
파일시스템 구현
버퍼 및 캐시
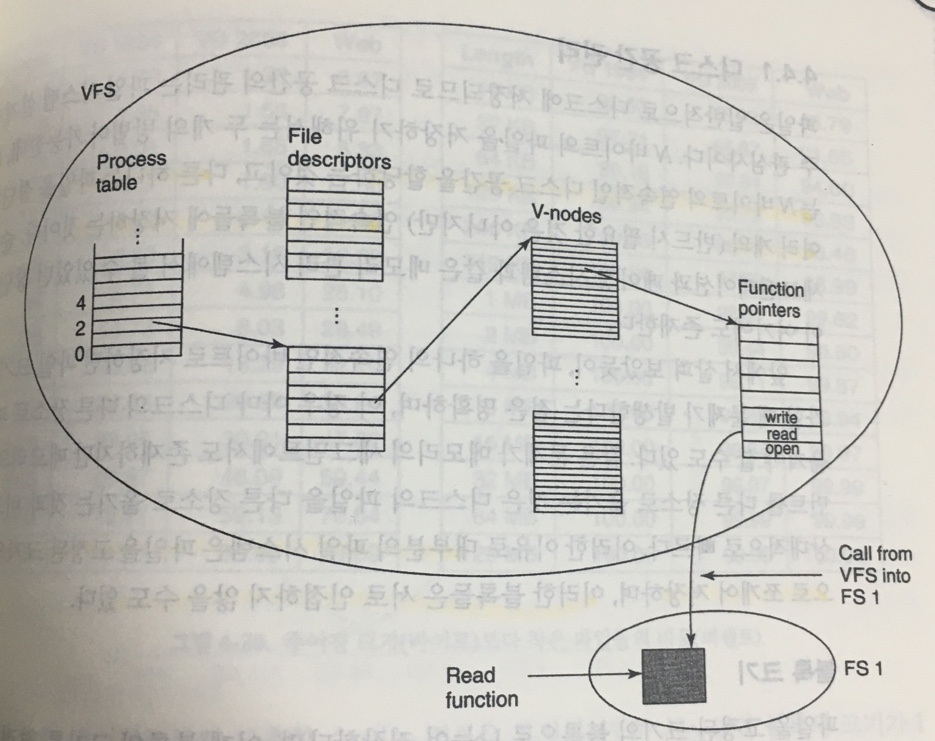
가상파일시스템
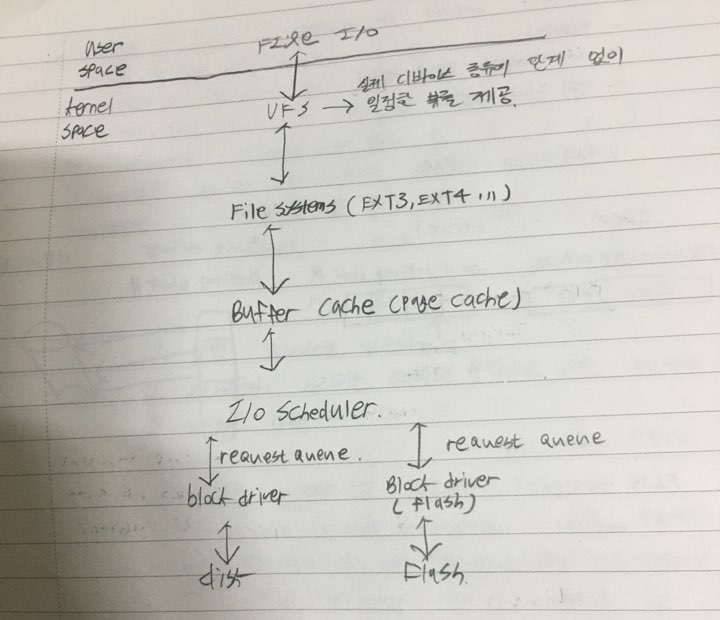
파일시스템의 구조
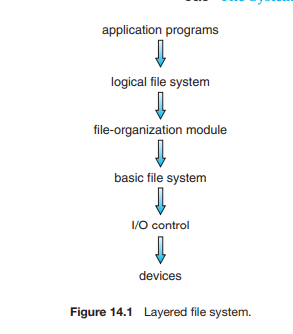
-
입출력장치: 입력으로는 , 몇 번 블록을 읽어라. 출력은 하드웨어에 맞는 기계적 명령이다.
장치드라이버들로 이루어져 있을 듯.
-
기본 파일 시스템 : 블록입출력 서브시스템, 적절한 장치 드라이버에게 명령을 내리는 층.
논리블록주소를 기반으로 드라이버에게 명령을 내린다.
버퍼/캐시 등도 관리한다.
-
file-org-module : 파일과 상응하는 논리블록을 알고 있다.
-
논리파일시스템 : 실질적으로 보이는 파일들.
파일구조는 FCB(INODE)같은 것으로 구현된다.
관점의 차이랄까,,?
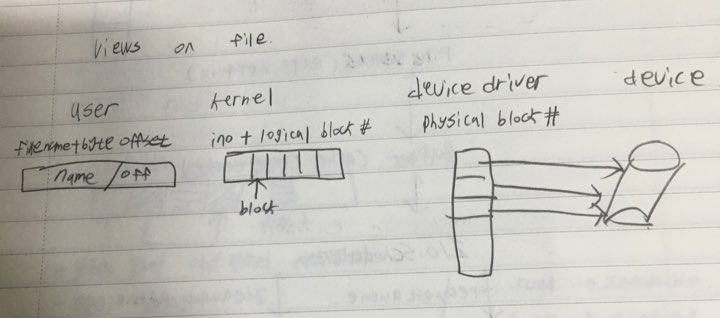
- 관점의 차이,,
파일시스템들
유닉스
- UFS(INODE 기반)
윈도우
- FAT
- FAT32
- NTFS
리눅스
- ext3
- ext4
디스크의 구조
-
부트 제어 블록
부트관련
-
볼륨제어블록
블록의 수, 블록의 크기, 가용블록의 수 등 관리정보를 가진다.
슈퍼블록(UFS), 혹은 NTFS(마스터 파일 테이블)
-
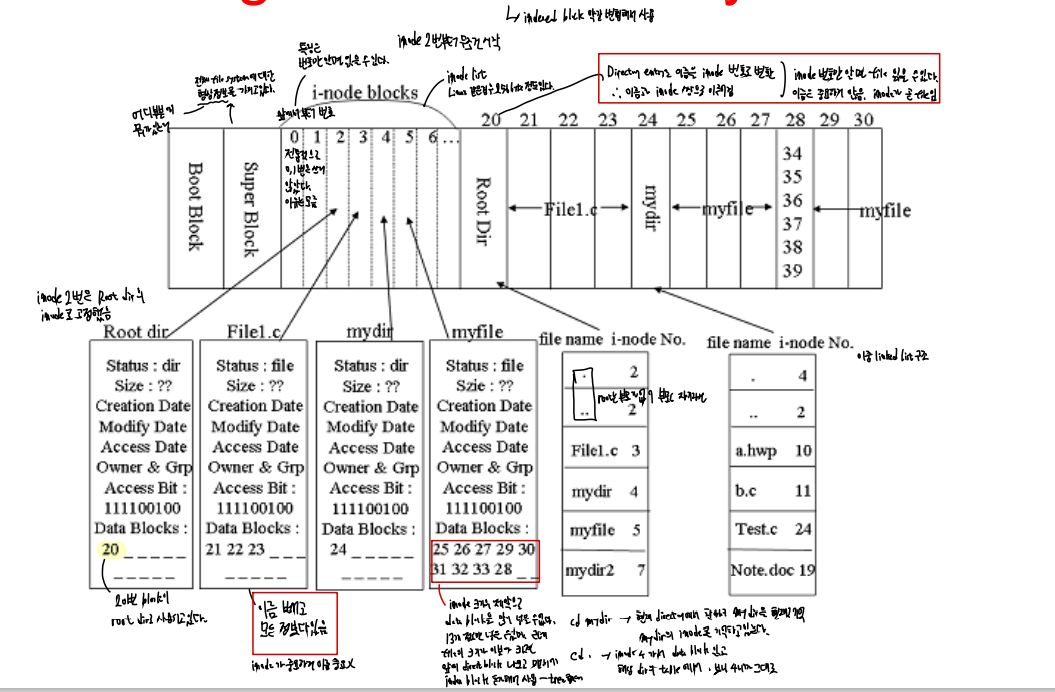
디렉터리구조
INODE에서는 그냥 파일에
NTFS에서는 마스터파일테이블에
-
파일에 대한 자세한 정보
INODE에서는 INODE안에
NTFS에서는 마스터 파일 테이블 안에
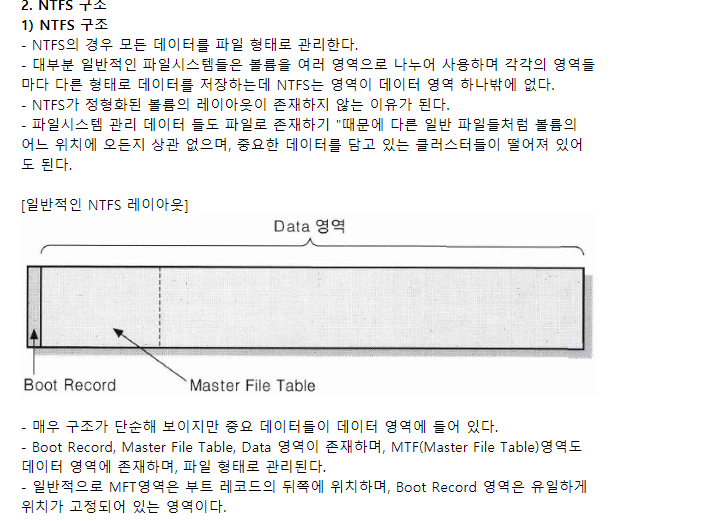
메모리 내에 담고있는 파일구조
- global file table : FCB파일의 복사본이지
- process file table : global file table에 대한 포인터
- 버퍼는 파일시스템 블록을 저장
- 파티션 테이블 : 마운트된 모든 파티션들
- 디렉터리 구조 : 디렉터리 파일들을 캐싱하는 용도
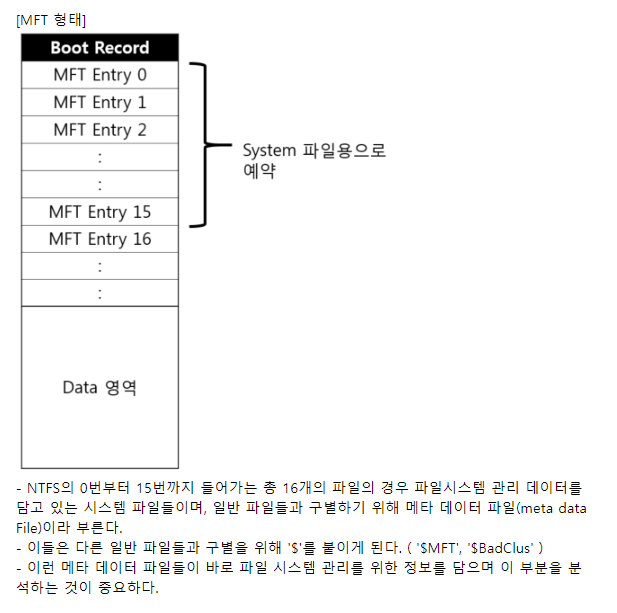
FCB의 간략 구조
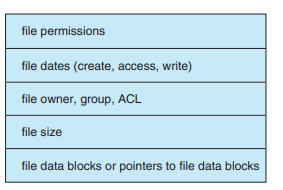
시스템 콜 구현 구조
오픈
-
논리적 파일 시스템에 파일 이름을 넘긴다
-
글로벌 파일테이블이 열려있는지?를 확인한다.
-
안 열려있으면, 주어진 파일 이름을 디렉터리에서 찾고,
그거 에 대한 FCB를 가지고 온다.
-
그리고 글로벌 파일 테이블에 이걸 연다.
-
그 후, 접근 모드나 포인터 항목에 대한 거를 채워서 프로세스 파일 테이블에 연다.
-
오픈을할때캐싱하네
-
그리고, 해당 파일테이블의 포인터를 리턴한다.
리드
- 리드를 하면, 그냥 프로세스 테이블에서 긁어다가 일겅버리면 되요.
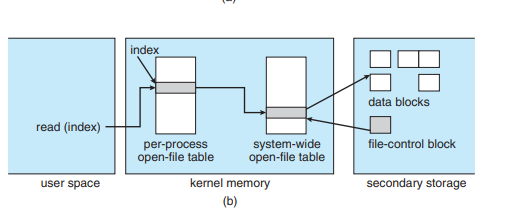
디렉터리 구현 방법
- 디렉터리라는 것은, 확대해서 생각해보면, 파일에 대한 FCB들을 저장해놓는 그런 곳이다.
선형 리스트로 그냥 아이노드 블락을 쭉 늘어놓는 방법
- 파일찾기위해 선형탐색
- 정렬리스트하면 좋긴 한데, 오버헤드가 크긴 할 수 있다.
- B트리가 이럴 때 도움이 될 수도,.
해시테이블
- 당연히 속도는 킹왕짱 먹는다
- 고정된 크기를 갖는 문제점
- 체인을 쓰면 해결하긴 하는데,, 그래도
파일들을 저장하는 방법
연속할당
- 그냥 1번이 1번이고, 2번이 2버이고,,,
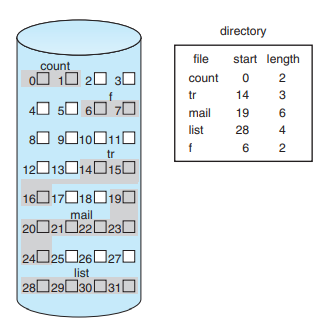
-
Start + Length로 구현한다.
-
순차적으로 저장되는게 진짜 개 큰일 아니겠니?
외부단편화,,
-
파일 직접접근 가능
연결할당
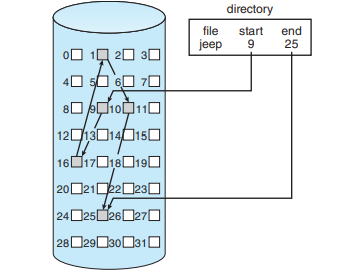
-
순차접근은 존내좋은데
-
외부단편화도 없다.
-
직접 접근은 정말 큰일난다.
-
클러스터 기법
그냥 블록 4개 쌍으로 I /O
포인터 적게 참조하므로 개이득
하지만 내부단편화
게다가 작은 데이터들을 다룰 떄는 비효율 적일수도 있따.
신뢰성의 문제가 있을 수 있다.(포인터가 끊기면 폭망)
-
한가지 중요한 변형인 FAT
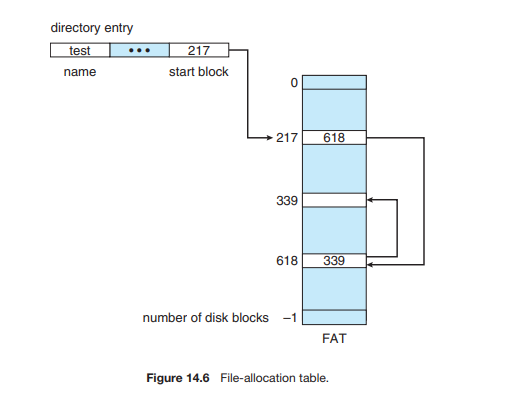
그냥 진짜 저거만 가지고 메모리에다가 주소만 넣어 놓는 것.
엄청난 램 소모량 예상된다.
색인할당
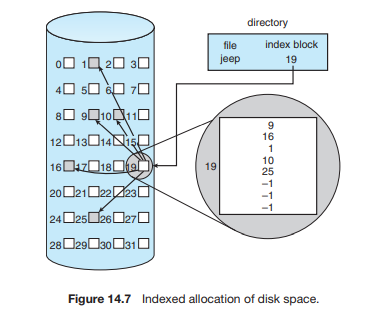
-
요게 아이노드랑 비슷하다 이말이지
-
크기가 제한적이기에 여러가지 기법을 이용한다
-
연결기법, 101번째는 다음 블록인거
-
다중 수준 색인, 그냥 첫번째 보이는 거는 다음 레벨의 블록을 가리키게 되는
-
12개는 직접, 3개는 간접
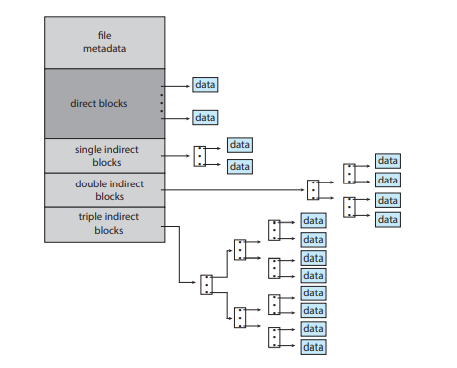
→아이노드
-
최적화방법
- 작은 파일은 연속할당, 아니면 색인 할당이렇게 결합해서 효율적으로 구현하던가,,
- 색인할당은 문제가, 직접접근 영역이 굉장히 작다는 것.
가용공간의 관리
비트벡터
-
블록이 비면 1, 채워지면 0
-
메인 메모리에 이게 다 올라와 있어야 함.
-
모든 공간에 대해 이거를 가지고 있다는 것이 비효율적일듯
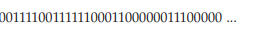
연결리스트
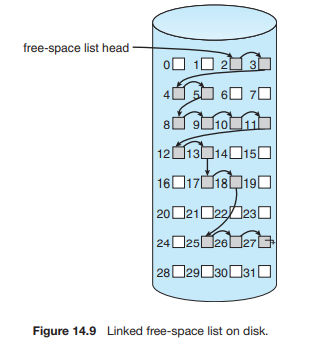
- 오버헤드가 심할거라 생각할 수도 있는데, 어차피 첫번째 블록만 잘 사용하는 편이야
그루핑
- 저 블록의 다음이 그냥 바로 가리키는게 아니라, 100개는 실제로 비어있는 블록의 이름, 마지막 블록은 다음 블록
계수(counting)
- 그냥 ,블록주소 10에 가용공간 5 이렇게 저장하는 일
성능향상방법
Inode
- Inode와 그에 해당하는 데이터블록을 붙여놓아서 성능 향상 (같은 실린더 그룹이라던가,,)
- 혹은, 아이노드를 미리 할당하고 이를 여러 디스크에 분할해서 성능 향상
클러스터로 여러개의 블록을 한번에 fetch하기. 내부단편화를 버리지만 그래도 속도는 빠르게 뽑는다.
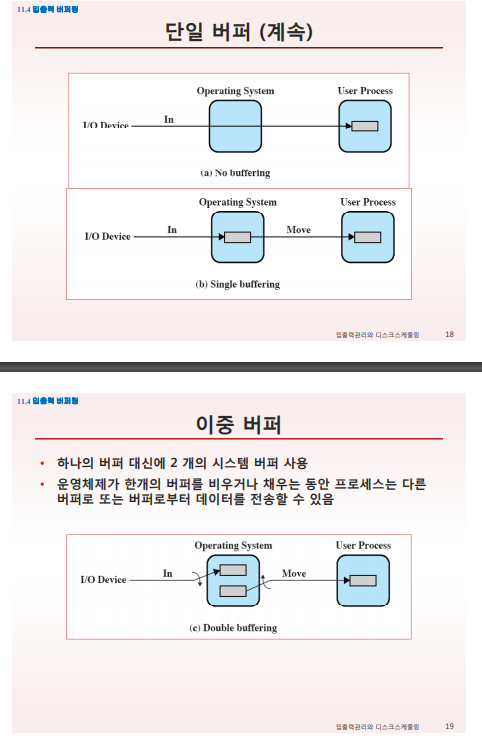
캐시
-
입출력장치들은 블록에 대한 캐시를 가지고 있다.
따라서, 회전지연 기다리지 않아도 데이터를 fetch할 수 있다.
디스크 암 이동 최소화
- 연속된 블록들로 할당하는게 아니라, 시스템에서는 1KB로, 디스크는 실제 2KB단위로 관리 →시스템에서는 1KB로 사용하지만, 실제로 디스크는 2KB씩 왔다갔다 하기 때문에 DISK I/O가 감소할 수 있다.
- 4-29에서처럼, 아이노드 블록과 동일한 실린더 그룹을 가지면, 개꿀이다. 바로바로 찾기가 가능.
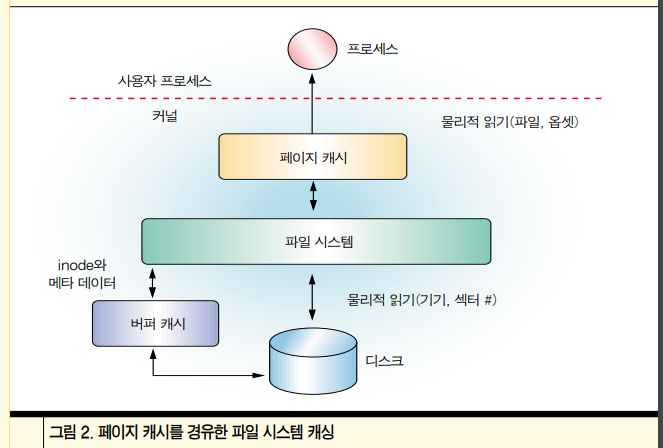
페이지캐시
-
페이지캐시를 하면
굉장히 빠르게 쓰기를 할 수 있다. 나중에 실제로 디스크에 대입하면 되니까.
-
페이지 캐시 최적화
블록 미리 읽기 정책 사용 가능
k번째 블록을 읽어 오면, k+1도 읽어 올 수 있따.
물론 순차 파일에만 효과
따라서, 랜덤 파일의 경우는 사용 X
통합버퍼캐시와 페이지캐시
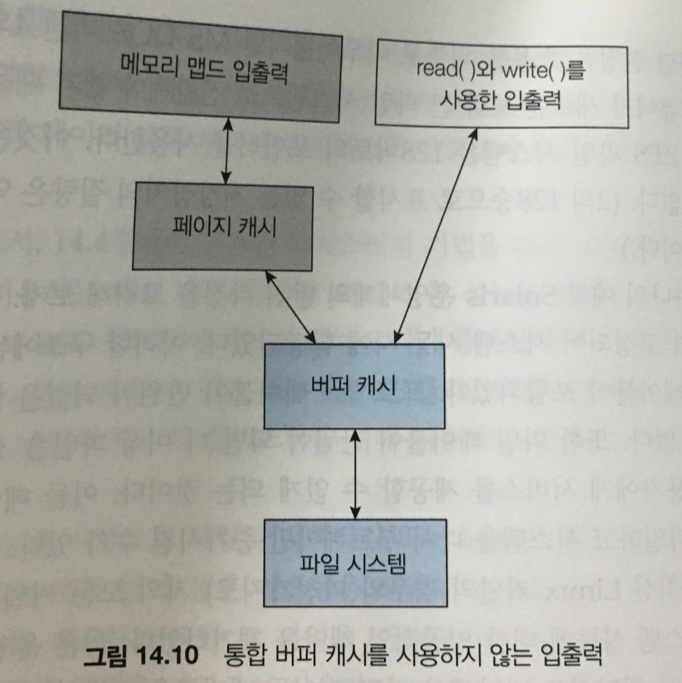
-
일부는 페이지캐시(파일자체를 페이지에캐시해서 빨리쓰기)
-
read,wrtie 입출력을 하기 위해서는, 실제 드라이버에 꽂히는 버퍼캐시가 필요하게 된다.
그러기 위해선, 페이지캐시가 버퍼캐시로 가야 된다는 것.
-
그러면, 결국 이중캐싱이 되고 개손해가 된다.
-
그러니까, 이거 두개를 합쳐서 하나의 캐시로 만들어야지 손해가 덜하다.
>>>>솔직히 여기부터는 잘 모르겠따.<<<<<
디렉토리 관리
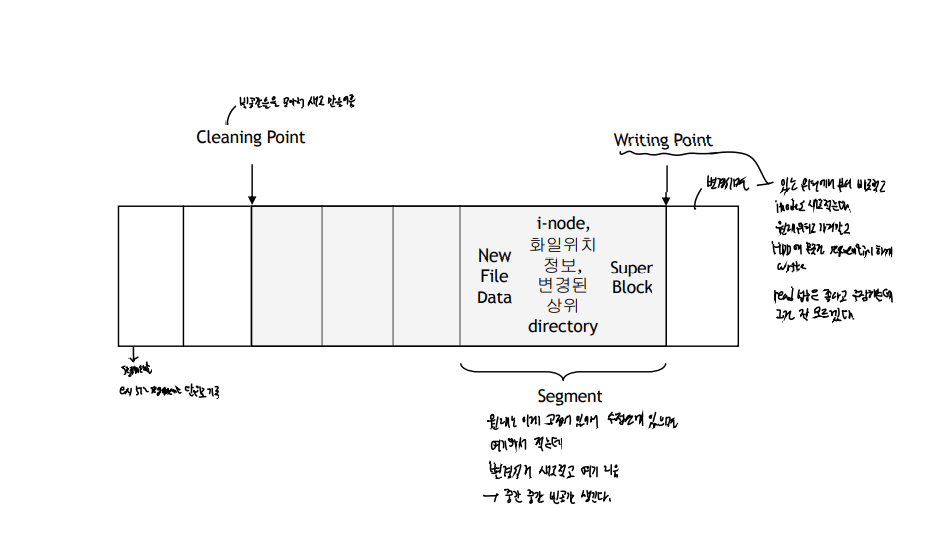
LFS
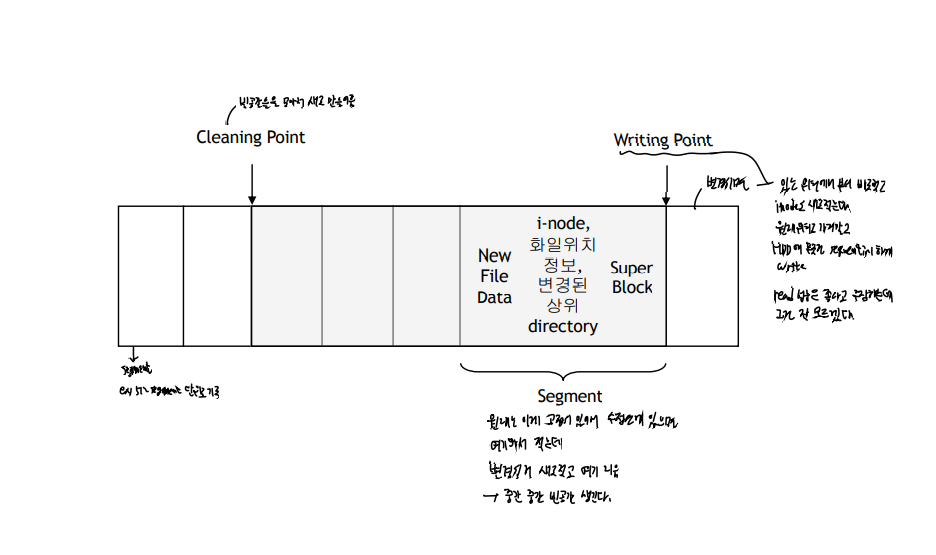
sequential writing을 지원하기 위함
먼저 메모리에 버퍼링하고,
어느 정도 세그먼트가 차면 이를 블록에 저장한다. 그리고 이 때, 새로운 inode 블록의 위치를 함께 저장한다. 만약 writing이 일어난다면, inode에 갱신이 일어나고 이 복사본이 다른 inode 블록에 지정된 후 포인터가 지정될 것이다.
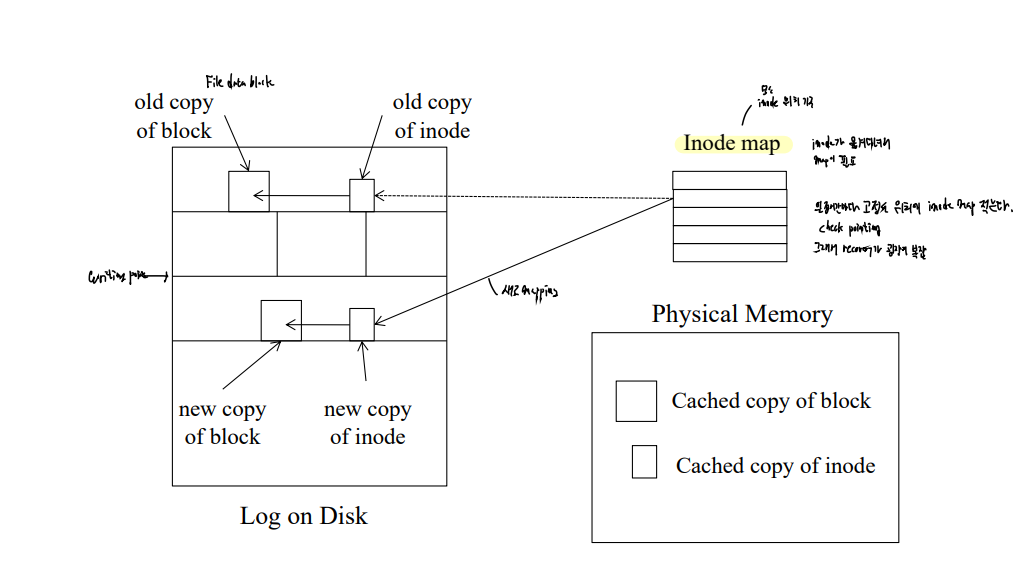
-
inode가 고정된 위치에 있지 않기 때문에, inode 블록의 위치를 지정하는 inode map이 따로 있다.
메모리에 쓰기가 발생할 때 마다, 해당하는 inode의 포인터들을 아이노드 맵에 저장합니다. 이렇게 떨어진 애들을 관리하기 위해서, 하나의 아이노드 체크포인트가 있고, 이거는 모두 메모리에 저장될만큼 작다.
-
할당이 풀린 애들은,
copying으로 한 곳으로 밀어넣던ㄷ가, 아니면 구멍이 뚫린 곳을 연결리스트로 이어서 사용한다.
-
새그먼트클리닝(외부단편화 최소)
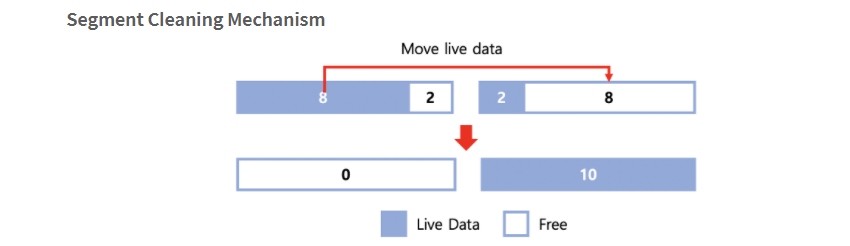

클리너쓰레드가 존재해서, 아이노드를 모두 검사해 현재 해당 블록이 유효한 블록인지를 검사하고, 만약 해당 새그먼트(아이노드 맵 + 블록)의 정보가 현재 유효하지 않다면, 제거한다.
- 언제, 어떤 데이터가 쓰여졌는지 확인 가능하기에, 시간대만 보고 크래시를 회복할 수 있다.
JFS..
파일 삭제 시 상황을 확인하자.
- 파일을 디렉터리에서 삭제
- I-node를 가용 i-node로 반환
- 파일이 차지하던 디스크 블록을 반환
1,2 와 2,3 사이에서 crash가 일어난다고 하면,
1~2 : inode가 낭비되고, 파일은 확인이 안 된다.
2~3 : inode는 없어지고, 블록에서 확인이 불가능 하다.
그렇기에, JFS에서는 1,2,3을 로그를 다 써 놓는다. 그리고 만약 크래쉬가 일어나면, 그냥 1,2,3을 다 다시 한다. 이렇게 다시 해도 전혀 문제가 없는 연산이여야 한다.
그리고 1,2,3을 완전 끝내면, 로그를 지운다.
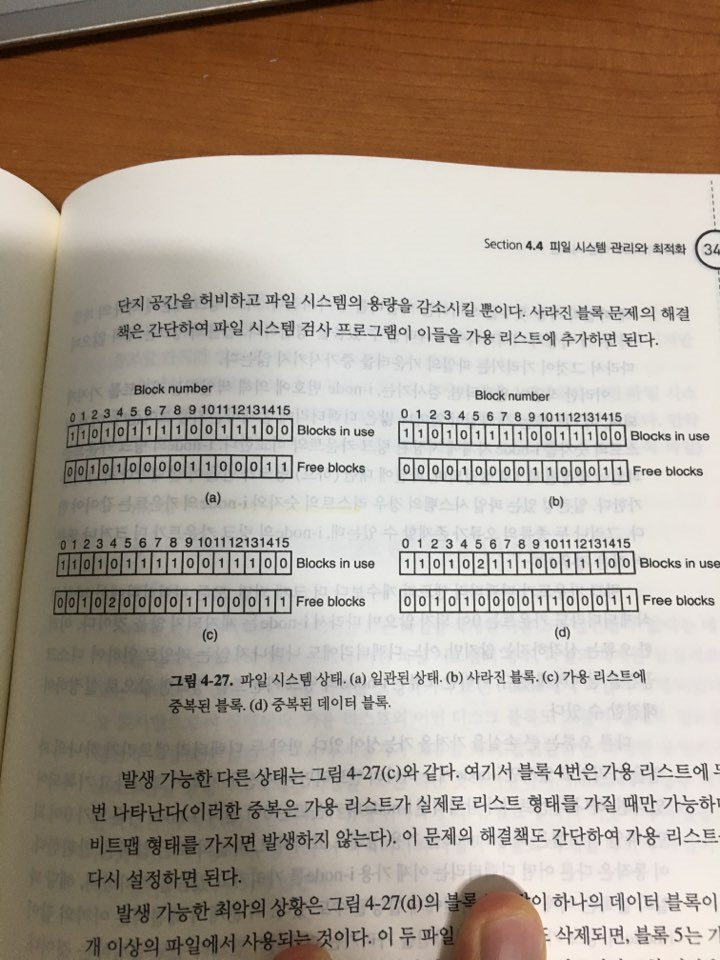
파일 시스템 일관성
그림 4-27와 같이,
두개의 array를 만들어 일일이 블록을 검사한다.
하나는 inode에서 가용한 블록을 하나씩 찍는 것
나머지 하나는 free block에서 하나씩 찍는 것
두 개가 매칭이 안되면 문제있다.
점진적백업/전체백업
- 점진적 : N, N+1, N+2
FFS
- 같은 실린더 그룹에 super block이라던가, inode 리스트 등을 배치해가지고 성능을 강화시킨거

- 크기가 큰 파일들은 인접실린더로 던진다.

-
기본적으로 아이노드 방식이다.
-
디스크의 논리-물리블록 번호를 이런 식으로 매핑해서, sequential read 성능을 극대화 했다.
-
fragmentation을 이용해서(블록보다 더 작은 단위) 메모리 버리는 걸 최소화했다.
-
기존 슈퍼블록 기반의 S5FS에서 발견되었던, 슈퍼블록이 깨지면 큰일나는 문제 해결
아이노드 블록을 새 디렉토리는 멀리, 가까운친구들은 가까이 배치했다.
→ 여러 곳에 분산 배치. 실린더 그룹별로 분산 배치
-
디렉토리 내의아이노드를 확인하기 위해 너무 긴 시간이 걸렸던 문제를 해결했다.
→ ls -l 시, 곳곳에 흩어져있는 아이노드를 다 읽어야 하기 때문에 엄청난 성능 저하.
→ 디렉토리 내의 아이노드는 인접 실린더 그룹에 배치
-
아이노드에 대한 테이블과, 실제 데이터를 비슷한 곳(실린더 그룹)에 배치아이노드에 대한 테이블과, 실제 데이터를 비슷한 곳(실린더 그룹)에 배치
S5FS
- 단점은, 슈퍼브록 깨지면 간다.
EXT3
-
실린더 그룹이 아니라, 블록 그룹으로 나누었다.
실린더 그룹으로 나누게 되면, 실린더 그룹마다 용량이 다르기 때문에 적절하지 않다.
-
블록들은 1,2,4,8KB등 다양하다
-
파일 할당 시, 블록그룹을 선택하자. 아이노드는 블록그룹 내에 존재하고, 할당도 동일블록그룹으로 간다.
-
디스크 부하를 줄이기 위해 디렉터리를 널리 분산시키는 일이 많다.
검색 시
-
먼저 가용 바이트를 찾고, 실패하면 그 다음에 가용 비트를 찾는다.
바이트 단위로 할당을 하기 위함.
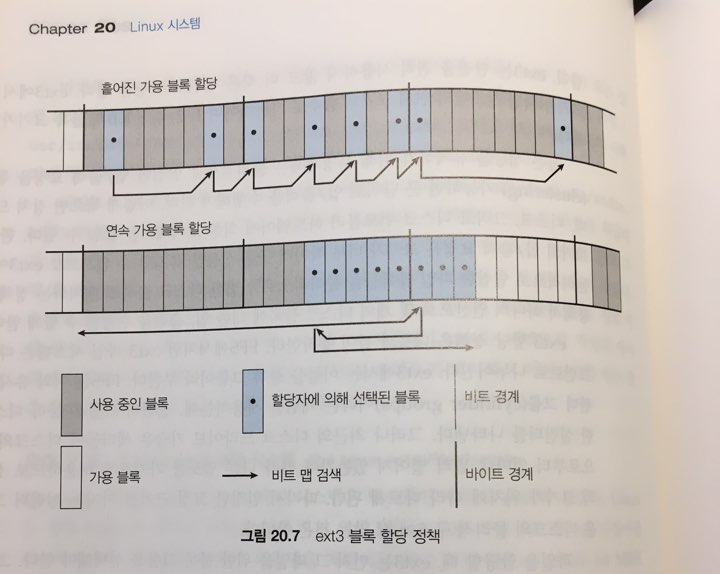
-
그냥 쭉쭉 찾는다.
ACL
- 지금 보여주는 거는 유저마다 모든 거에 다 거려있음
- 얼마나 귀찮냐,, 그래서 지금 유닉스같은ㅇ,,



LOST+FOUND FOLDER
e2fsck가 확장버전이기 때문에 실질적으로 현재 리눅스 배포판에서 fsck명령 실행하면 e2fsck가 실행돼요.
fask명령은 손상된 디렉터리나 파일을 수정할 때 임시로 /lost+found 디렉터리에서 작업을 수행하고 정상적인 복구가 되면 사라집니다.
fsck 명령어를 수행하면 내부적으로 동작 단계는 다음과 같습니다.
https://t1.daumcdn.net/cfile/tistory/997C86455C48CBE20F
시작
단계1 - 블록들과 파일 크기 검사
단계2a - 중복된 이름이 있는지 검사
단계2b - 경로명 검사
단계3 - 연결성 검사
단계3b - Shadows/ACLs 인증
단계4 - 참조 수 검사
단계5 - 싸이클 그룹 검사
