 적용
from tensorflow.keras.layers import Dropout
conv2 = tf.keras.Sequential()
conv2.add(Conv2D(10, (3, 3), activation='relu', padding='same', input_shape=(28, 28, 1)))
conv2.add(MaxPooling2D((2, 2)))
conv2.add(Flatten())
conv2.add(Dropout(0.5))
conv2.add(Dense(100, activation='relu'))
conv2.add(Dense(10, activation='softmax'))훈련하기
conv2.compile(optimizer='adam', loss='categorical_crossentropy',
metrics=['accuracy'])
history = conv2.fit(x_train, y_train_encoded, epochs=20,
validation_data=(x_val, y_val_encoded)) 드롭아웃 적용 후 손실 그래프 확인
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train_loss', 'val_loss'])
plt.show()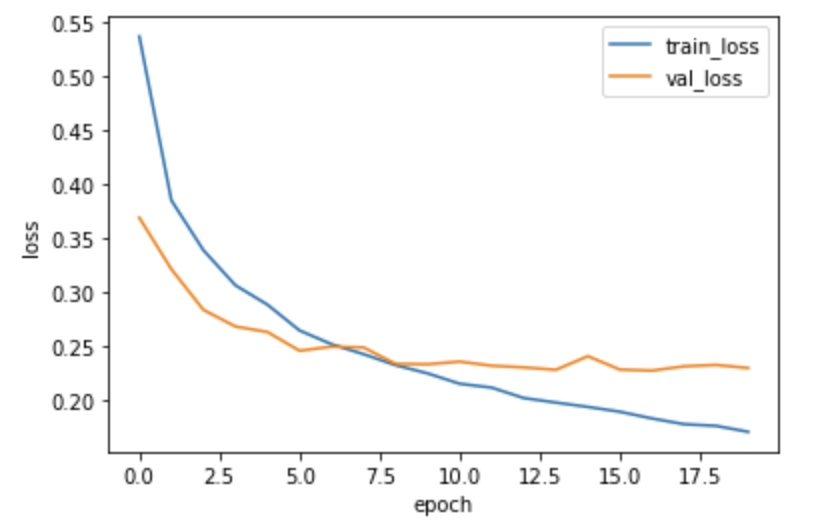
드롭아웃 적용 후 정확도 그래프 확인
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train_accuracy', 'val_accuracy'])
plt.show()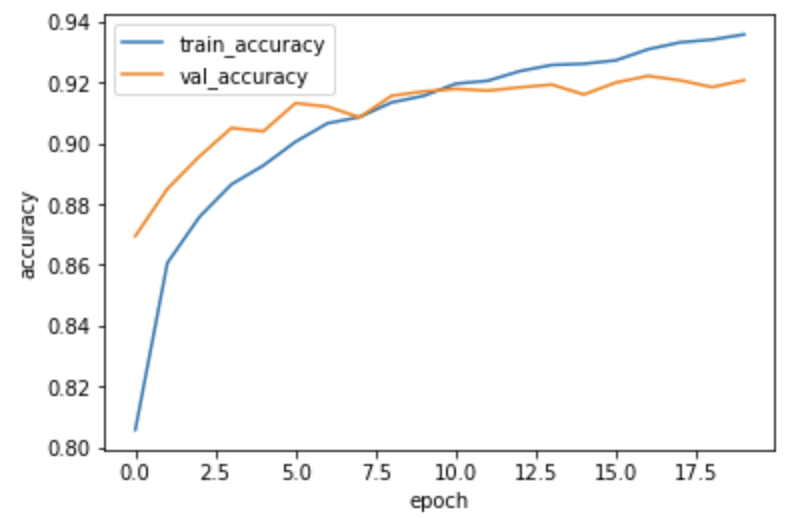
정확도 확인
loss, accuracy = conv2.evaluate(x_val, y_val_encoded, verbose=0)
print(accuracy)0.9206666946411133
드롭아웃 적용 후 과대적합이 줄어들어 정확도가 향상 됨.
