Real Time system
1. Hard Real-Time System
마감 기한(Deadline)을 단 한 번이라도 어기면 시스템 전체가 실패(Failure)하거나 치명적인 재앙이 발생하는 시스템입니다.
특징: 지연 시간(Latency)에 대한 관용이 전혀 없습니다.
결과: 기한을 넘긴 데이터는 아무리 정확해도 가치가 없으며, 인명 사고나 막대한 재산 피해로 이어집니다.
예시: 자동차 에어백 제어(충돌 후 수 ms 내에 전개되어야 함), 원자력 발전소 제어, 항공기 비행 제어 시스템.
2. Firm Real-Time System
마감 기한을 어기면 그 결과값의 가치가 0이 되는 시스템입니다. Hard 실시간만큼 재앙이 닥치지는 않지만, 기한을 넘긴 데이터는 쓸모가 없어 버려집니다.
특징: 기한을 조금 넘긴다고 시스템이 파괴되지는 않으나, 성능 저하가 발생합니다.
결과: 늦게 도착한 정보는 무효화 처리됩니다.
예시: 실시간 비디오 스트리밍(이미 지나간 프레임은 나중에 도착해도 화면에 뿌리지 않고 버림), 금융 거래 시스템.
3. Soft Real-Time System
마감 기한을 어겨도 데이터가 어느 정도 가치를 가지며, 시스템이 계속 동작하는 시스템입니다.
특징: 기한을 넘길수록 그 데이터의 효용성(Utility)이 점진적으로 감소합니다.
결과: 조금 늦어도 수용 가능하지만, 사용자 경험(UX)이 나빠집니다.
예시: 온라인 게임(핑이 튀어도 게임은 계속됨), 자동 온도 조절 장치, 일반적인 PC 소프트웨어.
Timing Constraints
1. Latency (응답 지연 시간)
이벤트가 발생하고 나서 시스템이 처리를 완료할 때까지 걸리는 시간입니다. 주로 인터럽트 기반 시스템에서 중요하게 다룹니다.
- 정의: 외부 사건()이 발생한 시각과 그에 대한 응답()이 완료된 시각의 차이입니다.
- 수식:
- 제약 조건: 시스템이 허용할 수 있는 의 최대값(Maximum Value)을 넘지 않아야 합니다.
- FPGA 프로젝트와의 연결: 질문자님이 FPGA에서 "데이터 준비 완료" 인터럽트를 보냈을 때, 프로세서가 ISR을 끝내고 "데이터 수신 완료"까지 걸리는 총 시간이 바로 Latency입니다.
2. Jitter (지터: 타이밍의 흔들림)
주로 주기적인 작업(Prescheduled Tasks)에서, 작업이 실행되어야 할 이상적인 시각과 실제 실행된 시각의 오차를 의미합니다.
주기적 작업의 예시:
- 매 30초마다 화재 감지 (Software checks for smoke)
- 22kHz로 소리 출력 (DAC)
- 300Hz로 심전도(EKG) 측정
이상적인 시각():
(여기서 는 시작 시간, 는 주기)
지터() 수식:
(
실제 실행 시간 - 이상적인 시간)
값이 양수(+)면 늦게 실행된 것이고, 음수(-)면 일찍 실행된 것입니다.
3. Real-Time 시스템의 판별 기준 (Bounded Jitter)
- 판별 기준: 주기적인 작업에서 발생하는 지터()가 항상 작지만 허용 가능한 범위(Small but acceptable value) 내에 있어야 실시간 시스템으로 분류됩니다.
- 수학적 정의: 지터에 대한 상한선()을 설정할 수 있어야 합니다.
즉, 작업이 조금 늦거나 빨라도 되지만, 절대 초 이상 어긋나면 안 된다는 뜻입니다.
4. 지터(Jitter)는 왜 발생하는가? (하드웨어 관점)
이 부분이 하드웨어 엔지니어에게 가장 중요한 포인트입니다.
- 인터럽트 비활성화 (Interrupts Disabled):
- OS 커널이나 다른 루틴이 중요 구간(Critical Section)을 보호하기 위해 인터럽트를 꺼놓은 시간 동안에는, 타이머가 울려도 태스크가 시작될 수 없습니다. 이것이 지터를 만드는 가장 큰 원인(Dominated factor)입니다.
- 높은 우선순위의 인터럽트 (Higher Priority Interrupts):
- 내 태스크보다 더 급한 인터럽트가 실행 중이라면, 그 처리가 끝날 때까지 기다려야 하므로 밀리는 시간만큼 지터가 발생합니다.
Thread VS Program
① 프로그램 (Program) = "설계도" / static
아직 실행되지 않은, 파일 시스템(하드디스크 등)에 저장된 파일 그 자체입니다.
예: 윈도우의 .exe 파일, 질문자님이 작성해서 보드에 굽기 전의 .bin 또는 .elf 파일.
혼자서는 아무것도 하지 못합니다. CPU를 쓰지도 않고, 메모리를 차지하지도 않습니다 (저장 공간만 차지함).
A program is a sequence of software commands connected together to affect a desired outcome. Programs perform input, make decisions, record information, and generate outputs.
② 스레드 (Thread) = "일꾼" /dynamic == light-weight process
프로그램이 메모리에 로딩되어 실행되면 '프로세스(Process)'가 되는데, 그 안에서 실제로 코드를 한 줄 한 줄 실행하며 움직이는 흐름입니다.
CPU의 레지스터(PC, SP 등)를 실제로 사용하며 연산을 수행합니다.
하나의 프로그램이 실행될 때, 여러 명의 일꾼(멀티 스레드)이 동시에 투입될 수 있습니다.
A thread is defined as either execution itself or the action caused by the execution.
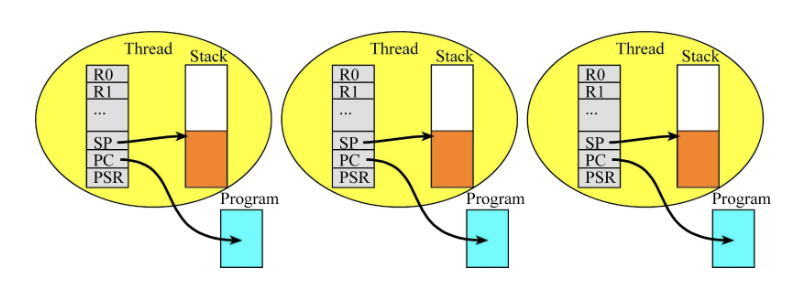
1. 레지스터의 진실: "책상은 하나, 사람은 여러 명"
Threads have physically separate registers. The stacks will be physically separate, but in reality there is just one set of registers that is switched between the threads as the thread scheduler operates
설명:
물리적 현실: 질문자님이 쓰시는 TM4C123(Cortex-M4) 칩 안에는 레지스터 세트(R0~R15)가 딱 한 세트밖에 없습니다.
논리적 가상화: 하지만 각 스레드는 마치 자기가 CPU를 독점하고 있는 것처럼 착각합니다.
비유: 회사에 책상(CPU 레지스터)이 딱 하나 있습니다. 사원 A가 일하다가 잠시 자리를 비울 때, 책상 위의 서류를 싹 치우고 나갑니다. 사원 B가 와서 자기 서류를 펼쳐놓고 일합니다. 책상은 하나지만, 각자 자기만의 업무 환경(레지스터 값)을 유지하는 것과 같습니다.
2. 문맥 교환의 과정: "짐 싸고 짐 풀기"
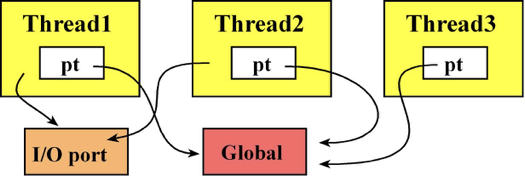
The thread switcher will suspend one thread by pushing all the registers on its stack, saving the SP, changing the SP to point to the stack of the next thread to run, then pulling all the registers off the new stack. Since threads interact for a common goal, they do share resources such as global memory, and I/O devices
-
Suspend (중단 & 저장): 현재 실행 중인 스레드(Thread A)의 레지스터 값들(R0~R15, PSR 등)을 Thread A의 스택(Stack) 메모리에 차곡차곡 쌓습니다(Push). 이것이 "현재 상태를 얼려두는" 과정입니다.
-
Save SP (주소 기억): 짐을 다 쌓았으면, 그 짐이 어디까지 쌓였는지 가리키는 스택 포인터(SP) 위치를 Thread A의 제어 블록(TCB)에 기록해 둡니다.
-
Change SP (교체): 이제 CPU의 SP 레지스터 값을 다음 순서인 Thread B의 스택 주소로 바꿔치기합니다. (이제 CPU는 Thread B의 메모리를 바라봅니다.)
-
Restore (복구): Thread B의 스택에 저장되어 있던 예전 레지스터 값들을 다시 CPU의 물리적 레지스터로 꺼내옵니다(Pop).
-
실행 재개: CPU가 동작을 시작하면, 자연스럽게 Thread B가 멈췄던 그 지점부터 다시 실행됩니다.
3. 자원의 공유: "한 지붕 세 가족"
차이점: 스레드마다 스택(Stack)은 각자 따로(Physically separate) 가지고 있어서 서로의 함수 호출이나 지역 변수는 침범하지 않습니다.
공유점: 하지만 전역 변수(Global Memory)와 I/O 장치(UART, GPIO 등)는 모든 스레드가 공유합니다.
장점: 데이터를 주고받기가 매우 쉽고 빠릅니다. (복잡한 통신 과정 불필요)
단점(위험): 아까 말씀드린 경쟁 조건(Race Condition)이 발생합니다. Thread A가 UART로 "Hello"를 보내는 중에 Thread B가 끼어들어서 "World"를 보내버리면 출력은 "HeWorlldo" 처럼 깨져버릴 수 있습니다.
Question
1. What’s the difference between a program and a thread?
가장 큰 차이는 "정적이냐(Static) 동적이냐(Dynamic)"의 차이입니다.
프로그램 (Program):
하드디스크나 보드의 Flash ROM에 저장되어 있는 '죽어있는 코드 덩어리'입니다.
비유하자면 주방에 꽂혀 있는 '요리 레시피 책'과 같습니다. 스스로 움직이지 않습니다.
스레드 (Thread):
프로그램을 실제로 메모리에 올려서 실행하고 있는 '독립적인 실행 흐름(동적인 상태)'입니다.
비유하자면 레시피 책을 보고 요리를 직접 수행하는 '요리사'입니다.
RTOS 환경에서는 하나의 프로그램 안에서 여러 명의 요리사(다중 스레드)가 동시에 각자의 요리를 진행할 수 있습니다.
가장 중요한 특징: 각 스레드는 자신만의 CPU 상태(PC, R0~R15)와 고유한 스택(Stack) 공간을 독립적으로 가집니다.
Can threads pass parameters to each other using the stack like functions?
스레드끼리 일반 함수들처럼 스택(Stack)을 이용해서 파라미터를 넘겨줄 수 있나요?
정답: 아니요, 절대 불가능합니다 (No).
일반적인 C언어의 함수 호출(Function Call)은 하나의 스택 메모리를 공유하기 때문에 매개변수를 스택에 쌓아서(Push) 전달할 수 있습니다. 하지만 스레드는 다릅니다.
불가능한 이유 (Private Stack):
앞서 TCB(Thread Control Block)를 배울 때 보셨듯, 스레드는 각자 자신만의 '독립적인 개인 스택(Private Stack)'을 따로 가집니다. Thread A가 파라미터를 넘기려고 자기 스택에 데이터를 집어넣어 봤자, Thread B는 실행될 때 오직 자기 자신의 스택만 쳐다보기 때문에 Thread A의 스택에 있는 데이터를 읽을 수 없습니다.
그럼 스레드끼리 데이터는 어떻게 주고받나요? (IPC, Inter-Process Communication)
스레드 간에 데이터를 넘겨주려면 개인 공간(Stack)이 아니라 공용 공간(Shared Memory)을 써야 합니다.
전역 변수 (Global Variables): 가장 단순하지만, 동시에 접근하면 데이터가 깨질 수 있어서 반드시 세마포어(Semaphore)나 뮤텍스(Mutex)로 보호(Critical Section Protection)해야 합니다.
메시지 큐 / FIFO (Message Queue): RTOS가 제공하는 안전한 우체통 같은 기능입니다. Thread A가 큐에 데이터를 넣으면, Thread B가 큐에서 데이터를 빼갑니다.
요약하자면: "스레드는 각자 독립적인 개인 스택을 가지기 때문에 스택으로 데이터를 주고받을 수 없으며, 반드시 전역 변수나 메시지 큐 같은 OS의 통신 기능을 사용해야 한다"가 정답입니다
State of Thread
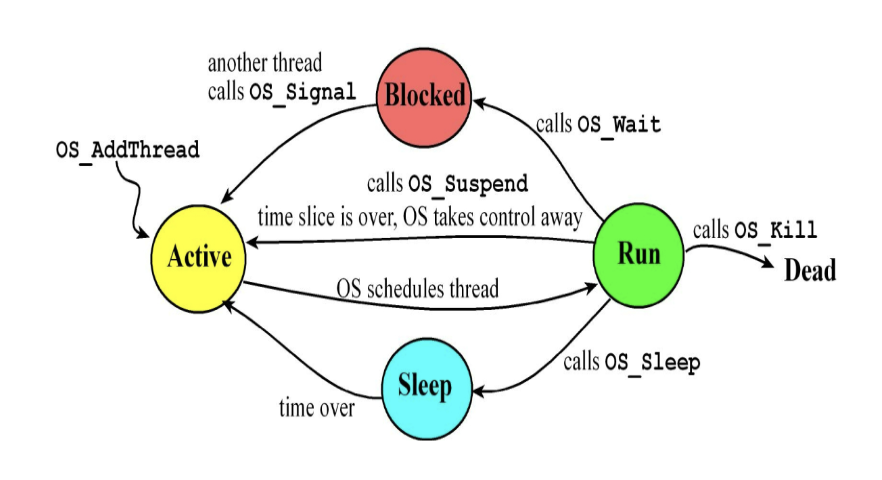
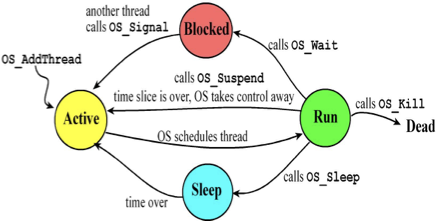
1. 주요 4가지 상태 (The 4 Main States)
RTOS 스케줄러는 스레드를 다음 네 가지 상태 중 하나로 관리합니다.
① Run State (실행 상태)
정의: 현재 CPU를 차지하고 실제로 명령어를 실행 중인 상태입니다.
특징: 멀티코어 프로세서라면 여러 개의 스레드가 동시에 Run State에 있을 수 있지만, 단일 코어에서는 한 번에 하나만 존재합니다.
② Active State (활성/준비 상태)
정의: 실행할 준비(Ready)는 완벽하게 끝났지만, 자신의 차례를 기다리고 있는 상태입니다.
상황: 스케줄러가 "너 잠깐 비켜"라고 해서 CPU를 뺏겼거나, 방금 막 생성되어 대기열(Ready Queue)에 들어온 상황입니다.
③ Sleep State (수면 상태)
정의: 정해진 시간(Fixed amount of time) 동안 기다려야 할 때 들어가는 상태입니다.
특징:이 상태에 들어가면 OS는 해당 스레드를 실행하지 않습니다.
약속된 시간이 지나면 OS가 다시 Active 상태로 깨워줍니다.
주로 실시간성이 엄격하지 않은 작업(Non real-time tasks)에서 사용됩니다.
CPU 자원을 낭비하지 않고 다른 스레드에게 양보(Free up)하는 효과가 있습니다.
④ Blocked State (차단 상태)
정의: 외부 이벤트(I/O)가 발생하기를 하염없이 기다리는 상태입니다.
원인:다른 스레드로부터 데이터를 받아야 하거나
키보드 입력, 프린터 준비 완료 등 I/O 장치의 응답을 기다릴 때 발생합니다.
특징: 이 상태에서는 스스로 진행(Progress)할 수 없으므로, 이벤트가 발생할 때까지 스케줄러가 실행시키지 않습니다.
스레드가 당장 작업을 진행할 수 없을 때(Waiting) 발생하는 세 가지 상황(Block, Sleep, Spin)
1. 스레드가 "막히는(Stuck)" 상황이란?
스레드가 자기 일을 하다가 더 이상 진도를 나갈 수 없는 상황입니다.
다른 스레드가 계산한 결과값이 필요할 때
사용자가 버튼을 누르거나 센서 값(I/O)이 들어오길 기다릴 때
단순히 "1초 동안 대기(Delay)"해야 할 때
이럴 때 RTOS는 CPU 자원을 낭비하지 않기 위해 스레드의 상태를 변경합니다.
2. 효율적인 대처법: Block & Sleep (양보하기)
OS가 스레드를 잠시 멈춰두고, 그동안 CPU가 다른 유용한 작업을 할 수 있게 해주는 똑똑한 방법입니다.
Block (블록 / 대기 상태): * 의미: "필요한 데이터(또는 이벤트)가 도착할 때까지 내 차례를 건너뛰어 줘."
특징: 특정 조건이 만족될 때까지 스케줄러는 이 스레드를 실행 대기열(Ready list)에서 빼버립니다.
Sleep (수면 상태):
의미: "나 100ms 동안만 잘 테니까, 시간 다 되면 깨워 줘."
특징: 정해진 시간이 지날 때까지 실행되지 않습니다.
장점: 두 가지 모두 자신이 CPU를 쓰지 않는 동안 다른 스레드에게 CPU를 양보(Free up)하므로, 시스템 전체의 효율이 극대화됩니다.
3. 비효율적인 대처법: Spin (제자리돌기 / Busy Waiting)
양보하지 않고 자기 혼자 CPU를 꽉 잡고 시간을 낭비하는 원시적인 방법입니다.
Spin (스핀):
의미: "버튼 눌렸나? 아니네. 버튼 눌렸나? 아니네. 버튼 눌렸나?..."
특징: while(Flag == 0); 처럼 아무 의미 없는 루프를 뱅글뱅글 돕니다.
단점 (Wastes time slice): 스케줄러 입장에서는 이 스레드가 루프를 돌고 있으니 "지금 열심히 일하는 중(Active state)"이라고 착각합니다. 결국 자신에게 할당된 턴(Time slice)을 조건 확인만 하다가 전부 낭비하게 되고, 다른 스레드들은 그만큼 실행될 기회를 뺏기게 됩니다.
Producer-Consumer pattern
RTOS와 멀티스레딩 환경에서 가장 유명하고 중요한 설계 패턴입니다.
질문자님이 FPGA에서 FIFO를 사용해 서로 속도가 다른 모듈을 연결하는 것과 정확히 같은 원리입니다. 이를 RTOS의 Mailbox와 엮어서 설명해 드릴게요.
1. Producer & Consumer 개념
두 개의 서로 다른 스레드(일꾼)가 데이터를 주고받는 상황을 가정해 봅시다.
Producer (생산자):
데이터를 만들어내는 스레드입니다.
예: 센서 값을 읽어오는 스레드, UART로 패킷을 수신하는 ISR.
Consumer (소비자):
데이터를 가져가서 처리하는 스레드입니다.
예: 읽어온 값을 LCD에 띄우는 스레드, 모터 PID 제어 연산을 하는 스레드.
문제점: 생산자가 데이터를 만드는 속도와 소비자가 처리하는 속도가 다를 수 있습니다. (예: 데이터는 막 쏟아지는데, LCD 출력이 느린 경우)
2. Mailbox의 역할 (중재자)
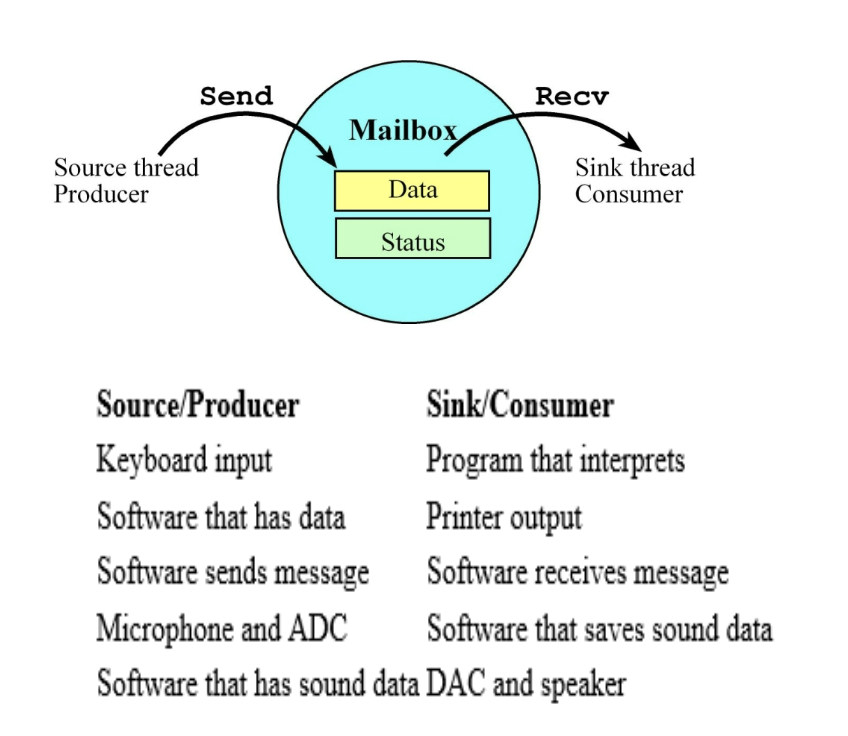
이 둘 사이에서 데이터를 임시 보관하고 교통정리(동기화)를 해주는 것이 바로 Mailbox입니다.
데이터 전달 (Data Passing): 생산자가 만든 32-bit 데이터(혹은 포인터)를 보관합니다.
동기화 (Synchronization): 이게 제일 중요합니다.
비어있을 때: 소비자가 달라고 해도 줄 게 없으므로, 소비자를 Blocked(대기) 상태로 만듭니다. (CPU 낭비 방지)
채워졌을 때: 생산자가 데이터를 넣으면, 자고 있던 소비자를 Wake up(활성) 시켜줍니다.
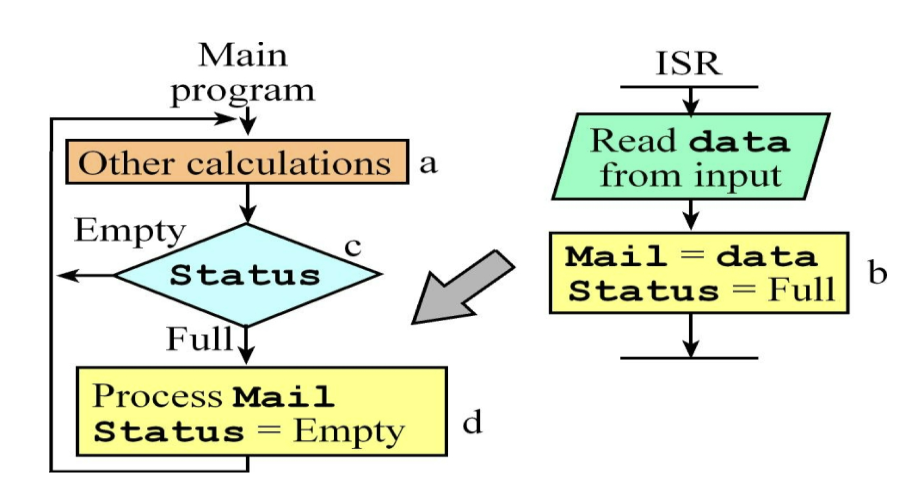
전체 구조: 전경/배경 시스템 (Foreground/Background)
오른쪽 (ISR): 하드웨어 신호에 의해 불규칙하게 실행되는 생산자(Producer)입니다. (RTOS 용어로는 'Background'라고도 부릅니다.)
왼쪽 (Main Program): 무한 루프를 돌며 작업을 수행하는 소비자(Consumer)입니다. (RTOS 용어로는 'Foreground'라고 부릅니다.)
단계별 상세 동작
오른쪽: ISR (데이터 생산)
ISR(Interrupt Service Routine)은 하드웨어 설계자에게는 "인터럽트가 발생했을 때 CPU가 즉시 실행하는 특수 함수"라고 이해하면 가장 정확합니다.
Read data from input: 하드웨어(예: UART, 센서)로부터 데이터가 들어오면 인터럽트가 발생하고, ISR이 데이터를 읽습니다.
Mail = data (b): 읽은 데이터를 전역 변수인 Mail이라는 공간(우체통)에 넣습니다.
Status = Full (b): "우체통에 편지 넣었어요!"라고 깃발을 듭니다. (Status 변수를 Full 상태로 변경)
이 과정은 매우 빠르게 끝나고, 다시 메인 프로그램으로 복귀합니다.
왼쪽: Main Program (데이터 소비)
Other calculations (a): 메인 프로그램은 평소에 자기 할 일(다른 계산, LED 제어 등)을 하고 있습니다.
Status 확인 (c): 루프를 돌면서 "혹시 편지 온 거 있나?" 하고 Status 변수를 확인합니다. (Polling 방식)
Empty라면: 화살표가 다시 위로 올라가죠? 편지가 없으니 하던 일을 계속합니다.
Full이라면: 아래쪽(d)으로 내려갑니다.
Process Mail (d): Mail 변수에 들어있는 데이터를 꺼내서 처리합니다. (예: 화면에 출력, 모터 제어값 변경)
Status = Empty (d): 처리가 끝났으니 "우체통 비웠음"이라고 깃발을 내립니다.
이 그림에서 중요한 기술적 포인트 (RTOS/FPGA 관점)
이 그림은 간단해 보이지만, 동기화(Synchronization)의 핵심을 담고 있습니다.
공유 변수 (Shared Resource): Mail과 Status는 ISR과 메인 프로그램이 같이 쓰는 전역 변수입니다. 앞서 말씀드린 "한 지붕 세 가족" 상황이죠.
폴링(Polling) 구조: 왼쪽의 다이아몬드(Status) 부분은 OS가 재워주는(Block) 방식이 아니라, 메인 루프가 직접 검사하는 방식입니다.
장점: 구현이 매우 쉽습니다.
단점: 메인 프로그램이 Other calculations를 하느라 바빠서 Status 확인이 늦어지면, ISR이 데이터를 또 보내버려서 이전 데이터가 덮어씌워지는 Data Overrun 문제가 발생할 수 있습니다.
요약하자면: 이 그림은 "ISR이 편지(Data)를 넣고 깃발(Status)을 올리면, 메인 프로그램이 깃발을 보고 편지를 꺼내가는 과정"을 도식화한 것입니다.
3. 동작 시나리오 (RTOS 관점)
TM4C123 보드에서 코드를 짠다면 다음과 같은 흐름이 됩니다.
상황 A: 생산자가 더 빠른 경우
Producer: 데이터를 Mailbox_Send(data)로 보냅니다.
Consumer: 아직 이전 데이터를 처리 중이라 바쁩니다.
Mailbox: 이미 데이터가 차 있다면, Producer는 대기(Spin/Block)하거나 에러를 띄웁니다. (FPGA의 FIFO Full 상황과 동일)
상황 B: 소비자가 더 빠른 경우 (일반적인 경우)
Consumer: Mailbox_Recv()를 호출합니다.
Mailbox: "데이터가 없는데?" → Consumer를 Blocked State로 보냅니다. (이때 CPU는 다른 스레드를 실행하러 갑니다. 효율적!)
Producer: 센서 값을 읽어서 Mailbox_Send(data)를 합니다.
RTOS: 메일박스에 데이터가 들어왔으니, 자고 있던 Consumer를 깨워서 Active State로 바꿉니다.
Consumer: 깨어나서 데이터를 받아 처리합니다.
| 구분 | FPGA (Hardware) | RTOS (Software) |
|---|---|---|
| 연결 도구 | FIFO (Async FIFO) | Mailbox (or Queue) |
| 제어 신호 | "empty, full 플래그" | Semaphore (세마포어) |
| 대기 방식 | rd_en 신호를 0으로 두고 대기 | 스레드를 Block/Sleep 시킴 (Context Switch) |
| 목적 | Clock Domain Crossing (CDC) 해결 | 스레드 간 속도 차이 극복 및 동기화 |
