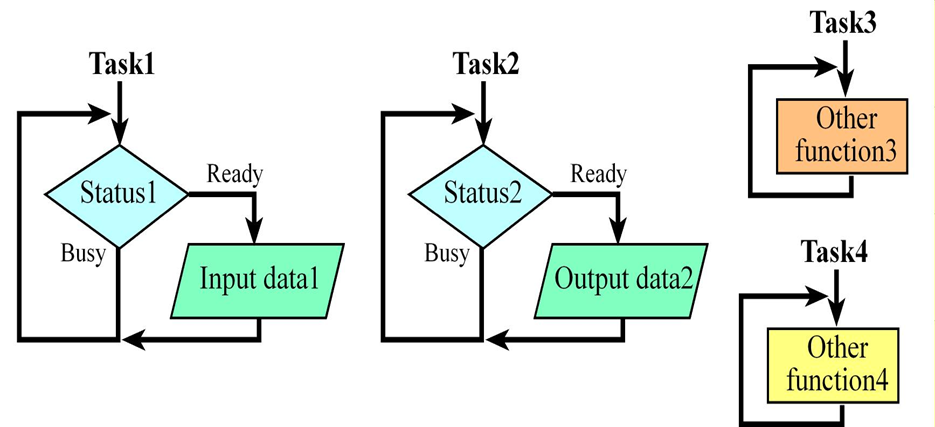

task 1 -> input
task 2 -> output
task 3 -> 대기
task 4 -> 대기스케줄러는 실행 대기 중인(Ready) 스레드들을 하나씩 번갈아 가며 매우 빠르게 전환(Switching)합니다
1. RTOS와 스케줄러의 필요성
복잡한 시스템에서 서로 느슨하게 연결된(loosely coupled) 여러 작업(Foreground tasks)을 효율적으로 처리하기 위해서는 어떻게 해야 할까요?
해결책: 스레드 스케줄러(Thread Scheduler)가 포함된 실시간 운영체제(RTOS)를 사용하는 것입니다.
작동 방식: Task1, Task2, Task3 등이 각각 마치 하나의 메인 프로그램인 것처럼 코드를 작성하면, RTOS의 핵심 기능인 스케줄러가 시스템의 제약 조건을 만족시키는 방식으로 이 모든 스레드를 실행시킵니다.
2.Scheduler, Concurrency
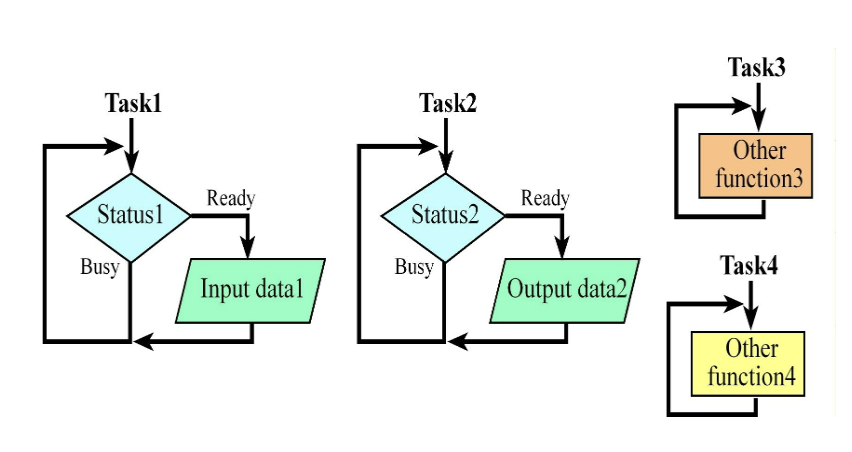
스케줄러와 동시성
스케줄러는 여러 스레드가 동시에 실행되는 것처럼 보이게 하는 동시성(Concurrent processing) 개념을 제공합니다.
실제 작동 원리: 겉보기에는 여러 작업이 동시에 돌아가는 것 같지만, Cortex-M과 같은 단일 프로세서(Single Processor) 환경에서는 한 번에 오직 하나의 스레드만 실행됩니다. * 환상(Illusion): 스케줄러는 실행 대기 중인(Ready) 스레드들을 하나씩 번갈아 가며 매우 빠르게 전환(Switching)합니다. 이 속도가 빠르기 때문에 사용자에게는 마치 모든 작업이 동시에 실행되는 것과 같은 환상을 줍니다.
3.Preemptive Scheduler
선점형 스케줄러
OS는 메인 스레드와 이벤트 스레드를 모두 관리하지만, 여기서는 메인 스레드 스케줄링에 집중합니다.
작동 방식: 프로세서가 유휴 상태(Free)가 되면, 스케줄러는 대기 리스트(Ready list)에 있는 메인 스레드 중 하나를 선택하여 실행시킵니다.
선점형(Preemptive)의 의미: 주기적인 인터럽트(Periodic Interrupt)가 발생하면 실행 중이던 메인 스레드는 잠시 중단(Suspended)됩니다. 스케줄러는 다음에 실행할 새로운 스레드를 선택하고, 인터럽트에서 복귀할 때 이 새로운 스레드를 실행합니다. * 제어권: 실행 중인 스레드를 언제 중단하고, 언제 다시 활성 상태로 돌릴지는 전적으로 OS가 결정합니다.
4. 스케줄링 알고리즘의 종류
A. Round Robin
라운드 로빈
대기 중인 스레드들을 순환식으로 실행합니다.
모든 스레드에게 동일한 실행 시간을 부여합니다.
B. Weighted Round Robin
가중치 라운드 로빈
라운드 로빈처럼 순환하지만, 스레드마다 불평등한 가중치를 부여합니다.
구현 방법:
중요도에 따라 각 스레드에 할당되는 실행 시간을 다르게 설정합니다.
중요한 스레드를 더 자주 실행시킵니다. (예: 스레드 1이 중요할 때 -> 1, 2, 1, 3, 1, 2, 1... 순서로 실행)
C. Priority Scheduler
우선순위 스케줄러
각 스레드에 우선순위 번호를 부여합니다(예: 1이 가장 높음).
규칙: 우선순위가 1인 스레드가 실행 대기 중이라면, 우선순위 2인 스레드는 절대 실행되지 않습니다. (높은 우선순위가 먼저 실행됨)
만약 모든 스레드의 우선순위가 같다면, 라운드 로빈 방식으로 작동합니다.
장점: 중요한 작업에 높은 우선순위를 주어 지연 시간(Latency/응답 시간)을 줄일 수 있습니다.
단점 - 기아 상태(Starvation): 시스템이 바쁠 경우, 낮은 우선순위를 가진 스레드는 영원히 실행 기회를 얻지 못할 수도 있습니다.
5. 우선순위 결정 기준과 메트릭 (Metrics)
실시간 시스템에서는 단순한 중요도 외에도 다양한 기준으로 우선순위를 정합니다.
- 마감 시간(Deadline): 작업이 완료되어야 하는 시점입니다.
- 여유 시간 (Slack Time): (마감까지 남은 시간) - (작업 완료에 걸리는 시간)
예: 과제 마감이 금요일이고 오늘은 화요일(3일 남음). 과제하는 데 1일이 걸린다면, 슬랙 타임은 2일입니다.
슬랙 타임이 음수가 되면 마감 기한을 놓치게 됩니다.
기타 우선순위 할당 기준:
- 지연 시간(Latency) 최소화
- 지연에 따른 금전적 비용 최소화
- CPU 중심 작업보다 I/O 중심 작업에 우선순위 부여
- 더 자주 실행되어야 하는 작업에 우선순위 부여
- 가장 급한 마감 시간(Smallest time-to-deadline first) 우선
- 가장 적은 여유 시간(Smallest slack time first) 우선
6. RMS (Rate Monotonic Scheduling)
작업 간의 상호작용이 거의 없다고 가정할 때, 스케줄링이 가능한지 예측하기 위해 Rate Monotonic Theorem을 사용합니다.
할당 규칙: 주기(Period)가 짧은(더 자주 실행되는) 작업일수록 더 높은 우선순위를 부여합니다.
스케줄링 가능성 판단:
전체 CPU 사용률(Utilization)이 특정 한계치 아래라면 모든 타이밍 제약 조건을 만족한다고 보장할 수 있습니다.
작업의 개수가 많아질수록 이 한계치는 에 수렴합니다. 즉, 전체 작업의 CPU 사용률이 약 69.32% 이하라면, RMS를 통해 모든 작업이 마감 기한 내에 처리됨을 보장할 수 있습니다.
"이 스케줄링이 과연 성공할까?" (스케줄링 가능성 검사)
RMS의 가장 큰 장점은 "이 시스템이 과부하로 터질지 안 터질지 미리 수학적으로 계산할 수 있다"는 점입니다. 이것을 Rate Monotonic Theorem (RM 정리)라고 합니다.
1단계: CPU 사용률(Utilization, ) 계산하기
- : 스케줄링할 전체 작업(Task)의 개수
- (Computation Time): 번째 작업이 한 번 실행되는 데 걸리는 최대 연산 시간(최악의 실행 시간)
- (Period): 번째 작업이 반복해서 실행되는 주기 (RMS에서는 보통 이 주기가 곧 해당 작업의 마감 시간(Deadline)이 됩니다)
각 작업이 CPU를 얼마나 잡아먹는지 비율을 더합니다.
예를 들어볼까요?
- Task 1: 주기 20ms, 실행시간 10ms (50%)
- Task 2: 주기 50ms, 실행시간 10ms (20%)
- 총 CPU 사용률(): (70%)
2단계: 한계치(Bound)와 비교하기
이제 계산한 총 사용률()이 아래 공식보다 작으면, "무조건 스케줄링 성공"을 보장합니다.
작업 개수()에 따른 한계치는 다음과 같습니다
: 100%
: 약 82.8%
: 약 77.9%
...
: 약 69.3% ()
3단계: 판정하기
아까 예시에서 총 사용률이 70%였죠?작업이 2개()일 때의 한계치는 82.8%입니다.
- 70% 82.8% 이므로, 이 시스템은 RMS를 쓰면 절대 데드라인을 어기지 않고 완벽하게 돌아갑니다.
만약 사용률이 한계치(약 69%)를 넘더라도 무조건 실패하는 건 아니지만, "보장할 수는 없다"는 상태가 됩니다. (이때는 직접 돌려봐야 알 수 있습니다.)
RMS를 쓰기 위한 3가지 전제 조건
이 이론이 통하려면 몇 가지 가정이 필요합니다. (현실과는 조금 다를 수 있지만, 이론적 모델입니다.)
주기성: 모든 프로세스는 정해진 주기로 반복되어야 합니다.
독립성: 프로세스끼리 서로 데이터를 주고받거나 기다리지 않아야 합니다. (동기화 없음)
마감시간: 각 프로세스의 마감시간(Deadline)은 그 프로세스의 주기(Period)와 같습니다. (즉, 다음 주기가 시작되기 전까지만 끝내면 됨)
문제 1
평균 사용률(Average Utilization)이 1(100%)을 넘으면 어떻게 되는가?"
정답: 시스템은 작동하지 않습니다 (The system will not work).
해설:
사용률이 1을 넘는다는 것은 "해야 할 일이 처리할 수 있는 능력보다 많다"는 뜻입니다.
예를 들어, 알바생은 1시간에 그릇을 10개 닦을 수 있는데(능력), 손님이 1시간에 그릇 12개씩(일) 내놓는 상황입니다.
시간이 지날수록 닦지 못한 그릇(처리 못한 작업)이 무한히 쌓이게 되고, 결국 시스템은 멈추거나 붕괴합니다.
문제 2
"평균 사용률은 1(100%) 미만인데, '최대 사용률(Maximum Utilization)'이 1을 넘으면 어떻게 되는가?"
정답: 시스템이 될 때도 있고, 안 될 때도 있습니다 (System will work some of the time, but not always).
해설:
평균적으로는 감당할 수 있지만, 일이 한꺼번에 몰리는 '피크 타임(Peak Time)'에는 감당을 못 한다는 뜻입니다.
