Korean Semantic Textual Similarity
Project Overview
Pretrained된 모델을 Fine-Tuning해 주어진 두 문장의 유사성을 유추하는 모델을 API화 했습니다.
Pretrained Model
klue/roberta-large
Klue benchmark 에서 제공하는 Roberta 모델로 paper 에서 명시한 8개의 task을 구현하는데 필요한 Base 모델이다.
- Embedding size: 1024
- Hidden size: 1024
- Layers: 24
- Heads: 16
Dataset
klue-sts-v1.1
Klue benchmark에서 제공하는 Semantic textual similarity 학습용 데이터 셋 으로,
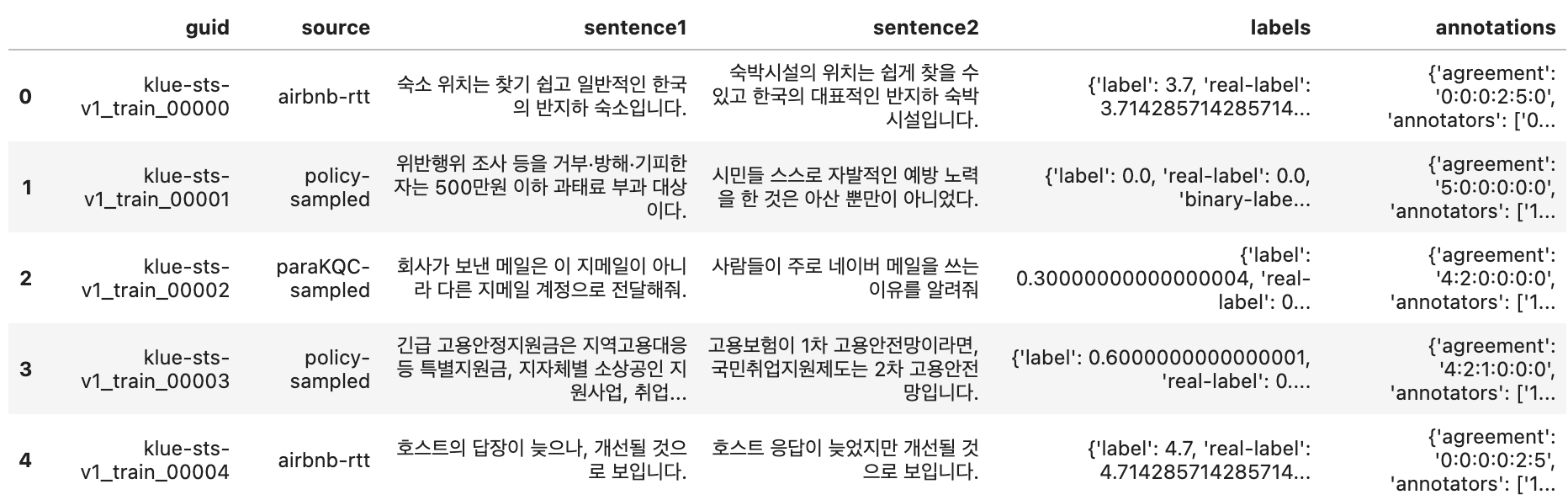 위와 같이 6개의 Column으로 구성되어 있으며, 이중
위와 같이 6개의 Column으로 구성되어 있으며, 이중
sentence1, sentence2, label(real-label) 세개의 Column만 Fine-Tuning process에 사용되었습니다.
Kor-STS
카카오 브레인에서 공개한 KorNLU 데이터 셋의 일부로 ,
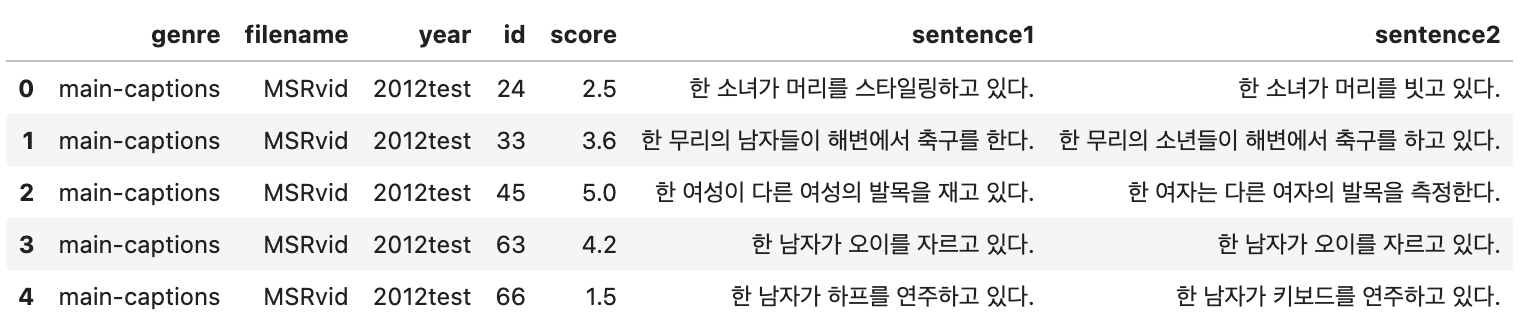 7개의 Column 중 sentence1, sentence2, score 세개의 Column만 Fine-Tuning process에 사용되었습니다.
7개의 Column 중 sentence1, sentence2, score 세개의 Column만 Fine-Tuning process에 사용되었습니다.
Preprocessing
klue-sts-v1.1
Train/Dev 두 개의 데이터 셋만 제공되었으므로 Train 데이터셋을 각 문장 페어의 유사도 점수 분포를 유지하며 10%의 데이터를 Random Sampling 하였습니다.
 Kor-STS
Kor-STS
데이터셋의 점수별 분포 입니다.

두 학습 데이터 모두 동일하게 preprocess 하였습니다
- Html 제거
- 따옴표 + 모든 특수부호 제거 (including Chinese Character)
- Labels = Labels / 5
- 사용하는 모델의 final output이 Cosine simialrity 로 계산되므로 (output of -1 to 1), 0-5 range의 label들을 0-1로 down scaling 하였습니다.
Model/Tokenizer
Tokenizer
Klue/roberta-large와 함께 train된 BertTokenizer 을 사용하였습니다
Model
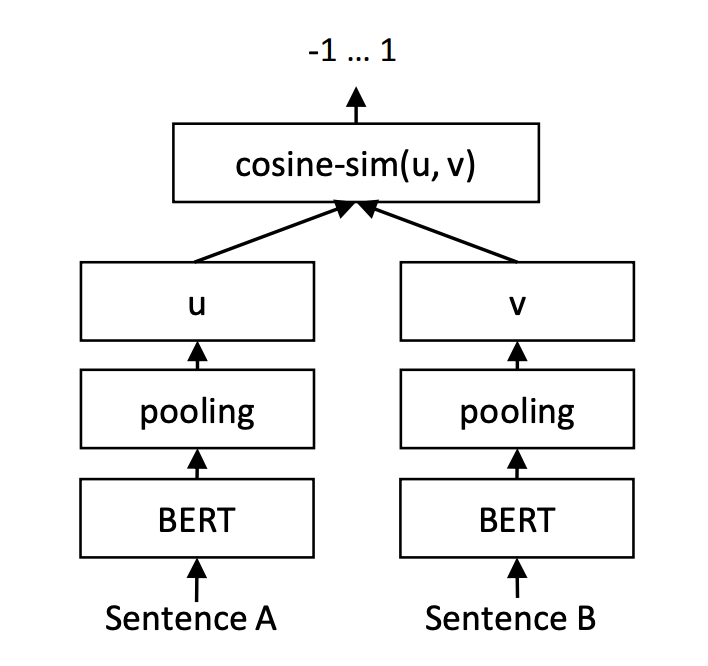
추론을 위한 Siamese BERT Network를 사용하였습니다.
위 모델은 weight를 공유하며 각 sentence의 embedding에 mean-pooling operation을 추가로 진행해 두 fixed-size sentence embedding의 Cosine Simialirty를 구하는 방식으로 설계되어 있습니다.


Training Details
Metric
klue-sts-v1.1의 Validation과 Test Set Evaluation시 사용한 Metric은 Klue paper에서 언급된 Pearson Correlation Coefficient와,
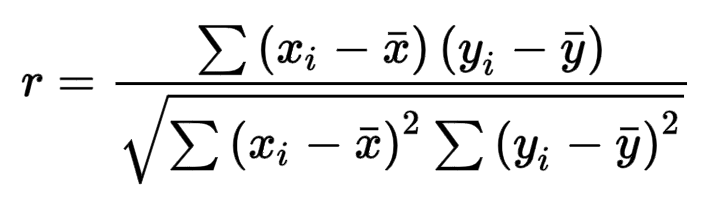
F1 Score을 사용하였습니다.
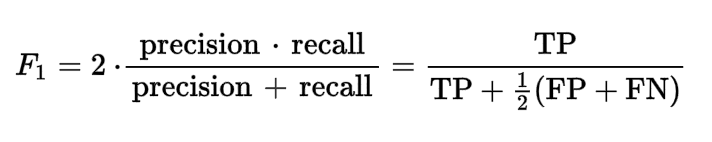
- F1 Score으로 Evaluate시 모델을 0/1 (Binary) 데이터에 대해 다시 Fine-Tuning 시킨것이 아닌,
Real-Value와 모델이 predict한 (0-5)사이의 값에 3의 threshold를 적용해 > 3 = 1, < 3 = 0 인 binary classification task으로 취급하였습니다.
Kor-STS의 Validation과 Test Set Evaluation시 Spearman Correlation을 사용하였습니다.
위와 다른 Metric을 사용한 이유로써는, 모델의 성능을 같은 데이터셋에 대해 평가/학습한 다른 모델들의 성능과 비교하기 위해서 사용하였습니다.
Max Sequence Length
128
Optimizer
AdamW
Loss Function
Regression task에 자주 사용되는 Mean Squared Error(MSE)을 사용하였습니다
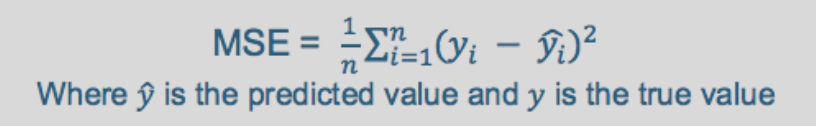
Klue paper에서 제공한 Optimal Hyper Parameter Range
- learning rate {1x0^-5, 2x10^-5, 3x10^-5, 5x10^-5}
- warm up ratio {0, 0.1, 0.2, 0.6}
- weight decay {0, 0.01}
- batch size {8, 16, 32}
- epoch {3,4,5,10}
- max_sequence_length 128
Fine-Tuning On klue-sts-v1.1
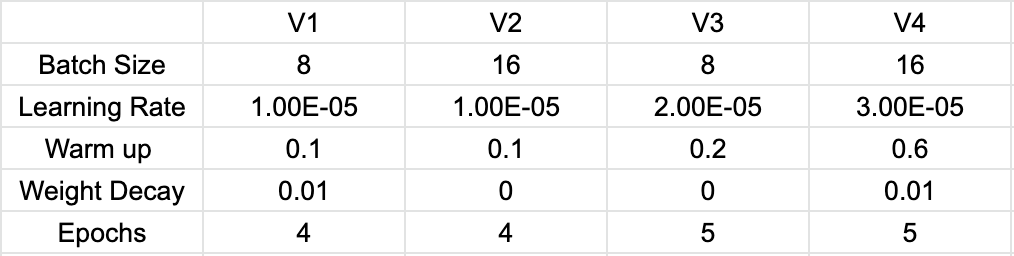
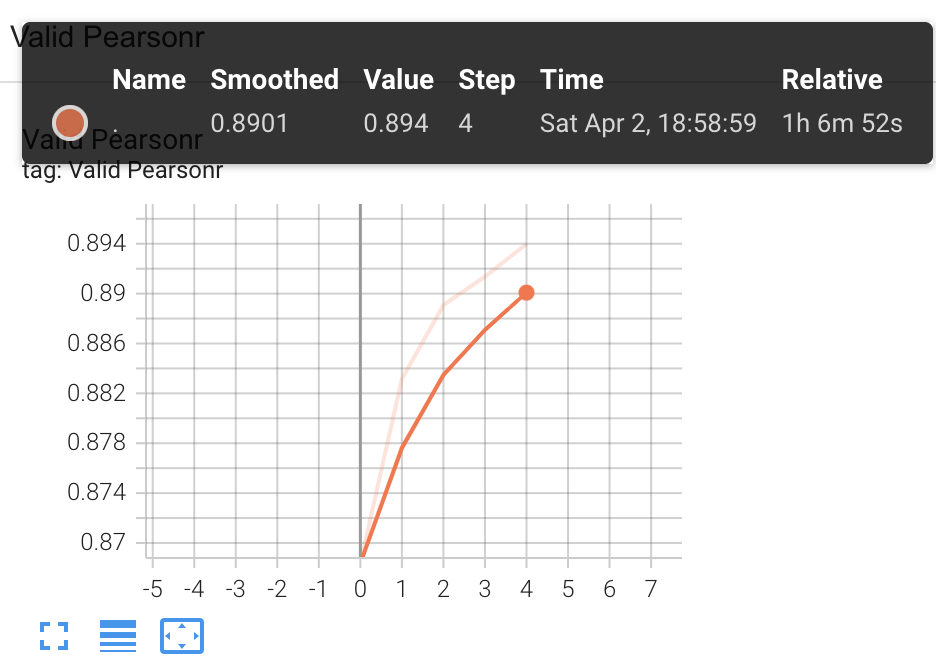
Out of 4 stages of Fine-Tuning, the third trial epoch 4 had the highest pearsonr and f1 score with lowest loss on validation set
Pearsonr: 0.894
F1 Score: 0.8491
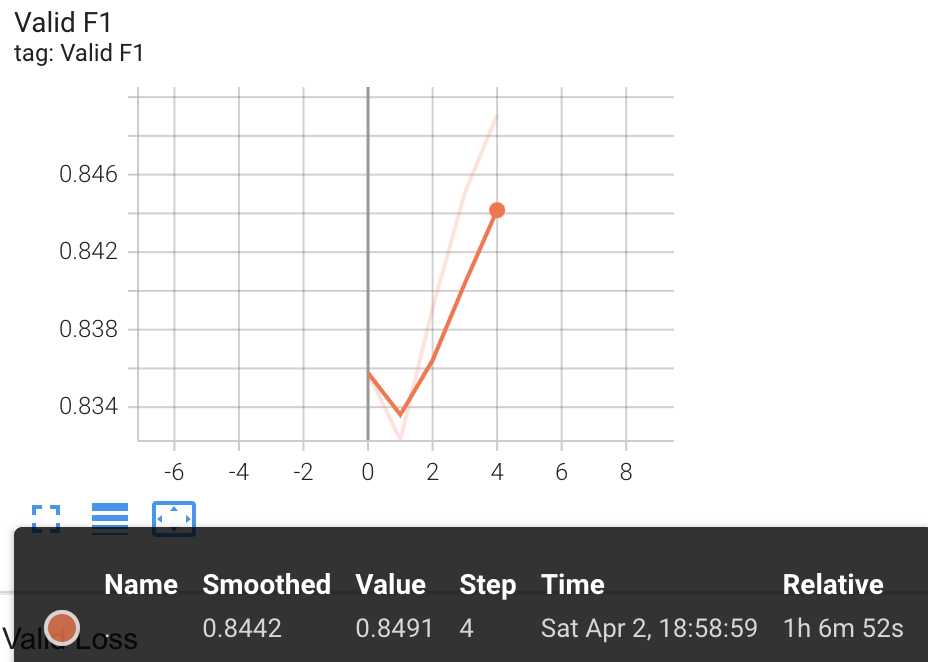
Loss: 0.5939
As the most optimal version for Klue/roberta-large model was fine-tuned with "10 epochs with a linear warmup of 1 epoch" performing as Pearsonr: 93.35,
having the model fine-tuned for 5 epochs (half the amount) along with 10% of data lost due to the splitting of the train set seems like a reasonable reason for underperformance of the fine-tuned model.
Testing model on Kor-STS
Testing of the highest perfoming model v3 epoch 4 on Kor-STS test set resulted as follows
Spearman
correlation=0.7763
pvalue=1.0966e-277
F1 Score
f1_score: 0.7793
Due to the underperformance of the model on Kor-STS data, I performed fine-tuning of the roberta model with same hyper parameter settings as the highest performing model, but with combined training and validation dataset of both Kor-STS and klue-sts-v1.1
Fine-Tuning On klue-sts-v1.1 and Kor-STS Dataset
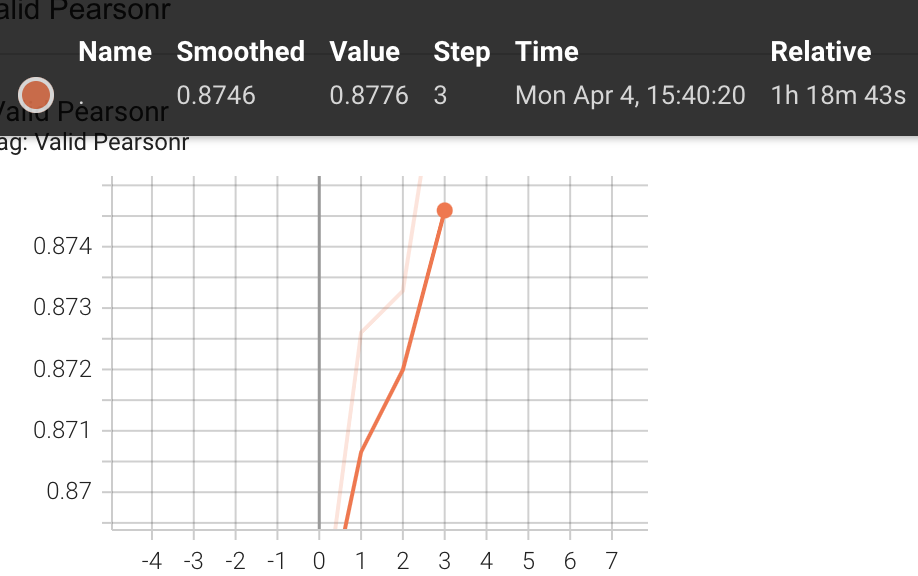
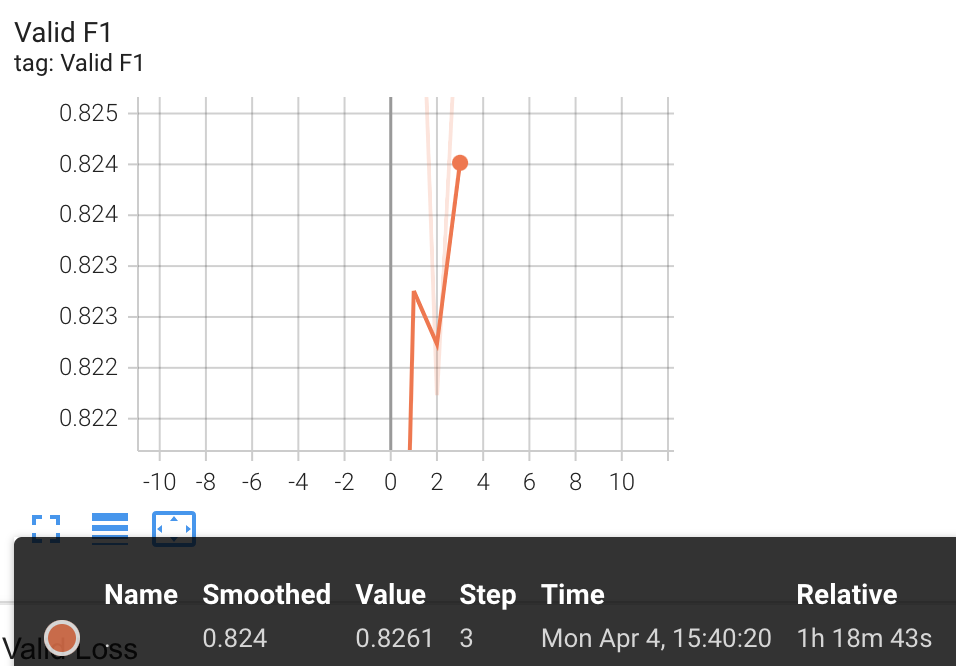
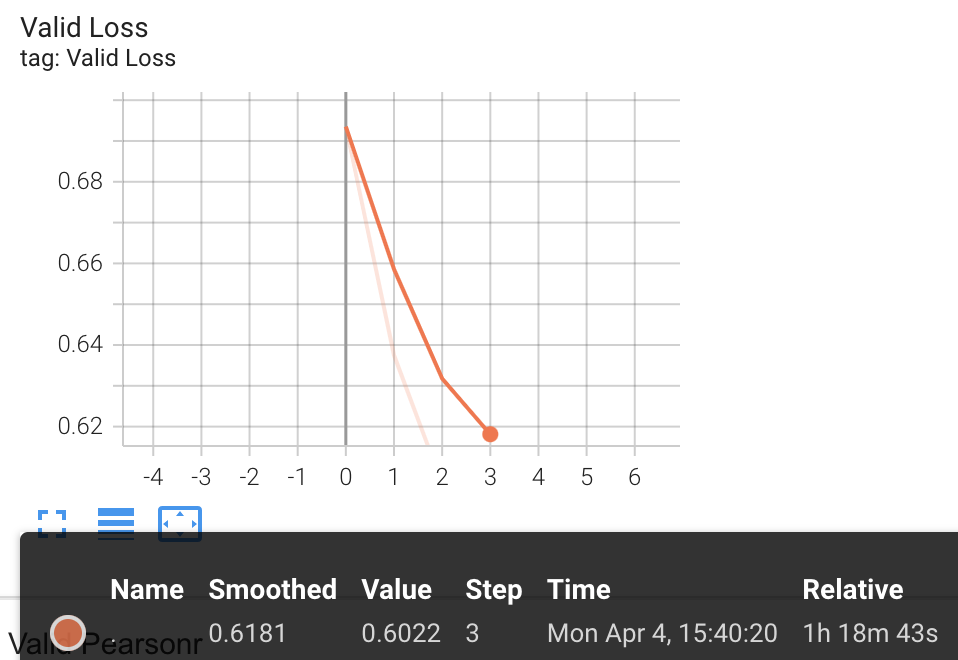
3rd Checkpoint had the highest Pearson correlation, f1 Score and lowest loss on merged dataset of klue-sts-dev and kor-sts-dev.
Pearsonr: 0.8776
F1 Score: 0.8261
Loss: 0.6022
As the merged validation set not comparable with other models, the model was tested on each Klue-sts-dev and kor-sts-test dataset.
Klue-sts-dev
- Pearsonr: 0.8845
- F1 Score: 0.8502
Kor-sts-test
- Spearman: 0.8355
- F1 Score: 0.8383
Although training on both dataset resulted in slight decrease in performance on Klue-sts dataset
- Pearson: -0.0095
- F1 Score: -0.0011
Model showed significant improvement on its performance on Kor-sts-test dataset
- Spearman: +0.0592
- F1 Score: +0.059
Rest API
Created API using pickle to save the entire fine-tuned model (trained on both dataset) and tokenizer
The API consists two method
-
Predict
- take two sentences as key and returns the semantic similarity score predicted by the model

-
Post
- takes a base sentence and a csv file consisting multiple sentences.
- The model predicts semantic similarity score between the base sentence and each sentences and returns dictionary of scores (in the format {index: prediction})

Example Usage
GET
Sentence One
- 한 남자가 밧줄을 타고 올라간다.
Sentence Two
- 한 남자가 밧줄을 타고 올라가고 있다.
Score
- 4.906567573547363
POST
Base Sentence
- 한 남자가 식당에서 밥을 먹고 있다.
Sorting the returned dictionary allows acquiring index of top semantically similar sentences
Top 10 Similar Sentences
- 한 남자가 음식을 먹고 있다.
남자가 먹고 있다.
한 남자와 여자가 식당의 테이블에 앉아 있다.
식당 식탁에 둘러앉은 사람들 무리.
한 무리의 사람들이 이탈리아 식당의 테이블에 앉아 있다.
한 남자가 냄비에 쌀을 붓는다.
네 명의 아이들이 식당에서 의자에 앉아 있다.
두 명의 근로자가 파이프 옆에 앉아 점심을 먹고 있다
한 남자가 어느 날 밤늦게 만화를 보면서 팝콘을 먹는다.
한 남자가 쌀 한 송이를 팬에 붓고 있다.
