Computer Architecture
1.ISA

명령어 집합(instruction set, instruction set architecture/ISA)은 소프트웨어와 하드웨어, 특히 CPU와의 사이의 약속이다. ISA는 여러 명령어들을 정의하며 또한 현재 시스템의 상태가 어떻게 구성되어 있고 명령어를 실행할 때 그
2.The Pipeline Hazard

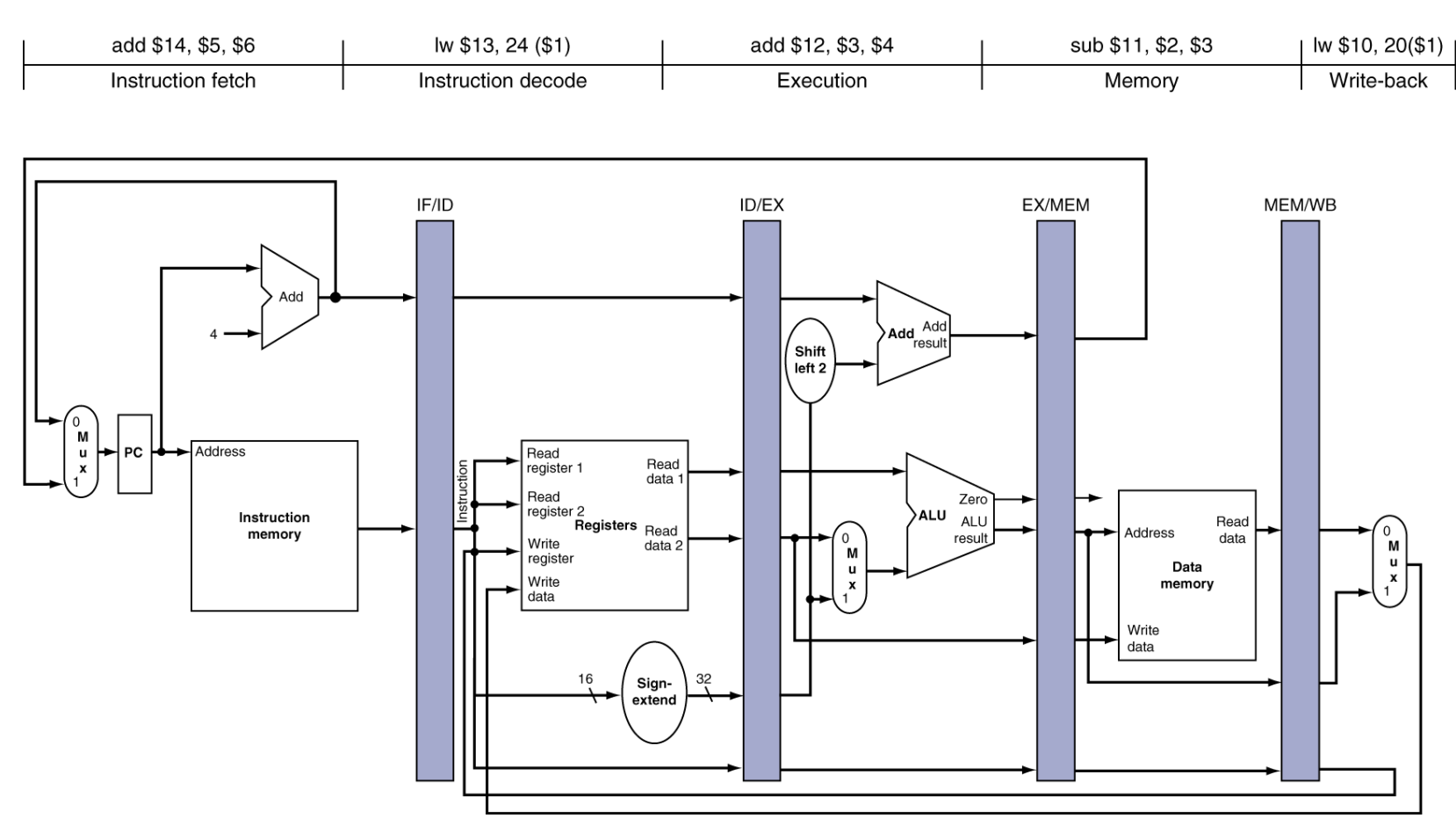
교수님이 "파이프라이닝이 뭐냐?"고 물으시면명령어 실행 과정을 독립적인 단계로 나누어 자원을 병렬로 활용하는 기법입니다.각 단계 사이에 파이프라인 레지스터를 두어 데이터를 임시 저장하고 흐름을 제어합니다.목표는 Throughput을 최대화하여 CPI를 1에 가깝게 만드
3.Memory Hierarchy and Cache
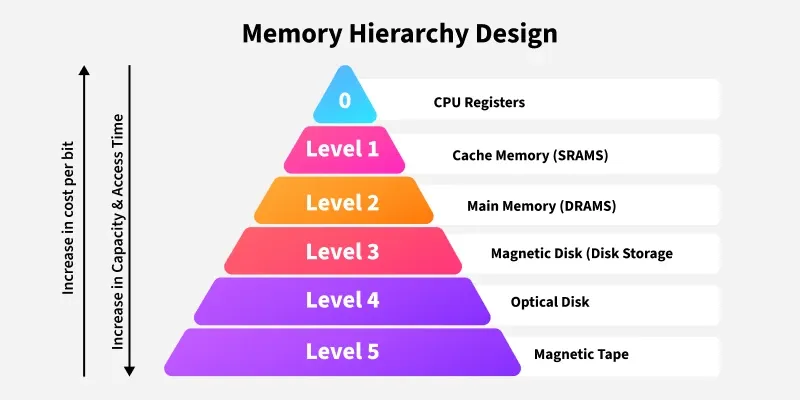
아무리 CPU를 Tomasulo 알고리즘으로 화려하게 설계해도, 데이터를 담고 있는 메모리가 느리면 CPU는 멍하니 기다려야 합니다. 이를 'Memory Wall' 문제라고 부릅니다. 이 벽을 깨기 위한 하드웨어의 노력을 파헤쳐 봅시다.캐시가 존재하는 근본적인 이유입니
4.Parallelism, Power and Energy, Flynn's Taxonomy
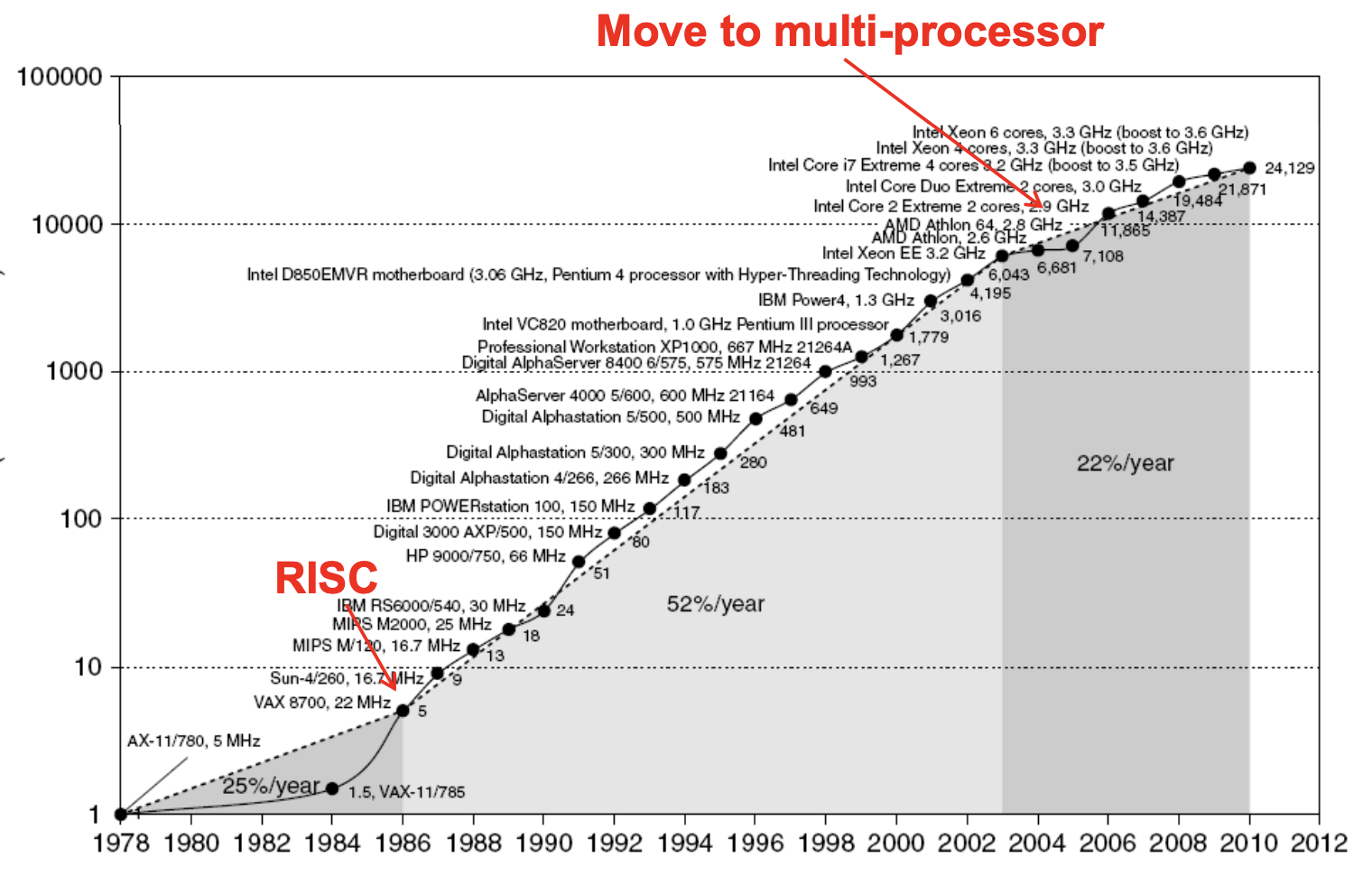
Moore's Law무엇이 성능을 기하급수적으로 늘렸나risc for pipelinecache ILP: Instruction Level parallelismpower density: 기하급수적으로 상승, 칩 집적도가 높아지면cpu Frequency 를 낫춰야한다 TLP
5.Reducing power, Cost of IC

1.Reducing Power A. Do nothing well 아무것도 안 할 거면, 확실하게 꺼라 놀고 있는 하드웨어는 전기를 0으로 먹게 만들어라 기술적 구현: Clock Gating 디지털 회로는 클럭 신호가 들어올때마다 전기를 사용 만약 ALU가 아무
6.Dependability, Performance

1. Dependability(신뢰성/의존성) 1. Dependability의 핵심 개념 Dependability는 "사용자가 시스템을 믿고 의존할 수 있는 능력"을 말합니다. 단순히 "고장이 안 난다"를 넘어서, 고장이 나더라도 얼마나 빨리 복구하느냐까지 포함하는 포
7.Amdahl's Law, MIPS Arch
"전체 시스템 중 일부만 빠르게 개선한다고 해서, 전체 속도가 그만큼 빨라지는 것은 아니다. 개선하지 못한 부분(Serial Part)이 결국 발목을 잡는다."$f$ (Fraction): 전체 작업 중 속도를 높일 수 있는 부분의 비율 (예: 40% = 0.4)$n$
8.Comp Arch HW1

textbook 90p
9.Addressign Modes
1\. Register: operand is in register– Add R4, R3– Second operand’s value = RegsR3ALU2\. Immediate: operand is constant– Add R4, – Second operand’s val
10.Structure Hazard, Data Hazard
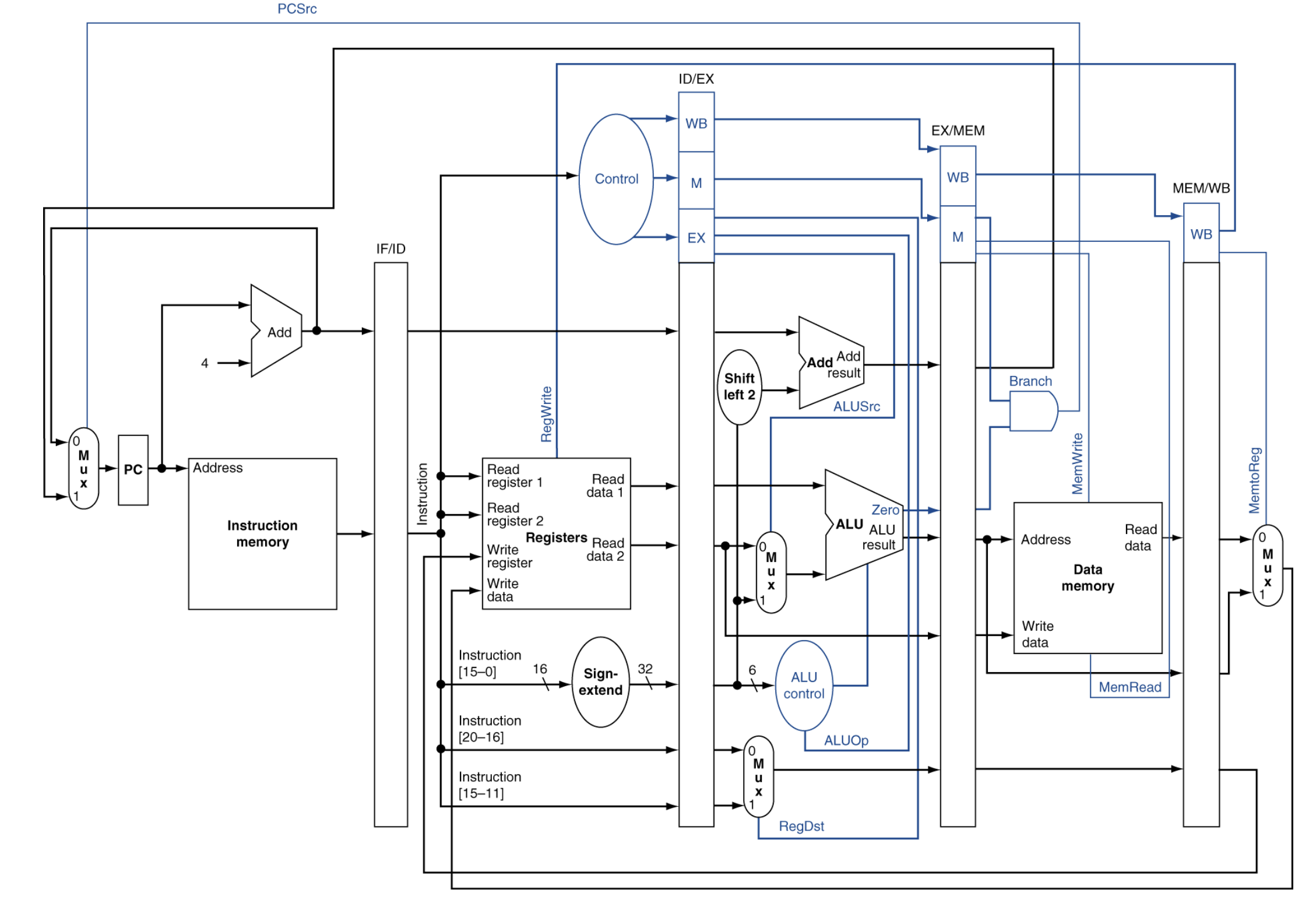
control signal: Bluedata path: Black파이프라인의 궁극적인 목표는"매 클럭마다 명령어 1개씩을 끝마치는 것(Ideal CPI = 1)"입니다.수식 분석:$$CPI = \\frac{\\text{IC} + \\text{Pipeline fill-u
11. Forwarding (Bypassing)
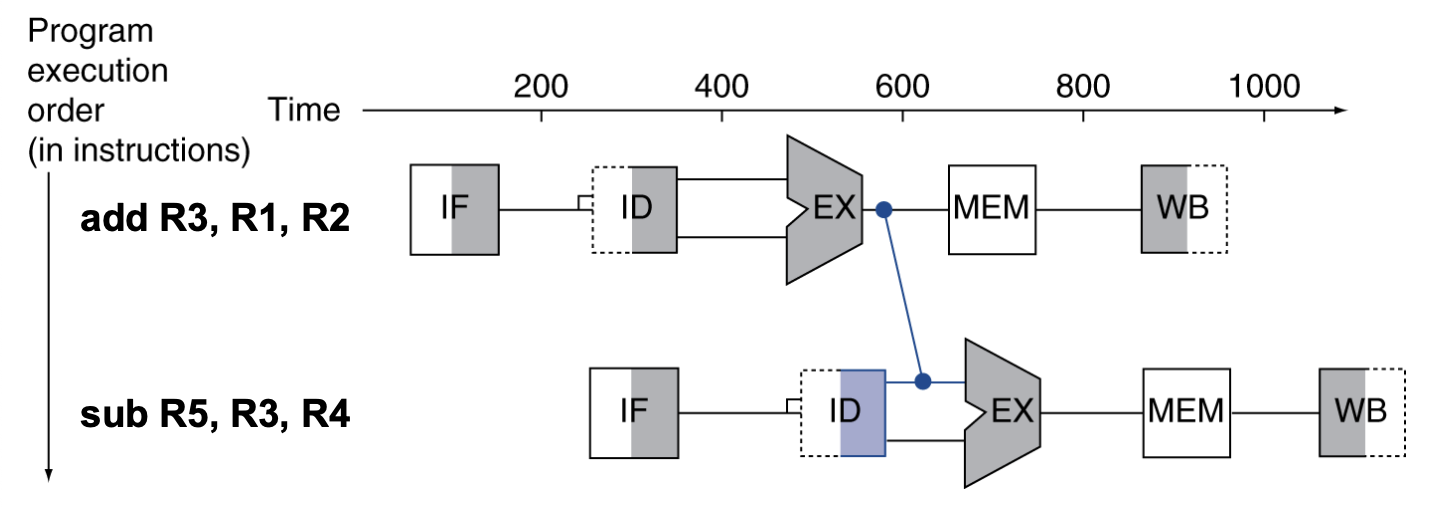
sub instruction able o select, we don rly care what is input Alusub inst need to stor incode anymoreDon’t wait for it to be stored in a registerRequir
12.Code Reordering, Control Hazard

앞서 우리가 BNEZ (Branch if Not Equal to Zero) 명령어를 풀면서 겪었던 '점프 페널티'나 '플러시(Flush)'의 근본적인 원인이 바로 이 녀석입니다"If the branch is taken (condition is true) next ins
13.Static Techniques to Reduce Branch Penalties
Control Hazards 근본적인 문제: 분기문(Branch)의 딜레마 파이프라인은 명령어를 쉬지 않고 연속해서 가져와야(Fetch) 속도가 빠릅니다. 그런데 if문 같은 분기명령어(Branch)를 만나면 다음 두 가지를 알아내기 전까지는 다음 명령어를 제대로 가져올 수 없습니다. Target Address (목적지 주소): 그래서 어디로 점프할 건데...
14.Delayed Branches
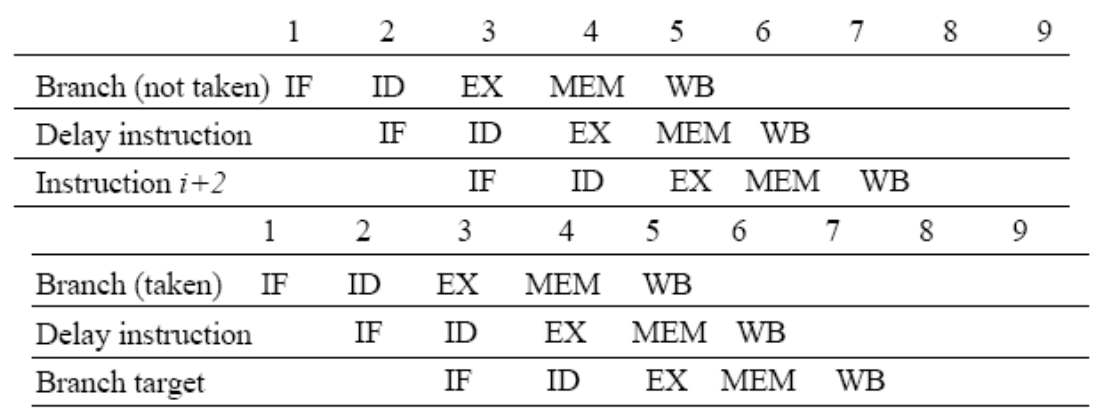
Compiler reorders instructions so that the nextinstruction after the branch is:– Useful in most cases– Harmless both in taken and not taken case– Disa
15.Comp Arch HW2
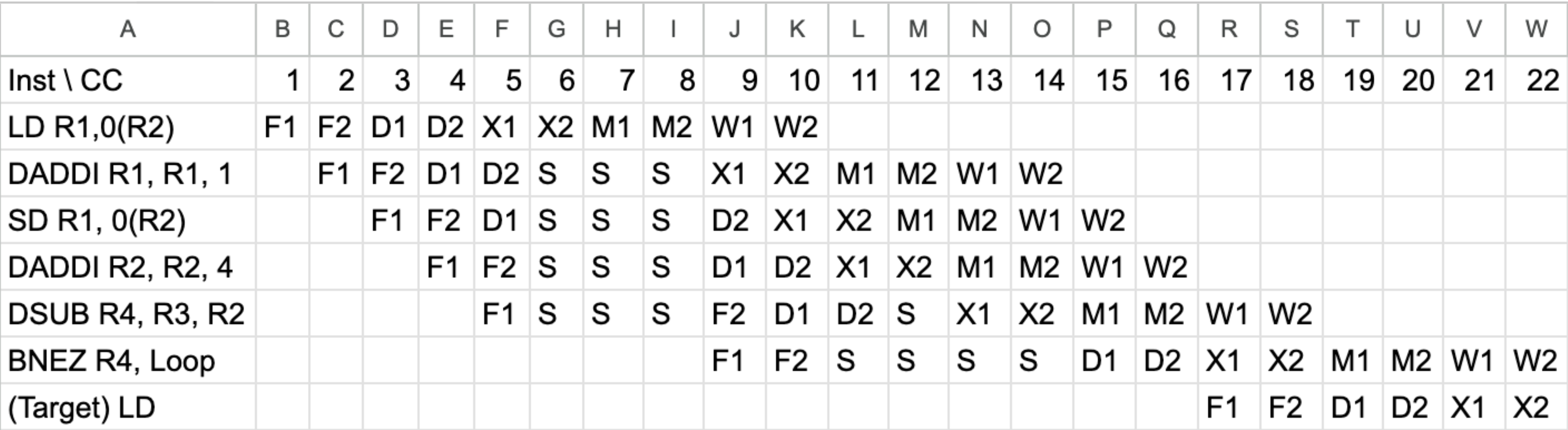
p726 1. (C.1) 달리기 경주 비유 R3 (도착선): 초기값이 R2 + 396입니다. 즉, 출발선보다 396만큼 앞에 그어진 '도착선'이며
16.Extending MIPS for FP Pipeling
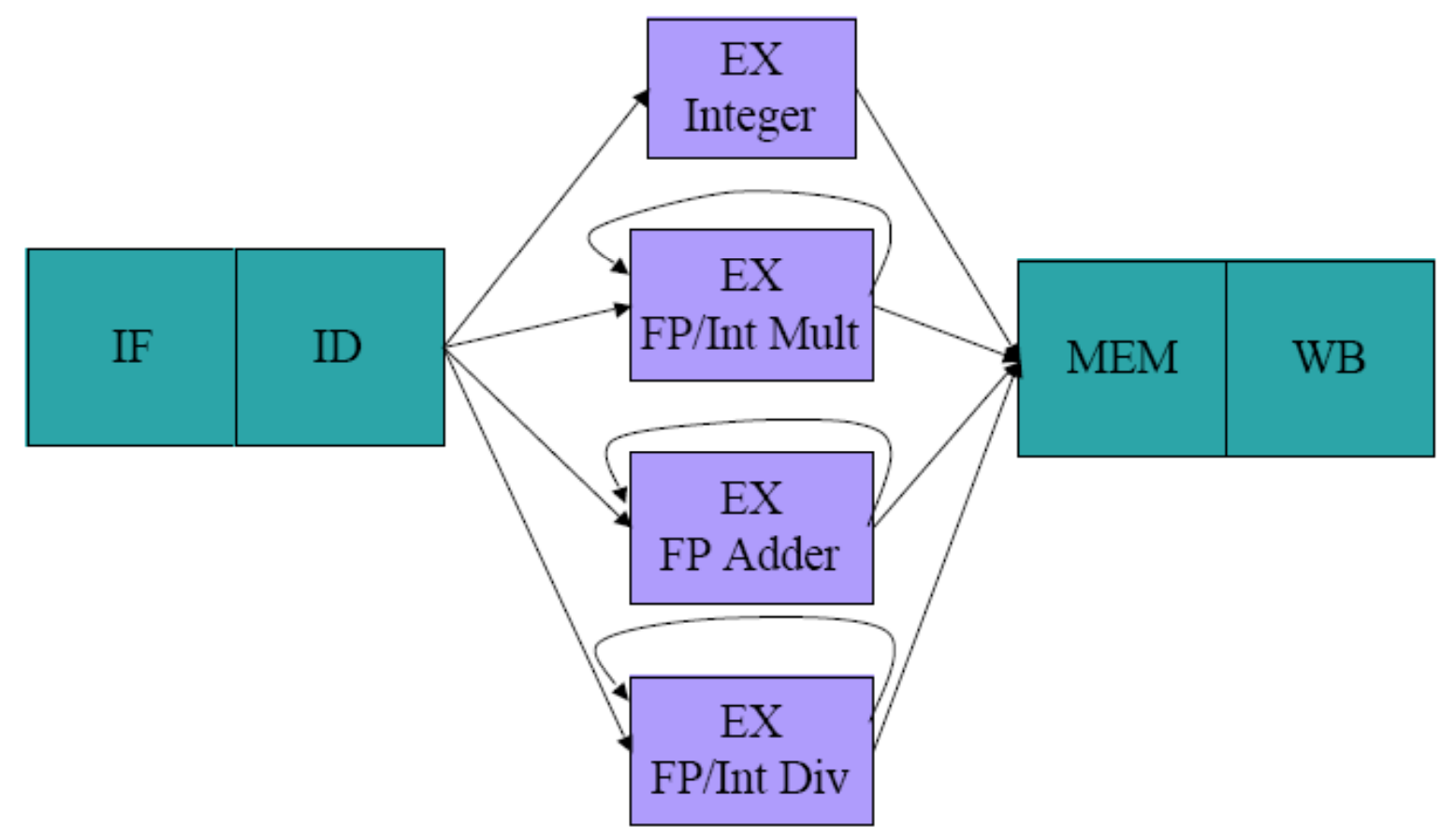
FP operations are long and cannot be completed in 5 cycles (EX lasts more than 1 cycle)• Simply imagine that EX stage is duplicated for FP기존 정수 연산(덧셈
17.Port structure hazard
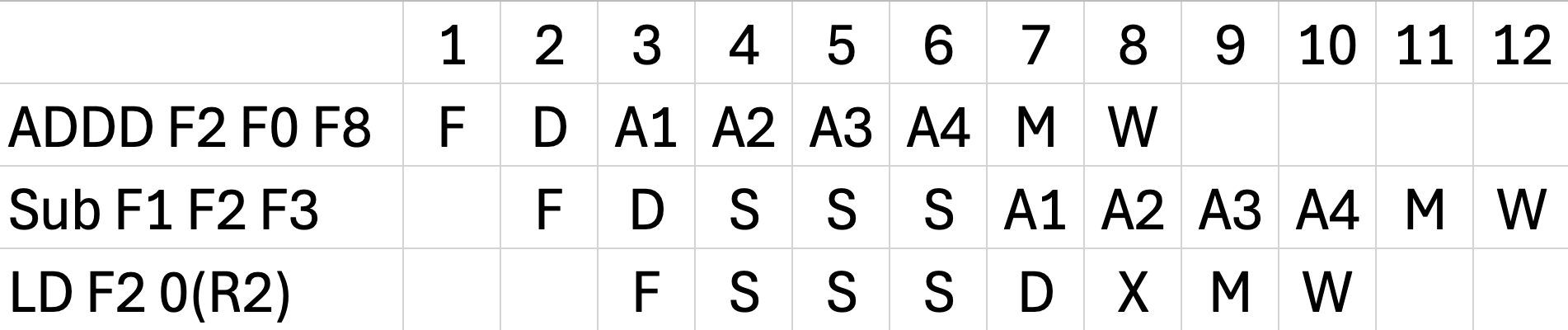
WAW (Write After Write) Hazard 성립조건 \-> "반드시 같은 레지스터(Same Destination Register)에 값을 써야 한다!"그래서 SUB, LD는 각자 F1, F2 다른값에 쓰므로 WAW 가 아니다ADDD, LD가 WAW 후보가
18.Dependence

프로그램을 짤 때 명령어들 사이에 어쩔 수 없이 생기는 끈끈한 관계입니다. 이 관계 때문에 함부로 순서를 바꾸거나 동시에 실행할 수 없습니다.의미: 앞 명령어가 만든 진짜 데이터(Real data)가 뒷 명령어에게 필수적인 상황.유발 해저드: RAW (Read Afte
19.이해 안됬던거 모음

명령어: LD F0, 0(R2)진짜 의미: "R2에 있는 값과 0을 더해서 메모리 주소(Address)를 구한 다음, 그 주소의 메모리(RAM)로 직접 찾아가서, 그 안에 들어있는 '데이터'를 꺼내와서 F0 방에 넣어라!"즉, LD 명령어는 두 번의 작업을 거쳐야 합니
20.HW3, 4, 5

WAW: stall at memory stage"라고 필기하신 게 바로 이 뜻입니다. "다른 건 다 하게 내버려 두고, 메모리 단계로 넘어가기 직전 문 앞에서 대기시킨다!"표(Timeline): EX 끝내고 MEM 가기 직전에 stall 3칸이론(Concept): 나중
21.Dynamic Scheduling

Pipeline with Scoreboarding1\. Fetch2\. Issue stage: should check structure hazard, WAW3\. Read operands: should check RAW4\. Execute5\. Write results
22.Scoreboard Example
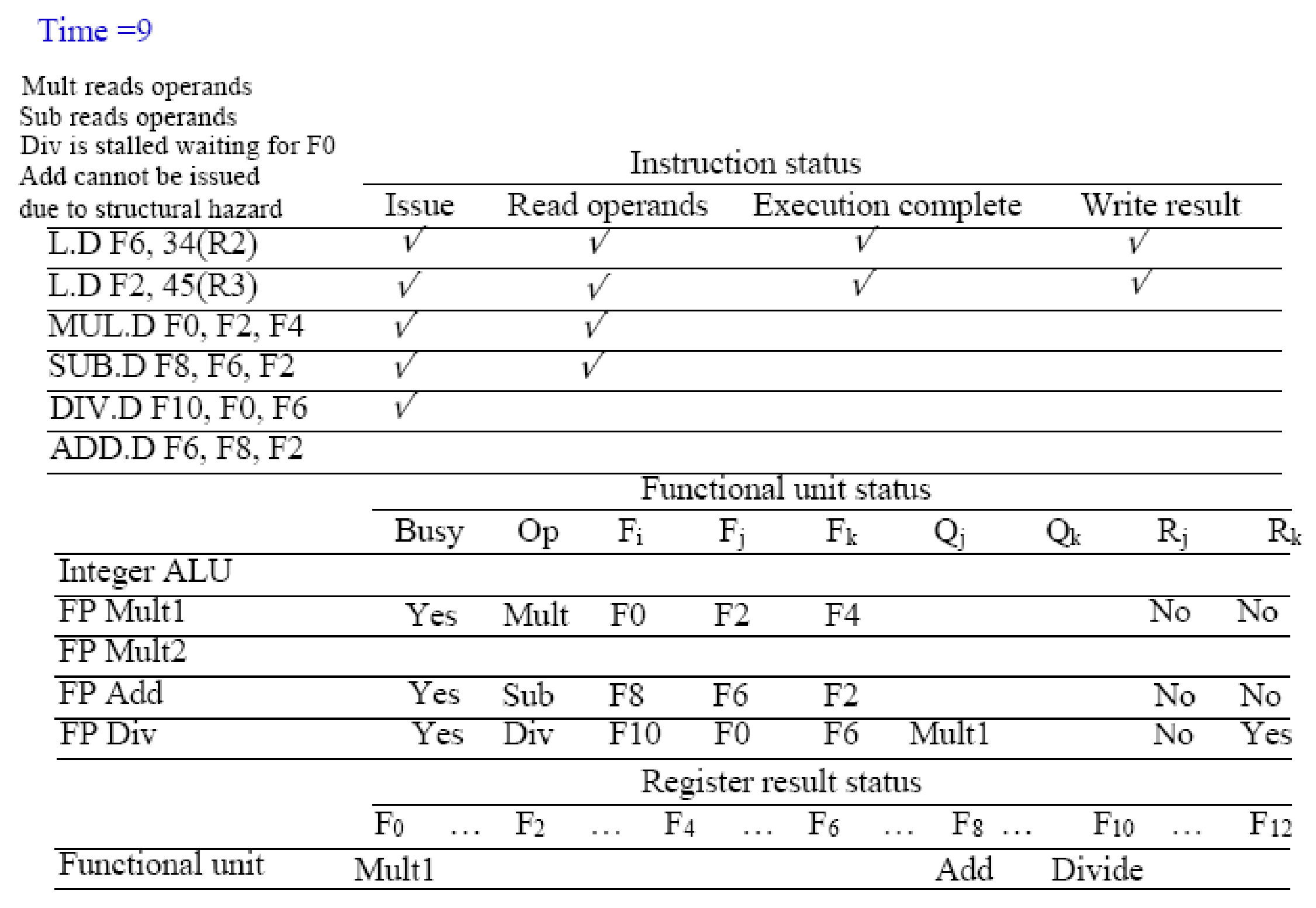
L.D F6, 34(R2)의미: R2 레지스터 값에 34를 더한 메모리 주소에서 데이터를 가져와(Load), F6 레지스터에 저장하라.스코어보드 업데이트 (Bookkeeping 적용):Instruction status (명령어 상태):L.D F6, 34(R2)의 Iss
23.Tomasulo’s Algorithm
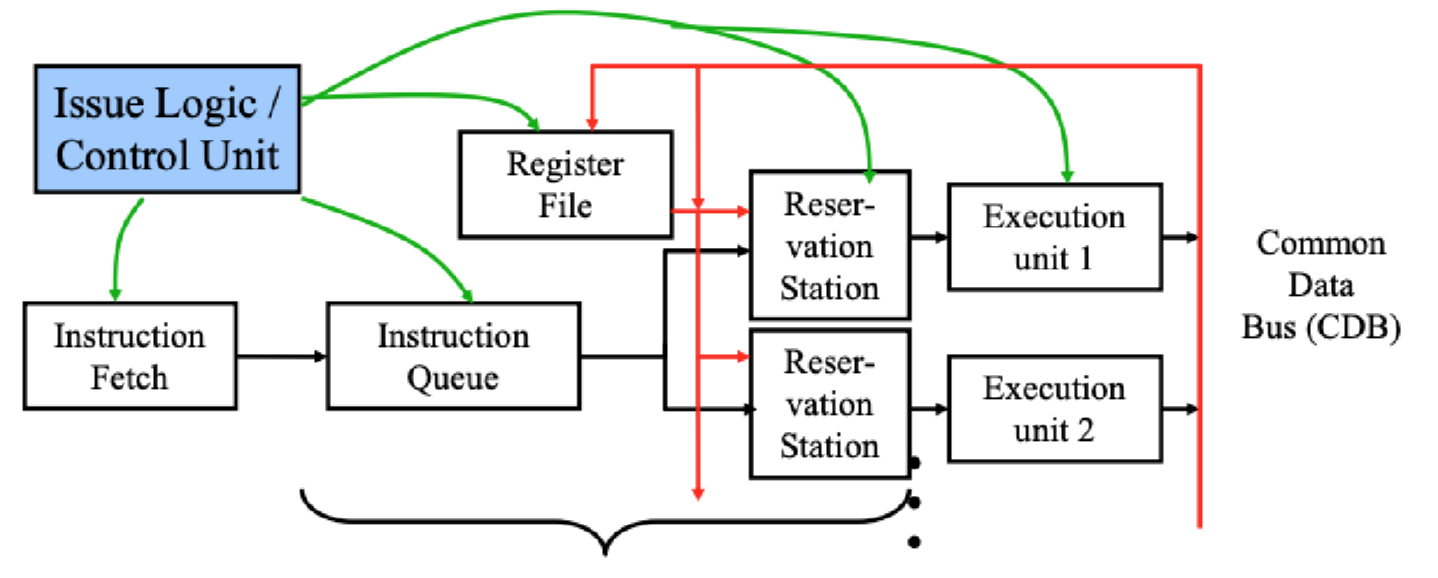
가장 중요한 차이점은 Dynamic Register Renaming(동적 레지스터 이름 변경)을 하드웨어 레벨에서 구현했다는 점입니다.Eliminates WAR & WAW hazards without stalling: 스코어보딩에서는 앞사람이 다 읽을 때까지, 혹은 다
24.Tomasulo Algorithm2

tomasulorwrite 부터 시작해라 -> issueissue 조건: reservation use or notload2 비어있으니 사용가능load has 2 step: it takes 2 cycleso begining of cycle 3 no datamul (Qj)
25.Dynamic Branch Prediction
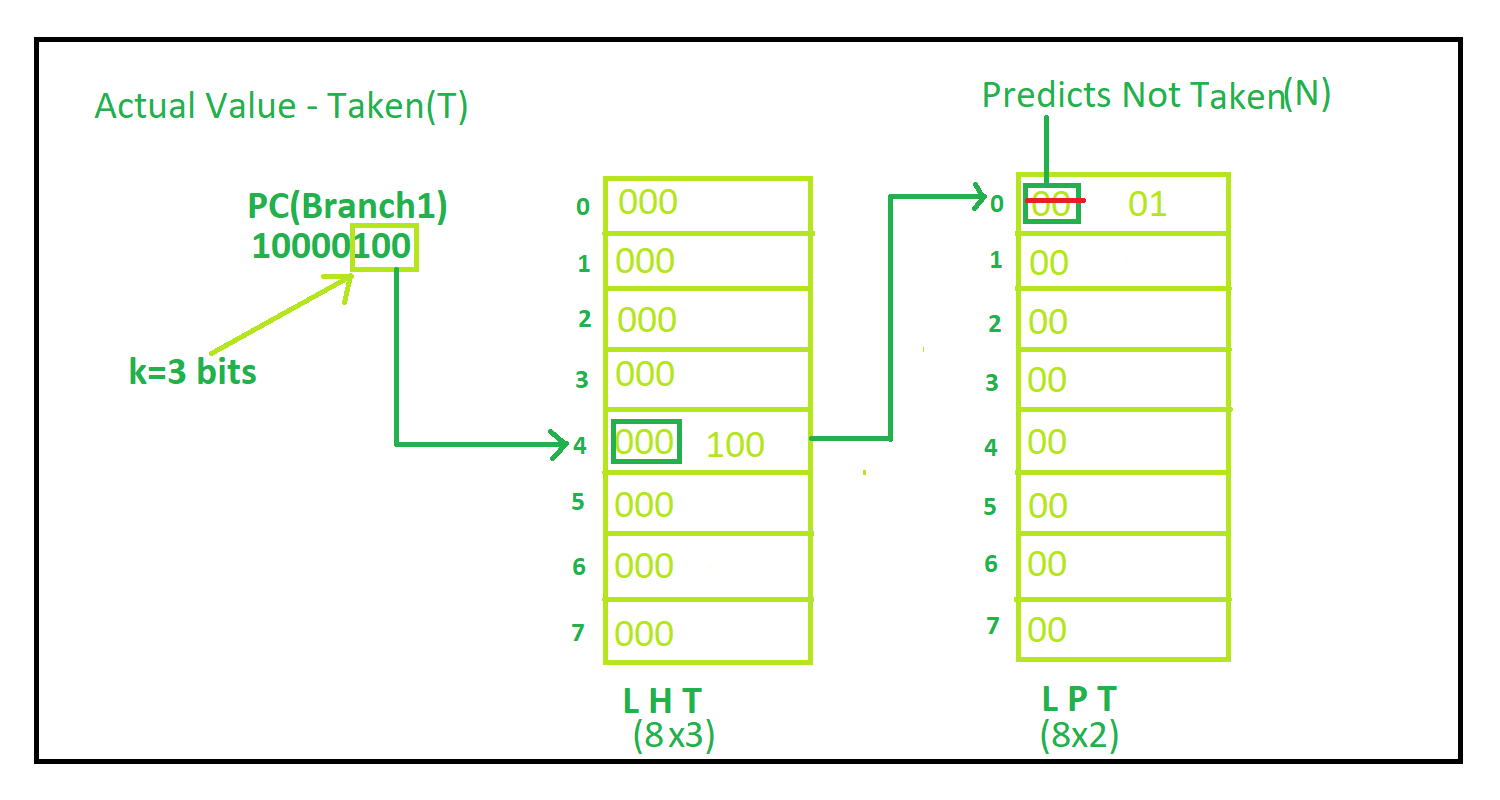
Local Branch prediction:use own historyGlobal Branch prediction:determined by other instructionuse someone else history(동적 분기 예측의 필요성)파이프라인이 왜 과거의 기록을
26. Correlated Prediction/ final --

핵심은 "서로 관련이 없어 보이는 앞선 두 개의 if문이, 세 번째 if문의 결과를 100% 결정지어 버린다"는 것을 증명하는 것입니다. 이것이 바로 주변 문맥을 파악하는 상관 예측(Correlated Prediction)의 존재 이유입니다.먼저 C 코드를 논리적으로
27.Tournament Predictors, Branch-Target Buffers (BTB)
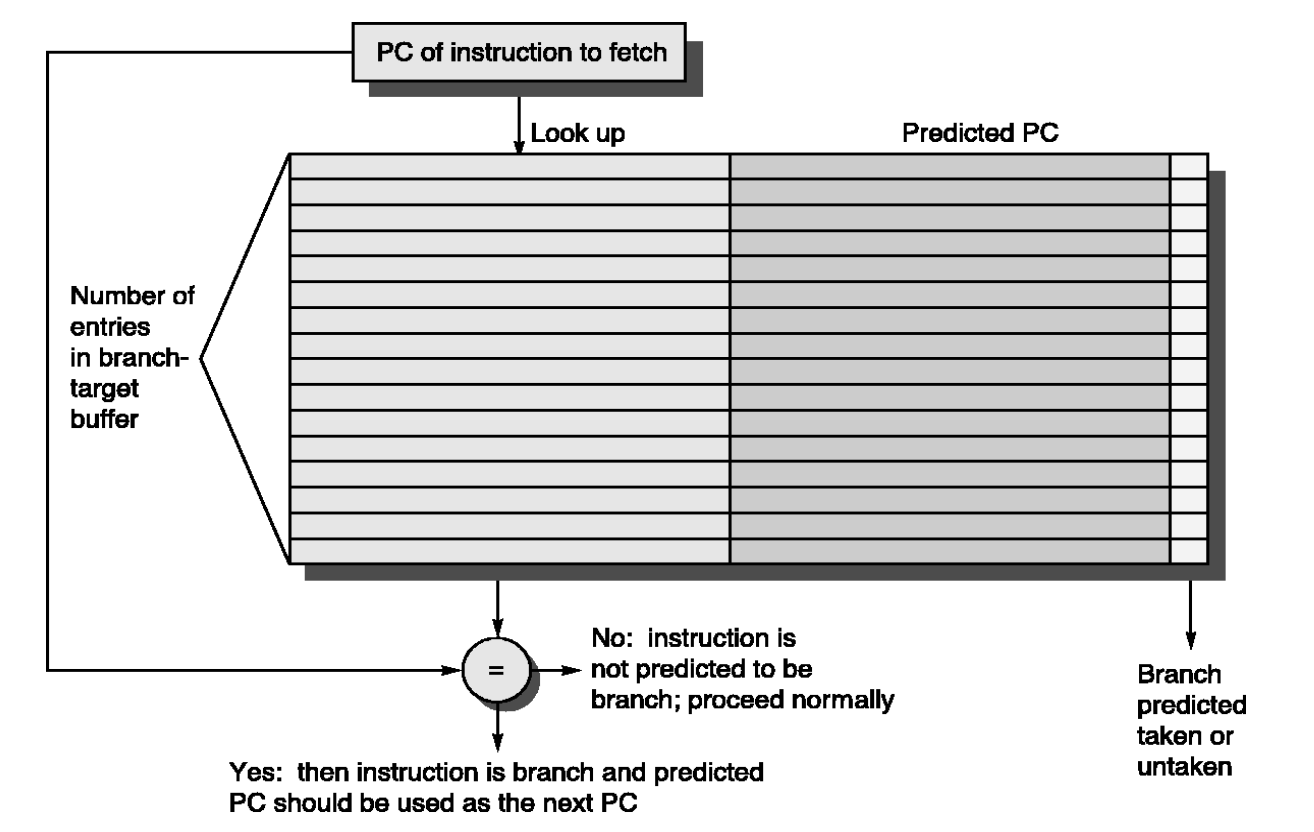
\*Tournament Predictor (토너먼트 예측기)는 말 그대로 칩 내부에서 두 개의 서로 다른 예측기를 경쟁시켜서, "지금 이 분기문에서는 누구 말을 듣는 게 더 정확할까?"를 하드웨어가 스스로 판단하고 선택하는 메타 예측기(Meta-Predictor)\*\
28.Hardware-based speculation
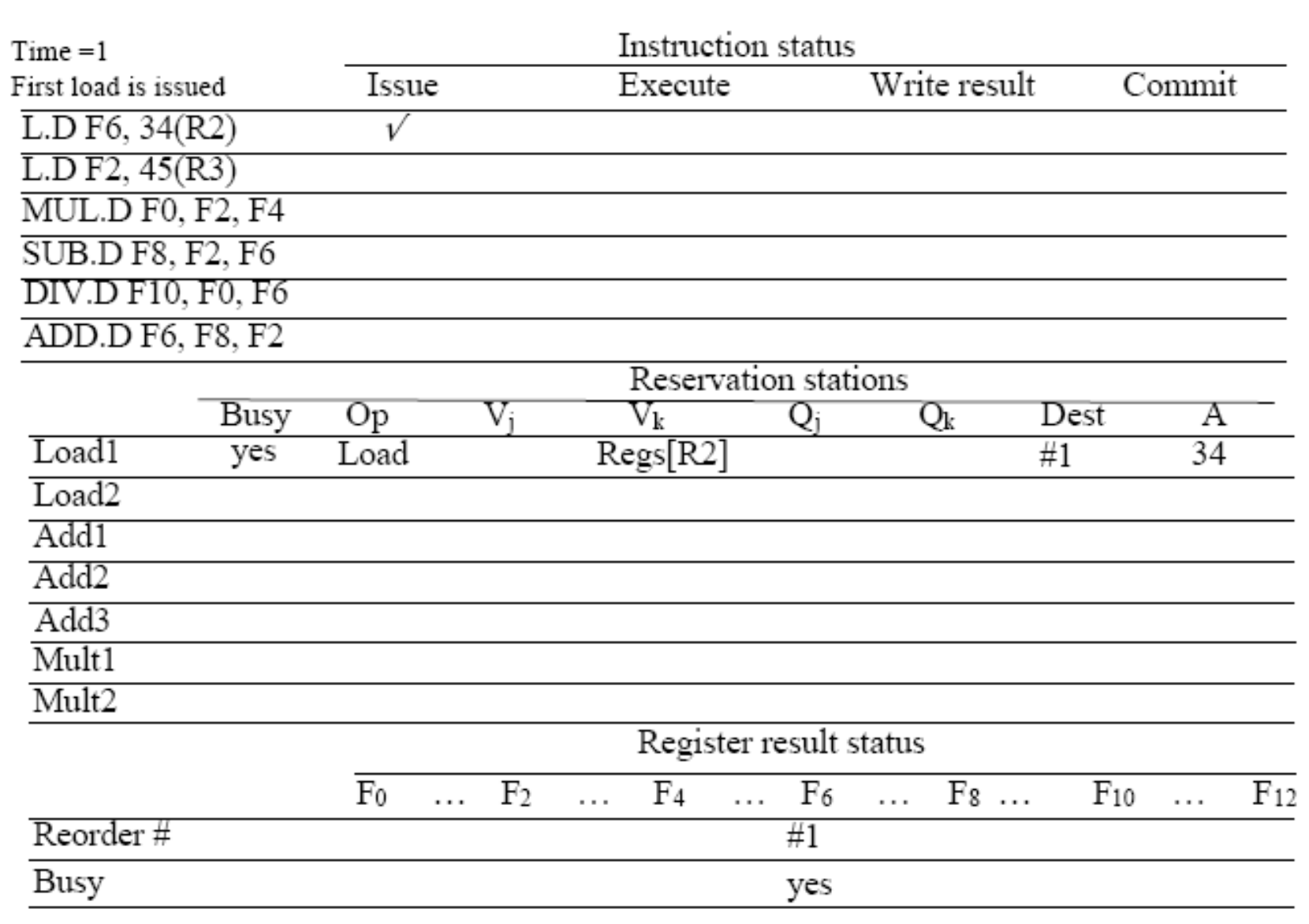
한 사이클에 명령어를 4개, 8개씩 빨아들이는(Fetch) 슈퍼스칼라 구조에서는 단순히 분기 방향 하나 맞췄다고 파이프라인이 매끄럽게 돌아가지 않습니다. 명령어들 사이에 얽혀있는 데이터 의존성(Data Hazard) 때문에 ALU가 놀고 있는 시간이 생기기 때문입니다.