1. Agglomerative Clustering
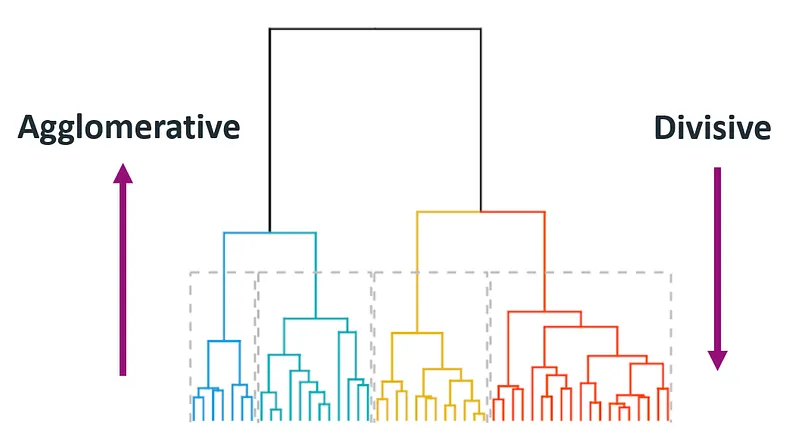
- '계층적 군집화'라고 부르는 방식으로 가장 작은 데이터 단위부터 유사한 것끼리 합쳐나가는 방식 (Bottem-up)
- 초기화 당계에서 모든 데이터 포인트를 각각 독립된 하나의 군집으로 간주
- K-Means와 달리 동일한 결과를 보장
2. 하이퍼 파라미터
from sklearn.cluster import AgglomerativeClustering
AgglomerativeClustering(
n_clusters=2,
affinity='euclidean',
memory=None,
connectivity=None,
compute_full_tree='auto',
linkage='ward',
pooling_func='deprecated',
distance_threshold=None,
)n_cluster
- 최종적으로 생성할 군집의 개수
- distance_threshold가 설정되어 있다면, 반드시 None (threshold넘으면 auto-stop)
metric (이전 affinity)
- 군집 간의 거리를 측정하는 방식을 결정
- "precomputed"일 경우 fit메서드에 입력할 때 데이터 간의 distance matrix가 필요 (단일 데이터 벡터X)
linkage
- 군집과 군집 사이의 거리를 어떻게 정의할지 결정하는 연결 방식
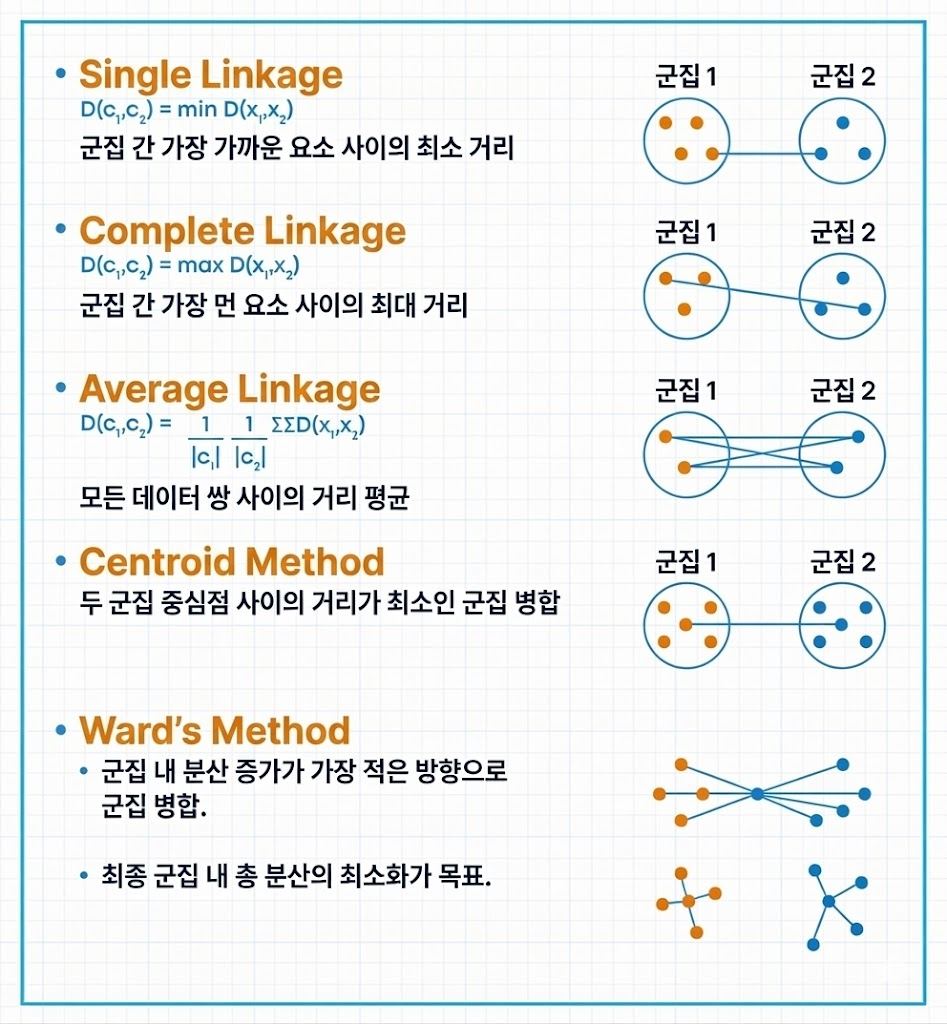
distance_threshold
- 군집 병합을 멈출 거리의 threshold
- 이 값을 설정하면 당연히 n_clusters는 None

AngDDo