Dunn Index
Dunn Index
-
Unsupervised-Clustering에서 군집이 얼마나 잘 묶였는지 평가하는 평가지표
-
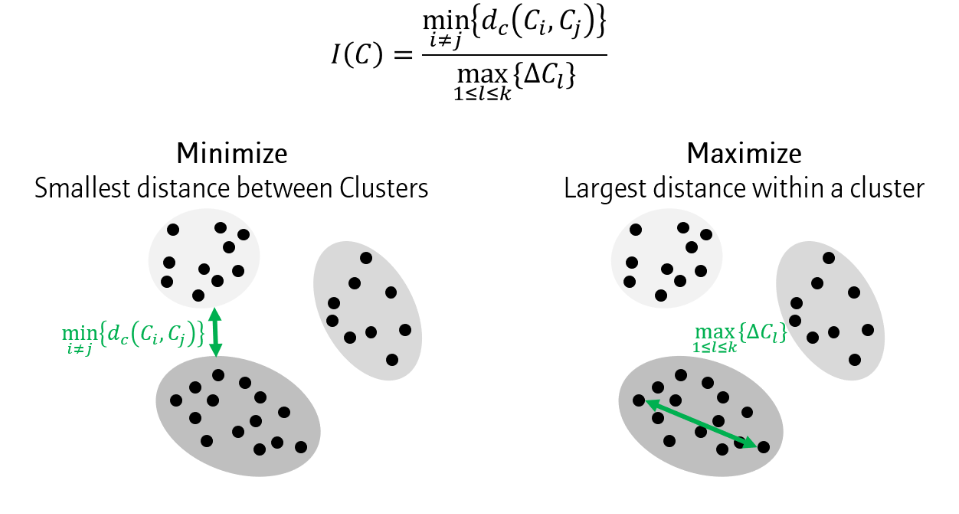
분리도(Separation)과 응집도(Compactness) 비율
- 분자(Separation): 가장 가까운 두 군집의 거리
- 분모(Compactness): 가장뚱뚱한 군집의 지름
-
개념이 직관적이지만 계산 비용이 높고 Outlier에 취약하여 Shilhouette-Score를 선호
코드
from scipy.spatial.distance import pdist, cdist
def calculate_dunn_index(df, features, cluster_label):
# 1. 분모 (Denominator): 군집 내 최대 지름 (Max Intra-cluster Diameter)
s_diam = df.groupby(cluster_label)[features].apply(
lambda x: pdist(x).max()
)
max_diam = s_diam.max() # 모든 군집의 지름 중 가장 뚱뚱한(큰) 값을 선택
# 2. 분자 (Numerator): 군집 간 최소 거리 (Min Inter-cluster Distance)
# apply했을떄 df이 arg로 들어가며 name이 group된 값의 name이 나옴
s_min_dist = df.groupby(cluster_label)[features].apply(
lambda tdf: cdist(tdf, df.loc[df[cluster_label] != tdf.name, features]).min()
)
min_dist = s_min_dist.min() # 모든 군집 간 거리 중 가장 아슬아슬한(작은) 값을 선택
# 3. Dunn Index 계산 (분자 / 분모)
dunn_index = min_dist / max_diam
# 결과 출력 (필요시 주석 처리 가능)
print(f"군집 간 최소 거리 (분자): {min_dist:.4f}")
print(f"군집 내 최대 지름 (분모): {max_diam:.4f}")
print(f"Dunn Index 점수: {dunn_index:.4f}")
return dunn_index
AngDDo