
Redis(Remote Dictionary Server)의 특징
1. NoSQL? 🤔
일반적인 관계형 데이터베이스 (Oracle, MySQL 등) 와는 다른 형태의 데이터를 저장 및 검색하는 데이터베이스 이며, 비 관계형 데이터베이스라고 표현하기도 합니다.
기존의 관계형 데이터베이스 시스템이 기하급수적으로 증가하는 데이터를 처리하기에는 많은 부담과 문제가 있었습니다. 특히 장비의 성능이 좋을수록 성능을 향상 (Scale-up: 수직적 확장) 시키는 비용이 기하급수적으로 증가하기 때문입니다.
따라서, 데이터를 분산하여 저장(Scale-out: 수평적 확장)을 목표로 NoSQL이 등장하게 됩니다.
이 NoSQL의 특징은 단순 검색 및 추가 작업을 위해 최적화 된 키 값 저장 공간으로, 레이턴시와 스루풋과 관련하여 이익을 내는 것이 목적입니다.
NoSQL에는 많은 종류가 있고 기본적인 분류는 데이터 모델에 기반을 둡니다.
그 중 Redis는 Key-Value 형태의 비 관계형 데이터베이스 입니다.
NoSQL 종류
Key-Value형
- 특정 : 데이터에 대해서 key/value 형태로 저장하는 데이터로 구현하기 쉬우나 value의 일부를 읽거나 업데이트에는 비효율적이다.
- 종류 : Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB, Amazon SimpleDB, Riak
Column family형
- 여러 서버에 분산된 수 많은 데이터를 저장,처리 하기 위해 만들어짐
- key-value형 처럼 Key를 사용하지만 key-value형과 다르게 여러개의 칼럼을 가리키고 있고 컬럼은 컬럼 패밀리에 따라 정렬된다.
- 종류 : Cassanadra, HBase
Doucument DB형
- 기본적으로 key-value와 비슷함
- document : 많은 key-value collection 들의 collection
- 반 정형화된 document들이 JSON과 같은 포맷으로 저장
- 종류 : CouchDB, MongoDb
Graph 형
- SQL은 Row, Column 기반의 테이블과 정형화된 구조를 가짐
- SQL 대신 유연한 graph model을 여러 서버들에 확장할 목적으로 사용 가능
- DB 조회는 데이터 모델에 기반함
- 종류 : Neo4J, InfoGrid, Infinite Graph
🙋♀️NoSQL 중에서도 Redis가 주목을 받는 이유?
- 데이터 저장소로 입력/출력이 가장 빠른 메모리를 채택
- 단순한 구조의 데이터 모델인 Key-Value 방식을 통한 빠른 속도
- 캐시 및 데이터 스토어에 유리
- 다양한 API 지원
Redis는 대형 서비스 업체들이 (페이스북, 인스타그램, 네이버 LINE 서비스, StackOverflow, 블리자드 등)
사용자들의 대규모 메세지를 실시간으로 처리하기 위하여 사용하고 있다.
2. 💾 In-Memory Data Structure Store
데이터베이스가 메인 메모리에 설치되어 운영되는 방식의 데이터베이스입니다.
메인 메모리에 데이터베이스를 설치하는 이유는 디스크 접근이 메모리 접근보다 느리기 때문이며, 데이터 양의 빠른 증가로 기존 데이터베이스 응답 속도가 떨어지는 문제를 해결할 수 있는 대안입니다.
단점
매체가 휘발성이다.
보통 캐싱, 세션과 같은 임시 데이터에 주로 사용되며, 메인 메모리의 용량이 부족할 경우 가상 메모리를 사용하여 역효과가 일어나기도 합니다.
Cache?
Cache : 나중의 요청에 대한 결과를 미리 저장하였다가 빠르게 서비스를 제공
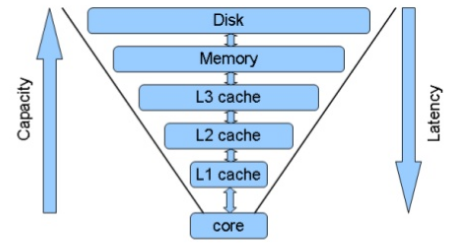
보통 DB들은 CRUD시 DISK에 저장이 되고 있습니다. 많은 용량을 저장할수 있다라는 장점이 있으나 그만큼 소요시간이 많이 걸린다. 그에 반해 Cache는 메모리를 이용하므로 결국 Cache는 빠른 속도를 위해서 사용한다.
3. Data Type

Redis는 Key로 참조되는 Value 타입을 다양하게 지정하여 저장 할 수 있습니다.
List, String, Sets, Sorted sets, Hashs 등 여러 데이터를 지정하여 손쉽고 편리하게 데이터를 저장할 수 있습니다.
Persistence(영속성)
본문에 내용에 의하면 In-Memory Database의 단점으로 데이터의 휘발성을 언급하였습니다.
그러나 Redis의 경우 SnapShot, AOF 와 같은 방식으로 일정 주기와 명령어를 통해 데이터를 보존할 수 있습니다.
SnapShot
SnapShot는 기존 RDBMS에서도 사용하고 있는 어떤 특정 시점의 데이터를 DISK에 옮겨담는 방식을 뜻합니다.
SnapShot 사용 시 다음과 같은 고려사항이 있습니다.
- 레디스에 저장되는 데이터 크기와 물리 메모리의 비율 고려
- 리눅스 운영체제의 경우 vm,overcommit_memory=1 설정 확인
- Swqp/SnapShot에 대한 Dist I/O이 많아질 수 있습ㄴ디ㅏ.
AOF
Redis의 모든 write/update 연산 자체를 모두 log 파일에 기록하는 형태입니다.
서버가 재 시작할 시 write/update를 순차적으로 재실행, 복구 합니다.
AOF 사용 시 다음과 같은 고려사항이 있습니다.
- 적당한 디스크 용량과 IO속도를 보장해야 함
- Redis 재시작 시 SnapShot보다 느리게 시작 됨.
레디스 공식문서 에서의 권장사항은 RDBMS 수준의 안전성을 원한다면
두 가지 지속성 방법을 모두 사용해야 한다는 것 입니다. 주기적으로 SnapShot으로 백업하고 SnapShot 이후 다음 SnapShot까지의 저장을 AOF 방식으로 수행하는 것입니다.
Sharding
Sharding은 각 데이터를 특정 조건에 따라서 서버에 분산 저장하는 기법입니다.
단일의 데이터를 다수의 데이터베이스로 쪼개어 나누는 걸 말합니다.
단일의 데이터베이스의 저장중인 데이터가 너무 클 때, 데이터를 구간별로 쪼개어 나눔으로써 데이터를 빠르게 검증할 수 있어 속도를 향상시킬 수 있습니다.
Redis는 읽기 성능 증대를 위한 서버 측 복제와 쓰기 성능 증대를 위한 클라이언트 샤딩을 지원합니다.
-
Range
특정 범위를 정하고 해당 Range에 속하면 해당 부분에 저장
서버의 상황에 따라서 노는 서버가 발생
범위로 지정되어 있기 때문에 한번 설정시 바꾸기 어려움
확장은 쉬움 -
Modular
N % K (서버 수) 로 서버의 데이터를 결정
Range보다 균등하게 분배할 가능성이 높다
서버를 증설시 배수로 증설해야 하는 단점이 있음 -
indexed
해당 key가 어디에 저장되어야 할지 관리 하는 서버가 따로 존재
상대적으로 제일 균등하게 분배할 가능성이 높음
관리서버가 죽을 경우 모든 서버에 장애 발생
Single thread
Redis Server는 1개의 싱글 쓰레드로 수행되며 서버 하나에 여러개의 서버를 띄우는 것이 가능하다.
Master-Slave 형식으로 구성이 가능하다.
데이터 분실 위험을 없애주는 것이 Master-Slave 방식이다. Master-Slave을 이용해 실시간으로 데이터를 다른 서버에 복제한다. Master Server가 다운 되어도 Slave Server로 접속하면 바로 서비스를 계속할 수 있다.
Redis 단점 😒
메모리 파편화가 발생하기 쉽다.
Redis는 싱글 쓰레드이다. 그래서 스냅샷을 뜰 때 자식 프로세스를 하나 만들낸 후 새로 변경된 메모리 페이지를 복사해서 사용한다. Redis는 copy-on-write 방식을 사용하는데, 보통 Redis를 사용할 때는 데이터 변경이 잦기 때문에 실제 메모리 크기만큼 자식 프로세스가 복사하게 된다. 그래서 실제로 필요한 메모리 양보다더 많은 메모리를 사용하게 된다.
대규모 데이터에 대한 응답 속도의 불안정성
대규모 트래픽으로 인해 많은 데이터가 업데이트 되면 매번 malloc과 free를 통해서 메모리 할당이 이루어진다.
💡 CRUD에 따른 Redis 데이터 처리
Redis 서버는 Client에서 Read 요청이 들어올 때 메인 서버로부터 값을 가져와 저장한다.
이 때 메인 서버와 싱크된 데이터 이 외에 추가로 데이터 만료 시점을 처리하기 위해서 현재 시간이나 만료 시간을 함께 저장해야한다.
Read 요청 시
Redis 서버에서 사용자가 요청한 데이터가 있는지 확인한다. 데이터가 존재하는 경우 만료 여부 확인 후 이 정보를 반환한다. 정보를 반환한 시간을 현재로 업데이트 후 종료한다. 데이터가 만료되었거나 없는 경우는 삭제 후 메인 서버에 요청한다. 메인 서버로 부터 받은 데이터를 캐싱 및 DB에 저장 후 이 값을 방문자에게 반환 후 종료한다.
CUD 요청 시
이 경우 앞의 과정과는 조금 다르다. 그 이유는 데이터에 변화가 생겼으므로 해당하는 값의 데이터는 캐싱 값이 아닌 현재 실시간 정보를 보내줘야한다. 그러기 위해 필요한 조치는 비교적 간단하다.
방문자의 CUD를 메인 서버에 요청을 한다. 메인 서버는 요청받은 CUD 작업을 반영 및 업데이트한다. 변경되기 전 데이터 값을 Redis에서 찾아 삭제 후 종료한다.
여기서 가장 중요한 점은 캐싱을 제공하는 경우 단순하게 정보를 제공하는 부분만 고려하는 것이 아니라 다양한 상황에 대처해야 한다는 점이다. 예를 들어 CUD처럼 데이터에 중요한 변경 사항이 있는 경우 기존의 캐싱 데이터를 삭제하는 과정을 들 수 있다.
📝 마치며
- Redis는 기본적으로 매우 좋은 툴
- 그러나 메모리를 빡빡하게 쓰는 경우 관리 어려움
- ex) 32GB장비에 24G이상 사용하는 경우 장비 증설을 고려 하는 것이 좋음
- Write가 Heavy한 경우 마이그레이션 또한 주의해야함
- Redis를 Cache로 쓰는 경우
- 레디스가 문제가 있을때 DB등의 부하가 어느 정도 증가하였는지 확인 필요
- Consistent Hasing도 부하를 아주 균등하게 나누지는 않음
- Redis를 Persistent Store로 쓰는 경우
- 무조건 Primary / Secondary 구조로 구성이 필요함
- 메모리를 절대로 빡빡하게 사용하지 말것
- 정기적인 마이그레이션 필요
- RDB/AOF가 필요하는 경우 Secondary에서만 구동
참고 :
https://velog.io/@jbb9229/redis-introduce01
https://velog.io/@gjrjr4545/Redis
https://sjh836.tistory.com/178
https://goodgid.github.io/Redis/
