사전 개념
bipartite graph
- 이분 그래프는 노드들이 두 개의 그룹으로 나뉘어 있고, 같은 그룹 내의 노드들 사이에는 간선이 없는 그래프를 말합니다. 즉, 모든 간선은 한 그룹의 노드에서 다른 그룹의 노드로 연결됩니다.
- 예를 들어, 남자와 여자 그룹이 있고, 서로의 그룹 내에서는 아무런 관계가 없지만, 남자와 여자 사이에는 친구 관계가 있을 수 있습니다. 이런 관계를 그래프로 표현하면 이분 그래프가 됩니다.
bipartite graph matching (이분 그래프 매칭)
- 이분 그래프에서 두 그룹 간의 연결(간선)을 최적화하는 문제를 말합니다. 목표는 특정 기준(예: 비용, 거리 등)을 최소화하거나 최대화하는 연결 방식을 찾는 것입니다.
- 이 문제를 해결하기 위한 알고리즘 중 하나가 "헝가리안 알고리즘 (Hungarian algorithm)"입니다.
Hungarian algorithm
- 가로 축:작업자 1, 2, 3
- 세로 축: 일 1, 2, 3 하는데 걸리는 시간
- 행 및 열 감소
- 각 행에서 최소값을 찾아 그 값을 해당 행의 모든 원소에서 뺍니다. 그 다음 각 열에서 최소값을 찾아 그 값을 해당 열의 모든 원소에서 뺍니다.
- 초기 매칭
- 조정된 비용 행렬에서 각 행과 열에 대해 최소 비용의 원소를 선택하여 초기 매칭을 구성합니다. 이때 선택한 원소는 0으로 표시하고, 그 행과 열을 커버링합니다.
- 커버링
- 모든 0 원소를 커버하기 위해 최소한의 행과 열을 선택합니다.
- 커버링을 최소화
- 커버되지 않은 위치에서 가장 작은 원소를 찾아 그 값을 커버되지 않은 모든 행에서 빼고, 커버된 모든 열에 더합니다.
- 매칭 업데이트
- 변경된 비용 행렬로 다시 매칭을 업데이트합니다.
Abstract
- DETR의 느린 수렴이 초기 훈련 단계에서 일관성이 없는 최적화 목표를 유발하는 이분 그래프 매칭의 불안정성에서 비롯된다는 것을 보여준다.
- 본 논문에서는 훈련 과정에서 이분 그래프 일치를 안정화하는 데 도움이 되는 쿼리 노이즈 제거 작업을 도입한다.
- 이를 해결하기 위해 Hungarian loss를 직접적으로 변경하기보단,
- 우회적인 방식으로 Transformer decoder가 noised GT boxes를 denoise하는 task를 추가함으로써 bipartite graph matching의 어려움을 완화시킨다.
- 노이즈 제거 훈련은 Ground truth 경계 상자를 디코더에 공급하며 GT는 이분 그래프 매칭을 거칠 필요가 없기 때문에 간단한 보조 작업으로 취급된다.
- 노이즈 제거 훈련은 이분 매칭 작업을 우회하기 때문에,
- GT와 거의 같은 "노이즈 쿼리"는 "좋은 앵커"로 간주될 수 있다.
- 따라서 노이즈 제거 훈련은 원래 경계 상자를 예측하는 명확한 최적화 목표를 가지고 있으며, 이는 헝가리안 매칭에 의해 초래되는 모호성을 근본적으로 방지한다.
- 한계:
- 노이즈 제거 훈련은 근처에 물체가 없는 앵커에 대해서는 "물체가 없다"고 예측하는 기능이 부족하다.
- 따라서 contrastive denoising(CDN)을 제안한다.
Method
-
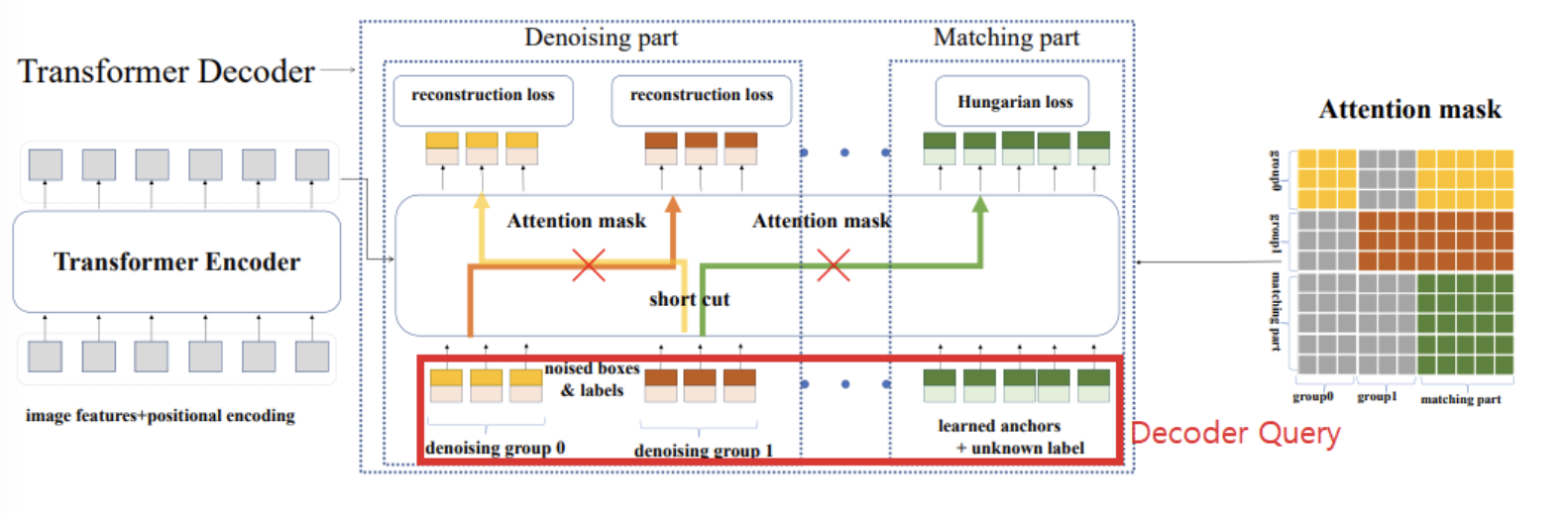
-
매칭 파트는 이분 그래프 매칭을 채택해 일반적인 매칭을 학습하고,
-
노이즈 제거 파트는 GT 객체(GT상자-label 쌍)를 재구성하는 것을 목표로 한다.
-
Attention mask는 다음과 같은 목적이 있다.
- 매칭 파트가 노이즈 제거 파트를 볼 수 없도록 함(정답을 유출해버리는 꼴이 되므로 )
- 노이즈 제거 그룹이 서로를 볼 수 없도록 함
-
Label 임베딩에 노이즈 제거 파트의 쿼리일 경우 1, 매칭 파트의 쿼리일 경우 0을 추가한다.
-
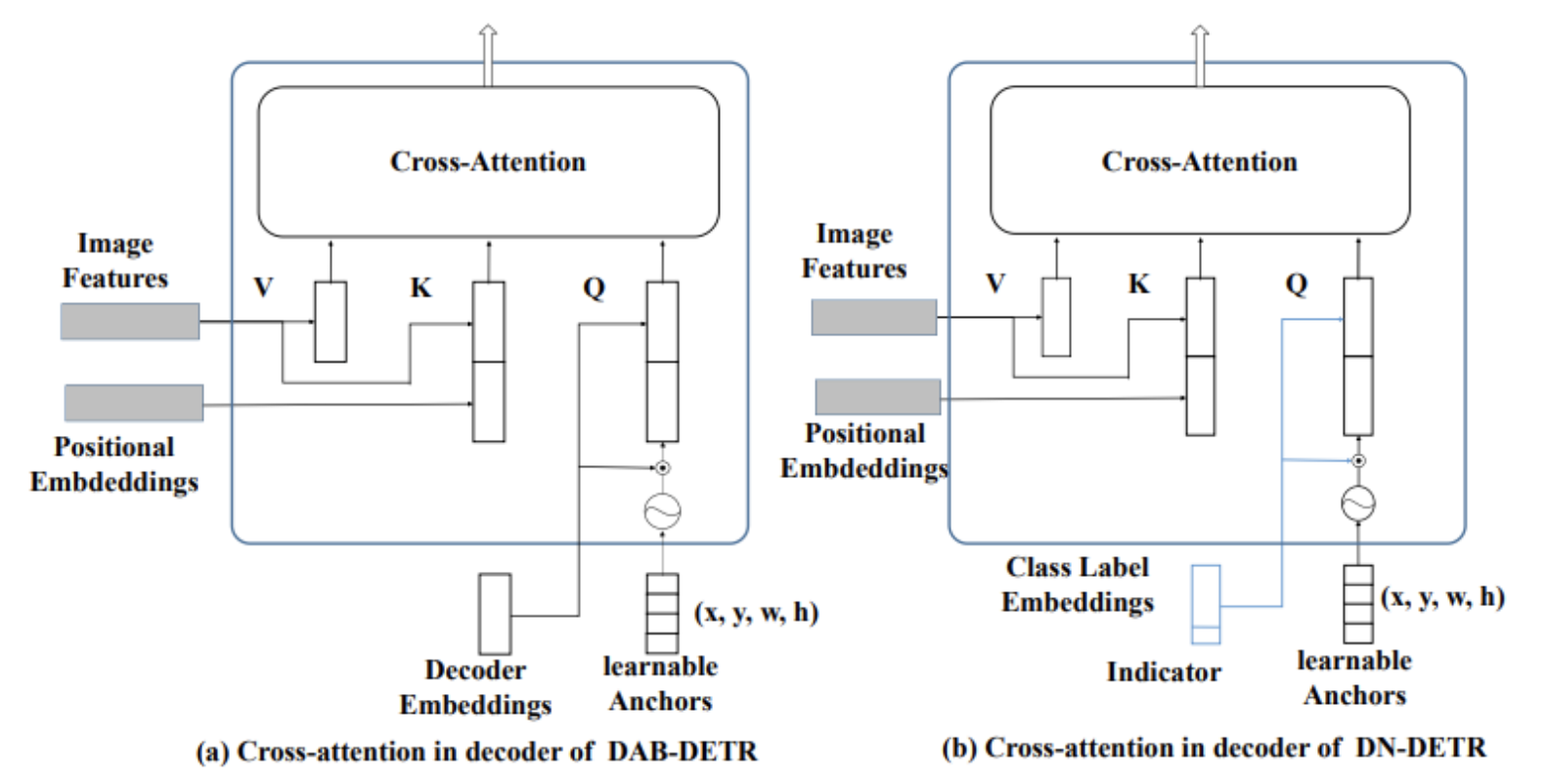
-
MSCOCO의 80개 클래스를 문구(phrase)로 간주하고, 사전 훈련된 언어 모델에서 문구 임베딩을 수집하여 "class label embedding"을 생성합니다.
- 언어 모델은 텍스트 데이터를 학습하여 단어나 문구의 의미를 벡터 형태로 표현할 수 있습니다.
- 논문에서는 이미 학습된 언어 모델을 사용하여 MSCOCO의 80개 클래스 이름(문구)에 대한 임베딩을 얻습니다.
- 즉, "사람", "자동차", "고양이" 등의 클래스 이름을 해당 언어 모델에 입력하면, 각 클래스 이름에 대한 벡터 표현(임베딩)을 얻을 수 있습니다.
-
아마, denosing group에 대해서만 class label embeddings를 사용한 것이 아닐까 추측.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것