
본 포스팅의 내용은 Operating System Concepts 10th의 내용을 토대로 작성되었습니다.
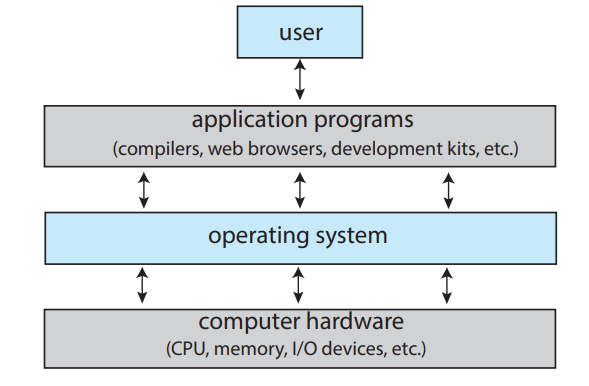
운영체제란
- 시스템 관점
- 자원 할당자 : CPU, 메모리, 저장장치, 입출력 장치
- 제어프로그램 : 입출력 장치 제어 등
컴퓨터 시스템의 구성
System Bus
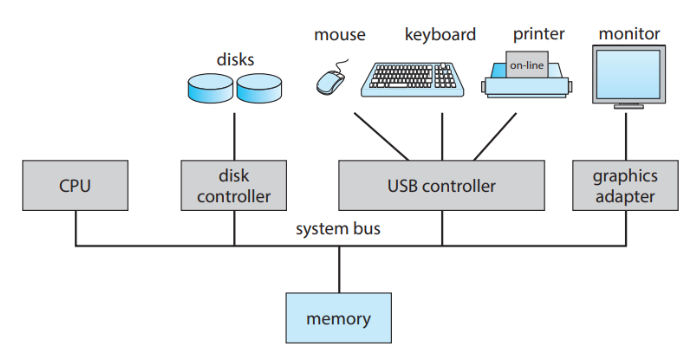
-
Data bus와 Address bus로 크게 나눌 수 있다.
-
bus arbiter가 bus request를 중재하게 된다.
왜냐하면, 입출력 장치들은 버스 하나밖에 못 쓰니까요
access bus request signal
replies wtih bus grant signal
-
bus master는, bus를 장악하고 무언가를 뿌려주는 친구들
cpu, dma 등
-
bus slave는, master를 통해 동작하고 데이터 입출력이 되는 친구들
memory controller
device controller
저장장치 구조
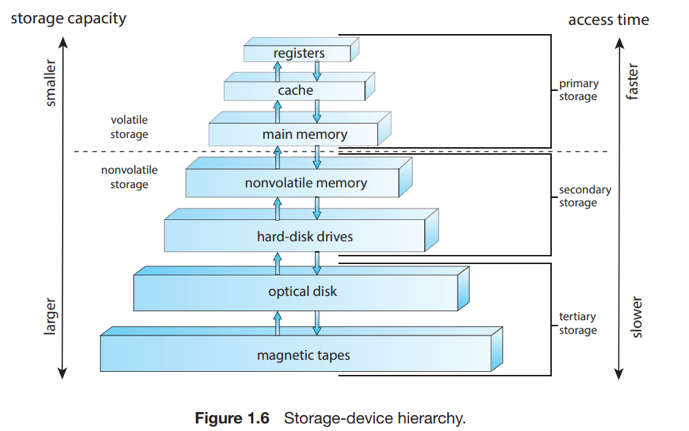
기계적 → 싸다, 많다, 느리다
전기적 → 빠르다. 비싸다.
입출력 구조
- 각 하드웨어들은 input, output, control, status register 등을 가진다.
- output operation의 예
- status register를 가지고 와서, 사용 가능한 지 확인.
- control register에 output 명령 입력
- I/O 종료를 interrupt 혹은 pooling 방식으로 기다린다.
- address method
- memory mapped I/O : 평범한 load/store 명령어
- port mapped I/O : bus도 다르게 구현하는 경우가 많음. input,ouput operation을 따로 수행하도록 한다.
DMA
- 등장 배경
- 전송이 한 바이트씩 일어난다고 하면, block 디바이스 같은 곳에서 대용량 데이터를 전송할 때 한 바이트마다 계속해서 CPU interrupt가 발생할 것이다.
- 그러니까, DMA가 이를 대신해서 처리하자.
- 동작방식
- Cycle stealing : cpu가 비어있을 때만, 빠르게 처리
- burst mode : 한번 시작하면 끝까지 한다. 비선점형
- 동작 과정
- CPU가 DMA에 일을 시킨다.(input/output인지, 시작주소는 어디인지, 목적 주소는 어디인지)
- DMA가 I/O device에 메모리를 복사한다.
- I/O device가 일을 마치고 DMA가 ACK를 받는다.
- DMA가 interrupt를 통해 CPU에 알린다.
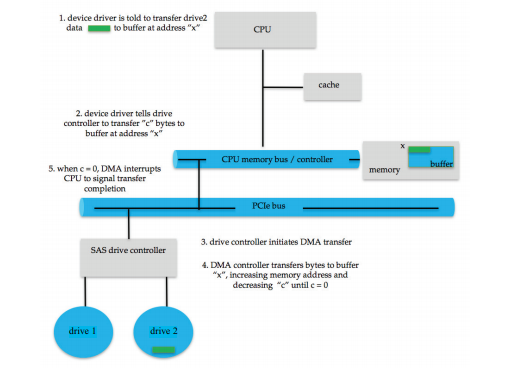
-
DMA 리퀘스트 , DMA ack 라는 두 개의 선에의해 통신
DMA 리퀘스트를 통해 장치컨트롤러에서 요청한다.
-
스위치라는 구조를 이용하면, 각각의 장치에서 동시에 입출력이 가능하다.
사이클을 경쟁하지 않고 동시에 가능하다.
인터럽트
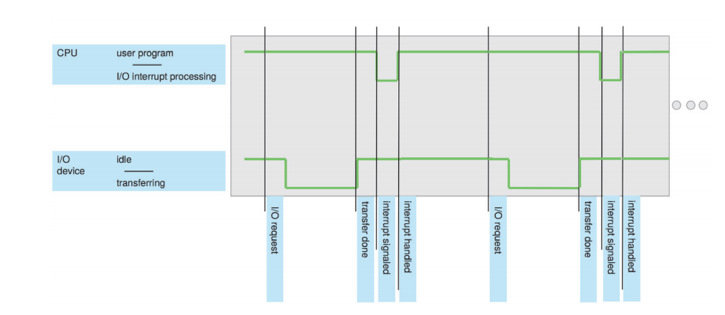
인터럽트의 잇점을 보여주는 사진
-
인터럽트 테이블 : 각 인터럽트 루틴에 대한 핸들러 포인터 테이블이다.
테이블의 크기가 제한되어 있기 때문에, 체이닝 기법을 이용한다.
-
인터럽트 벡터 : 테이블의 색인. 인터럽트 종류라고 할 수 있음, 요청과 함께 들어온다.
-
인터럽트 발생 시
- 현재 실행하던 프로그램을 멈춘다.
- interrupt 당한 instruction address를 저장한다.
- ISR을 인터럽트 벡터 넘버로 확인
- ISR로 점프
- 다른 interrupt disable
- 인터럽트 마친 후 return to save address and enable interrupt
-
마스크 불가능 인터럽트, 마스크 가능 인터럽트
특수한 상황에 무시할 인터럽트
이러한 disable 혹은 mask들은 버퍼에 달릴 수도 있다. 단, 한계는 있다.
-
우선순위가 높은 인터럽트, 낮은 인터럽트를 잘 가려내야 한다.
높은 인터럽트가 낮은 인터럽트를 선점할 수 있다.
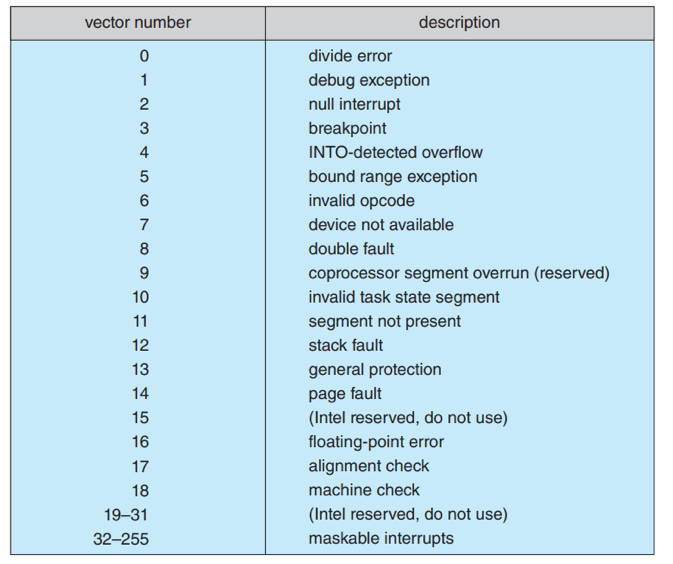
-
두 개의 타입이 있다.
Hardware
Trap, software interrupt, 실제 인터럽트와 동일하게 취급하게 된다.
-
PIC
- 동작과정
1. 마스터는, 어떤 슬레이브 인터럽트 컨트롤러부터 왔는 지를 interrupt vector를 통해 CPU 에 전달
2. CPU는, 인터럽트가 발생한 것은 알지만, 어떤 인터럽트인지는 실제 인터럽트를 발생시킨 slave PIC를 통해 전달받음 ( 이 때, 데이터 버스를 이용한다.)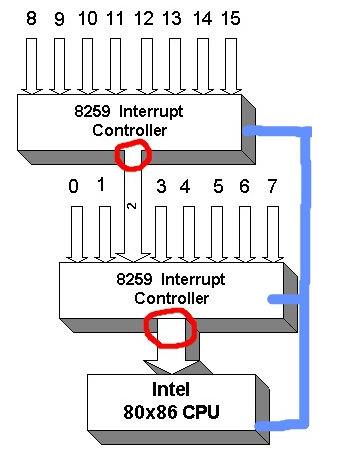
1차 인터럽트 처리기와 2차 인터럽트 처리기
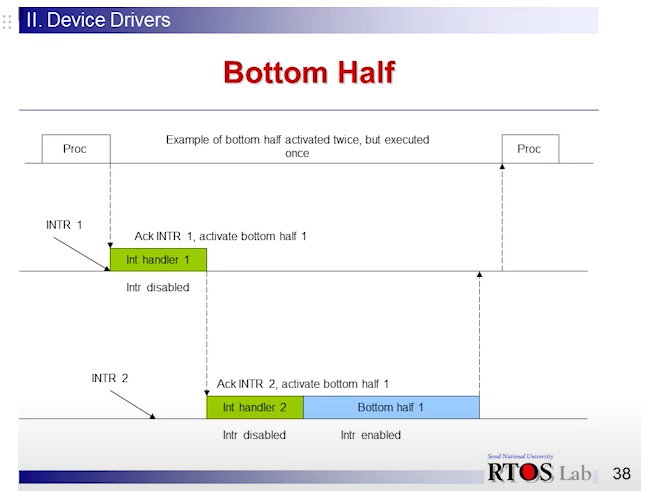
-
two level interrupt handling → 일단 가장 중요한 부분만 돌리고, 나중에 처리해도 되는 작업은 별도의 context에서 따로 돌게 한다(프로세스, 스레드가 아님 bottom half, 커널 레벨 스레드).
-
인터럽트를 키고, 낮은 우선순위로 bottom half가 돌게 되겠지.
-
빨리빨리 끝내고 나가는게 1차 인터럽트 처리기
-
그게 아니면 2차 인터럽트 처리기
-
예를 들면,, 디스크 요청
1. 일단, 1차 인터럽트 처리기가 디스크 명령어를 수행시켜놓는다.
2. 2차 인터럽트 처리기는 해당 작업을 천천히 천천히 실행한다.
만약, 디스크에 대한 작업이 끝나면 자기가 할 것도 끝내서, 해당 인터럽트 핸들러에서 사용자 공간에 복사한다음 리턴한다.인터럽트를 처리하기 위한, 스택
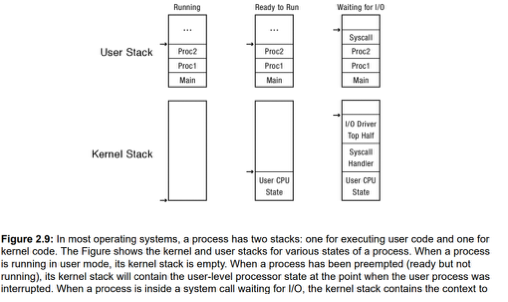
-
모든 프로세스는 인터럽트를 처리하기 위해 커널 스택을 따로 둔다.
유저 공간에 스택을 냅둬버리면, 인터럽트 처리 도중 막 값이 변경되고 하는 부작용이 있을 수 있기 때문이다.
-
또한 여기에는, 선점된 유저 프로세스의 정보가 들어갈 수도 있다. 그냥 여러가지 용도로 쓰이겠네
-
X86의 예
이런 저장 과정을 소프트웨어 적으로 구현하지 않았다.
인터럽트가 걸리면, 인터럽트 스택 포인터로 프로세스의 스텍 포인터를 바꾼다. 그리고, insturction pointer(pc)를 저장하고,
condition bit등을 저장한다(for arithmetic,,,), process status word라고 하지.
그리고 나서, 하드웨어 적으로 이런게 끝나고 핸들러가 실행될 때 프로세스의 모든 정보를 저장하게 된다.(레지스터)
이런게 하드웨어 적으로 일어난다.다중 처리기
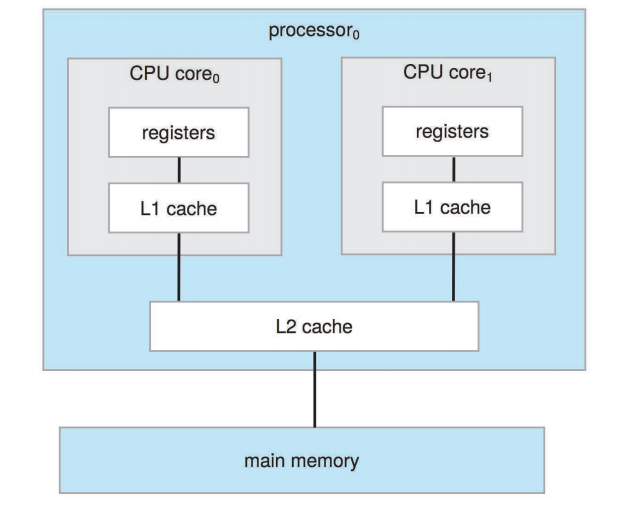
-
하나의 메모리를, 여러개의 코어가 공유하는 방식
-
버스가 제한되어 있어서, 확장성이 좋지는 못하다.
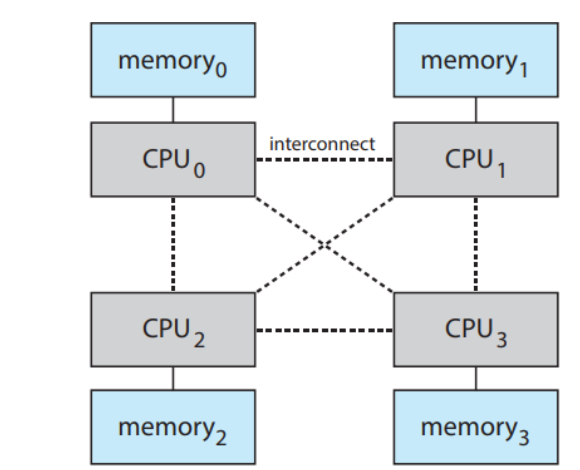
-
NUMA
-
공유 시스템으로 연결되어, 각각의 cpu에 메모리를 할당한다.
-
장점으로는
cpu끼리 간섭도 없다.
따라서 효과적으로 확장 가능하고,
-
단점으로는
다른 cpu의 메모리에 접근해야 할 때, 성능 저하가 커진다.클러스터형 시스템
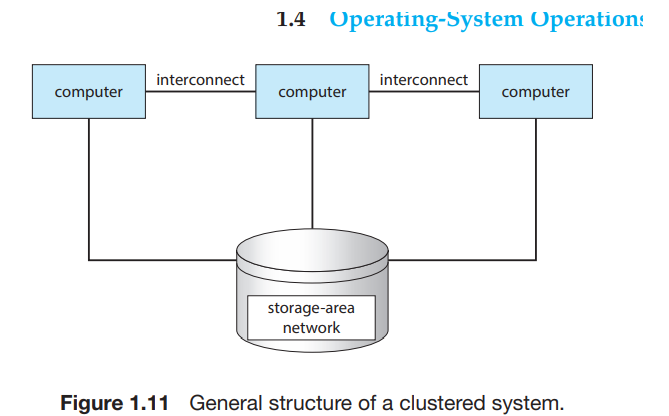
-
-
결함 허용: 하나가 망해도 계속 돌아갈 수 있다.
-
비대칭형 : 일부는 hot-stand-by로 남겨놓고, 만약 어떤 노드가 망하면 그 노드를 대신해 일을 하는 방식
-
대칭형: 그냥 똑같이 일한다. 성능은 훨씬 향상된다.
-
병렬화: 작업을 각 노드에 나누는 일
-
하둡이 대표적이다. 분산 컴퓨팅 노드에서 데이터와 파일을 관리한다.
mapreduce 시스템이 클러스터의 노드에서 데이터를 병렬처리 할 수 있게 한다.
운영체제의 작동
- 시스템 데몬: 커널이 실행되는 전체 시간동안 실행되는 프로그램
다중 프로그래밍과 다중 태스킹
-
다중 프로그래밍 : 여러 개의 프로세스를 동시에 메모리에 유지하는 일
I/O 작업 중에 다른 일을 할 수 있다는 점
-
다중 태스킹 : 사용자에게 빠른 응답시간을 제공하는 예, 동시에 프로세스를 실행시키는 일
이중 모드와 다중 모드
-
user mode 1, kernel mode 0
-
resource 관리나 중요한 명령어(instruction load, I/O 관리, 타이머 관리 및 인터럽트 관리, 메모리 관리(다른 프로세서 영역 침범 X) 등)를 사용자 공간에서 실행 못 하게 하기 위함
-
위반 시 (즉, user mode에서 kernel을 호출 시) 트랩
-
여러 개의 모드는 딱히 쓸모 없지만, 도커와 같이 애매한 프로세스를 실행할 때는 의미 있을지도 모르겠네
-
프로세스가 마비당하는 것 이상으로, 시스템 전체가 털릴 수 있다.
-
프로세스가 커널 모드로 실행되면, 메모리를 막 드나들며, instruction을 막 쓸 수도 잇고, timer interrupt또한 무시할 수도 있다. 이런 점을 잘 고려해라.
-
커널이 아닌 유저영역에서 이런 모든 걸 다 해버리면,,
OS dependent 해진다. 유저영역이 결국 커널을 필요하다고 막 써버리기에. 나중에 이식이 안 된다.
타이머
- 가변 타이머는 클록과 계수기로 구현. 클록이 돌 때마다 계수기가 감소, 계수기가 0이되면 인터럽트
- 이러한 명령은 엄연히 priv 명령이다.
가상화
- 에뮬레이션: 정말 하드웨어 자체를 따라해서 다른 하드웨어를 따라하는 일. 너무 어렵다
- 가상화: 운영체제 위에서, 게스트 운영체제를 만들어 낸다.
