
⚠️ 해당 포스팅은 인프런 공룡책 강의를 듣고 개인적으로 정리하는 글입니다. 정확하지 않은 정보가 있을 수 있으니 주의를 요합니다.
Section 04
Chapter 4 Threads
Thread Overview
- 프로세스는 기본적으로 하나의 흐름에서 프로그램을 실행했으나, 프로세스는 여러 흐름에서 프로그램을 제어할 수 있다.
- 그것이 바로 스레드(Thread)로, 경량화된 프로세스 라고 불리운다.
- CPU 이용의 기본 단위로, thread ID, program counter, register set, stack 으로 구성되어 있다.
Motivation for multithreading
- 현대 컴퓨터 혹은 모바일 기기의 소프트웨어는 대부분 멀티 스레딩을 지원한다.
- 클라이언트-서버 시스템 케이스가 있는데, 예를 들어 웹 서버를 생각해보자.
하나의 분주한 웹 서버는 수천, 수만 개의 클라이언트들이 병행하게 접근할 수 있다.만약 웹 서버가 전통적인 단일 스레드 프로세스로 작동한다면, 자신의 단일 프로세스로 한 번에 하나의 클라이언트만 서비스할 수 있게 되어 클라이언트자신의 요구가 서비스되기까지 매우 긴 시간을 기다려야 한다. 이러한 단점을 개선하기 위해서 여러 요청을 수행할 별도의 프로세스들을 만들 수도 있지만 이는 많은 리소스가 필요함으로 많은 오버헤드가 발생한다. 프로세스를 새로 만드는 것 보다 프로세스의 개념을 확장하여 한 프로세스가 다수의 실행 스레드를 가질 수 있도록 허용한다. 그들은 프로세스가 한 번에 하나 이상의 일을 수행할 수 있도록 허용함으로써 문제를 해결한다. 이를 웹 서버에 적용 시켜보면, 웹 서버가 다중 스레드화 되게끔 만들어서 서버는 클라이언트의 요청을 listen 하는 별도의 스레드를 생성한다. 요청이 들어오면 다른 프로세스를 생성하는 것이 아니라, 요청을 서비스할 새로운 스레드를 생성하고 추가적인 요청을 listen 하기 위한 작업을 재개한다. (번역 출처)
- 멀티 스레드 프로그래밍을 채택하면 여러 이점을 얻을 수 있다.
: Responsiveness (응답성) : 프로세스의 일부분이 차단되더라도 지속적으로 실행이 가능하다.
: Resource Sharing (자원공유) : 프로세스의 자원을 스레드가 공유함으로서, 앞에서 프로세스 통신을 위해 배운 shared-memory 나 message-passing 보다 쉽게 스레드간 협업이 가능하다.
: Economy(경제성) : 프로세스 생성보다 스레드를 활용하는 것이 훨씬 가볍다. 또한, 프로세스간의 컨텍스트 스위칭(문맥 교환)보다 스레드 스위칭이 훨씬 쉽다.
: Scalability(확장성) : 멀티 프로세서 아키텍처에서 각각의 스레드가 다른 프로세서에서 병렬로 처리가 가능하기 때문에 확장성이 좋다.
Multicore Programming
- 멀티 코어 시스템에서의 멀티 스레딩은 동시성을 개선하며 효율적으로 사용할 수 있다.
- 4개의 스레드가 있다고 생각해보면, 싱글 코어에서는 스레드가 시간이 지나며 교차로 배치되지만, 멀티 코어에서의 스레드는 병렬로 실행할 수 있다.
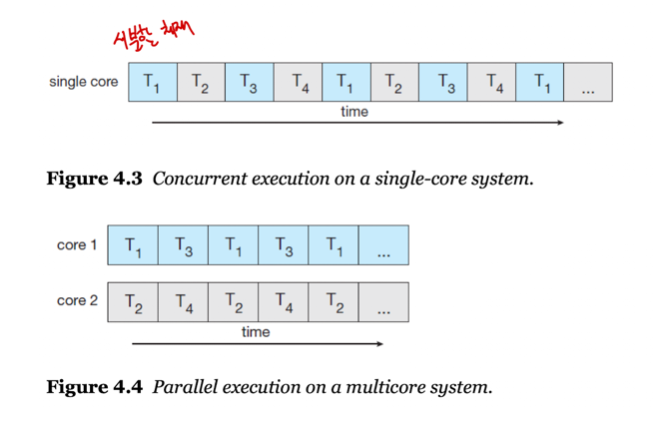
- 멀티코어 시스템에서 고려해야 할 프로그래밍 챌린지는 여러가지가 있다.
: Identifying task (태스크 인식) : 태스크가 독립적으로 실행될 수 있게 별도의 공간을 부여해야 한다.
: Balanace : 여러 태스크가 있을 때 각각의 태스크의 작업량을 동등하게 부여해야 한다.
: Data splitting (데이터 분리) : 태스크가 데이터를 조작할 때 해당 데이터는 개별 코어에서 사용할 수 있도록 나눠져야 한다.
: Data dependency (데이터 종속성) : 둘 이상의 태스크가 데이터를 조작할 때 동기적으로 실행하여 데이터에 대한 종속성을 유지해야 한다.
: Testing and debugging : 병행 프로그램을 테스팅 및 디버깅해야 하며 싱글 스레드를 사용할 때보다 어려움을 겪을 수 있다.
-
병렬 실행 시 두 가지 유형이 있다.
: 데이터 병렬 : 데이터를 쪼개 각각의 코어에 분산하고, 동일한 연산을 수행한다.
: 태스크 병렬 : 데이터가 아닌 태스크를 쪼개 각각의 코어에 분산한다.
: 분산 시스템의 개발로 크게 중요한 부분은 아니다. -
Amdahl's Law, 코어는 무조건 많을수록 좋은가?
: 예를 들어 코어가 2개일 때 처리 속도가 2라고 가정했을 때 코어가 4개이면 처리 속도는 4가 되는걸까?
: 정답은 그렇지 않다.
: 모든 처리가 병렬로 이뤄지면 그런 결과가 나올 수도 있겠지만, 순차적으로 처리해야만 하는 작업이 있기 때문에 기대만큼의 성능 향상이 이뤄지진 않는다.
Multithreading Models
- 기본적으로 스레드는 두 개의 종류가 있다.
- User thread : 커널 위에서, 커널의 지원 없이 실행되는 스레드를 의미하며 유저 어플리케이션에서 생성된다.
- Kernel thread : 코어에서 직접 스레딩할 수 있는 스레드를 O/S가 직접 관리하고 지원한다.
- 궁극적으로 유저 스레드는 CPU에서의 실행을 위해 커널 스레드로 매핑되어야 한다.

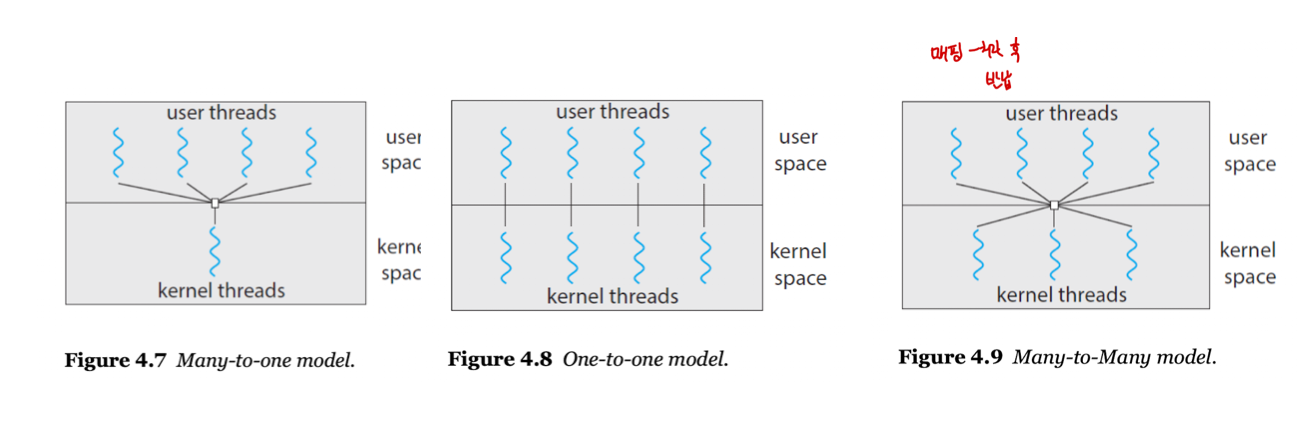
- 유저 스레드와 커널 스레드 사이에는 3개의 관계 모델이 존재한다.
- Many-to-One Model : 커널 스레드 하나가 많은 유저 스레드를 담당하는 방법으로, 한 스레드가 블락될 경우 전체 프로세스가 블락되며, 하나의 스레드만이 커널에 접근할 수 있기 때문에 다중 스레드가 다중 코어 시스템에서 병렬로 실행될 수 없다.
- One-to-One Model : 커널 스레드 하나와 유저 스레드 하나가 매핑되는 방법으로, 한 스레드가 블락되더라도 다른 스레드는 실행이 유지되며, 이로 인해 높은 병렬성을 유지할 수 있다. 그러나, 많은 커널 스레드가 생성될 경우 시스템 성능에 부담을 줄 수 있다.
- Many-to-Many Model : 여러 유저 스레드에 그보다 적거나 같은 커널 스레드를 매핑하는 방법으로, 필요한 만큼 유저 스레드 생성이 가능하고, 그에 맞게 커널 스레드를 매핑할 수 있어 병렬성도 유지가 가능하다. 그러나 구현이 어렵다는 단점이 있다.
- 현재는 시스템 성능 개선과 함께 코어의 수가 증가하는 추세로, 커널 스레드를 제한하는 것에 큰 부담을 느끼지 않아 1:1 모델을 많이 이용한다.
Thread Libraries
- 스레드 라이브러리는 프로그래머의 스레드 생성 및 관리를 지원하는 API를 제공한다.
- 라이브러리 구현에는 두 가지 방법이 있다.
: 커널의 지원 없이 유저 스페이스에서만 라이브러리를 제공하는 방법
: 운영체제에 의해 지원되는 커널 스페이스에서 라이브러리를 구현하는 방법
- 세 가지의 스레드 라이브러리가 주로 사용된다.
: POSIX Pthreads (커널 스페이스)
: Window Thread (커널 스페이스)
: Java Thread (유저 스페이스)
Pthreads
- POSIX가 스레드 생성과 동기화를 위해 만든 표준 API로, 스레드 동작에 대한 정의에 대한 것뿐이고, 구현은 아니다.
(그러나 일반적으로는 구현까지도 함께 의미한다.)
/* the data shared by the threads */
int sum;
/*thread call this functions */
void * runner(void *param);
int main(int argc, char *argv[])
{
pthread_t tid; // Thread id
pthread_attr_t attr; // Thread attributes
pthread_attr_init(*attr);
pthread_create(&tid, &attr, runner, argv[1]); // argv[1] -> runner paramter
pthread_join(tid, NULL); // 스레드 종료까지 대기
printf("sum = %d\n", sum);
}
void *runner(void *param)
{
int i, upper = atoi(param);
sum = 0;
for (i = 0; i <= upper; i++)
sum += i;
pthread_exit(0);
}
- 아래의 코드를 보고 생각해보자.
: 몇 개의 프로세스가 생성되었는가?
: 몇 개의 스레드가 생성되었는가?
정답은 아래 코드의 주석에 기재
pid_t pid;
pid = fork();
if (pid == 0) { // child process
fork();
thread_create( . . . );
}
fork();
/* 프로세스 총 6개, 스레드는 총 2개 생성 */
Implicit Threading
- 다중 코어 처리의 성장에 따라 엄청나게 많은 스레드를 가진 어플리케이션이 등장하게 되었고, 이에 따라 병행 처리 및 병렬(동시) 처리에 어려움을 겪게 되었다.
- 어려움을 타파하기 위해, 컴파일러와 라이브러리에게 스레드 생성과 관리에 대한 책임을 넘기게 된다. 이를 암시적 스레딩(Implicit Threading) 전략이라고 부른다.
- 암시적 스레딩 전략에는 총 4가지 방법이 있다.
: Thread Pools : 프로세스 시작시 일정한 수의 스레드를 미리 만들어 스레드 풀에 저장하는 전략으로, 유저가 스레드를 생성하는 것이 아니라, 스레드 풀에 스레드를 요청하여 작업을 처리하는 방식이다.
: Fork & Join : 라이브러리가 생성할 실제 스레드 수를 결정하는 동기 버전의 스레드 풀로, 명시적 스레딩이지만 암시적 스레딩에도 적합한 방법이다.
: OpenMP : C/C++로 작성된 컴파일러 지시어들의 집합으로, 유저가 병렬로 실행할 영역을 지정하면, OpenMP는 해당 영역을 병렬로 실행하는 방법이다.(아래에 실습 코드 기재)
: Grand Central Dispatch (GCD) : macOS와 iOS 운영체제에서 실행될 수 있도록 애플이 개발한 전략으로, 병렬로 실행되는 스레드를 찾아 유저가 식별할 수 있도록 한다.
/* OpenMP Test Code */
#include <omp.h>
int main(int argc, char *argv[])
{
#pragma omp parallel // compiler directive (시스템 코어의 개수만큼 스레드를 생성)
{
printf("I am a parallel region.\n"); // 코어가 4개면 4줄 프린트
}
return 0;
}
---
#include <omp.h>
int main(int argc, char *argv[])
{
omp_set_num_threads(4); // 생성 스레드 개수를 지정할 수도 있음
#pragma omp parallel // compiler directive (지정 개수만큼 스레드를 생성)
{
printf("I am a parallel region.\n"); // 4줄 프린트
}
return 0;
}
#include <omp.h>
#define SIZE 10000000
int main(int argc, char *argv[])
{
int i;
for (i = 0; i < SIZE; i++)
a[i] = b[i] = i;
#pragma omp parallel for // 병렬 처리
for (i = 0; i < SIZE; i++) {
c[i] = a[i] + b[i];
}
/*
처리 결과 시간 측정
병렬 처리 없이 돌렸을 때
real 0m0.586s -> 유저 스레드, 커널 스레드 처리 시간을 더함
user 0m0.364s
sys 0m0.223s
병렬 처리와 함께 돌렸을 때
real 0m0.423s -> 커널 스레드의 시간만 (더 빠름)
user 0m1.091s -> 관여하지 않고 병렬 처리동안 대기
sys 0m0.441s -> 커널 스레드가 모두 처리
*/
}