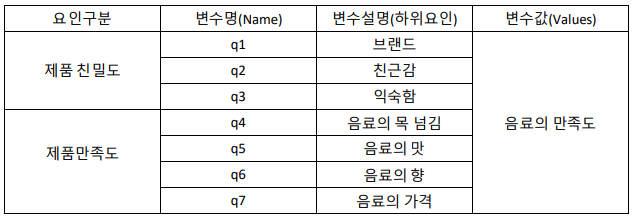
1. 다음은 drinking,water_example.sav 파일의 데이터셋이 구성된 테이블이다. 전체 2 개의 요인에의해서 7 개의 변수로 구성되어 있다. 아래에서 제시된 각 단계에 맞게 요인 분석을 수행하시오.
1) 데이터파일 가져오기
library(memisc)
setwd("C:/Rwork/")
data.spss <- as.data.set(spss.system.file('drinking_water_example.sav'))
data.spss
drinkig_water_exam <- data.spss[1:7]
drinkig_water_exam_df <- as.data.frame(drinkig_water_exam)
str(drinkig_water_exam_df)
2) 베리맥스 회전법, 요인수 2, 요인점수 회귀분석 방법을 적용하여 요인 분석
3) 요인적재량 행렬의 컬럼명 변경
4) 요인점수를 이용한 요인적재량 시각화
5) 요인별 변수 묶기
# 1.
# 1)
library(memisc)
setwd("C:/Rwork/")
data.spss <- as.data.set(spss.system.file('dataset2/drinking_water_example.sav'))
data.spss
drinkig_water_exam <- data.spss[1:7]
drinkig_water_exam_df <- as.data.frame(drinkig_water_exam)
str(drinkig_water_exam_df)
# 2)
abc <- factanal(drinkig_water_exam_df, factors = 2,
rotation = "varimax",
scores = "regression")
# 3)
a <- abc$loadings
colnames(a) <- c("제품친밀도","제품만족도")
a
# 4)
plot(abc$scores[,c(1,2)], main="제품친밀도와 제품만족도 요인점수 행렬")
text(abc$scores[,1], abc$scores[,2],
labels = rownames(abc$scores),
cex = 0.7, pos = 3, col = "blue")
points(abc$loadings[,c(1,2)], pch=19, col = "red")
text(abc$loadings[,1], abc$loadings[,2],
labels = rownames(abc$loadings),
cex = 1.5, pos = 3, col = "red")
# 5)
c <- data.frame(drinkig_water_exam_df$Q1, drinkig_water_exam_df$Q2,
drinkig_water_exam_df$Q3)
d <- data.frame(drinkig_water_exam_df$Q4, drinkig_water_exam_df$Q5,
drinkig_water_exam_df$Q6, drinkig_water_exam_df$Q7)
c1 <- round((c$drinkig_water_exam_df.Q1+c$drinkig_water_exam_df.Q2 +
c$drinkig_water_exam_df.Q3)/ncol(c),2)
d1 <- round((d$drinkig_water_exam_df.Q4 + d$drinkig_water_exam_df.Q5
+ d$drinkig_water_exam_df.Q6 + d$drinkig_water_exam_df.Q7) / ncol(c), 2)- 1 번에서 생성된 두 개의 요인을 데이터프레임으로 생성한 후 이를 이용하여 두 요인 간의
상관관계 계수를 제시하시오.
final <- data.frame(c1, d1)
cor(final)