
가상 메모리
배경
-
가상 주소공간을 사용한다는 거랑 또 다른 이야기이긴 하다.
-
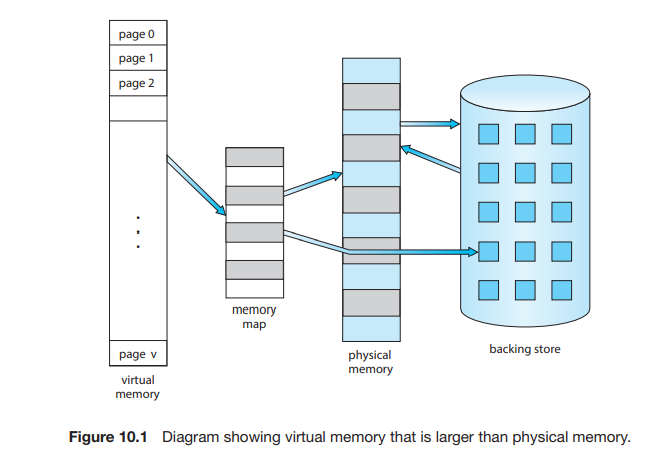
프로그램이 항상 모두 메모리에 올라올 필요는 없다.
예외처리 디버그를 위한 코드같은게 필요는 없잖아.
배열같은것도, sparse할 수 있다.
-
메모리 제약을 적게 받으면서 여러 프로그램을 올릴 수 있다.
throughput과 cpu 이용률이 높아질 수 있다.
-
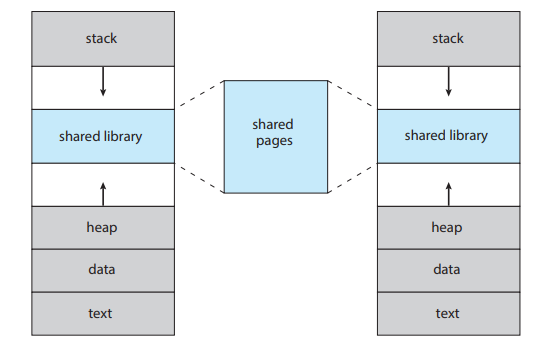
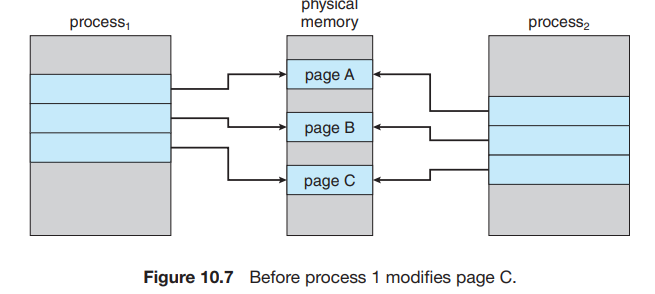
실제로 공유메모리 관리도 편해진다.
실제로는 자신의 일부라고 생각하지만, 사실은 같은 거를 가리키고 있는.
-
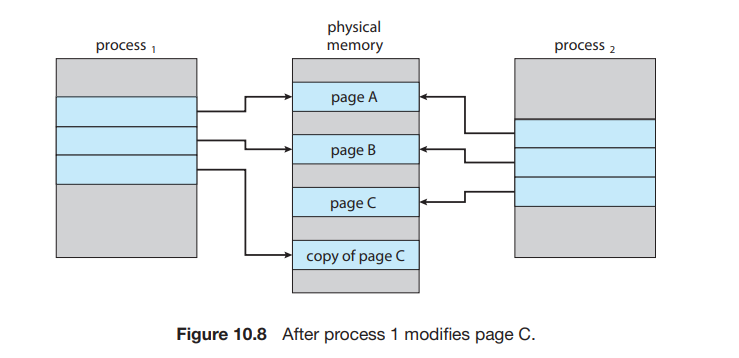
fork 시에 copy-on-write도 구현하기 쉬워진다.
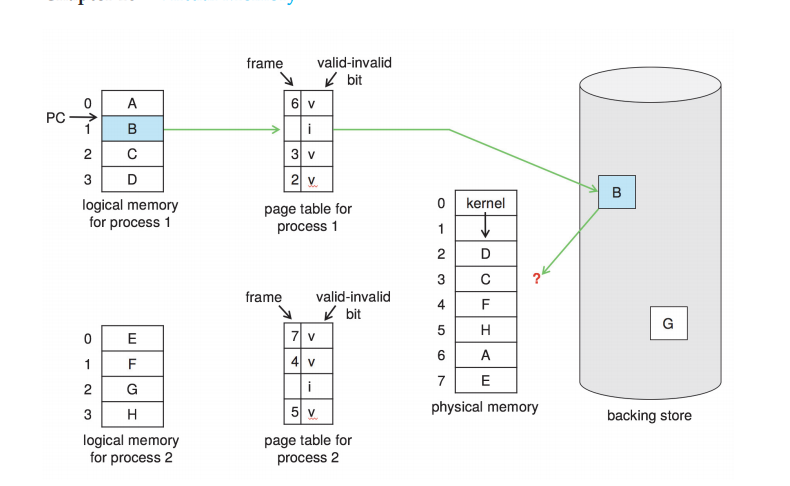
디멘딩 페이지
기본 개념
-
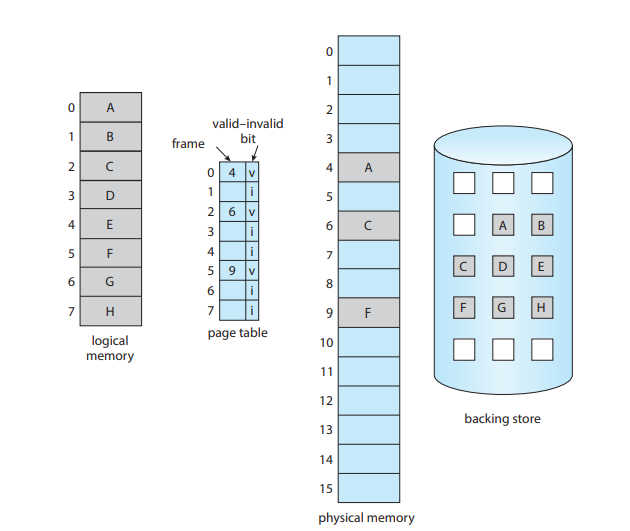
필요할 때만 적재
-
backing store를 스왑공간이라 한다.
-
메모리의 v, i를 이용 이용
-
메모리에 없는 (invalid) 메모리를 접근하려고 하면 page fault가 걸린다.
-
극단적으로, 메모리에 아무 것도 없어도 프로세스를 실행 가능하다.
이런 걸 순수 요구 페이징이라고 하는데,
극단적으로 느려진다.
페이지 폴트 핸들링
-
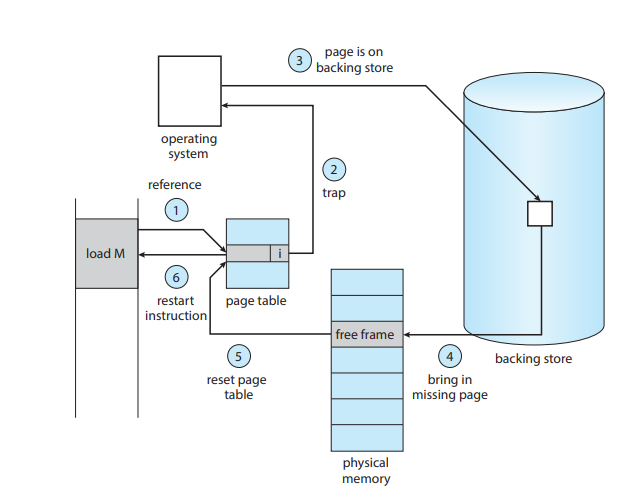
추가적으로 처음에, 권한등을 통해 해당 메모리 참조가 유효한 지를 판단하고, 만약 유요하지 않다면 트랩을 걸어서 애초에 시작을 못 하게 해야지.
-
페이지 폴트 발생 시, 명령어가 실행되다가 멈추고 재실행 될 수 있어야 한다.
block transfer 명령어(A블록의 정보를 B블록에 전송)을 하다가 만약메 페이지 폴트가 일어났다고 해봐. 다시 돌아와야 하는데, 처음부터 어떻게 하냐,,?
레지스터를 이용해, 어디까지 썼는지를 기록해 놓는다.
-

- 트랩을 걸고
- 현재 프로세스 상태를 저장하고
- 페이지 폴트 핸들링인지를 확인하고
- 안된다면 read for swap to a free frame을 시도하고
- 그 동안 다른
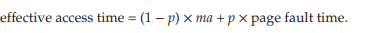
-
성능을 위해서 어떻게든 페이지 폴트 시간을 줄이는 것이 중요하다.
p = 페이지 폴트 확률
ma = 메모리 엑세스 시간
page fault time = 페이지 폴트에 걸리는 시간
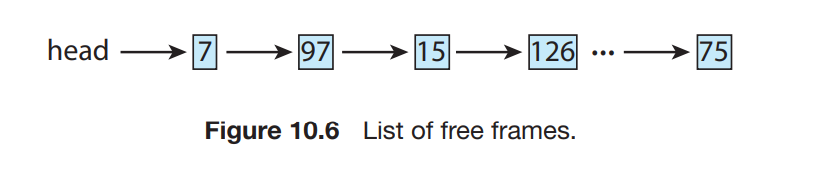
가용 프레임 리스트
-
zero fill-on-demand 사용
보안을 위해
할당되기 직전에 0으로 초기화된다.
스왑공간 처리 방법
-
일반적인 파일시스템을 쓰지 않는다.
-
더 큰 블록, 파일 찾기등을 하지 않아도 되기 때문에 속도가 빠르다.
-
옵션 1.
파일시스템에서 프로세스의 전체 페이지를 스왑공간에 복사한 다음, 요구페이징 수행
느릴 것
-
옵션 2.
처음할 때는 파일시스템에서 페이지들을 가지고 오고, 이후에는 페이지들을 교체할 때 스왑공간에다가 복사해 놓음
나름 효율적
-
옵션 3.
실행파일을 이용한 페이지 폴트 처리
즉, 스왑공간을 쓰지 않고 직접 파일시스템에서 페이지를 처리한다.
스왑 공간의 크기를 줄일 수 있다.
익명 메모리(스택,힙)등 파일과 관련없는 메모리를 저장하기 위해서 스왑공간을 사용한다.
-
모바일 운영체제
스왑공간 없이, 파일시스템 사용한다.
ios에서는 프로세스가 버리지 않으면 절대로 안 방출한다.
그래서 압축메모리라는걸 쓴다.
copy on write
-
vfork()
진짜 그냥 자식이 부모의 주소공간을 그대로 사용한다.
자식이 부모꺼를 바꿀 수도 있음
exec()을 바로 하게끔 만든 의도
페이지 교체
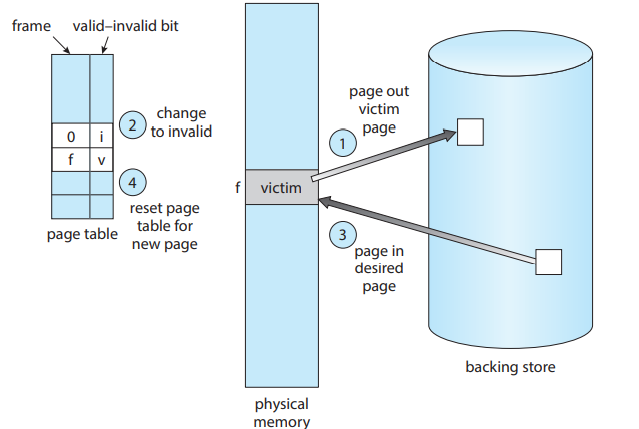
- 페이지 교체의 필요성. 어떻게 할 거냐,,?
변경 비트
-
페이지 교체 시, 디스크를 두 번 (뱉을 때, 쓸 때) 사용해야 한다.
그래서, modify된 것만 저장한다.
읽기전용 페이지들도 마찬가지겠지.
페이지 교체 알고리즘
피포
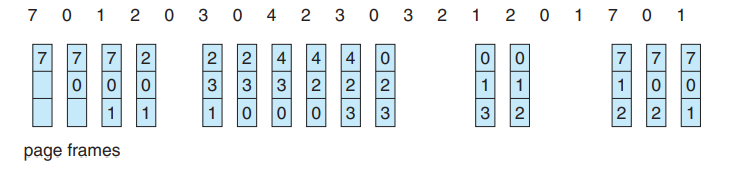
-
서버 프로그램 같이, 계속 돌아가는 프로그램을 내쫓는 문제가 있다.
-
밸러디의 모순이 발견된다.
즉, 프레임의 개수는 늘어나도 페이지 폴트율이 늘어나는 알고리즘
프레임이 N일때와 N+1일 때, 부분집합이 안 되는 알고리즘이다.
LRU를 보면, N+1일 때, 각 상황에서 하나가 다른 하나의 부분집합이 되는데,,
opt
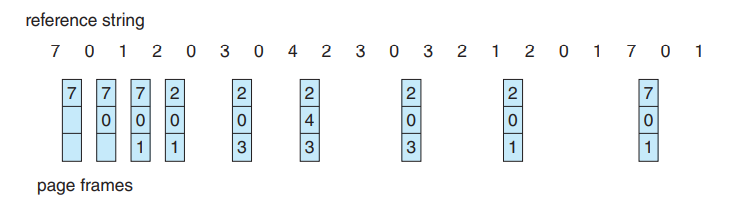
- 미래를 예견해야 된다.
- 앞으로 가장 이후에 쓰일 프레임을 삭제해야 되니까.
- 연구목적으로 쓰게 된다
LRU
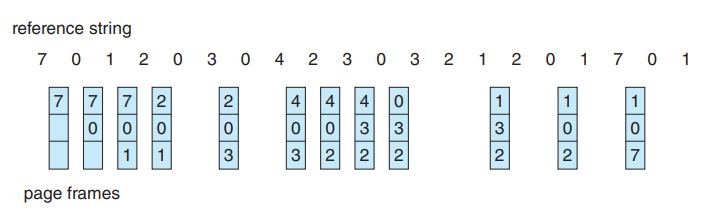
-
구현 방법
카운터 : 시간을 저장한다.
솔직히, 쓰기 힘들다.
시간 값 오버플로우도 생각해야 하고, 테이블을 시간값으로 탐색해야 한다.
또한, 시간값을 탐색하면서 동시에 메모리에 쓰기작업까지 병행된다. 끔직하네.
스택 : 여러번의 포인터 교체가 필요하긴 하다. 또한, 이중연결리스트로 구현하는데, 이렇게 되면 탐색까지 해야된다. 항상 메모리 쓰기를 해야 하게 된다.
-
스택알고리즘이라고 부른다. 프레임 수가 증가하더라도 n개일 때가 부분집합이 된다.
LRU 페이지 교체(approximation) - 부가 참조 알고리즘
-
시프트 레지스터 이용
-
일정 시간마다, 8비트 짜리 시프트 레지스터를 밀어낸다.
왼쪽에서, 오른쪽으로
그리고 제일 왼쪽에, reference 비트를 입력시킨다.
-
00000000 → 한번도 사용 안 되었다.
11100110 → 최근에 한번 또 사용이 되었다.
LRU 페이지 교체(approximation) - second chance 알고리즘
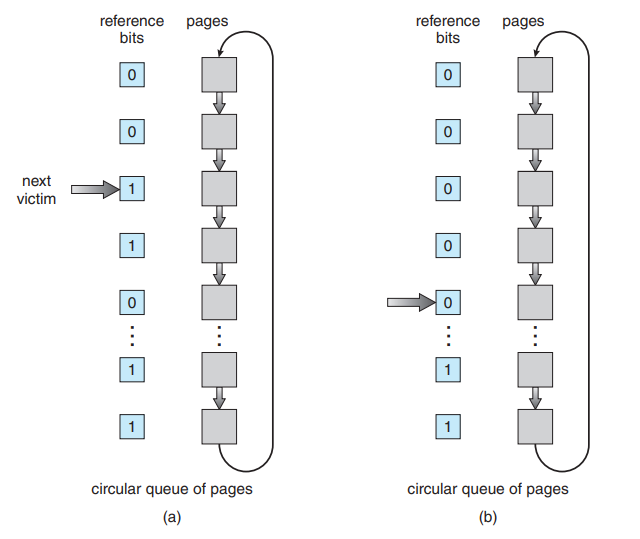
-
이게 너무 많이 돌아가면, 페이지 적재율이 많다는 것이다.
-
기본적으로 FIFO이지만, 1이라면 reference bit를 0으로 세팅하고 기회를 준다.
-
개선점


modify 된 친구들은 그냥 빨리빨리 버려준다.
쫓아낼 페이지들에게 점수를 매기는 느낌이다.
-
투핸디드 클록 기법을 이용해서, 하나는 modify를 찾는 방식으로 효율을 극대화하다.(페이징디먼)
counter 기반 페이지 교체 - LFU
- 카운터를 사용할 때 마다 늘린다.
- 가장 적게 참조된 페이지를 버린다.
- 집중적으로 많이 사용하고 그 이후로 사용 안 할 페이지에 대해서 별로 작동 잘 안 할 수도 있따.
- 잘 안 쓰인다. OPT를 잘 반영 못 한다. 비용도 많이 든다. 가장 적게 쓴거를 찾아야 하고, counteㄱ도 갱신해야 한다.
counter 기반 페이지 교체 - MFU
- 가장 작은 참조회수를 가진걸 반대로 살린다.
- 지금 적게 쓴게 가장 오래 쓰일 것이라는 판단에 근거한다.
- 잘 안 쓰인다. OPT를 잘 반영 못 한다. 비용도 많이 든다. 가장 적게 쓴거를 찾아야 하고, counteㄱ도 갱신해야 한다.
페이지 버퍼링 알고리즘 ( 페이지 교체 알고리즘과 병행)
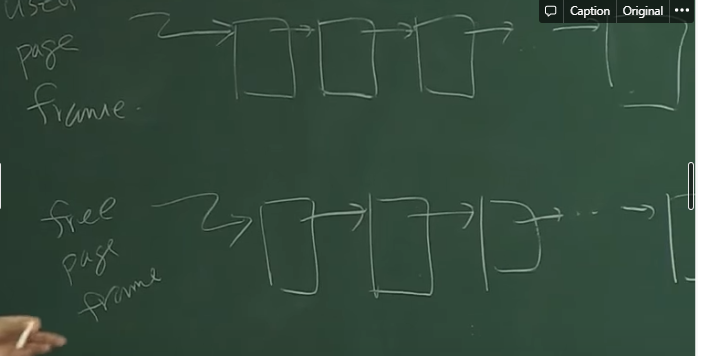
-
페이지를 내쫓고 나서, 그거를 바로 디스크에 쓰는게 아니라, 일단 가용페이지 프레임에 그대로 추가한다.
해당 가용페이지 프레임은, 다른 페이지가 쓰일 수는 있지만, 일단 어떤 페이지에 대한 정보였는지 기억한다.
만약, 다시 해당 프레임을 찾게 되면, 그 데이터를 그대로 가지고 와서 디스크에 접근하지 않는다.
-
가용 페이지 프레임 풀에 있는 modify된 페이지들은, swap out할 때 빨리 하기 위해서, DMA에서 빨리빨리 바꿔놓고 modify를 0으로 맞춘다.
어플리케이션에게 모든 것을 맡길 때
- 데이터 베이스 같은 경우는, global한 운영체제의 페이지 교체 알고리즘을 따르지 않는 것이 효과적일 수 있다.
- 버퍼링 같은 경우도, 어플리케이션단에서 해결하려고 한다. 만약 운영체제의 버퍼링을 이용하게 되면, 하나의 메모리에 대해 2개의 버퍼를 가지게 된다.
- 그래서, 아예 파일시스템을 거치지 않는 raw disk를 할당 받아 알아서 처리하는 응용프로그램이 있다.
프레임 할당
최소 할당 프레임
- 만약, ADD A,B,C 명령어를 가진 프로세서에서
- 프레임을 2개만 주면
- 무한 페이지폴트
할당 알고리즘 - 균등할당
- 그냥, 가용 프레임 풀 3개정도 남겨 놓고(앞선 예에서 말한 버퍼등을 위해)
- 나머지는 N빵
할당 알고리즘 - 비례할당
- 프로세스의 크기에 따른 N빵

- 우선순위를 고려하지 않기에 ,, 조금 문제가 있을 수도 있다.
주요 페이지 폴트 / 사소한 페이지 폴트
- 주요 페이지 : 그냥 디스크에서 불러옴
- 사소한 페이지폴트 : 가용 프레임 풀 혹은 공유라이브러리 매핑만 한다.
지역할당 vs 전역할당
-
전역교체
우선순위가 높은 상태에서 다른 프로세스의 페이징 할당량을 그냥 떼올 수 있다.
다른 프로세스의 페이징 활동을 방해할 수도 있다.
따라서, 동일한 상태에서도 수행시간이 달라질 수 있다.
-
일반적으로 전역교체가 더 좋다.
-
전역교체에서 페이지 양 조절
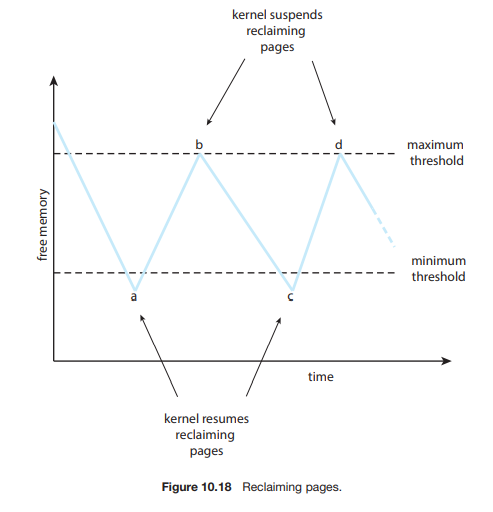
커널은 전체적으로 메모리 양을 조금 남기려고 한다.
임계점을 넘어가면, 페이지 교체 알고리즘을 통해 쫓아낸다.
이러한 루틴을 리퍼라고 부른다.
만약, 어느 정도 일정한 량을 회수하지 못하면, 공격적으로 FIFO로 막 그냥 떼낸다.
비균등 메모리 접근 (NUMA)
- 프레임을 당연히, 프로세스가 돌아가던 CPU에 할당이 되어야 한다.
- NUMA별 가용 메모리 프레임 리스트를 내준다.
스레싱
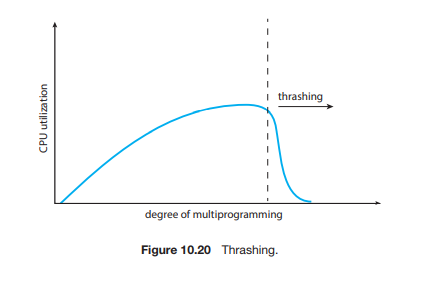
원인
- 페이지 폴트가 많아진다
- CPU 이용률이 낮아진다
- 일을 안 하는 줄 알고 프로세스를 더 늘린다
- 마비가 된다.
- 지역할당을 해도, 페이지 폴트 큐가 길어짐에 따라 페이지 폴트 처리 시간이 급격하게 늘어나게 된다.
작업집합 모델
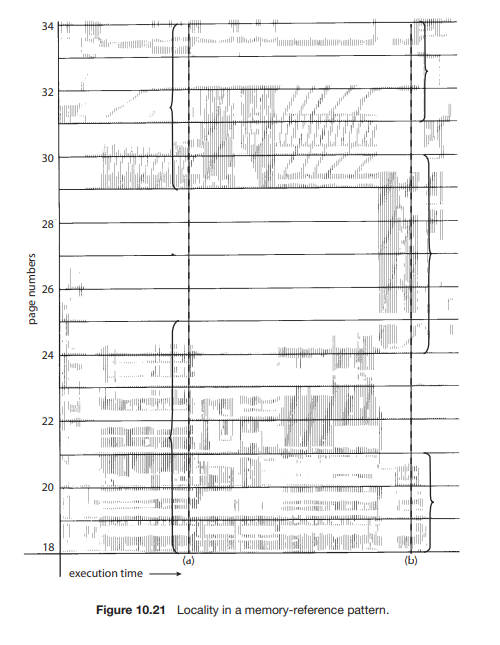
작업집합이란
-
작업집합이란
일정 실행시간동안 참조한 페이지의 집합이라고 할 수 있다.
-
즉, 프로그램은 공간적으로, 시간적으로 locality를 가지게 된다.
공간 : for loop 등
시간 : 어떤 변수들..
-
어떤 시점에 어떤 프로세스에 필요한 정도의 양이 있게 되고, 이게 바로 작업집합모델이 된다.
이 조건을 만족시키지 못하면 스레싱이 발생하게 된다.
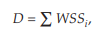
wss(i) = 프로세스 i의 working set 크기
작업집합이 변하는 모습
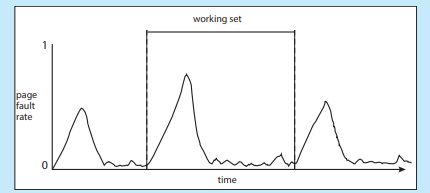
작업집합 정하는 방법 - 그냥 페이지 참조 몇 번 동안 어떤페이지를 참조했는가
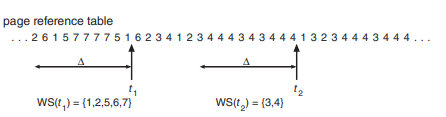
-
근사하는 방법
만약, 세타가 10000이라면, 5000과 10000에 리퍼런스 비트를 조사하고 만약 1이라면 워킹셋이다 이렇게 정의할 수가 있을듯
작업집합 정하는 방법 2 - 페이지폴트율 이용하기
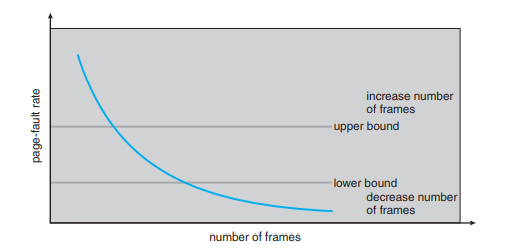
- 프로세스가 페이지 폴트를 많이 일으키면 많이 주고, 적게 일으키면 적게 준다.
워킹셋 알고리즘
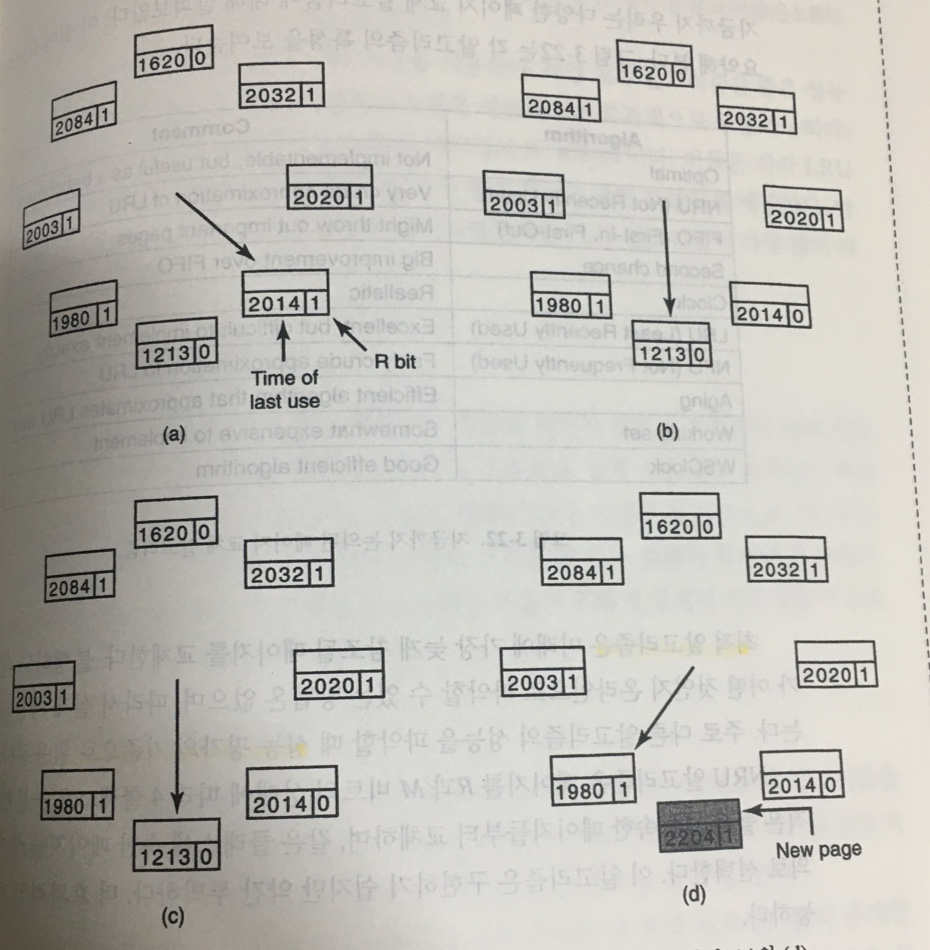
-
클록을 돌면서, 1인 애는 0으로
-
0인 에는 일단 쓰기 요청을 하고 돈다.
-
0이면서 쓴 애들은 그냥 내쫓는다.
근데, 그냥 0일 때 뱉는게 아니라, 워킹셋의 기준시간보다 작으면 뱉는다.
-
클락이 원점으로 돌아왔을 때, 만약 아무 것도 못 뱉었다면,
그런데, 디스크 쓰기 스케줄링도 못 시켰다면
그냥 아무것나 뱉는다.
메모리 압축

- 페이징의 또다른 대안. 스왑공간으로 보내지 않음
- 절차
- 15,3,35,26을 몰아내려고 한다.
- 7에다가 15,3,35,26을 압축해서 때려 넣는다.
- 이후에 다시 15,3,35,26이 필요하면, 압축을 해제하여 쓴다.
- 모바일에서는 이거를 주로 쓴다
- 운영체제에서는, 이거의 효율이 좋기 때문에, 이렇게도 해결이 되지 않으면 그 때 페이징 한다.
- 트레이드 오프가 존재한다.
커널 메모리의 할당
커널 메모리 할당을 따로해야 하는 이유
-
다양한 자료구조를 사용한다.
따라서, 페이지 단위로 뚝뚝 끊는것 보다, 정확하게 하는게 내부 단편화를 줄인다는 면에서 더 효과가 좋다.
-
하드웨어를 사용하는 메모리들이 있는데, 이런 것들은 연속적으로 할당되어야 할 필요성이 있을 수 있다.
-
또한, 커널 코드는 어떻게 구성될 지 운영체제가 알고 있기 떄문에 최적화를 할 수 있다.
버디시스템
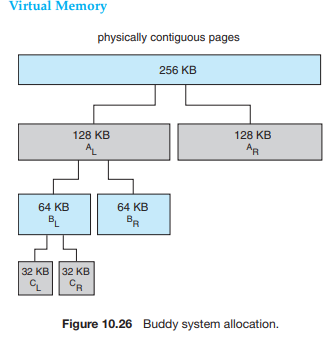
- 2의 배수로 할당한다.
- 합병하기가 쉽다. 단위가 어느정도 일정하기 때문이다.
- 내부단편화가 발생할 수 있다. ( 33KB에다가 64KB?)
슬랩할당
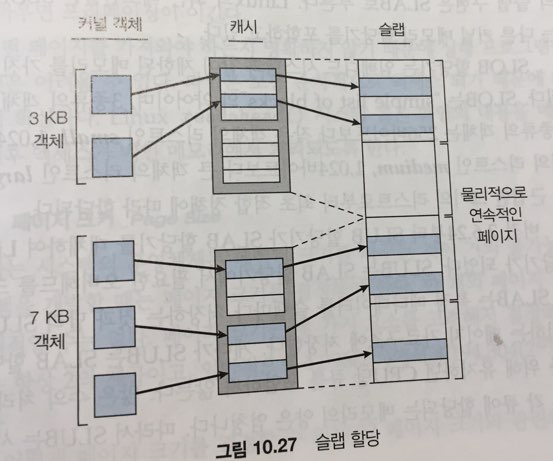
-
그냥, 메모리를 슬랩단위로 나눈다
→ 캐쉬는 여러 개의 슬랩으로 이루어져 있고.
→ 캐쉬 안에는 각 객체가 있다.
-
미리 할당해 놓기 때문에
-
kmalloc
프리페이징
- 일단, 프로세스가 시작하기 전에 필요한 메모리를 다 올려놓는 일(페이지)
- 작업집합을 정확하게 하지 않으면 오히려 손해가 날 수 있다.
페이지의 크기에 관한 고찰
-
크기가 작으면 빠르겠지만, 메모리 효율이 떨어진다.
- 물론 크기가 작으면, 정밀도가 높아져서 전체적으로 페이지폴트되는 메모리의 양 자체는 줄어들 수도 있다. 또한 I/O 회수도 생각보다 커지지 않을 수도 있다.
- 하지만 페이지가 커지면, 이를 관리해야 하는 테이블의 크기라던가, 레지스터, 큐잉 등등 복잡해지는 부가요소가 더 커진다.
-
I/O 에 대한 효율
디스크의 경우
I/O는 대부분 탐색에서 많은 시간이 소요된다
따라서, 큰 페이지를 하면 효율이 높아진다.
TLB Reach
- TLB 엔트리의 수 * 페이지의 용량
- 즉, 얼마나 많은 용량을 TLB에서 확인할 수 있는지를 파악하는 것
재미있는거

- 행단위로 저장을 하기 때문에 페이지 폴트 많이 줄어들고 잘 된다.
- 읽기 전용으로 나눠놓으면, 빠르게빠르게 뺄 수 있다.
I/O시 잠금
문제점
- I/O 하다가 갑자기 메모리를 회수해버리면? 존나 망한다.
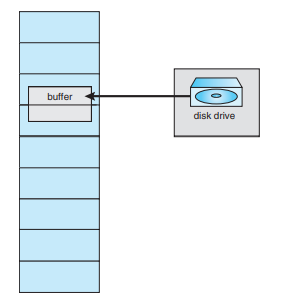
사용자 공간에 I/O를 안 하는 방법
- 사용자가 메모리를 사용하려면 이를 복사해야 한다.
페이지 잠금 기법
- 괜찮다.
- 운영체제 커널은 어지간해서 잠구겠지
- 실수하면 메모리가 버려진다.
- 낮은 순위의 프로세스가 힘들게 페이지를 가지고 왔는데, 높은 순위의 프로세스가 이를 선점해버리면 개손해니까, 이런 것도 락을 걸어 놓을 수는 있다.
LINUX
- 클록알고리즘과 유사한 알고리즘
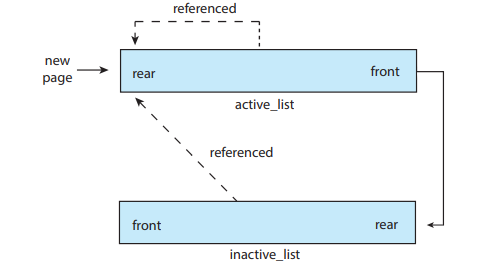
- reference되면 다시 앞쪽 큐 맨 앞으로 올라온다.
- inactive_list에서 제거한다.
WINDOWS
-
클러스터링 페이지 기법
앞뒤로 가져온다
-
작업집합 최소값, 최대값
최소값만큼은 할당해주고, 최대값보다는 크지 않게 해준다.
-
LRU를 사용한다.
-
threshold 밑으로 떨어지면, 자동 작업 트리밍이라는게 생겨서 어느 정도 채워질 때 까지 모든 프로세스를 작업집합 최소값으로 맞춰버린다.
솔라리스는,,
