EX1

WAW: stall at memory stage"
라고 필기하신 게 바로 이 뜻입니다. "다른 건 다 하게 내버려 두고, 메모리 단계로 넘어가기 직전 문 앞에서 대기시킨다!"
표(Timeline): EX 끝내고 MEM 가기 직전에 stall 3칸
이론(Concept): 나중에 온 놈이 먼저 쓰기(WB)를 해버리는 순서 역전(WAW)을 막기 위해
WAW (Write After Write) Hazard 성립조건
-> "반드시 같은 레지스터(Same Destination Register)에 값을 써야 한다!"
그래서 SUB, LD는 각자 F1, F2 다른값에 쓰므로 WAW 가 아니다
ADDD, LD가 WAW 후보가 될 수 있는데, cc8 에 끝나고, cc10에 순차적으로 끝나므로 WAW가 아니다
부동소수점 파이프라인(FP Pipeline)에서는 실행 시간이 제각각이라, 데이터 해저드(WAW)를 피하려고 스케줄을 조정하다가 쓰기 포트 충돌(Structural Hazard)이라는 또 다른 폭탄을 터뜨릴 수 있다!"
Write Port Structural Hazards In FP MIPS Pipeline
HW 3

DataMemory 는 예외적으로 latency 와 cycle이 동일하다
1. Use the following code fragment:
Loop:
L.D F0, 0(R2)
L.D F4, 0(R3)
MUL.D F0, F0, F4
ADD.D F2, F0, F2
DADDUI R2, R2, #8
DADDUI R3, R3, #8
DSUBU R5, R4, R2
BNEZ R5, LoopD (소수점) 공식: 명령어 끝에 점(.)과 함께 D**가 붙으면
Double-precision Floating Point (소수점 연산)
아래는 그냥 정수 연산
DADDUI: Doubleword ADD Unsigned Immediate (64비트 정수에 '상수'를 더해라!)
DSUBU: Doubleword SUBtract Unsigned (64비트 정수끼리 빼라!)
DADDU: Doubleword ADD Unsigned (64비트 정수끼리 더해라!)
F2랑 R2랑 다른 레지스터임!!!!Assume that the initial value of R4 is R2+792.
For this exercise assume the standard five-stage integer pipeline and the MIPS FP pipeline as described in Section C.5. If structural hazards are due to write back contention, assume the earliest instruction gets priority and other instructions are stalled.
(여러 명령어가 동시에 계산을 끝내고 레지스터에 값을 쓰려고 충돌할 때, 무조건 먼저 출발한(오래된) 형님 명령어한테 먼저 쓰게 해주고, 나중에 출발한 동생 명령어는 한 사이클 기다려라)
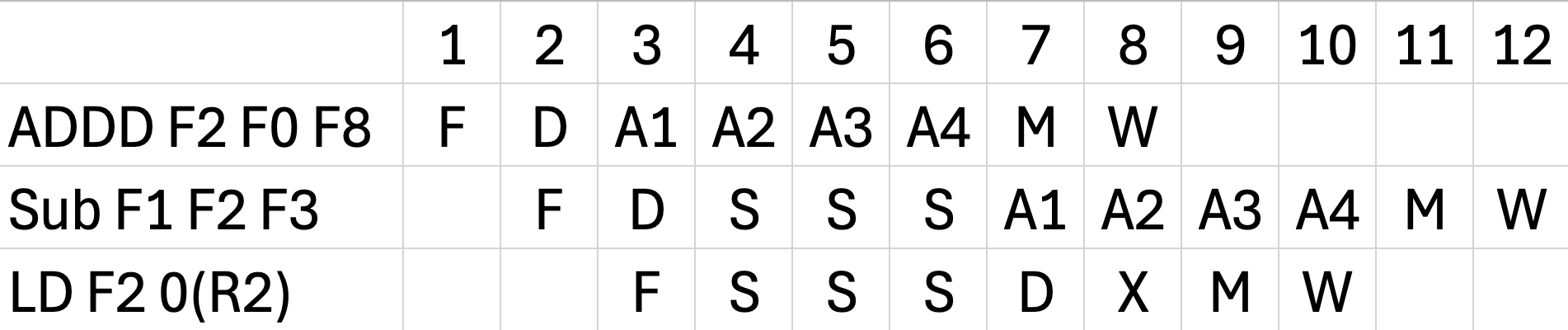
a. without forwarding, Flush
Show the timing of this instruction sequence for the MIPS FP pipeline without any forwarding or bypassing hardware but assuming a register read and write in the same clock cycle “forwards” through the register file. Assume that the branch is handled by flushing the pipeline. If all memory references hit in the cache, how many cycles does this loop take to execute? (35 points)

R2 8 = 792
99 cycle
23 98 + 25 = 2279
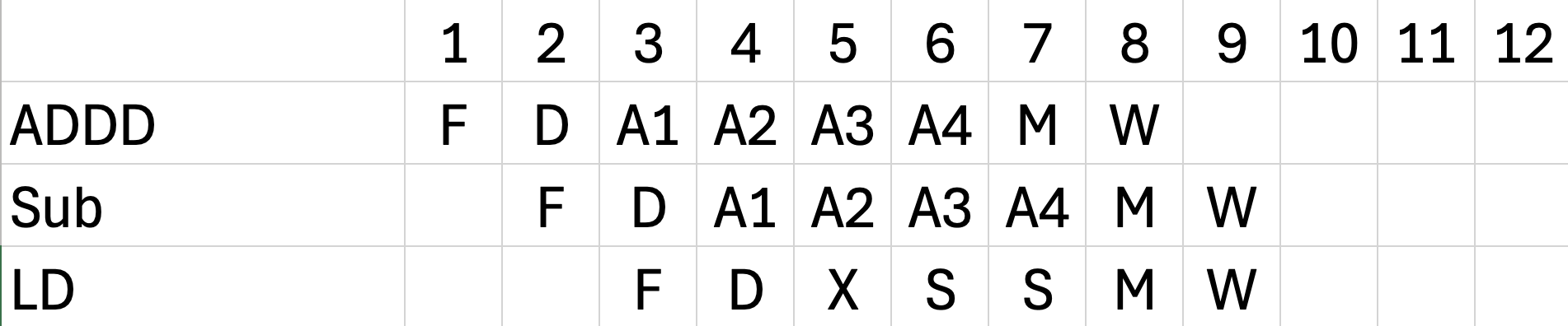
b. forwarding, predict not taken
Show the timing of this instruction sequence for the MIPS FP pipeline with normalforwarding and bypassing hardware. Assume that the branch is handled by predicting it as not taken. If all memory references hit in the cache, how many cycles does this loop take to execute? (35 points)

Predict Not Taken (하드웨어의 예측):
CPU는 분기문을 만나면 "음, 왠지 조건이 안 맞아서 안 뛸 것 같은데?
일단 그냥 밑에 있는 코드 계속 가져와봐!"라고 추측합니다.
그래서 BNEZ 바로 다음 줄에 있는 쓸데없는
명령어들(Inst. j, Inst. j+1)을 파이프라인에 계속 밀어 넣습니다(Fetch).
Actual Outcome is TAKEN (실제 상황):
하지만 코드를 잘 보세요. 맨 끝이 BNEZ R5, Loop입니다.
전형적인 반복문(Loop)이죠? 반복문을 도는 동안에는 당연히 R5가 0이 아니므로,
루프 맨 위(L.D F0...)로 무조건 뛰어야(Jump/Taken) 합니다!18 * 98 + 20 = 1784
2. Given a code sequence
1. LW R1, 50(R2)
2. ADD R3, R1, R4
3. LW R5, 100(R3)
4. MUL R6, R5, R7
5. SW R6, 50(R2)
6. ADD R1, R1, #100
7. SUB R2, R2, #8Find all dependencies in the code segment and list them by category (data dependence,
output dependence, anti-dependence and control dependencies) (30 points)
Answer
Data dependece (RAW)
find Write -> read
- 2 on 1 for R1
- 3 on 2 for R3
- 4 on 3 for R5
- 6 on 1 for R1
- 5 on 4 for R6 // R6 (4:Write, 5:Read)
output dependence (WAW)
find write -> write
- 6 on 1 for R1
anti-dependence (WAR)
find Read -> write
- 7 on 1 for R2
- 6 on 2 for R1
- 7 on 5 for R2
control dependence
- None
-
Data dependece: 첫번째 레지스터가 아래의 두번째 or 세번째 레지스터와 같은것 // Store는 읽는거다
-
output dependence: 첫번째 레지스터끼리 같은거, store는 해당안됨
-
Anti dependence: 위의 두번째 or 세번째 레지스터가 아래의 첫번째랑 같은거, 순서 반대로는 안됨
HW4
- 스코어보딩은 WAW안되고 issue 하려면 앞선 동작이 끝나야 한다.토마슬로 처럼 덮어쓰기 안됨
- data dependence있을때 앞선 동작이 끝나야 read operands 할 수 있다
Show scheduling of the following code:
L.D F2, 0(R2)
L.D F4, 100(R3)
ADD.D F8, F2, F2
MUL.D F6, F4, F8
SUB.D F6, F2, F4Using scoreboard. Assume one integer ALU, two FP multipliers, one FP adder and one FP
divider. Integer ALU takes one execution cycle, FP multipliers take 7 cycles, FP adder takes 4
cycles and FP divider takes 25 cycles.
Example: Register Renaming
왜 Register Renaming이 필요한가?
-
RAW (Read-After-Write) is a True Data Dependence:
뒷 명령어가 앞 명령어의 '실제 계산 결과값(Data)'을 반드시 필요로 하는 진짜 의존성입니다. 데이터 자체가 완성되어야만 다음 연산을 진행할 수 있으므로, 레지스터 이름을 바꾼다고 해서 이 의존성이 사라지지는 않습니다. -
WAW (Output dependence) & WAR (Anti-dependence) are NOT True Data Dependences:
이 두 가지는 명령어들 사이에 데이터를 주고받는 관계가 아닙니다. 단지 프로세서가 가진 레지스터의 개수(Architectural Registers)가 한정되어 있다 보니, 우연히 '같은 레지스터 이름(Name)'을 재사용하면서 발생하는 가짜 충돌(Name Dependence)입니다. -
결론: WAW와 WAR는 진짜 데이터 의존성이 아니므로, 목적지 레지스터에 덮어쓰기가 발생할 때 내부적으로 완전히 새로운 임시 레지스터(Physical Register)를 할당(Renaming)해 주면 충돌을 원천적으로 제거할 수 있습니다.
1. L.D F4, 0(R2)
2. MUL.D F4, F4, F2
3. ADD.D F2, F6, F8
4. DIV.D F10, F8, F4
5. ADD.D F10, F2, F12(a) Identify all RAW, WAW and WAR hazards.
RAW: 1→ 2, 2→ 4, 3→5
WAW: 1→ 2, and 4→5
WAR: 2→3
(b) Apply renaming to resolve WAW and WAR
hazards and list the new MIPS code.
1. L.D F4, 0(R2)
2. MUL.D S, F4, F2
3. ADD.D T, F6, F8
4. DIV.D F10, F8, S
5. ADD.D U, T, F12목적지 이름이 바뀌었으므로 그 값을 가져다 쓰는(Read) 뒷 명령어들의 소스 레지스터(Source Register) 이름도 세트로 함께 바꿔주어야 RAW 의존성이 올바르게 유지됩니다.
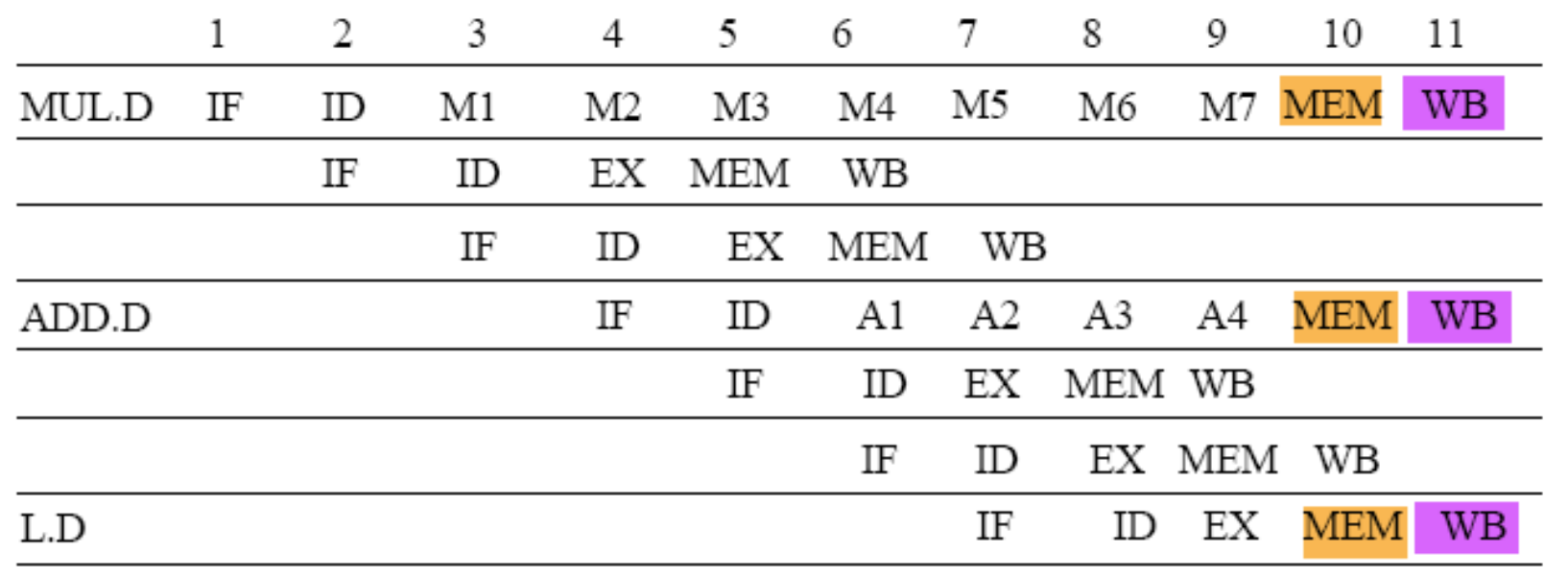
HW 5
write result 가 작성된 time에서 바로 다른 명령어를 execute 할 수 없다,
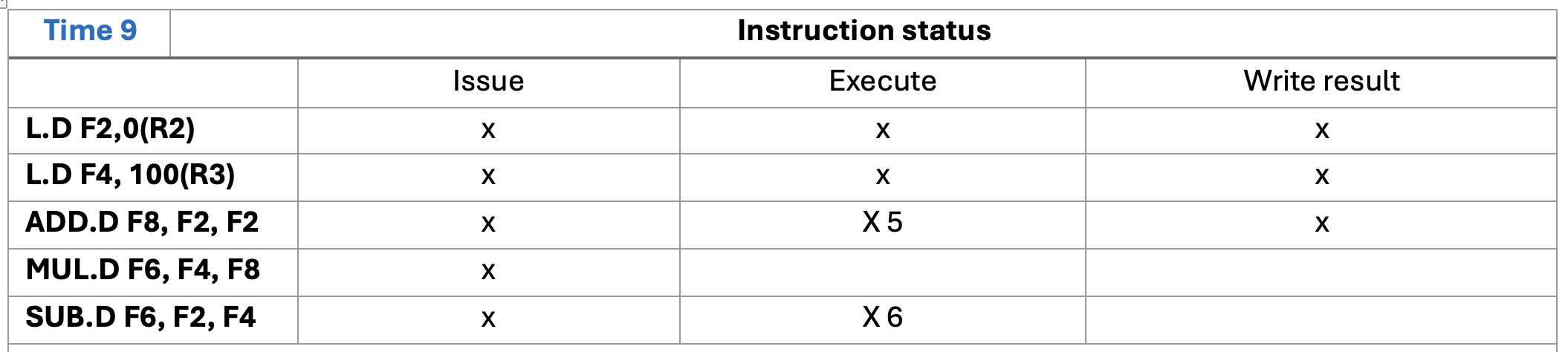
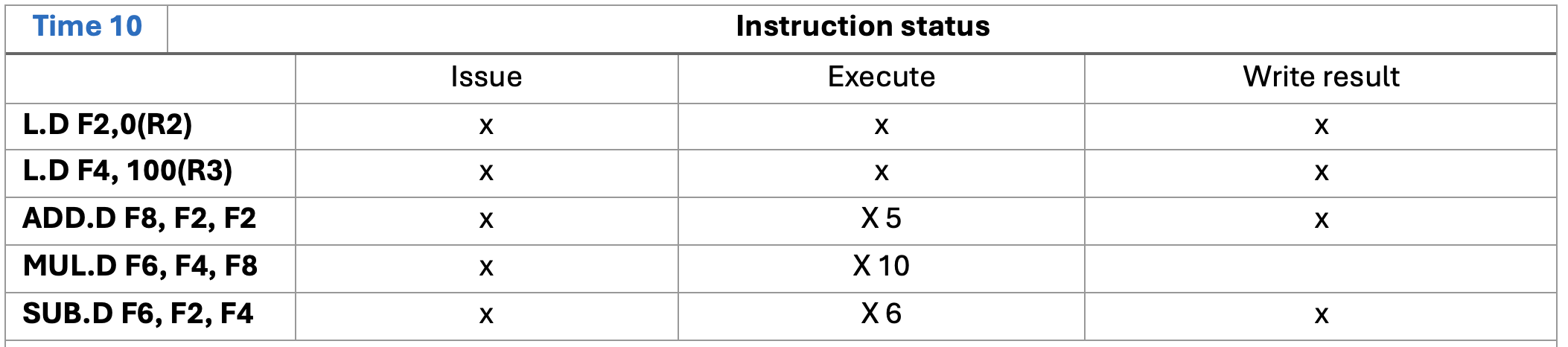
- time 9에서 ADD 가 write result 하고나서 이제 Mult에서 F8을 쓸 수 있는데, 그건 time 10에서 excute가능하다. time9에서 바로 못함
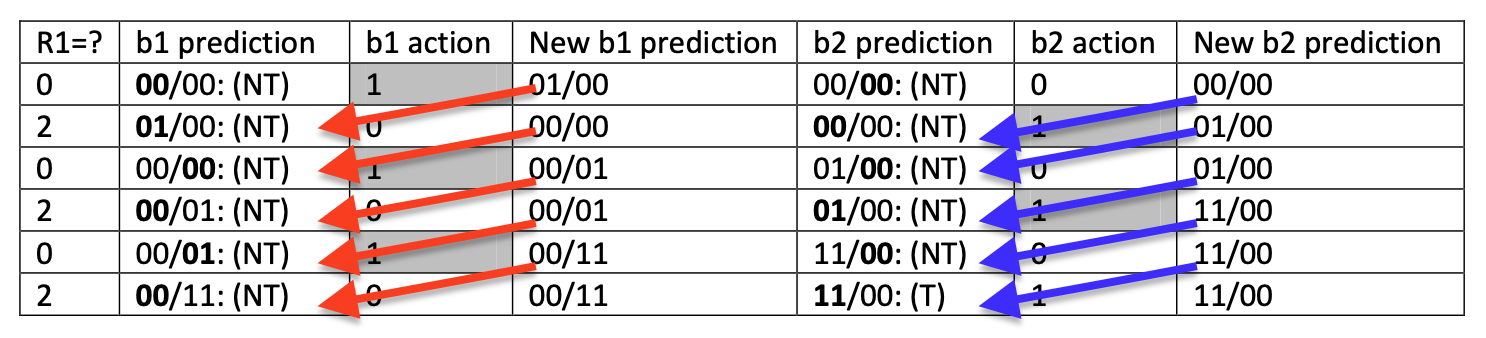
For the following code use (1,2) branch predictor to predict branch outcome for b1 and b2. This means that you will be using a correlating predictor that depends on the outcome of 1 previous branch and this predictor will have 2 bits. Also assume that the values of R1 at the entry point of the code are 0, 2, 0, 2, 0, 2 etc. Show the values for both b1 and b2 predictors and note how many misses you have. You may draw a table (similar to Lec.24-slide 6) to show the values. Assume that start values are 00/00.

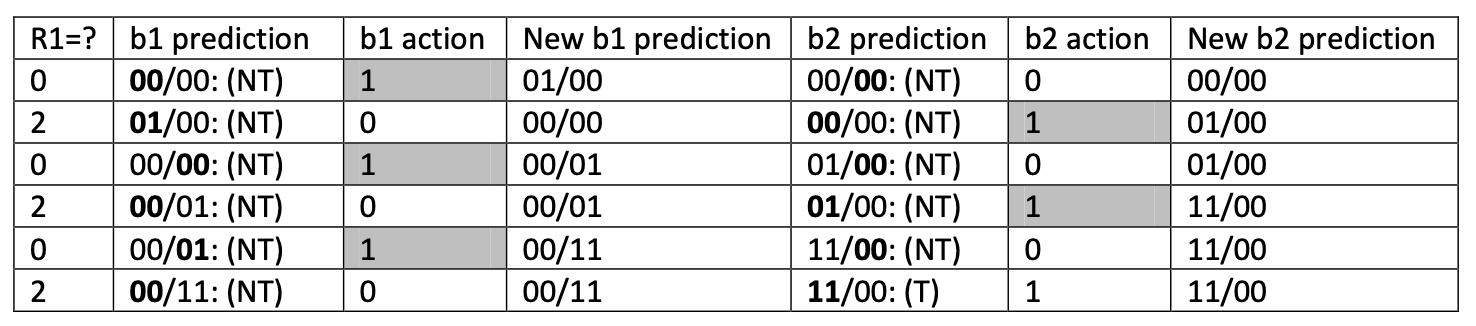
-
이전 action이 NT면 왼쪽을 바라보고
-
이전 action이 T면 오른쪽을 바라본다.
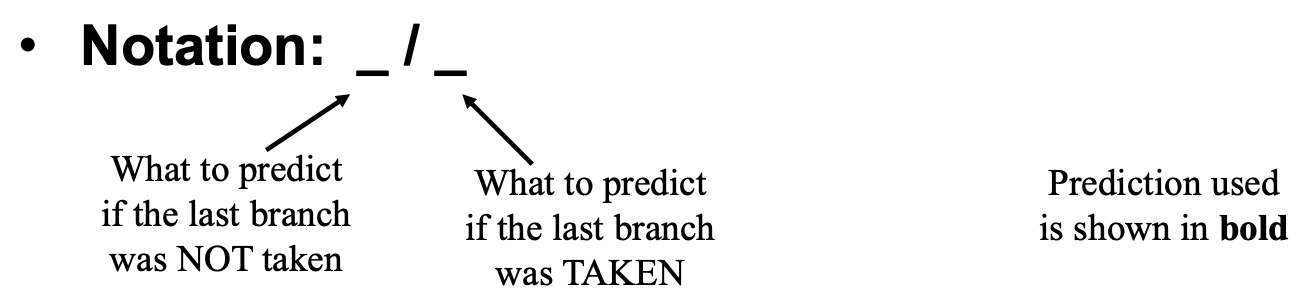
-
b1, b2는 이전 action이 NT, T였는지만 참고하고 자신이 어디를 바라볼지를 확인하며 그 이외에는 전혀 상관없다
-
이전 new predecion이 다음 prediction 값이다.
-
prediction은 이전 값을 가져오는거지 진짜 prediction이 아니다