Extractive Summarization Task (추출 요약)
Summarization Task
추상적 요약 Abstractive (advanced)
원본의 요약본을 생성하되, 생성된 요약본은 원본에 포함되지 않은 문단과 문장들 또한 포함할 수 있다
Abe and Mary went out to have a dinner with their best friend John at the hotel
-> Abe and Mary ate at a hotel with their dearest friend John
추출 요약 Extractive (traditional)
문서가 주어졌을 때, 원본을 가장 올바르게 표현/정리할 수 있는 단어와 문장들을 변형 없이 추출해 요약본을 생성한다.
Abe and Mary went out to have a dinner with their best friend John at the hotel
-> Abe Mary have dinner John hotel
clustering based / optimization based / information and itemset bsed / word emdbedding based 등 다양한 형태로 존재한다
Single document summarization (SDS): 한 문서에 대해서 요약
Multi-document summarization (MDS): 같은 topic에 관련된 여러 문서에 대해서 요약
SDS와 비교했을 때 MDS는 여러 시간대에 출판된 문서들을 통해 더 정확도가 높으면서 topic에 대한 더 다양한 의견을 제공하는 종합적인 요약본을 생성한다.
MDS의 단점으로는 중복된 정보를 처리해야 한다는 것과 degradation 현상이 일어날 수 있다는 것이 있다.
기존의 존재하는 접근과 다르게,
Semantic approach / Syntactic approach / Statistical approaches
또한 존재합니다.
추출 요약의 features
추출된 문장
문서의 주요 정보를 담고 있는 원본 그대로의 문장들이다. 각각의 문장들은 rank score을 갖고 있으며, 원본 내의 문장의 시작점(position)을 표시해주는 offset과 문장의 길이를 갖고 있다
Rank Score
문서가 담고 있는 main idea와 비교해, 문장이 담고 있는 정보가 얼마나 적합한지 알려주는 점수이다. 대개 사용하는 모델에 의해 각 문장은 Rank Score 0 과 1 사이의 점수로 측정되며, 높은 점수를 기준으로 정렬되어 return 된다.
Maximum Sentences
Return 될 최대 문장 개수. N개 이면 정렬된 문장 중 위에서부터 N개의 문장이 return 된다.
Sorting
문장들의 정렬 시에 offset 또는 rank score로 정렬할 수 있다.
Supervised 요약 모델
각 문장의 어떠한 단어들이 요약에 포함될 중요도를 가졌는지 분류하는 classification task으로 여긴다.
언어의 예측할 수 없는 패턴 때문에 정확성이 상당히 떨어진다.
Unsupervised 요약 모델
문장의 중요성이 각 문장과 문서 전체의 semantic similarity에 의해 측정된다
추출 요약 예시
- 문단을 문장단위로 변환
- Stop words, 특수기호, 문장부호 제거
- 토큰화
- 문단의 단어 등장 횟수에 비례해 각 단어에 가중치 (Rank Score) 부여
- 문장별로 (단어들의 가중치 합 / 문장의 단어 개수) 계산 후 정렬
- 문장들의 평균 점수를 threshold로 설정
- 설정된 문장 개수 (< Maximum Sentences) return
요약본 평가 방법
Bleu (정확도 측정)
모델이 생성한 요약본에 몇 개의 단어 (and/or n-grams)가 high-quality 요약본에 들어있는지 측정
Rouge (Recall 측정)
high-quality 요약본에 몇 개의 단어 (and/or n-grams)가 모델이 생성한 요약본에 들어있는지 측정
F1
F1 = 2 x (Bleu x Rouge) / (Bleu + Rouge)
데이터 소개
CNN/Daily Mail
말그대로 CNN와 Daily Mail 기사들 (URL)과 그의 요약본 (URL)을 모아놓은 데이터 셋이다.
training: 286,817 pair
validation: 13,368 pair
test: 11,487 pair
training set의 원본 문서 (article)
word spanning: 766
문장별 평균 단어 개수: 29.74
요약본 (highlights)
word spanning: 53
문장별 평균 단어 개수: 3.72
{
'article': '(CNN) -- An American woman died aboard a cruise ship that docked at Rio de Janeiro on Tuesday, ... ,
'highlights': 'The elderly woman suffered from diabetes ...
}
SOTA 모델
1. HAHSum
SDS joint-extraction & syntactic compression 요약 모델이다.
각 문장을 constituency parsing으로 분해하여 규칙에 따라 압축하고,
compressions을 뉴럴 네트워크를 통해 점수를 부여한다.
learning시, 추출된 component와 compressed component를 (X) 둘 다 사용하며,
압축된 Oracle summaries를 (Y) supervised training 하는 데 사용한다.
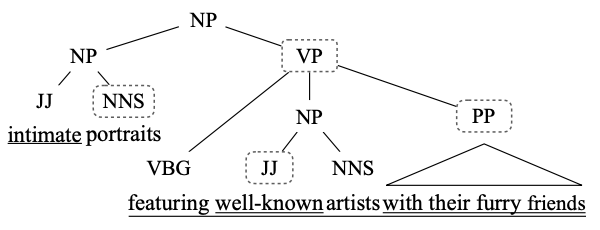
Constituency Parseing
문장을 sub-phrases (constituents)로 분해한다.
각 sub-phrase는 NP (Noun Phrase) 또는 VP (Verb Phrase)에 속한다
text compression 예시
"Intimate portraits featuring well-known artists with their furry friends"
-> intimate, well-known, with their furry friends 삭제
-> Portraits, featuring, artists (compression)
Oracle summary
Maximum ROUGEn 점수를 가진 문장들을 종합해 만든 요약본
ROUGE-N (Recall-Oriented Understudy for Gisting Evaluation)
n-gram Recall 에 기반하여 계산됩니다
2. MatchSum
추출 요약 task를 일반적인 방법이 아닌, semantic space에서 원본 문서와 추출된 candidate 요약본들이 매칭되는 방식으로 다루는 모델입니다.
더 나은 요약본들이 원본 문서와 semantic space 상에서 가까운 위치에 있을 것이고 'gold summary'가 가장 가까운 위치에 있을 것입니다.
sentence-level 추출이 아닌 summary-level 추출 framework가 사용되었습니다.
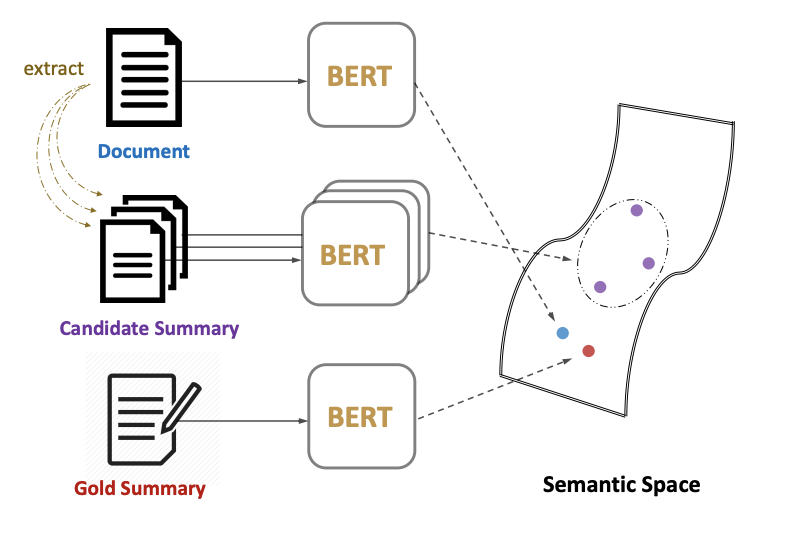
Gold Summary
Candidate summary와 비교해서 ROUGE 점수를 생성하는 데 사용되는 기준이 되는 요약본
Content selection module
각 문장에 중요도 점수를 부여해 (trigram blocking을 제외한 BERT 사용)
중요한 문장만 남겨 pruned 문서를 제작하는 데 쓰인다.
pruned 문서에서 모든 sentence의 combination을 생성한 뒤, 원본에 존재했던 문장들의 위치에 따라 정렬하여 candidate summary를 생성한다.
Siamese-BERT
문서 D와 candidate 요약본 C를 매칭하는 데 사용.
2개의 BERT가 tied-weights와 cosine-similarity layer로 연결되어 있다



추출 요약의 Features도 다뤄주셔서 도움 많이 됐습니다!