MatchSum
Project Overview
Match Sum 모델 framework을 Bert/Roberta 모델과 문서요약 텍스트 데이터셋을 사용해 구현해 보았습니다.
Pretrained Model / Tokenizer
형태소 분석을 바탕으로 학습된 KorBert 모델이 Fine-Tuning 되었을시 SentencePiece Tokenizer을 사용하는 Kobert을 비롯한 다른 모델보다 더 좋은 성능을 보여줄것이라 판단하였지만, ETRI가 제공하는 형태소 분석기 API의 하루 사용량이 5,000개의 호출제한이 있으므로 편의성을 위해 klue/roberta-large를 기반으로 사용하였습니다.
또한 논문에서 명시된 CNN/DailyMail 데이터 셋의 Fine-Tuning시 8개의 Tesla-V100-16G GPU가 30시간동안 학습 되었단 사실은 Google Colab에서 학습을 진행하는 입장에서, 시작부터 Fine-Tuning process을 포기하고 Data Preprocessing과 모델을 중점으로 학습해야 겠다는 목표를 세워주었습니다.
Dataset
문서요약 텍스트 train_original_news.json
AI-Hub에서 배포하는 뉴스 기사요약 텍스트 데이터셋을 사용하였습니다.
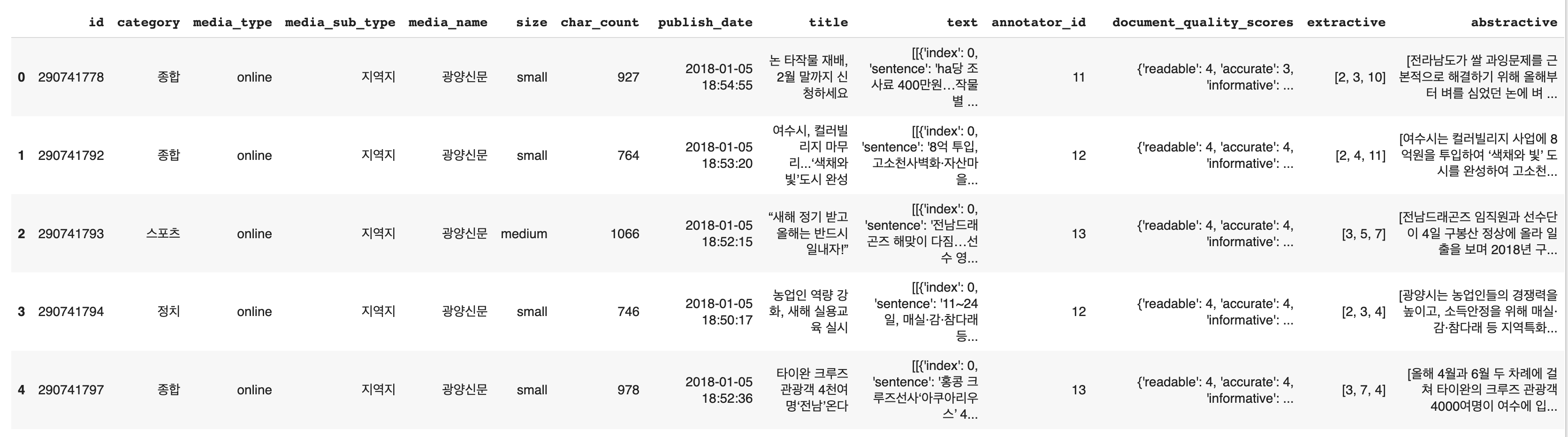
'documents' Column아래 14개의 Columns가 존재하는데, 이중
- text
- 기사의 index와 그에 해당하는 본문, 문장내의 중요 단어들의 indices가 dictionary 형태로 포함되어 있다 - extractive
- 사람이 판단한, 기사를 요약할수 있는 0-3개의 문장에 대한 index가 포함되어 있다 - abstractive
- 기사에 대한 사람이 작성한 요약본을 담고 있다
3개의 Column만을 사용하여 진행 하였습니다.
Preprocessing
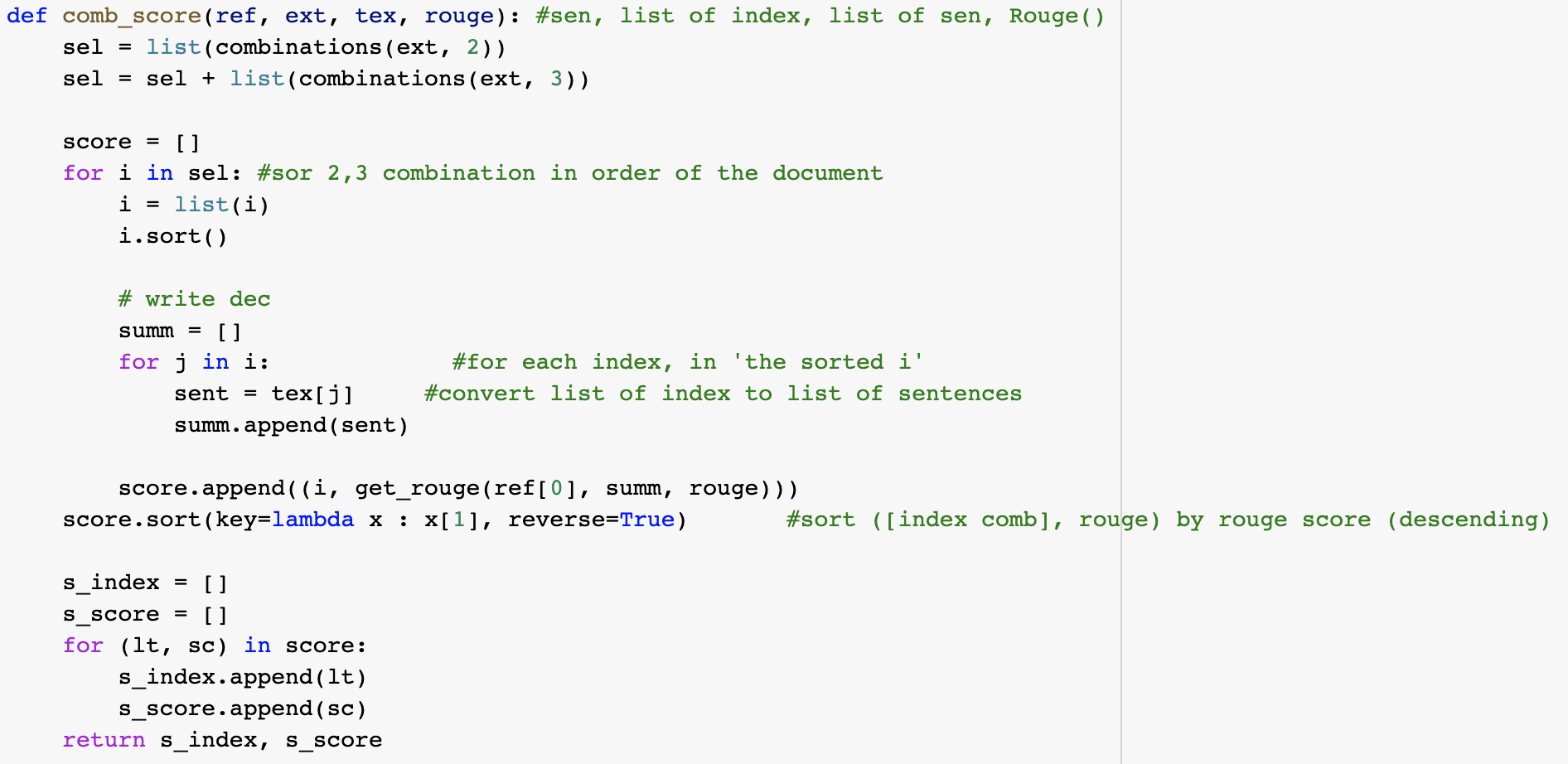
MatchSum 모델에 있어서 가장 중요한 개념중 하나는 Sentence-Level 추출이 아닌 Summary-Level 추출 Framework을 사용하는 점이다.
Sentence-Level이면 데이터 셋의 'extractive' Column에서 제공하는 (최대 3개의) index을 그대로 사용할수 있었겠지만, 3개의 인덱스 만으로는 충분한 Candidate을 만들기에 충분하지 않다고 판단 되어 Paper에서 명시된
- Candidates Pruning
- Candidate Combination
- Sorting based on Rouge((1+2+L)/3)
등의 과정을 진행하였다.
Faulty Data
데이터 셋이 제공하는 기사들중 Abstractive Column에 요약본이 존재 하지 않는 기사 (4개)와 Extractive Column에 None이 포함된 (index 개수가 3미만) 기사 (8개)는 Train Dataset에 포함하지 않았습니다.
Cleaning Up Sentences
문장 에서의 영문/한글/숫자를 제외한 모든 Special Characters은 제거하였습니다.
기사에서 자주 등장하는 'ㅁㅁㅁ기자' 와 같은 문장들은 Paper에서 CNN/DM의 non-anonymized version을 사용하였듯이 따로 다루지 않았습니다.

Candidates Pruning
MatchSum Paper에서 등장하는 기사/문서를 간추리는 과정으로 "Content Selection Module"을 사용해 원본 문서 길이에 따라 적당한 길이로 Pruning 합니다.

- Ext: 간추려진 문서의 길이
- Sel: 생성할 Candidate 요약본의 길이
- Size: Candidate 요약본의 개수
문서요약 텍스트 데이터 셋은 길이와 용도 면에서 CNN/DM과 가장 흡사하다고 판단해
Greedy-Selection (Content Selection Module)을 통해 5개의 문장으로 기사를 요약해 보았습니다.
Paper 에서 명시된 Content Selection Module은 BertExt로 BertSum모델을 trigram blocking (중복되는 문장들을 걸러주는 장치)을 사용하지 않고 각 문장에 점수를 부여해 가장 높은 ext개의 문장을 '간추린 문서'로 사용하는 것이였습니다.
하지만 BertExt을 새로 Fine-Tuning할 시간과 Resource가 부족하기에, BertSum의 Oracle Summary 제작에 사용되는 Greedy-Selection알고리즘을 사용해 보았습니다.
(문장들의 조합의 Rouge 1&2의 점수를 최대화하는 알고리즘 입니다)
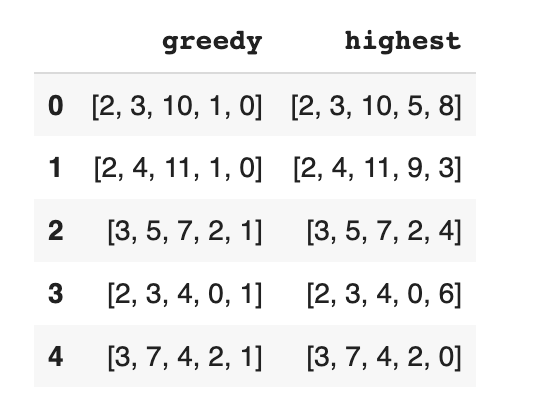
 기존의 Greedy-Algorithm을 문서에 적용한 결과, 대개 5개에는 못미치는 1,2개의 문장만 추출 하는 경향을 보여주어, 데이터 셋이 제공한 Extractive Column의 3개의 index을 활용해, 3개의 index을 포함해 조합했을때 가장 로그 점수가 높게 유지되는 두 index을 추가로 선택하는 식으로 변형하였습니다.
기존의 Greedy-Algorithm을 문서에 적용한 결과, 대개 5개에는 못미치는 1,2개의 문장만 추출 하는 경향을 보여주어, 데이터 셋이 제공한 Extractive Column의 3개의 index을 활용해, 3개의 index을 포함해 조합했을때 가장 로그 점수가 높게 유지되는 두 index을 추가로 선택하는 식으로 변형하였습니다.
이에 추가로 발생한 문제점은, 로그 점수의 감소를 최소화하는 특성 때문에, 대개 index 0,1에 포함되어 있는 ㅁㅁㅁ기자 + (이메일) 문장이 거의 모든 index set에서 발견된 점 입니다.
Trigram Blocking을 사용하지 않은 BertSum은 중복된 문장이라도 높게 평가할거라 생각해, Extraction Column의 index를 포함해 추가로 2개의 최대 Rouge1 + Rouge2 Score을 가진 문장을 선정해 5개의 index로 Pruning 하였습니다.
Candidate Combination & Sorting based on Rouge
간추린 기사를 사용해, 각 기사당 5C2 + 5C3 = 20 개의 Candidate Summary을 제작하였습니다.
 20개의 Candidate Summary는 5줄로 간추려진 본문과 비교하여 (Rouge-1, Rouge-2, Rouge-L)/3 점수가 가장 높은 순서대로 정렬하였습니다.
20개의 Candidate Summary는 5줄로 간추려진 본문과 비교하여 (Rouge-1, Rouge-2, Rouge-L)/3 점수가 가장 높은 순서대로 정렬하였습니다.
Tokenizing Inputs
기본적으로 Document/Candidate Summary/Gold Summary 모두
[CLS] + Tokenized + [SEP] Format으로 토큰화 되었는데 이를 통해 학습을 진행하였을시 GPU 용량을 초과해, 이를 방지하기 위해
- Candidate Summary 개수의 조정
- Candidate Summary max_length 조정 (Default: 180)
- Document max_length 조정 (Default: 512)
- Batch Size 조정
등을 진행하였습니다.
Model
Siamese-Bert architecture로 Document 원문을 Candidate Summary들과 Gold Summary에 대해 Matching 합니다. Matching을 진행할때 BERT Layer에서 추출한 [CLS] 토큰 벡터를 문서/요약본의 Representation으로 취급합니다.
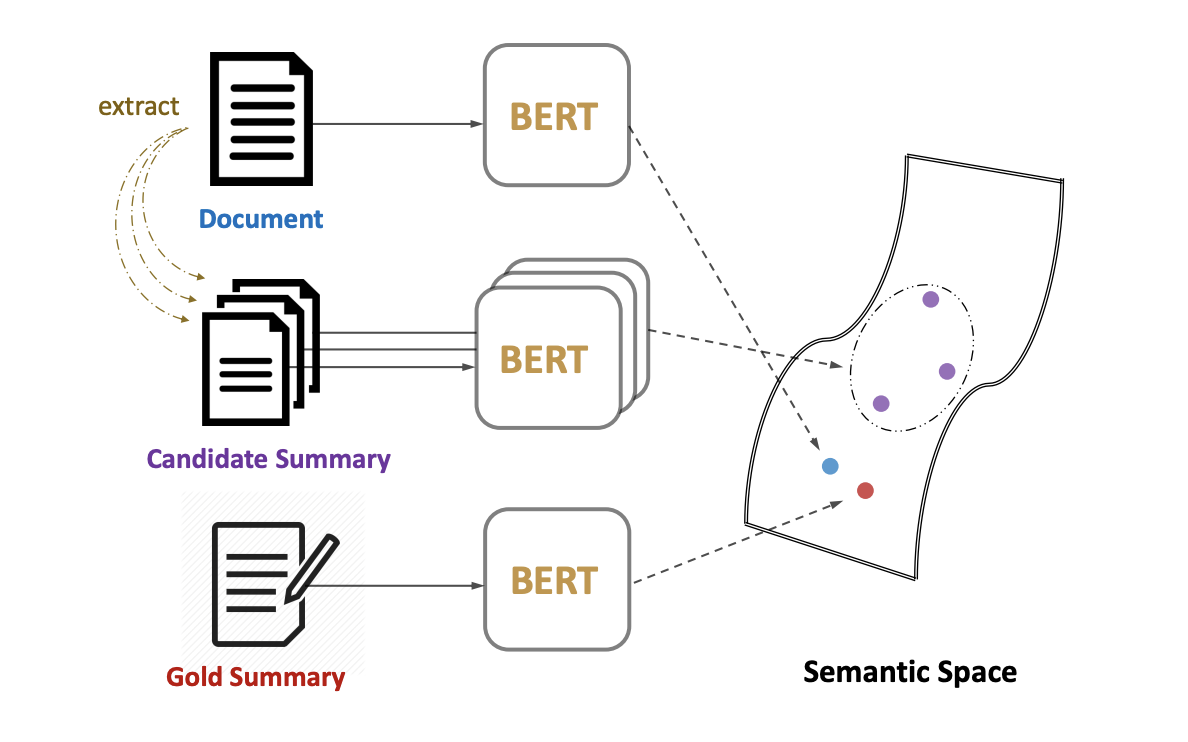
Gold Summary (사람이 작성한 Abstract)가 다른 Candidate Summary와 비교했을때 원본 기사에 가장 근접한 (Cosine Similarity)거리를 가져야 합니다.
이를 Ensure하기 위해 Margin-Based triplet loss (MarginRankingLoss)을 Training에 사용하게 됩니다.
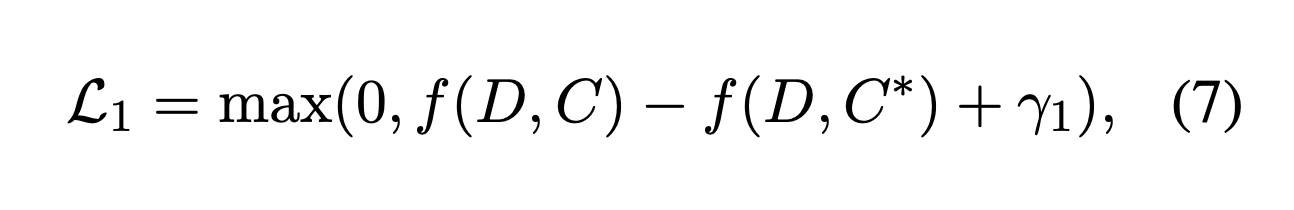
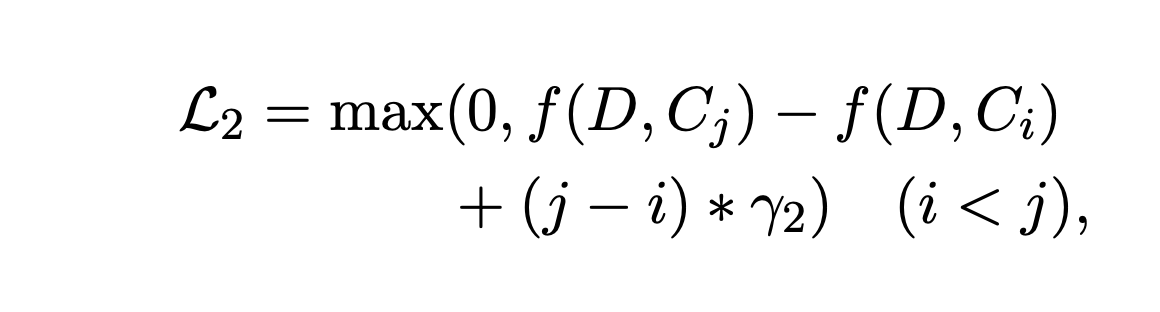
- D: Document Embedding
- C*: Gold Summary
- Ci: i'th ranking Candidate Summary
- γ1: Margin Value
- γ2: 좋은 Candidate Summary와 안좋은 Candidate Summary을 구분하기 위한 Hyperparameter
MatchSum Paper에서 사용된 Hyperparameter γ1와 γ2는 각각,
- γ1 = 0
- γ2 = 0.01
입니다.

Reference
MatchSum Paper
https://arxiv.org/pdf/2004.08795.pdf
BertSum Paper
https://arxiv.org/abs/1903.10318
MatchSum Github
https://github.com/maszhongming/MatchSum.git
BertSum Github
https://github.com/nlpyang/BertSum.git
Klue Github
https://github.com/KLUE-benchmark/KLUE
