
스케줄링
CPU Burst, I/O Burst
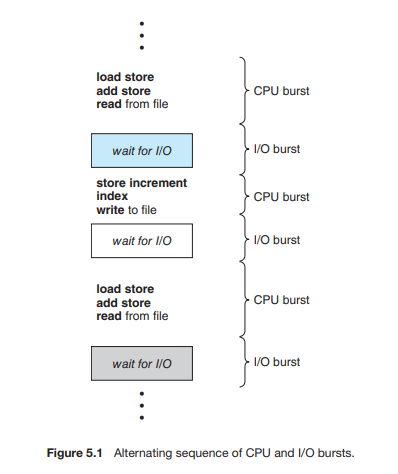
스케줄링 발생 상황
- I/O wait 등으로 물러나면,,
- 실행 상태에서 준비 상태로 바뀔 때(인터럽트라던가,,)
- 대기상태에서 준비상태가 될 때(I/o wait 등에서 복귀할 때)
- 종료될 때
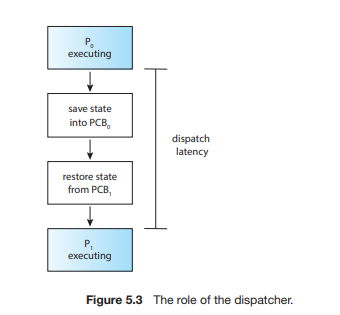
디스패처
- 매커니즘
- 다른 프로세스로 실행 흐름을 넘기는 모듈
각종 명령어

- 딱 보니 I/O bound

- 처음 1초, 직전 1초전, 직전 2~1초 전
지표들
- CPU 이용률 : CPU를 얼마나 바쁘게 유지하는지
- 처리량(throughput) : 단위 시간동안 처리한 프로세스 개수
- 응답시간 : 응답에 걸리는 시간, 응답을 출력하는게 아니라, 사용자가 뭐를 보냈을 때 그거에 반응하기 시작하는 시간
- 대기시간 : 준비큐에서 대기하는 시간 (I/O 대기 큐는 I/O 시간이다)
- 총 처리시간(turnaround time) : 제출부터, 완료까지, 즉, 모든 시간을 합침. 기다리는 시간까지도
스케쥴링 기법
복권
그냥, A 40개, B 20개, C 10개면 그냥 랜덤뽑기하는거지
FIFO

- 들어오는 순서에 따라 대기 시간(즉, 실행 말고 대기시간)이 끔찍해 질 수 있다.
- CPU 바운드가 먼저 들어오면 개끔찍함
SJF
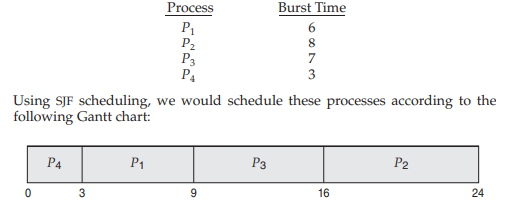
-
무조건 빨리 끝나는 아이 먼저
-
짧은 프로세스를 빨리 끝내면 전체적으로 대기시간이 줄어들 수 밖에 없다.
a,b,c,d 순으로 정렬되어 있다면,
a+b+c가 최소가 아니라면,
증명
만약 이거보다 빠른 방법이 있다고 하자
몰라!
-
실제로 CPU버스트를 예측하기가 너무나도 어렵기 때문에, 사용하기 힘들다.
-
일반적으로, 지수평균을 이용하여 구한다.
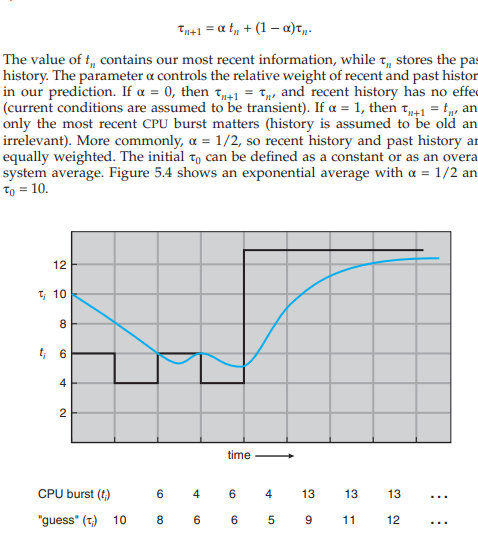
shortest remaining time first

- 비선점형 SJF라고 생각하자
RR

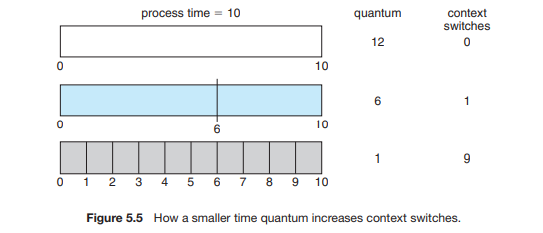
-
time slice가 무한대라면, FIFO이다.
-
쓸데없이 타임슬라이스가 커지면, 문맥교환 코스트 때문에 손해를 볼 수 있다.
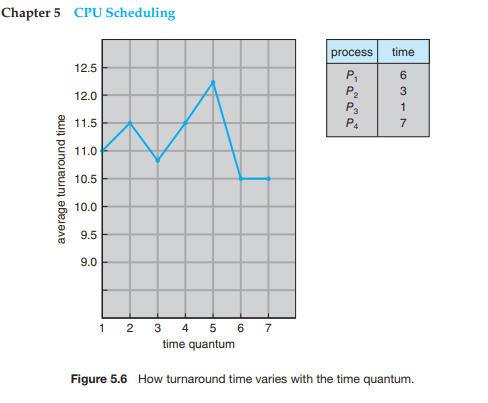
-
80%정도의 프로세스들의 CPU 버스트 타임(즉, 한번 받았을 때 하는 것)이 타임슬라이스보다 짧아야 한다.
우선순위 스케줄링
-
SJF는 우선순위를 짧은 거에 몰빵한 거라고 생각하면 될 듯
-
여러가지 고려할 면이 있다
내부적
-
시간 제한, 메모리 요구, I/O 버스트와 CPU 버스트의 시간 비율
외부적
-
비즈니스로직
-
-
비선점형, 선점형 모두 되겠지. 선점형에서는 그냥 우선순위 높은 아이한테 뺏겨버릴듯
-
무한봉쇄, 기아상태
우선순위 낮은 애들이 너무 밀려버린 것
에이징을 통해서 해결한다
멀티레벨 다단계큐
- 우선순위 스케쥴링을 하기 위해 o(n)의 검색시간이 필요할 수 있기 때문에 다른 방법을 고안했다.
멀티레벨 피드백 큐
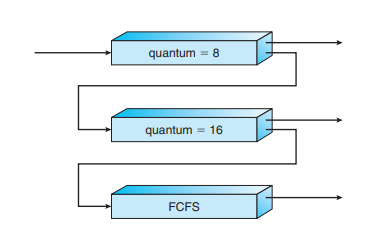
- 시간 할당량을 다 채우면, 다음으로 넘어간다
- 마지막 큐는 FIFO방식으로 작동하기도 함.
- 너무 오래동안 머무르면 다시 승격시킮 수도 있음. 이건 정책에 따른다.
스레드의 스케줄링
경쟁 범위
-
PCS(프로세스 내부에서 가용한 LWP를 이용해서 경쟁)
-
SCS(프로세스 외부, 시스템 전체에서 커널스레드를 할당받기 위한 전쟁)
당연히, 1:1 모델을 쓰면 SCS만 하겠네
코드

- 위에 거를 하게 되면, 해당 스레드가 커널스레드와 LWP의 할당을 받아 움직인다.
- 아래 거를 하게 되면, 그냥 스레드 내에서 경쟁한다.

리눅스, 윈도우
- 프로세스 내에서 움직인다.
스케줄링 기법 선택 가능
- 동일하게, FIFO 혹은 RR 선택 가능. 운영체제 마다 제 3의 스케줄링 기법을 제공하기도 한다.
다중 처리기 스케줄링
- 현대에는 각 CPU 칩이 여러 개의 코어로 나뉘어 있어서 여러 개의 CPU를 가진 것 처럼 보인다.
비대칭에서 그냥 쓰는 oblivous scheduling

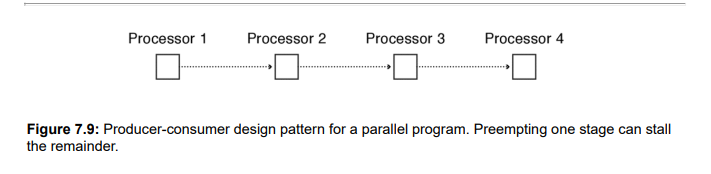
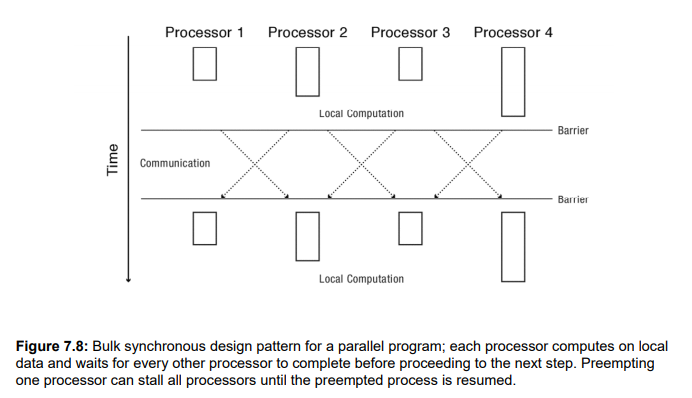
- 되는대로 쓰면, 병목이 심해질 수 밖에 없다.
갱 스케쥴링
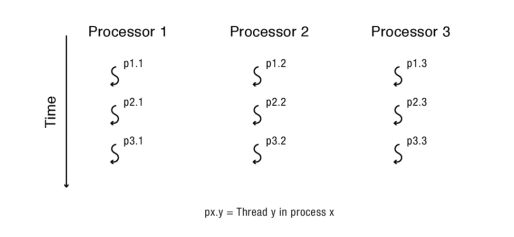
- 생각을 하고 쓰레드를 나눈다.
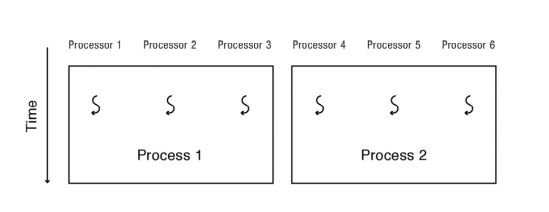
-
암달의 법칙에 따라,
그렇기에, 두 개의 프로그램을 한번에 돌려야 한다면, 두 개의 프로그램을 시간 순으로 나눠서 하는 것보다, 프로세서를 반반띵해서 동시에 돌리는게 차라리 효율이 좋다. (time sharing → space sharing)
대칭/비대칭
-
대칭 : 그냥 다(SMP)
-
비대칭 : 하나의 코어에만 커널, 나머지는 다 사용자 공간
쉽지만 병목
준비 큐의 구조
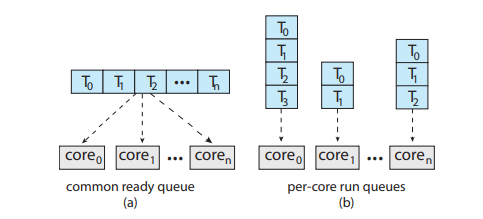
-
왼쪽 : 공유자원이 중간 것이므로 락에 의한 성능 저하 심각할 수 있다.
-
오른쪽: 균형이 안맞을 수 있다.
-
로드밸런싱
push(빈 곳으로 밀어넣기),pull(빈 곳이 땅겨오기) 방식
캐시 어퍼니티 고려해라
또한 따로관리되기에 공유메모리의 접근성도 고려해야 하고,
캐쉬일관성문제도 존재한다는것.
하이퍼 스레딩
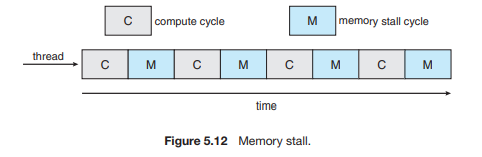
-
기존 문제점
어떤 프로세스를 실행할라 치면, 메모리를 기다리는 시간 때문에 아무것도 못한다
-
그러니까, 이렇게 하드웨어 실행흐름을 두개를 만들어서, 실제 컴퓨팅을 안할 때는 다른 스레드로 점프하게 하자.
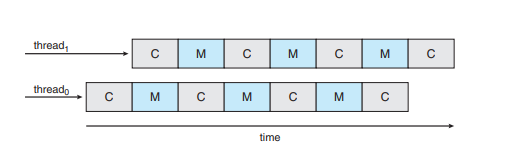
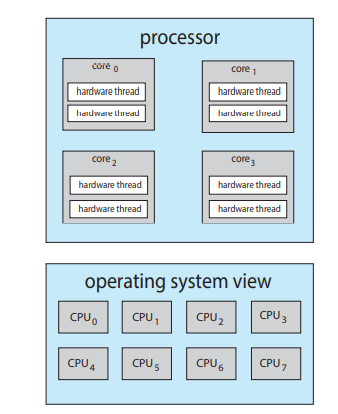
-
컴퓨터의 입장에서는, CPU가 많은 듯이 보이게 된다.
-
coarse 쓰레딩
그냥 지연시간 긴 거 만나면 싹 다 갈아 엎고 다시 함
쓰레드 문맥교환에 시간이 좀 걸린다
-
세밀한 쓰레딩
뭔가 경계점에서 이렇게 잘 중복시키고 하는,,
추가적인 하드웨어 필요
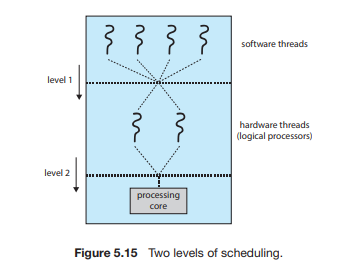
-
실제 하드웨어까지 문맥교환에 참여하게 되는,,
같은 코어에 두 개의 쓰레드가 병렬적으로 실행되는 상황이 안 나오게끔 해야 겠다.
이기종 다중처리
- 모바일 에서 사용
- 저전력부와 고전력 부를 나눠서 따로 스케줄링
- big.LITTLE 아키텍쳐, LITTLE 부분에다가 백그라운드 서비스 등을 스케줄링 시키면 전력을 아낄 수 있다!
캐시 어퍼니티
- work conserving vs non-work conserving
- 한 프로세서에서 실행되던 프로세스가 다른 프로세서로 이주하면 캐시 어퍼니티가 심각하게 떨어진다.
- 공통 큐를 사용하면 캐시 어퍼니티 바닥이고, 각각의 큐를 사용하면 캐시어퍼니티 높아진다.
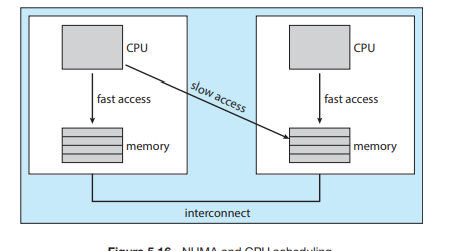
실시간 스케줄링
- 연성 : 그냥 빠르게만,,
- 강성 : deadline이 존재
지연 시간
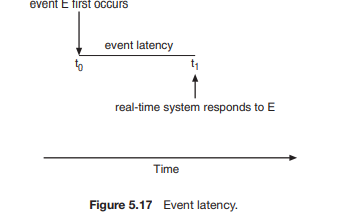
지연 시간 결정 요인
- 인터럽트가 실행되기 전 까지
- 필요한 프로세스가 실행되기 전까지
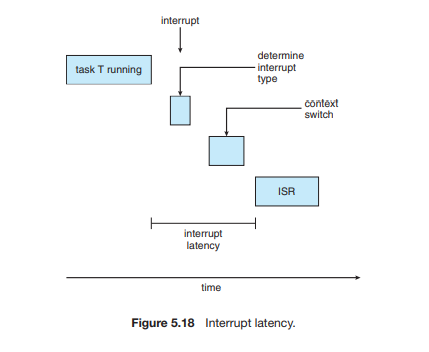
- 인터럽트 지연 시간
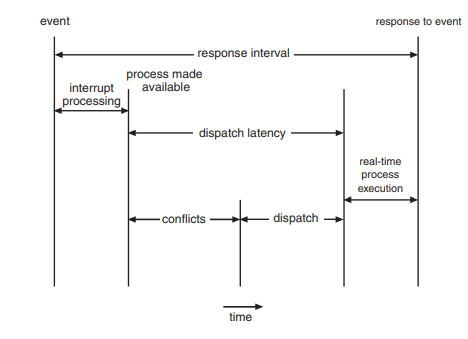
- 디스패치 지연 시간
우선순위 기반 스케줄링
- 이전에 배운 거는, 그냥 우선순위가 높은 거를 지정해줄 뿐
- 여기서는, 강성(hard)하게, 제한시간 안에 요청을 처리해야 함.
프로세스들의 특성
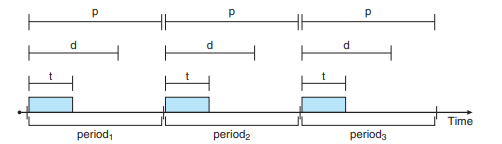
- 주기 p 시간 안에, d라는 제한시간(마감시간) 안에 처리되어야할 태스크 의 양(양적으로의 시간)t가 들어온다.
- 이 말은 뭐냐면, 몇 초 마다 얼마 안에 자기께 수행될 시간을 가져야 한다는 것.
레이트 모노토닉
- 낮은 우선순위를 가진 테스크가 실행 중에 높은 우선순위를 가진 프로세스가 들어오면 선점당한다
- CPU 이용을 더 자주(많이가 아니라)하는 쪽에 우선순위를 부여한다.(즉, 주기가 짧은 쪽)

첫번째그림 p1은 주기 50, t1은 25, p2는 주기 100, t2는 35
-
모든 테스크의 필요한 CPU버스트 시간/주기 를 해서 100 이하면 사용 가능하다
만약, 10개가 10 cpu 버스트 시간마다 100마다 필요하다면 100%이므로 딱 사용 가능
하지만, 항상 사용 가능하지는 않다. CPU가 100%를 이용할 수 있다는 보장이 없기 때문에
이상한 식도 있다.
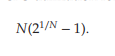
얼리 데드라인 퍼스트(EDF)
- 프로세스가 미리 마감시간을 시스템에 알린다.
- 데드라인이 얼마 남지 않은 프로세스를 먼저 끝낸다.
- 주기 개념이 필요 없다.
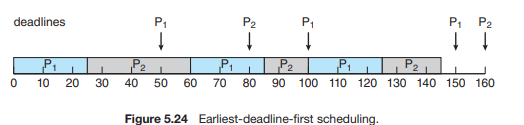
p1의 주기 50, t1 25, p2의 주기 80, t2는 35
- 항상, 프로세스가 들어온 시점에 데드라인이 얼마 남지 않은 프로세스가 선점한다.
- 이론적으로 최적이다.
일정 비율의 몫 스케줄링
- 그냥 일정 주기 안에, A,B,C가 얼마나 실행될 건지 말함. (50,30,20처럼)
- 만약, 100을 넘어버리는 프로세스가 들어오면 짜른다.
리눅스 스케줄러
o(1) 스케줄러
- 마치 멀티 레벨 피드백 큐 처럼, 다음 스케줄링을 할 때 필요한 시간이 상수시간이다.
- SMP에서도 다중 큐를 이용해서 어느 정도 성능을 보여줬지만,
- 대화형 시스템에서 느린 응답속도를 가졌었다.
CFS 스케줄러


-
각 프로세스는 우선순위(nice)값에 따라, vruntime 값이 바뀐다.
디폴트면 200ms 시간되면, 200ms 실행되었다고 말하지만, 우선순위가 높다면 200ms 실행되어도 200ms보다 작은 시간을 실행되었다고 구라친다.
-
가장 작은 vruntime 값을 가진 프로세스가 스케줄링 된다.
이 부수효과로, I/O 태스크가 우선순위에 상관없이 vruntime 값이 작아지게 된다.
-
RB트리를 사용한다. 가장 왼쪽 값이 스케줄링 되며, logn시간이 필요하지만 이 값만 캐쉬로 떼놓는다.

-
이렇게, 실시간 프로세스는 따로 스케줄링을 받고, normal 프로세스는 -20~19까지의 CFS 스케줄링을 받게 된다.
-
로드밸런서도 정교하게 구현한다.
-
단순하게 프로세스의 양을 보는게 아니라, CPU 이용률과 우선순위를 중심으로 본다.
CPU 이용률이 높으면 → 부하가 크다
우선순위가 높으면 → 부하가 크다
따라서, CPU이용률이 높고, 우선순위가 낮은 프로세스와 CPU이용률이 낮고 우선순위가 큰 프로세스는 부하가비슷하다.
-
NUMA 노드 안에서 구현된다.
계층적으로, 하지만 이 밖으로는 안 나게끔 해서 캐쉬친화도를 유지한다.
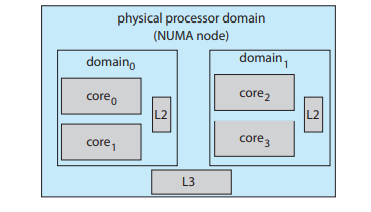
-
윈도우의 스케줄링
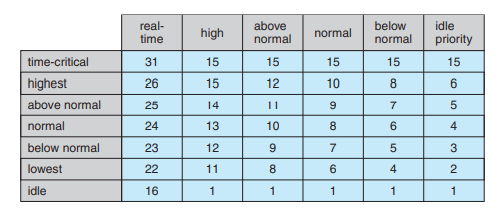
16~31 : 실시간 프로세스
1~15 : 가변, 우선순위 프로세스
-
스레드의 타임퀀텀이 끝나면, 스레드의 우선순위가 낮아진다. 계산에게 덜 주기 위해서이다.
하지만, 디폴트보다는 낮아지지 않는다.
-
어떤 대기에서 풀려나게 되면, 무얼 위해 대기했느냐에 따라 우선순위를 다르게 준다.
I/O 였으면 크게,, CPU 계산이였으면 작게...
-
fore ground와 background의 시간할당량이 3배정도 차이나게 한다 → 응답성 향상
-
사용자 모드 스레드 스케줄링 도입했다.
-
동일한 논리 프로세서 집합에서 실행되도록 했따. (이전의 NUMA와 비슷하다)
솔라리스
지랄
알고리즘의 평가
지랄
큐잉모델
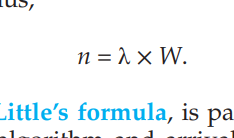
- N는 : 현재 사람의 수
- 감마는 : 시간
- W는 : 시간에 비례하는 들어오는 속도
평균 대기시간 동안에 들어오는 프로세스의 개수를 곱하면, 큐의 길이가 된다.
O(1)


