1. 연관규칙 평가척도
(1) 지지도(support)
전체에 대한 품목A와 품목B가 동시에 일어나는 확률
Support = P(A∩B) = 품목 A와 품목 B가 동시에 포함된 거래 수 / 전체 거래수
일반적으로 지지도가 낮다는 의미는 A와 B를 동시에 구매하는 거래가 자주 발생하지
않음을 의미
Support(AB) 와 Support(B A)가 상호 대칭적으로 서로 같은 값을 가진다.
(2) 신뢰도(confidence)
품목 A가 구매될 때 품목 B가 동시에 구매되는 경우의 조건부확률
Confidence (A B) = P(B|A) = 품목 A와 품목 B가 동시에 포함된 거래 수 / 품목 A를
포함한 거래수
지지도는 상호 대칭적으로 서로 같은 값을 가지기 때문에 포함 비중이 낮은 경우에는
연관성을 판단하는데 어려움이 있어 이를 보완한 것이 신뢰도
품목 A가 포함된 거래 중에서 품목 B를 포함한 거래의 비율
(3) 향상도(lift)
하위 항목들이 독립에서 얼마나 벗어나는지의 정도를 측정한 값
Lift(A B) = 신뢰도 / 품목 B를 포함한 거래율
지지도 또는 신뢰도가 높은 연관성 규칙 중에서 우연히 연관성이 높게 보이는 것들이
나타날 수 있는데 이를 보완하기 위해서 향상도가 사용된다.
향상도가 1에 가까우면 두 상품은 서로 독립적
향상도가 1보다 작으면 두 상품은 음의 상관성
향상도가 1보다 크면 두 상품은 양의 상관성
연관규칙에 의미가 있으려면 향상도가 1보다 큰 값이어야 한다.
향상도의 값이 클수록 상품 간의 연관성이 높다고 볼 수 있다.
예시) 상품거래 트랜잭션:
T1: 라면, 맥주, 우유
T2: 라면, 고기, 우유
T3: 라면, 과일, 고기
T4: 고기, 맥주, 우유
T5: 라면, 고기, 우유
T6: 과일, 우유

지지도와 신뢰도가 높을수록 발견되는 규칙(rule)은 적어진다.
트랜잭션 객체를 대상으로 연관규칙 생성
1단계: 연관분석을 위한 패키지 설치
install.packages("arules")
library(arules)
2단계: 트랜잭션(transaction) 객체 생성
setwd("C:/Rwork/ ")
tran <- read.transactions("tran.txt", format = "basket", sep = ",")
tran
3단계: 트랜잭션 데이터 보기
inspect(tran)
4단계: 규칙(rule) 발견1
rule <- apriori(tran, parameter = list(supp = 0.3, conf = 0.1))
inspect(rule)
5단계: 규칙(rule) 발견2
rule <- apriori(tran, parameter = list(supp = 0.1, conf = 0.1))
inspect(rule)2. 연관규칙 시각화
library(ggraph)
library(arulesViz)
plot(ar3, method = "graph", control = list(type = "items"))
data("Groceries")
str(Groceries)
Groceries
Groceries.df <- as(Groceries, "data.frame")
head(Groceries.df)
rules <- apriori(Groceries, parameter = list(supp = 0.001, conf = 0.8))
plot(rules, method = "grouped")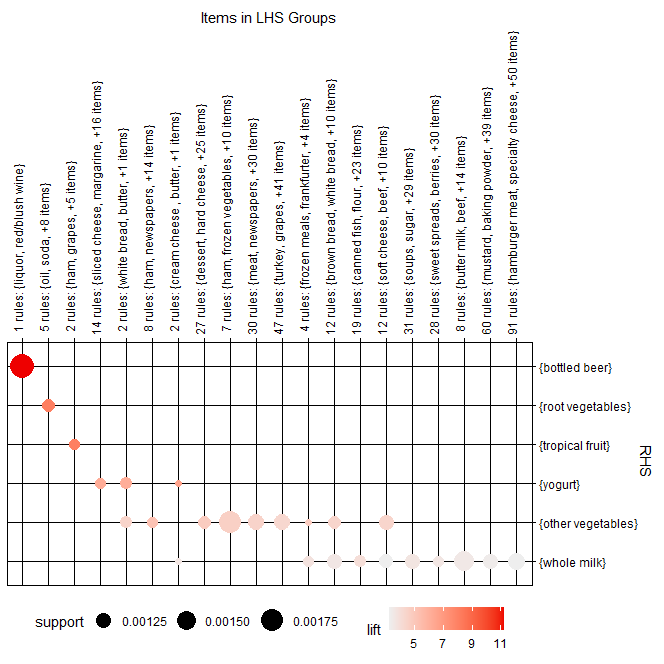
rules <- apriori(Groceries,
parameter = list(supp = 0.001, conf = 0.80, maxlen = 3))
rules <- sort(rules, decreasing = T, by = "confidence")
inspect(rules)
library(arulesViz)
plot(rules, method = "graph")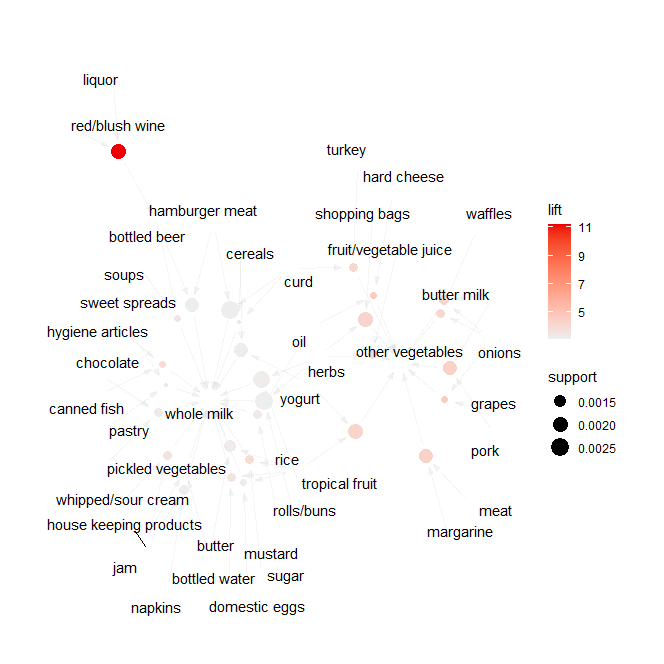
wmilk <- subset(rules, rhs %in% 'whole milk')
wmilk
inspect(wmilk)
plot(wmilk, method = "graph")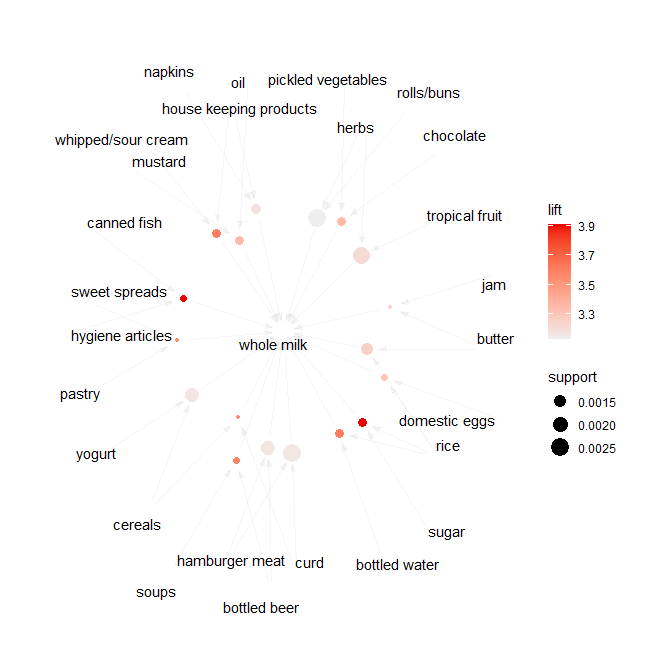
3. 연관분석 정리
하나의 거래나 사건에 포함된 항목 간의 관련성을 파악하여 둘 이상의 항목들로 구성된
연관성 규칙을 도출하는 탐색적인 분석 방법
“장바구니 분석”
연관성규칙은 지지도(support), 신뢰도(confidence), 향상도(lift)를 평가척도로 사용
연관분석은 구매패턴을 분석하여 고객을 대상으로 상품을 추천하거나 프로모션 및
마케팅 전략을 수립하는데 활용
연관분석 특징
사건의 연관규칙을 찾는 데이터마이닝 기법
y변수가 없으며, 비지도학습에 의한 패턴 분석 방법
거래 사실이 기록된 트랜잭션(Transaction)형식의 데이터 셋을 이용
사건과 사건 간의 연관성을 찾는 방법
예) 기저귀와 맥주(Diapers vs. Beer) 이야기: Karen Heath는 1992년 맥주와 기저귀의
상관관계 발견
지지도(제품의 동시 구매패턴), 신뢰도(A제품 구매 시 B제품 구매패턴),
향상도(A제품과 B제품간의 상관성)을 연관규칙의 평가도구로 사용
활용분야: 상품구매 규칙을 통한 구매패턴 예측(상품 연관성)
연관분석 시행 절차
1단계: 거래 내역 데이터를 대상으로 트랜잭션 객체 생성
2단계: 품목(Item)과 트랜잭션 ID 관찰
3단계: 평가 척도(지지도, 신뢰도, 향상도)를 이용한 연관규칙(rule) 발견
4단계: 연관분석 결과에 대한 시각화
5단계: 연관분석 결과 해설 및 업무 적용
