Linguistic Acceptability Judgement (적합성 판단)
문제 정의
task가 해결하고자 하는 문제가 무엇인가?
Linguistic acceptability judgement (적합성 판단)은 간단히 말해, 주어진 문장이 문법적으로 맞는지 판별하는 것이다.
적합성 판단/문법 검사를 위해 가장 대표적으로 쓰이는 방식은 BERT를 파인튜닝 하는 방법이 있다.
데이터셋 소개
데이터 셋 명칭
CoLA (The Corpus of Linguistic Acceptability)
구조
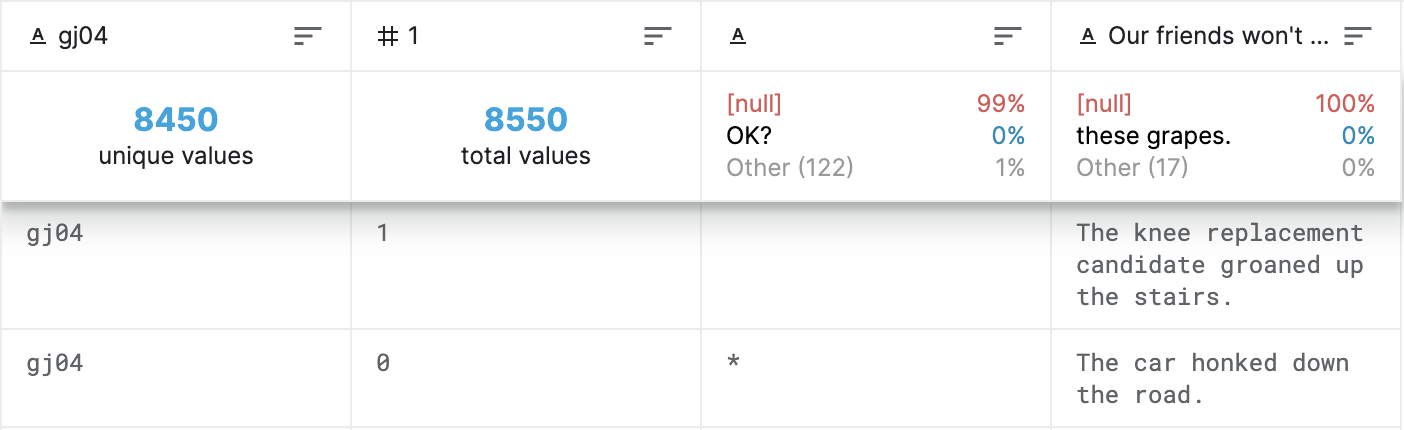
10657 문장과 23개의 언어학 출판물로 이루어진 데이터 셋으로,
in-domain (train & development) set / out-of-domain (test) set 둘로 나뉜다.
in-domain 데이터는 17개의 source에서 추출되었고
out-of-domain 데이터는 23개 중 남은 6개의 출판물에서 추출되었다.
1열: source를 나타내는 코드 번호
2열: 적합성 (0: 부적합, 1: 적합)
3열: (*: 출판물의 원작자가 문장이 부적합하다고 notated 한 경우)
4열: 문장
SOTA 모델 소개
1. EFL (Entailment as Few-Shot Learner)
EFL은 Large pre-trained language models (LMs) 을 더 나은 few-shot learners 로 변환하는 데 중점을 두고 있다. (classification/regression task을 추론 형식으로 변형)
적합성 판단 뿐만이 아니라, 18개의 NLP task에 대해서 전반적으로 개선된 효율을 보여주고 있다.
LMs (PLM): fine-tuning이 필요한, 큰 데이터 셋에 train 되어 특정한 task를 수행할수 있는 모델
Few-Shot Learning (퓨샷러닝): 최소한의 샘플 데이터로 classification/regression을 수행하는 것.
N-way K-shot: N (클래스의 갯수) K (각 클라스에 train 할 데이터의 개수)
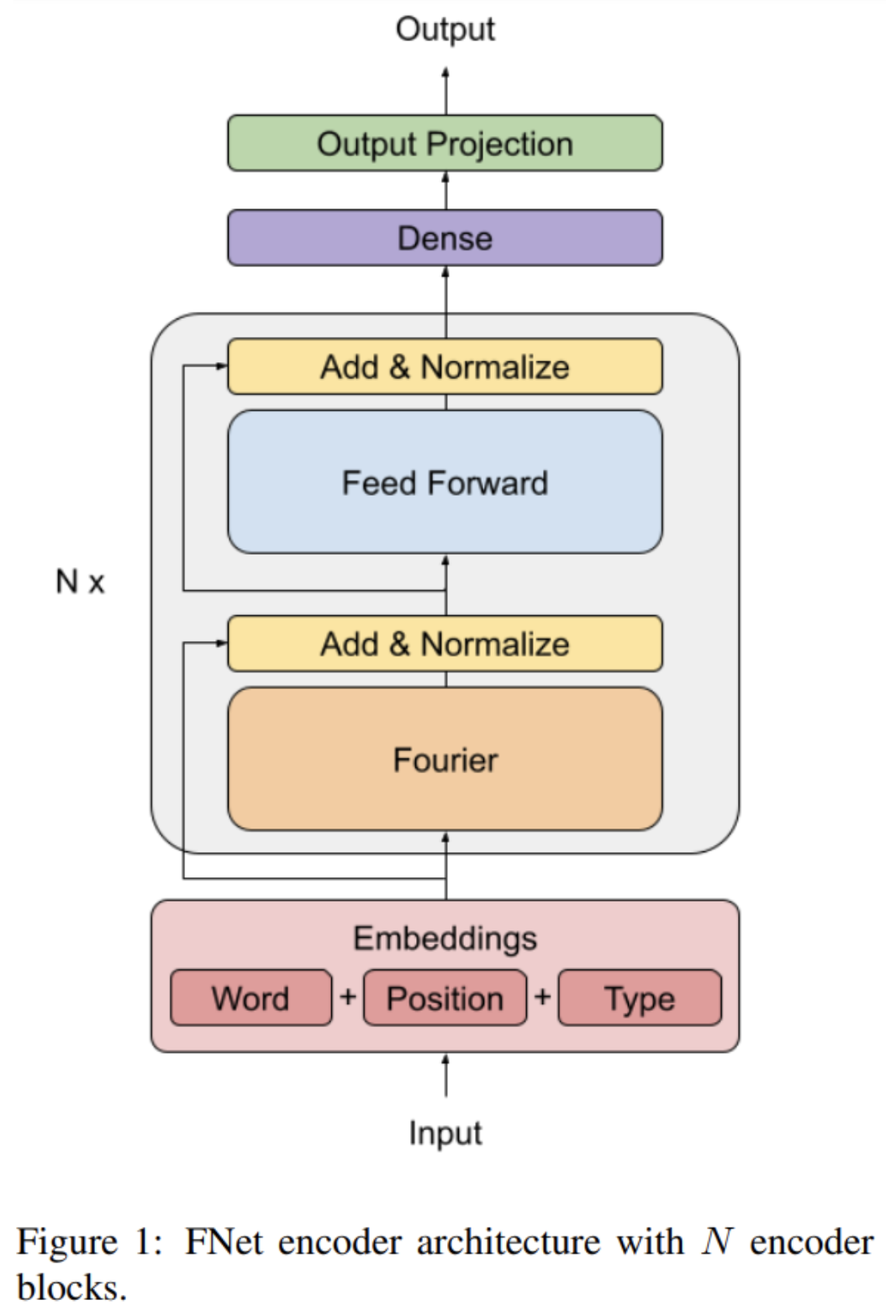
FNet
FNet는 여러 layer을 가진 정규화된 residual normal network으로
Transformer encoder architecture의 self-attention sublayers를 input토큰을 섞는 unparameterized 푸리에 변환으로 변형함으로써 희생되는 정확도에 비해 GPU와 TPU에서의 training 속도를 획기적으로 올려주는 모델입니다.
self-attention layer:
self-attention layer = self-attention sublayer + feed forward sublayer
Transformer encoder:
input의 가중치를 데이터의 연관성에 따라 다르게 부여하는 (self-attention 을 도입한) 딥러닝 모델. Parallel training을 통해 RNN/LSTM이 하지 못하는 큰 데이터 셋의 train을 가능하게 해, BERT/GPT와 같은 pre-trained 모델을 개발할 수 있게 했다.
unparameterized Fourier Transform (linear mixer)
간단히 말해 선형변환입니다.
Time domain은 겹쳐지게 되고 Frequency domain은 분산되며 인풋 토큰이 섞이게 됩니다.
Reference
[1] https://www.kaggle.com/krazy47/cola-the-corpus-of-linguistic-acceptability
[2] https://paperswithcode.com/paper/fnet-mixing-tokens-with-fourier-transforms
FNet 에 대한 youtube 정리:
https://www.youtube.com/watch?v=JJR3pBl78zw

3개의 댓글

정합성 판단 모델링에 대해서는 처음 읽었는데, 역시 이곳에서도 트랜스포머의 self-attention을 도입한 모델이 사용되는군요! 잘 읽었습니다.

잘읽었습니다! EFL과 FNet 중 어느 것이 성능이 더 좋은지 궁금하네요.