
RTOS?
RTOS(Real-Time Operating System)는 일반적인 운영체제(Windows, macOS 등)와 달리, 특정 작업이 정해진 시간 내에 완료됨을 보장(Determinism)하는 데 최적화된 시스템입니다.
1. RTOS의 핵심 철학: "속도"보다 "예측 가능성"
일반 OS는 여러 프로그램을 최대한 공평하고 빠르게 돌리는 것이 목적이지만, RTOS는 "아무리 바빠도 이 작업은 무조건 10ms 안에 끝내야 한다"는 약속(Deadline)을 지키는 것이 제1 목표입니다.
- 결정론적 동작(Deterministic): 동일한 상황에서 시스템이 반응하는 시간이 항상 일정해야 합니다.
- 실시간성(Real-time): 작업 처리가 단순히 빠른 것이 아니라, 정해진 시간 제한을 엄수하는 것을 의미합니다.
2. RTOS를 구성하는 3대 요소
RTOS 수업에서 다루게 될 가장 중요한 구성 요소들입니다.
① 태스크(Task)와 스케줄러(Scheduler)
태스크: RTOS에서 실행되는 독립적인 작업 단위입니다. FPGA의 always 블록들이 병렬로 돌아가는 것과 달리, 소프트웨어는 CPU를 나눠 써야 하므로 태스크 단위로 일을 쪼갭니다.
스케줄러: 우선순위가 높은 태스크가 먼저 CPU를 쓸 수 있도록 교통정리를 해주는 '심판'입니다.
② ISR (Interrupt Service Routine)
하드웨어 신호(예: FPGA에서 보낸 데이터 도착 신호)가 들어왔을 때, 하던 일을 멈추고 즉각적으로 대응하는 특수 함수입니다. 하드웨어와 소프트웨어가 만나는 최전선이라고 볼 수 있습니다.
③ IPC (Inter-Process Communication)
태스크끼리 서로 데이터를 주고받거나 순서를 맞추기 위한 도구입니다.
- Mailbox/Queue: 태스크 간에 편지(데이터)를 주고받는 통로입니다.
- Semaphore/Mutex: 여러 태스크가 하나의 자원(예: 공유 메모리)을 동시에 건드리지 못하게 막는 자물쇠 역할을 합니다.
특징
- Simple
- Guaranteed response
- Strict timing constraints
- Minimum and maximum limits
- Known components
- Predictable behavior
- Upgradable
한계점
1. 문맥 교환 오버헤드 (Context Switching Overhead)
RTOS는 여러 태스크를 번갈아 실행하기 위해 현재 상태를 저장하고 복구하는 과정을 반복합니다.
한계: 이 '교체 작업' 자체가 CPU의 자원을 소모합니다. 태스크가 너무 많거나 교체 주기가 너무 빠르면, 실제 일을 하는 시간보다 태스크를 바꾸는 데 더 많은 시간을 쓰는 상황이 발생할 수 있습니다.
FPGA와 비교: FPGA는 회로가 각각 독립적으로 돌아가므로 이런 교체 비용이 아예 제로(0)입니다.
2. 인터럽트 지연 (Interrupt Latency)
RTOS는 하드웨어 신호에 즉각 반응해야 하지만, 실제로는 약간의 지연이 발생합니다.
한계: 인터럽트가 발생했을 때, 현재 실행 중인 중요한 코드가 있거나 커널이 스케줄링 중이라면 즉시 ISR로 진입하지 못하고 대기해야 합니다. 이를 Latency라고 하며, 매우 정밀한(나노초 단위) 제어가 필요한 시스템에서는 이 지연이 치명적일 수 있습니다.
3. 우선순위 역전 현상 (Priority Inversion)
스케줄러의 논리가 꼬이면서 발생하는 가장 대표적인 설계상의 한계입니다.
한계: 낮은 우선순위의 태스크가 자원(세마포어 등)을 붙잡고 있어서, 정작 중요한 높은 우선순위의 태스크가 실행되지 못하고 대기하는 상황이 벌어집니다. 이를 해결하기 위해 '우선순위 상속' 같은 복잡한 기법을 추가해야 하며, 이는 시스템을 더 무겁게 만듭니다.
4. 낮은 처리량 (Low Throughput)
RTOS는 "제시간에 끝내는 것"에 집착하느라 "전체적인 처리 양"은 손해를 볼 수 있습니다.
한계: 일반적인 OS(Windows 등)는 시스템 전체의 효율을 높이기 위해 데이터를 모아서 한꺼번에 처리하는 방식을 쓰지만, RTOS는 매번 정해진 타이밍을 맞춰야 하므로 전체적인 데이터 처리 성능(Throughput)은 상대적으로 떨어질 수 있습니다.
RTOS에 대한 오해
1. Real-time systems are synonymous with "fast" systems.
오해: 실시간 시스템은 그냥 "빠른" 시스템이다.
진실: 실시간 시스템의 핵심은 '속도'가 아니라 '결정론적 동작(Determinism)'입니다.
단순히 처리 속도가 빠른 것보다, 어떤 작업이 정해진 시간(Deadline) 내에 완료됨을 보장하는 것이 훨씬 중요합니다. 아무리 빨라도 가끔씩 늦어진다면 그것은 실시간 시스템이 아닙니다.
2. Rate-monotonic analysis has solved "the real-time problem."
오해: RMA(Rate-monotonic analysis)가 실시간 문제를 모두 해결했다.
진실: RMA는 우선순위 기반 스케줄링의 아주 기초적인 이론일 뿐입니다.
실제 시스템에서는 태스크 간의 의존성, 자원 공유 문제(Priority Inversion), 인터럽트 지연 등 RMA 공식 하나만으로 설명할 수 없는 복잡한 변수가 훨씬 많습니다.
3. There are universal, widely accepted methodologies for real-time systems, specification and design.
오해: 실시간 시스템 설계에는 전 세계적으로 통용되는 표준 방법론이 있다.
진실: 실시간 시스템은 하드웨어 의존성이 매우 높습니다.
사용하는 보드(EK-TM4C123GXL 등), 센서, 요구되는 응답 시간 등에 따라 설계 방식이 제각각입니다. 모든 상황에 들어맞는 '정답 설계도'는 존재하지 않습니다.
4. There is never a need to build a real-time operating system, because many commercial products exist.
오해: 상용 제품(FreeRTOS 등)이 많으니 직접 RTOS를 만들 필요는 전혀 없다.
진실: 특수한 목적이나 초경량 시스템, 혹은 고도의 보안이 필요한 하드웨어 가속기 설계 시에는 기존 OS가 너무 무거울 수 있습니다.
특히 FPGA 내부에 아주 작은 커스텀 커널을 올려야 할 때는 필요한 기능만 넣은 OS를 직접 설계해야 하는 상황이 반드시 생깁니다.
5. The study of real-time systems is mostly about scheduling theory.
오해: 실시간 시스템 공부는 거의 다 스케줄링 이론이다.
진실: 스케줄링은 아주 일부분일 뿐입니다.
실제로는 하드웨어와의 인터페이스(ISR), 메모리 관리, 태스크 간 통신(Mailbox/Queue), 그리고 하드웨어 타이밍 분석 등 시스템 전체를 아우르는 이해가 필요합니다.
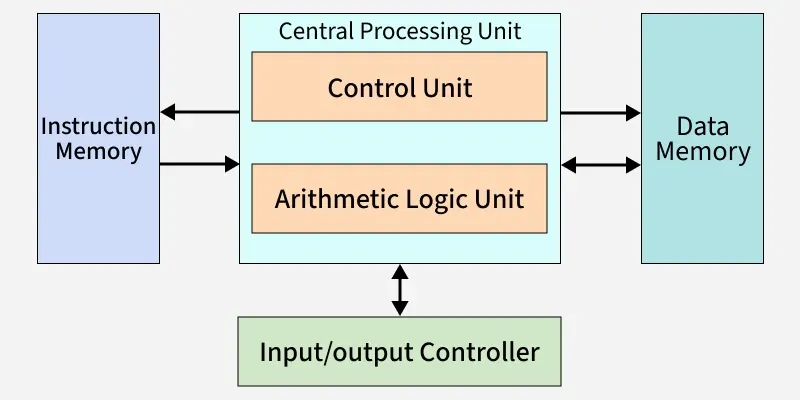
Von Neumann Computer system
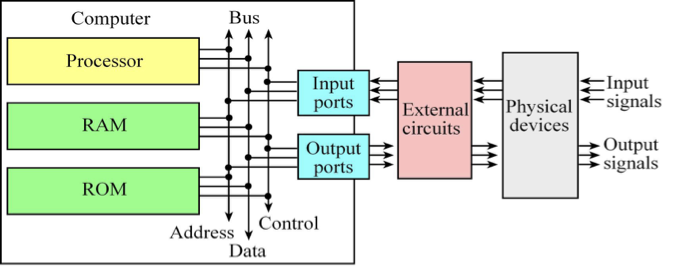
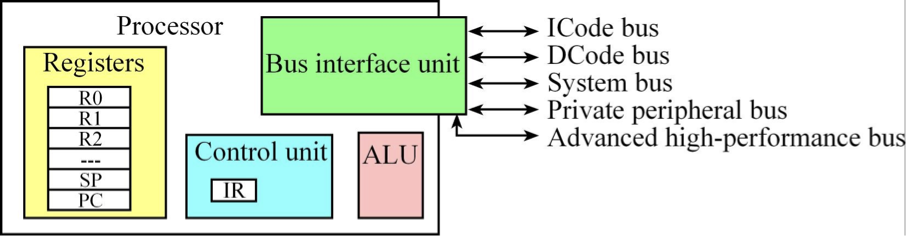
1. 폰 노이만 구조의 핵심 개념
폰 노이만 구조는 "프로그램 내장 방식(Stored-Program Concept)"을 처음으로 도입한 설계입니다. 이전의 컴퓨터들이 새로운 계산을 할 때마다 물리적으로 회로를 다시 연결(Hard-wired)해야 했던 것과 달리, 명령어와 데이터를 모두 메모리에 저장하여 소프트웨어만 바꾸면 범용적으로 사용할 수 있게 만든 혁신적인 구조입니다.
주요 구성 요소
- 중앙 처리 장치 (CPU): 연산(ALU)과 제어(Control Unit)를 담당합니다.
- 메모리 (Memory): 프로그램(명령어)과 데이터를 구분 없이 같은 공간에 저장합니다.
- 입출력 장치 (I/O): 외부와 데이터를 주고받습니다.
- 버스 (Bus): CPU와 메모리 사이를 연결하는 데이터 통로입니다.
2. 폰 노이만 병목 현상 (Von Neumann Bottleneck)
현재 수업 중인 'Advanced Computer Architecture'에서 가장 중요하게 다룰 지점입니다. 폰 노이만 구조의 가장 큰 특징이자 단점은 명령어와 데이터가 하나의 버스를 공유한다는 점입니다.
문제점: CPU 연산 속도는 비약적으로 발전했지만, 메모리에서 데이터를 가져오는 통로(Bus)의 대역폭은 제한적입니다.
결과: CPU가 아무리 빨라도 메모리에서 명령어와 데이터를 가져올 때까지 기다려야 하는 지연 시간이 발생하며, 이를 '폰 노이만 병목 현상'이라 부릅니다.
3. 현대 아키텍처에서의 극복 방안
현재 질문자님이 공부하시는 AI 하드웨어나 고성능 프로세서들은 이 병목 현상을 해결하기 위해 다음과 같은 기술들을 사용합니다.
- 하버드 아키텍처 (Harvard Architecture): 폰 노이만 구조와 달리 명령어 메모리와 데이터 메모리의 통로를 물리적으로 분리합니다. 현대의 CPU 내부 L1 캐시는 대부분 이 방식을 따릅니다.
- 캐시 메모리 (Cache Memory): CPU와 메인 메모리 사이에 속도가 빠른 SRAM 기반 캐시를 두어 메모리 접근 횟수를 줄입니다.
- 파이프라이닝 (Pipelining): 한 번에 하나의 명령어만 처리하는 게 아니라, 여러 단계를 겹쳐서 실행하여 처리 효율을 높입니다.
- 프로세싱 인 메모리 (PIM): 아예 메모리 내부에서 연산을 처리하여 데이터 이동 자체를 최소화하는 최신 AI 하드웨어 기술입니다.
MCU(Microcontroller)
마이크로컨트롤러(MCU)의 구조적 특징
MCU는 말 그대로 "단일 칩 내에 컴퓨터의 모든 구성 요소를 포함"하고 있는 장치입니다.
- All-in-one 시스템: CPU뿐만 아니라 메모리(RAM, Flash), I/O 포트, 타이머 등이 하나의 칩에 집적되어 있습니다. 폰 노이만 구조와 달리 외부 버스로 멀리 나갈 필요가 없어 제어 속도가 빠르고 전력 소모가 적습니다.
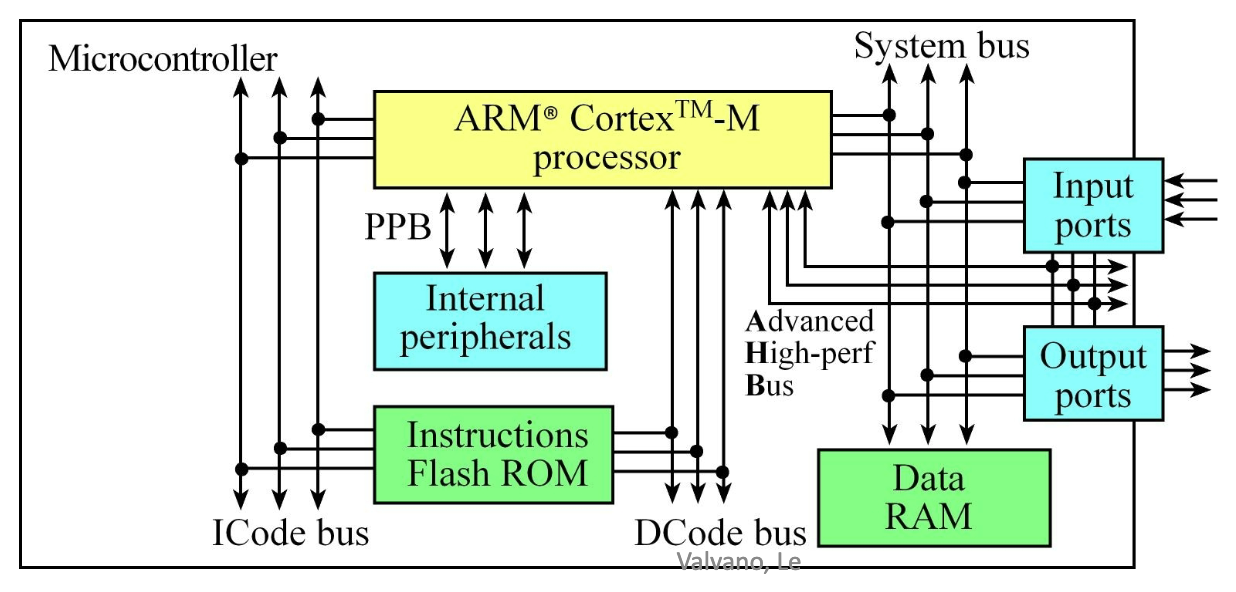
-
Harvard Architecture (ARM Cortex-M): 이미지에 언급된 TivaC TM4C123 같은 ARM 계열 MCU는 하버드 아키텍처를 사용합니다. 이는 명령어(Instruction)용 버스와 데이터(Data)용 버스가 물리적으로 분리되어 있어, 동시에 두 가지를 모두 처리할 수 있으므로 성능이 뛰어납니다.
-
Instruction Pipeline: 명령어를 여러 단계(Fetch, Decode, Execute 등)로 나누어 동시에 처리하는 파이프라인 구조를 가지고 있어, 클럭당 처리 효율을 극대화합니다.
ARM Cortex-M Register

1. General Purpose Registers: R0-R12
데이터 연산 및 일시적인 저장소로 사용됩니다.
- Low Registers (R0–R7): 모든 명령어 세트에서 접근 가능한 기본 레지스터입니다.
- High Registers (R8–R12): 일부 32-bit 명령어에서만 접근이 가능하며, 주로 복잡한 연산에 활용됩니다.
2. Special Registers: R13-R15
이 레지스터들은 시스템의 흐름을 제어하는 핵심적인 역할을 합니다.
R13: Stack Pointer (SP)
현재 스택의 주소를 가리킵니다.
Cortex-M은 MSP(Main Stack Pointer)와 PSP(Process Stack Pointer) 두 가지를 가집니다.
RTOS 관점: 커널이나 ISR은 MSP를 사용하고, 각 태스크(Thread)는 독립적인 PSP를 사용하여 시스템의 안정성을 높입니다.
R14: Link Register (LR)
함수 호출(BL 명령어) 시, 함수가 끝난 후 돌아갈 복귀 주소를 저장합니다.
ISR 실행 시에는 특별한 값(EXC_RETURN)이 저장되어 예외 처리가 끝난 후 올바른 모드로 복구되도록 돕습니다.
R15: Program Counter (PC)
다음에 실행할 명령어의 주소를 가리킵니다.
Cortex-M의 파이프라인 구조 때문에 실제 실행 중인 명령어보다 몇 단계 앞선 주소를 가리키는 특징이 있습니다.
3. 상태 및 제어 레지스터 (xPSR, CONTROL)
단순 수치 저장이 아니라 프로세서의 상태를 나타냅니다.
xPSR (Program Status Register):
연산 결과가 0인지(Z flag), 음수인지(N flag) 등의 상태와 현재 처리 중인 예외 번호(IPSR)를 저장합니다.
CONTROL Register:
현재 프로세서가 Privileged(특권) 모드인지 혹은 어떤 스택 포인터(MSP/PSP)를 사용할지 결정합니다.
PRIMASK (Priority Mask Register):
가장 강력하고 단순한 인터럽트 차단 도구입니다.
역할: NMI(Non-Maskable Interrupt)와 HardFault를 제외한 모든 인터럽트를 한꺼번에 차단합니다.
FAULTMASK (Fault Mask Register):
PRIMASK보다 한 단계 더 강력한 차단 도구입니다.
역할: NMI를 제외한 모든 예외를 차단합니다. 심지어 가장 치명적인 오류인 HardFault까지도 차단할 수 있습니다.
BASEPRI (Base Priority Mask Register):
RTOS 설계에서 가장 중요하게 다루는 레지스터입니다.
역할: 특정 우선순위보다 낮은(숫자가 큰) 인터럽트들만 선택적으로 차단합니다.
작동 방식: 예를 들어 BASEPRI를 0x50으로 설정하면, 우선순위가 0x50보다 높은(숫자가 작은 0x00~0x4F) 인터럽트는 여전히 허용하고, 그보다 낮은 우선순위만 막습니다.
Context Switching과의 연결
RTOS 수업에서 배우는 스케줄러가 작동할 때, 바로 이 레지스터 값들을 메모리(스택)에 저장하는 것이 Context Save입니다.
자동 저장: 인터럽트(ISR) 발생 시 R0~R3, R12, LR, PC, xPSR은 하드웨어가 자동으로 스택에 저장합니다.
수동 저장: 나머지 R4~R11 레지스터는 RTOS 스케줄러 코드가 직접 저장해야 합니
AAPCS
ARM Architecture Procedure Call Standard
1. ABI (Application Binary Interface)
-
ABI는 두 개의 이진 프로그램 모듈(보통 컴파일된 코드와 운영체제, 혹은 라이브러리) 사이의 저수준 인터페이스입니다.
-
정체: 하드웨어(ISA:Instruction Set Architecture)와 소프트웨어(OS/컴파일러) 사이의 약속입니다.
-
역할: 함수를 호출할 때 인자를 어떻게 전달할지, 메모리 정렬을 어떻게 할지, 시스템 콜(System Call)을 어떻게 요청할지 등을 정의합니다.
-
중요성: ABI가 맞지 않으면, 서로 다른 컴파일러로 짠 코드들이 한 시스템에서 함께 돌아갈 수 없습니다.
2. AAPCS
-
AAPCS는 ARM 아키텍처를 위한 ABI의 핵심 부분으로, 함수 호출(Procedure Call)이 일어날 때의 구체적인 규칙을 정의합니다.
-
주요 규칙 (ARM Cortex-M 기준)
질문하신 레지스터 정보와 연결해서 이해하면 좋습니다. -
인자 전달 (R0 - R3): 함수의 첫 4개 인자는 레지스터 R0, R1, R2, R3를 통해 전달합니다. 인자가 더 많으면 스택(Stack)을 사용합니다.
결과 반환 (R0): 함수의 리턴 값은 보통 R0 레지스터에 담겨 돌아옵니다. -
레지스터 보존 (Scratch vs Preserved):
Caller-saved (R0-R3, R12): 함수를 부르는 쪽이 저장해야 하는 레지스터입니다. 함수 내부에서 마음대로 써도 되지만, 값이 바뀔 수 있으므로 필요하면 호출 전에 스택에 저장해야 합니다. -
Callee-saved (R4-R11): 호출받은 함수가 책임지고 보호해야 하는 레지스터입니다. 함수 내에서 사용하려면 반드시 원래 값을 스택에 저장했다가, 함수가 끝나기 전에 복구해 놓아야 합니다.
-
스택 정렬: 함수 호출 시 스택 포인터(SP)는 반드시 8바이트 단위로 정렬되어야 합니다.
3. RTOS와 AAPCS의 관계 (Context Switching)
이게 왜 RTOS 수업에서 중요할까요? 바로 스케줄러(Scheduler)를 구현할 때 이 규칙을 그대로 따르기 때문입니다.
자동 스태킹 (Hardware Stacking): ARM Cortex-M은 인터럽트가 발생하면 R0-R3, R12, LR, PC, xPSR을 하드웨어가 자동으로 스택에 쌓습니다. 이는 AAPCS에서 정의한 'Caller-saved' 레지스터들과 일치합니다.
수동 스태킹 (Software Stacking): 나머지 R4-R11은 RTOS 커널(스케줄러)이 소프트웨어적으로 직접 저장해야 합니다.
Status Registers/PSR
PSR (Program Status Register)의 구조
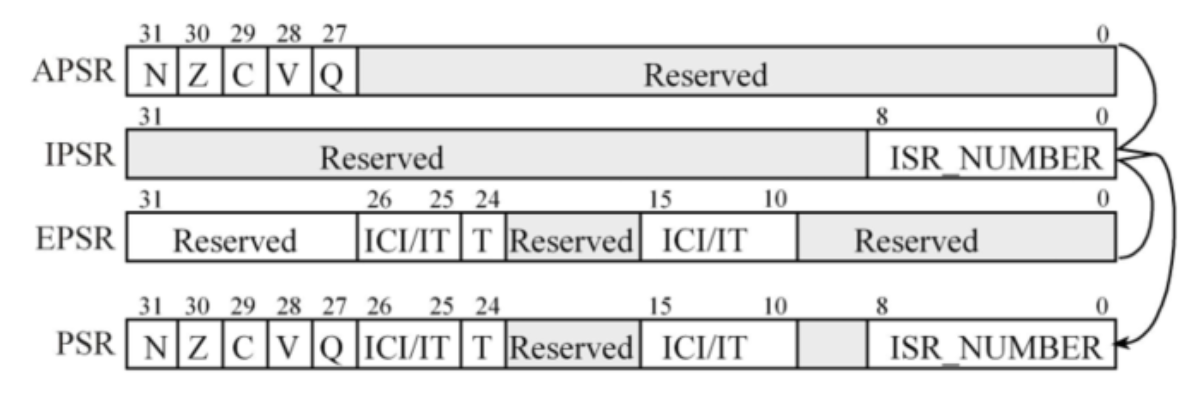
이미지에서 볼 수 있듯이, 32비트짜리 전체 PSR은 논리적으로 APSR, IPSR, EPSR이라는 3개의 하위 레지스터로 나뉘어 있으며, 우측의 화살표가 보여주듯 이 3개가 합쳐져서 하나의 완전한 32비트 PSR을 구성합니다.
- APSR (Application Program Status Register)
주로 ALU(산술논리연산장치)의 연산 결과 상태를 저장하는 구역으로, 최상위 비트(31~27)에 위치합니다. 어셈블리어에서 if나 while 같은 조건 분기문(Branch)을 실행할 때 이 플래그들을 보고 점프할지 말지를 결정합니다.
- N (Negative - Bit 31): 연산 결과가 음수일 때 1이 됩니다.
- Z (Zero - Bit 30): 연산 결과가 0일 때 1이 됩니다.
- C (Carry - Bit 29): 덧셈에서 올림(Carry)이 발생하거나, 뺄셈에서 빌림(Borrow)이 발생하지 않았을 때 1이 됩니다.
- V (Overflow - Bit 28): 부호 있는(Signed) 연산에서 표현할 수 있는 수의 범위를 넘어서는 오버플로우가 발생했을 때 1이 됩니다.
- Q (Saturation - Bit 27): DSP(디지털 신호 처리) 연산 등에서 값이 포화(Saturation, 최댓값/최솟값에 고정됨)되었을 때 1이 됩니다.
-
IPSR (Interrupt Program Status Register)
현재 실행 중인 인터럽트(Exception)의 번호를 나타내는 구역으로, 최하위 9개 비트(8~0)를 사용합니다. -
EPSR (Execution Program Status Register)
명령어 실행과 관련된 시스템의 내부 상태를 나타냅니다.-
T (Thumb state - Bit 24): ARM Cortex-M 프로세서는 항상 Thumb 상태(16/32비트 혼합 명령어 셋)로 동작해야 합니다. 따라서 이 비트는 항상 1이어야 하며, 만약 0으로 클리어하려고 시도하면 하드 폴트(Hard Fault) 에러가 발생합니다.
-
ICI/IT (Interrupt-Continuable Instruction / If-Then - Bits 26:25, 15:10):
-
LDM / STM (여러 개의 레지스터를 한 번에 메모리에 저장/불러오기) 같은 긴 명령어를 수행하던 중 인터럽트가 발생하면, 이 비트들에 어디까지 실행했는지 저장해 둡니다. 인터럽트가 끝나고 돌아왔을 때 처음부터 다시 하지 않고 이어서 할 수 있게 해줍니다.
-
RTOS에서 문맥 전환(Context Switch)이 일어날 때, 스케줄러는 현재 실행 중인 스레드의 상태를 고스란히 저장해야 합니다. 이때 CPU는 R0~R3, R12, LR, PC와 함께 방금 설명해 드린 이 32비트 단위의 전체 PSR (xPSR) 레지스터를 통째로 스택에 푸시(Push)합니다. 그래야 나중에 돌아왔을 때 연산 결과(APSR 플래그 등)를 잊어버리지 않고 이어서 연산할 수 있기 때문입니다.
Stacks
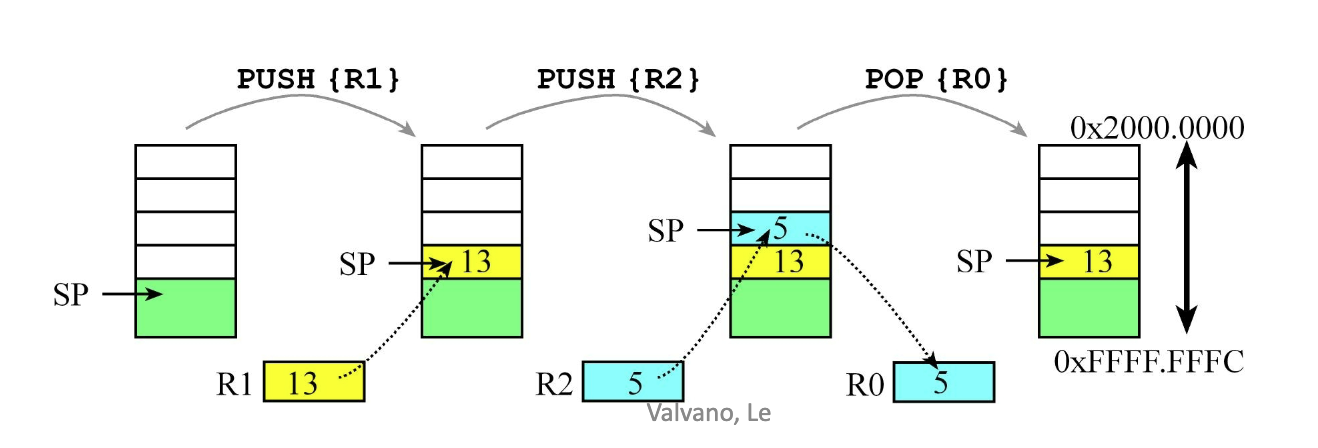
함수가 호출되거나 인터럽트가 발생했을 때, 방금 언급한 RAM 영역에 데이터를 잠시 대피시키는 공간이 바로 스택입니다. 스택은 나중에 들어간 데이터가 먼저 나오는 LIFO (Last-In-First-Out) 구조를 가집니다.
Push (데이터 밀어 넣기):
- 스택 포인터(SP)의 값을 먼저 4만큼 감소(Decrement) 시킵니다.
- 감소된 주소 위치에 32비트(4바이트) 데이터를 저장합니다.
(주소가 왜 감소할까요?) ARM의 스택은 메모리의 높은 주소에서 낮은 주소 방향으로(Top-down) 자라나기 때문입니다. 32비트 데이터는 4바이트를 차지하므로, 한 칸 이동할 때마다 주소가 4씩 바뀝니다.
Pop (데이터 꺼내기):
- 현재 스택 포인터(SP)가 가리키는 위치에서 32비트 데이터를 읽어옵니다 (Retrieve).
- 스택 포인터(SP)의 값을 4만큼 증가(Increment) 시켜 원래 위치(위쪽)로 돌아가게 합니다.
메모리 맵 (Memory Map)
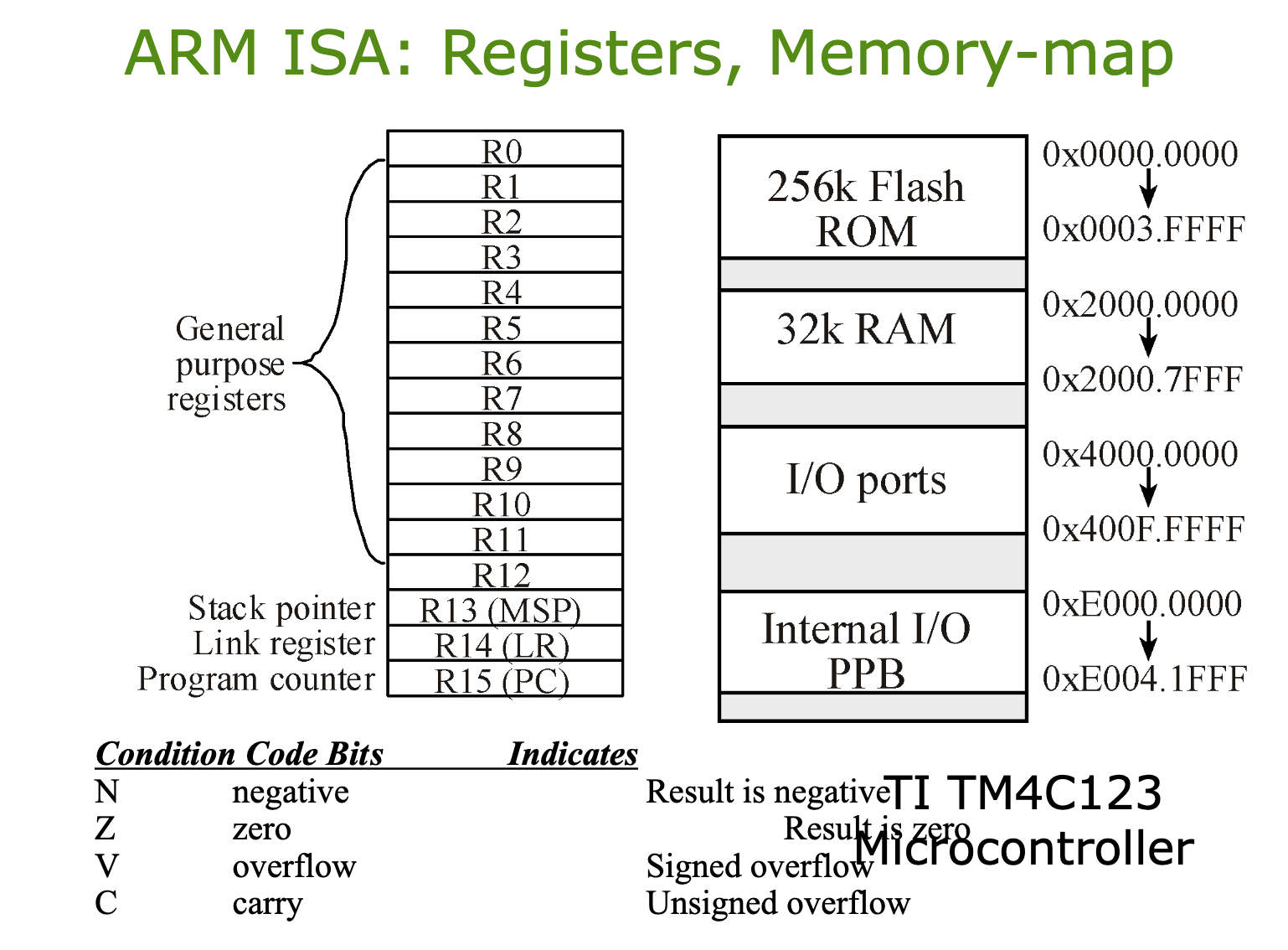
TI TM4C123 마이크로컨트롤러는 하나의 32비트 주소 체계 안에 물리적으로 다른 여러 장치들을 일렬로 배치해 두었습니다. 이를 메모리 맵 I/O (Memory-Mapped I/O)라고 합니다.
256k Flash ROM (0x0000.0000 ~ 0x0003.FFFF): 우리가 짠 프로그램 코드와 변하지 않는 상수들이 저장되는 비휘발성 메모리입니다.
32k RAM (0x2000.0000 ~ 0x2000.7FFF): 전원이 켜져 있는 동안 수시로 변하는 변수들이 저장되며, 스택(Stack) 공간도 이곳에 위치합니다.
I/O ports (0x4000.0000 ~ 0x400F.FFFF): GPIO 핀들이 연결된 주소입니다. (예: 포트 F에 불을 켜기 위해 데이터를 쓰는 주소)
Internal I/O PPB (0xE000.0000 ~ 0xE004.1FFF): NVIC, SysTick 등 Cortex-M 코어 내부의 핵심 주변장치들을 제어하는 구역입니다.
ARM Assembly Language
1. 어셈블리어의 4가지 필드 (Four Fields)
어셈블리어의 한 줄은 보통 다음과 같은 구조를 가집니다.
[Label] Opcode/Pseudo-op Operand(s) ; Comment① Labels (선택 사항)
역할: 메모리의 특정 주소(Address)에 사람이 읽을 수 있는 이름을 붙여주는 역할을 합니다.
특징: 줄의 가장 맨 앞(첫 번째 열)에서 시작해야 합니다.
용도: 함수의 이름(시작점)이 되거나, 반복문/조건문에서 점프(Branch)할 목표 지점이 됩니다.
② Opcodes or Pseudo-ops (필수)
CPU가 수행할 명령어(Opcode)이거나, 어셈블러(번역기)에게 내리는 지시어(Pseudo-ops/Directives)입니다.
[핵심 Opcodes - 실제 CPU가 실행하는 명령]
메모리 접근 (Load/Store 구조): ARM은 메모리에서 직접 연산하지 않고 레지스터로 가져와서 연산합니다.
- LDR (Load Register): 메모리에 있는 데이터를 CPU 레지스터로 가져옵니다.
- STR (Store Register): CPU 레지스터의 값을 메모리에 저장합니다.
데이터 이동 및 산술 연산:
- MOV (Move): 레지스터 간에 데이터를 복사하거나, 특정 숫자(상수)를 레지스터에 넣습니다.
- ADD (Add): 두 값을 더합니다.
- SUB (Subtract): 두 값을 뺍니다.
스택 메모리 제어:
- PUSH: 레지스터의 값을 스택 메모리에 집어넣습니다. (백업)
- POP: 스택 메모리에 있던 값을 레지스터로 빼옵니다. (복구)
흐름 제어 (Branch - 분기문):
- B (Branch): 무조건 지정된 라벨(주소)로 점프합니다. (C언어의 goto와 유사)
- BL (Branch with Link): 지정된 라벨로 점프하되, 돌아올 주소를 LR 레지스터에 저장합니다. (함수 호출 시 사용)
- BX (Branch and Exchange): 레지스터에 저장된 주소로 점프합니다. 주로 BX LR 형태로 쓰여 함수나 인터럽트에서 원래 곳으로 돌아갈 때(Return) 사용합니다.
시스템 제어 (인터럽트):
- CPSID I (Change Processor State, Interrupt Disable): 하드웨어 인터럽트를 끕니다. (Critical Section 진입)
- CPSIE I (Change Processor State, Interrupt Enable): 하드웨어 인터럽트를 켭니다.
---------------------------------------------------------------------
[핵심 Pseudo-ops - 어셈블러를 위한 지시어]
이것들은 CPU 명령어가 아니라, 컴파일 과정에서 번역기에게 "이 코드는 어떻게 배치해 줘"라고 지시하는 명령어입니다.
- AREA: 메모리의 섹션(코드 영역, 데이터 영역 등)을 정의합니다.
- EQU (Equate): C언어의 #define과 같습니다. 특정 숫자나 주소에 상징적인 이름을 붙여줍니다.
- IMPORT: 다른 파일(C파일이나 다른 어셈블리 파일)에 있는 함수나 변수를 가져와서 쓰겠다고 선언합니다.
- EXPORT: 이 파일에서 만든 라벨(함수명 등)을 다른 파일에서 쓸 수 있도록 전역으로 공개합니다.
- ALIGN: 데이터나 코드가 메모리에 저장될 때 일정한 바이트 단위(예: 4바이트)로 정렬되도록 공간을 맞춥니다. CPU가 메모리를 효율적으로 읽기 위해 필수적입니다.③ Operands (피연산자)
역할: Opcode가 연산할 대상(데이터, 레지스터, 주소 등)입니다.
특징: 명령어에 따라 피연산자가 0개일 수도, 3개 이상일 수도 있습니다. 쉼표(,)로 구분합니
④ Comments (선택 사항)
역할: 코드를 설명하는 주석입니다.
특징: 세미콜론(;)으로 시작하며, 그 뒤의 내용은 어셈블러가 무시합니다.
Object Code
소스 코드는 사람이 읽을 수 있는 문자열이지만, CPU(TM4C123GXL 보드의 Cortex-M4)는 오직 이진수(0과 1)만 이해할 수 있습니다. 컴파일러는 소스 파일을 읽어 CPU가 실행할 수 있는 명령어 집합인 Object Code로 변환합니다.
변환 과정: Source Code (.c/.sv) → Compiler/Assembler → Object Code (.o/.obj)
특징: 기계어 형태로 되어 있지만, 아직 여러 파일이 하나로 합쳐지지 않았기 때문에 바로 실행할 수는 없는 상태입니다.
Object Code는 "컴파일은 끝났지만 아직 실무(실행)에 투입되기 전인 상태의 기계어 덩어리"라고 이해하시면 됩니다.
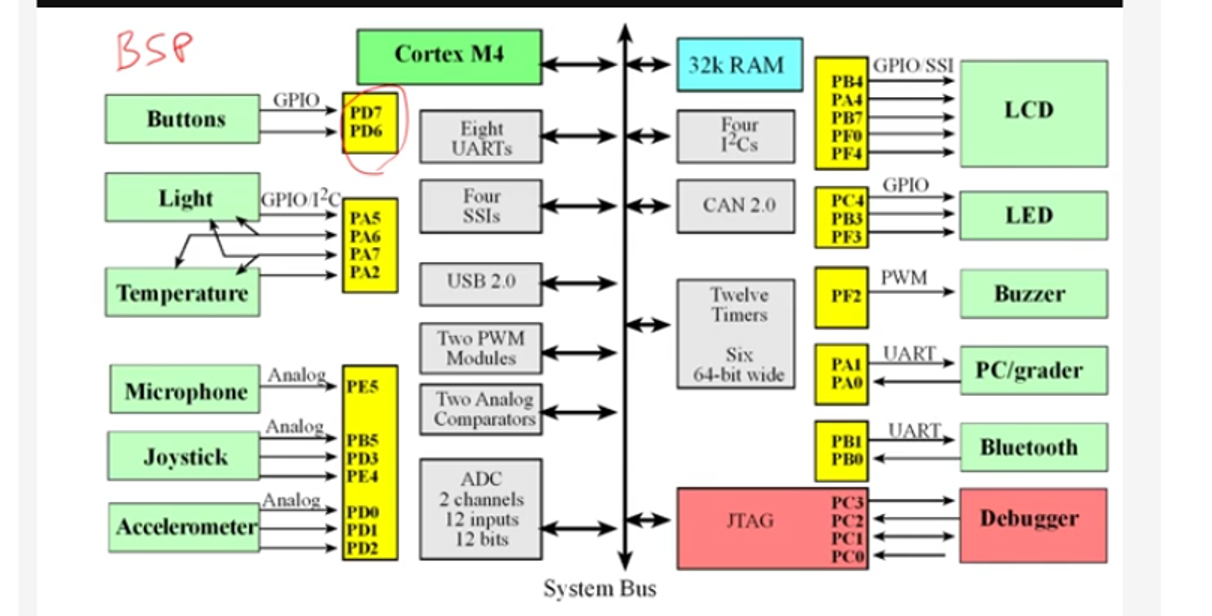
BSP
Board Support Package(BSP)는 특정 하드웨어 보드와 그 위에서 돌아가는 운영체제(RTOS 등) 사이를 연결해주는 최소한의 소프트웨어 계층입니다.
BSP의 핵심 역할: 하드웨어 추상화
운영체제나 애플리케이션 입장에서는 하드웨어의 복잡한 레지스터 주소를 일일이 알 필요 없이, BSP가 제공하는 인터페이스를 통해 하드웨어를 제어합니다.
초기화 (Initialization): CPU 클럭 설정, 메모리 컨트롤러 초기화, 스택 포인터 설정 등 보드가 전원이 켜진 후 가장 먼저 수행해야 할 작업을 담당합니다.
장치 드라이버 포함: UART, SPI, I2C, GPIO 등 보드에 내장된 주변 장치들을 제어하는 저수준(Low-level) 드라이버를 포함합니다.
커널 연결: RTOS가 하드웨어 타이머를 사용하여 스케줄링을 할 수 있도록 틱(Tick) 설정을 돕습니다.
| 구성 요소 | 역할 |
|---|---|
| Bootloader | 운영체제를 메모리에 로드하고 실행 준비를 함 |
| Device Drivers | 하드웨어(UART, LCD 등)를 제어하는 함수들 |
| Linker Script | 메모리 맵(Flash, RAM 주소)을 정의하여 데이터 배치 결정 |
| Header Files | 레지스터 주소 및 하드웨어 관련 상수 정의 |
