Object detection
1.DETR & DETR 3D & PETR
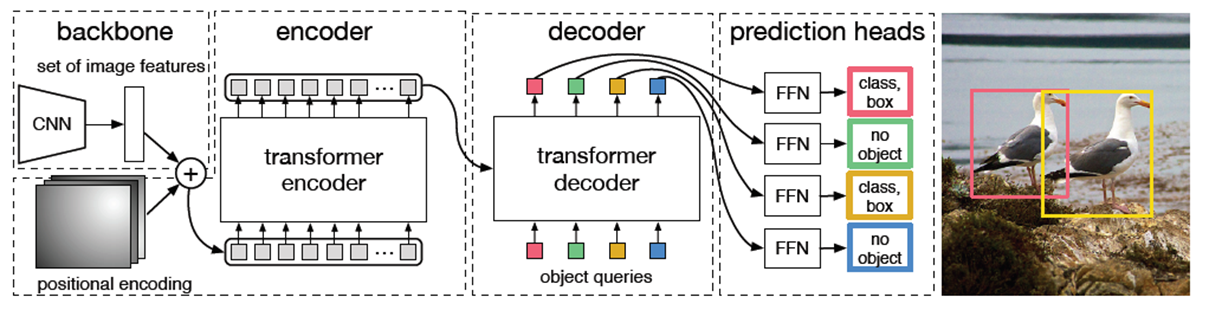
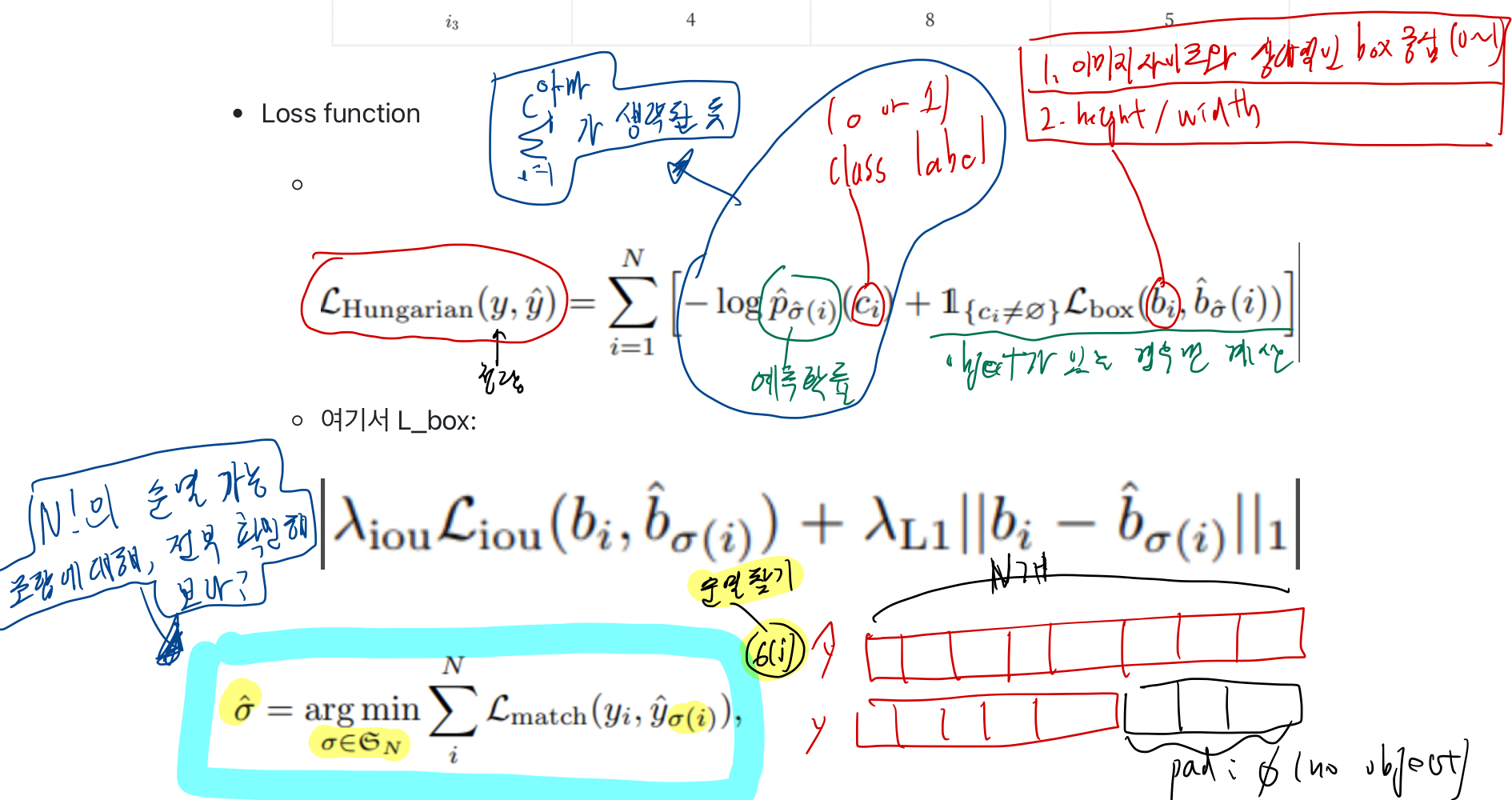
object detection을 direct set prediction 으로 간주하고 해결Partite matching + Transformer encoder decoderbi-partite matchingbounding box 와 ground truth 간 1대 1
2.StreamPETR
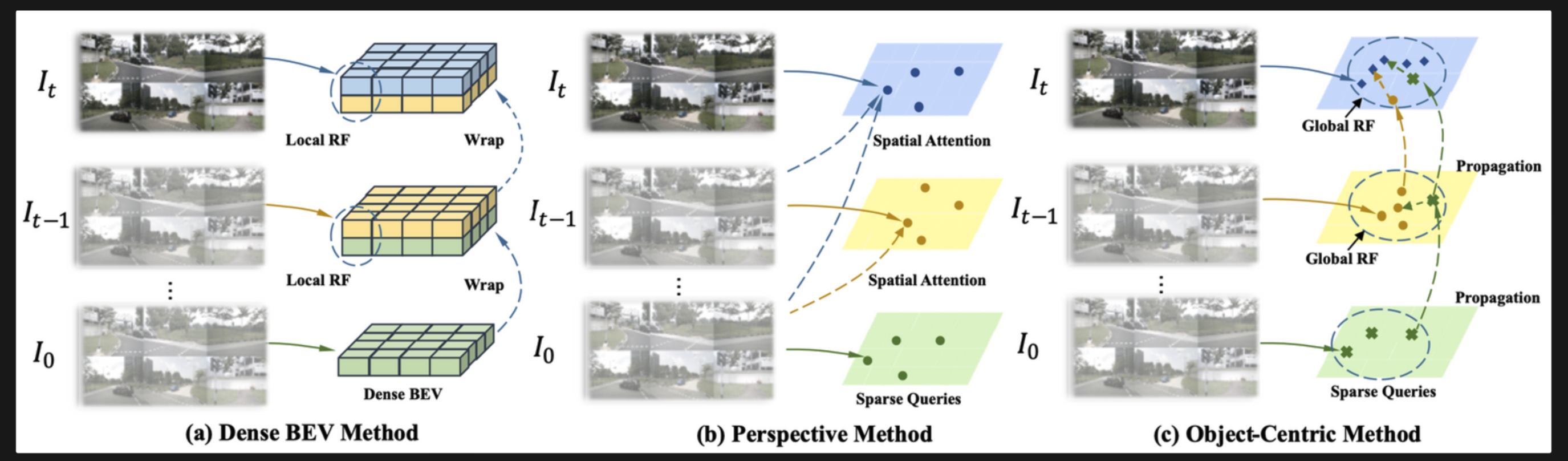
object queries를 통해 frame 마다 long-term historical information 이 전파됩니다.motion aware layer normalization을 이용하여, objects의 움직임을 모델링하였다.(a) Dense BEV method
3.[230616]CAPE: Camera View Position Embedding for Multi-View 3D Object Detection
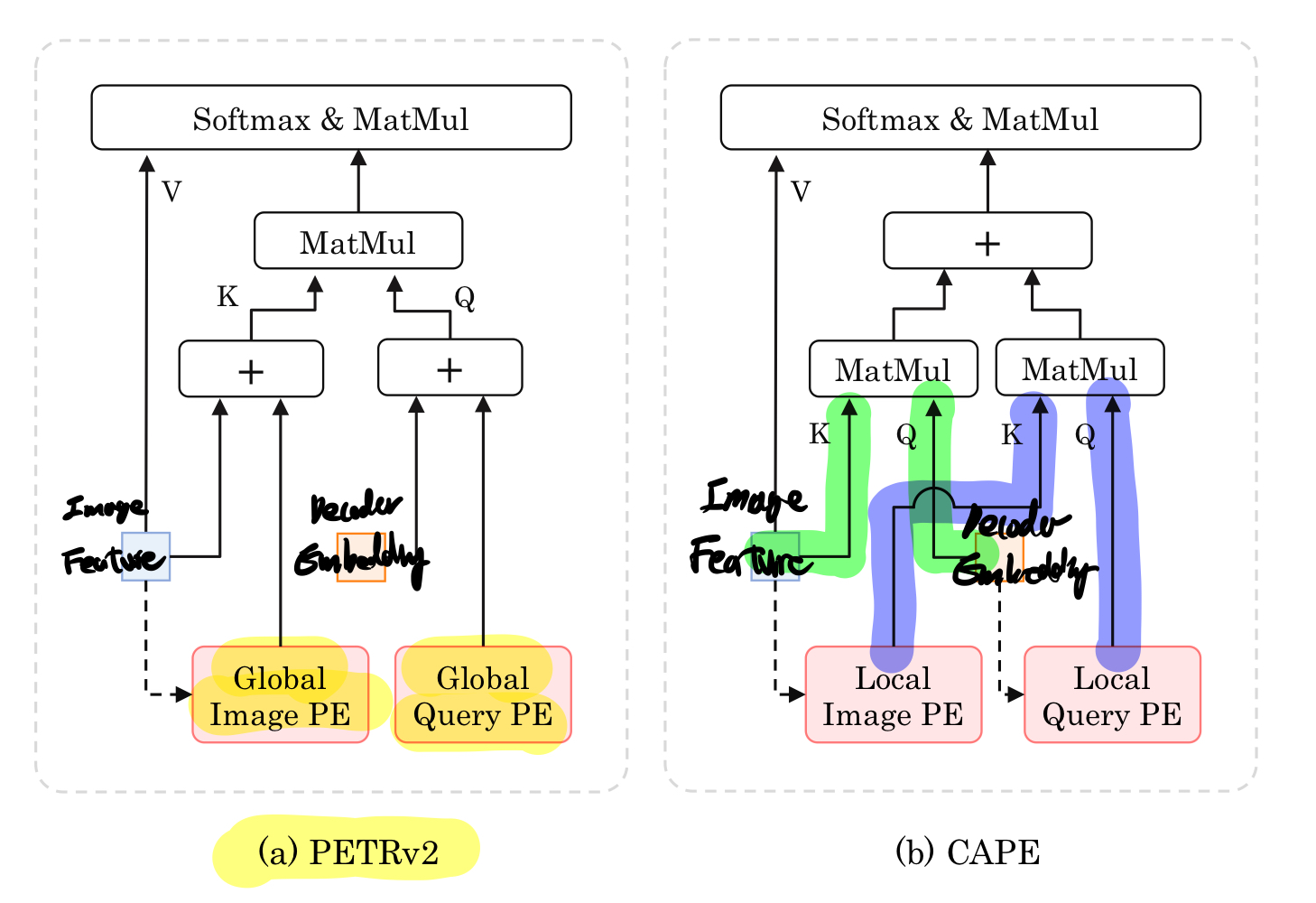
Abstract Introduction Related work DETR-based 2D Detection Monocular 3D Detection Multi-View 3D Detection View Transformation
4.[230623] BEVHeight: A Robust Framework for Vision-based Roadside 3D Object Detection
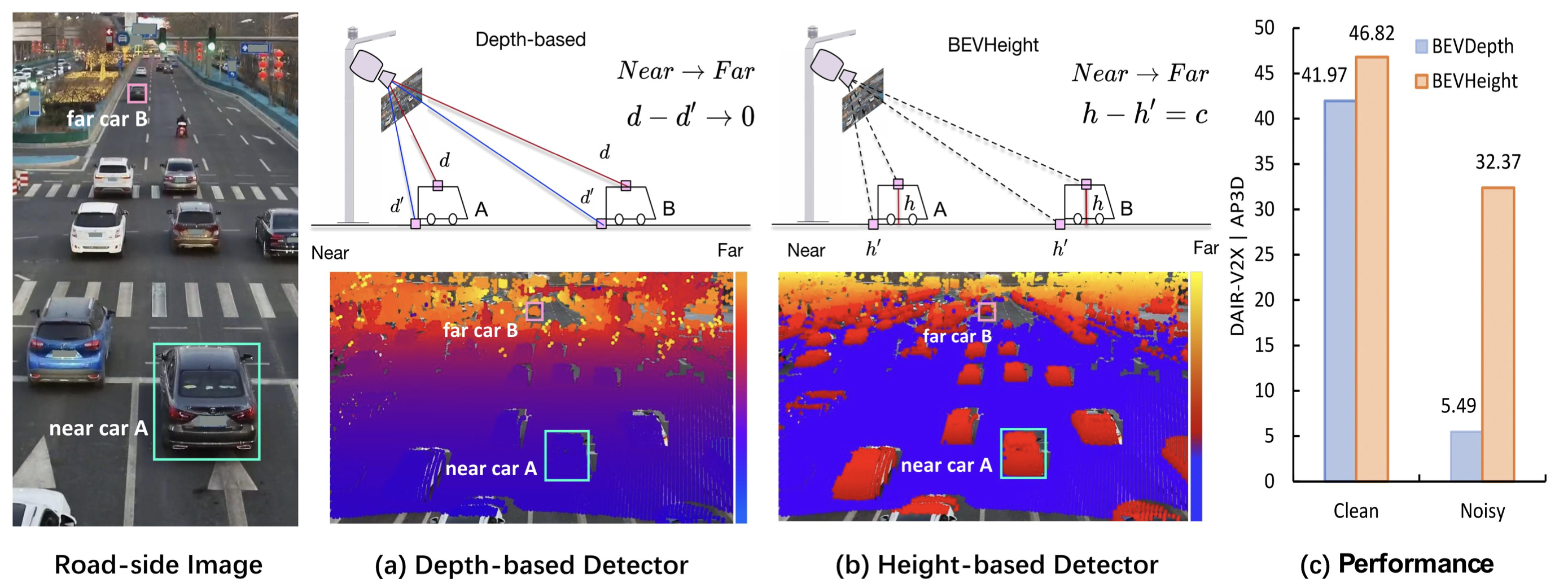
Abstract Introduction Related work Roadside Perception Vision Centric BEV Perception Method Problem Definition Comparing the depth and height Anlay
5.[230630] BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection

dubbed BEVDepth, for camera-based Bird’s-Eye-View (BEV) 3D object detection.leveraging explicit depth supervision.또한, 카메라를 고려한 깊이 추정 모듈을 도입하여 깊이 예측 능력
6.nuScenes/KITTI / Lyft
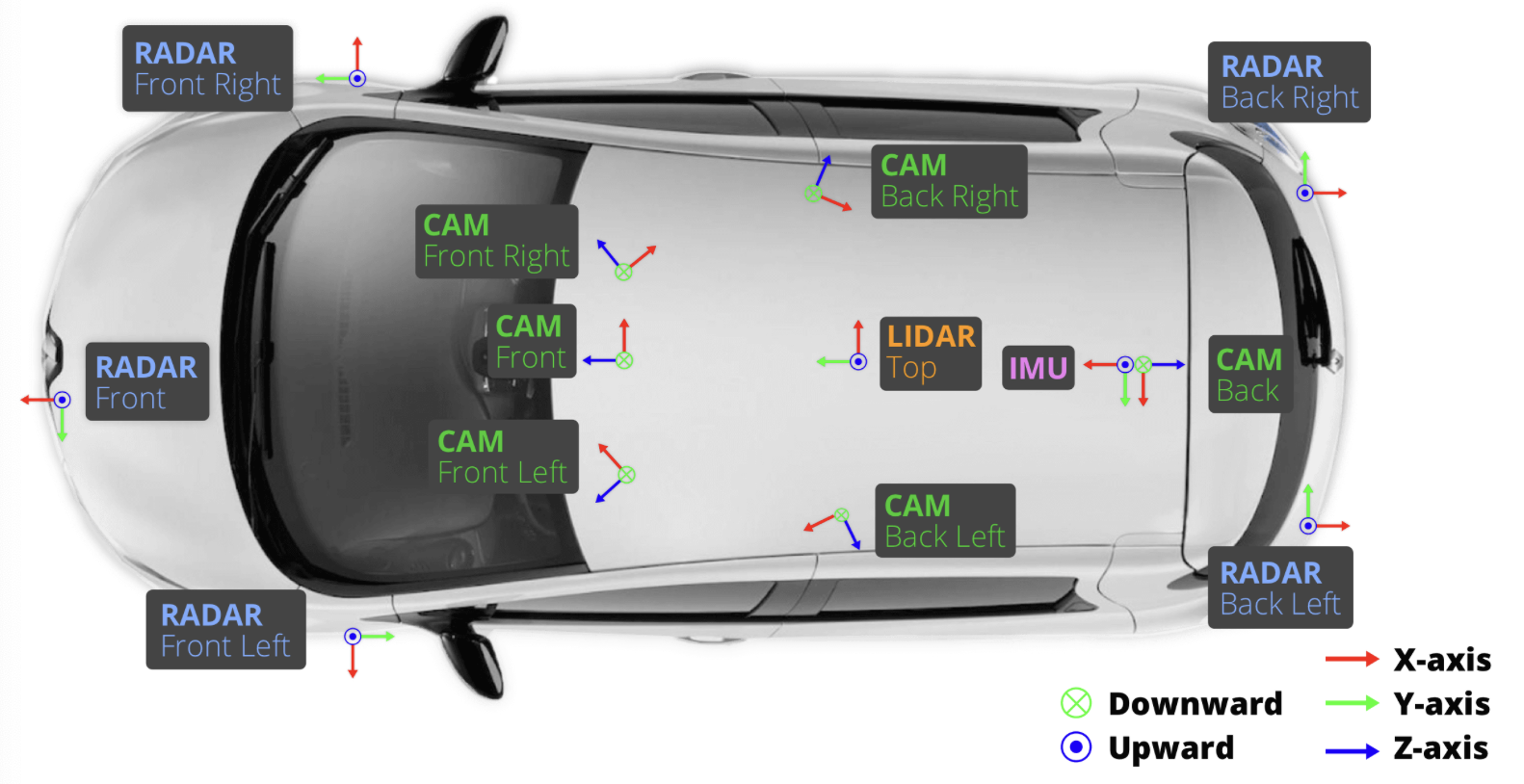
6x camera (Basler acA1600-60gc):12Hz capture frequencyEvetar Lens N118B05518W F1.8 f5.5mm 1/1.8"1/1.8'' CMOS sensor of 1600x1200 resolutionBayer8 form
7.[230804]Grounding DINO (Marrying DINO with Grounded Pre-Training for Open-Set Object Detection)
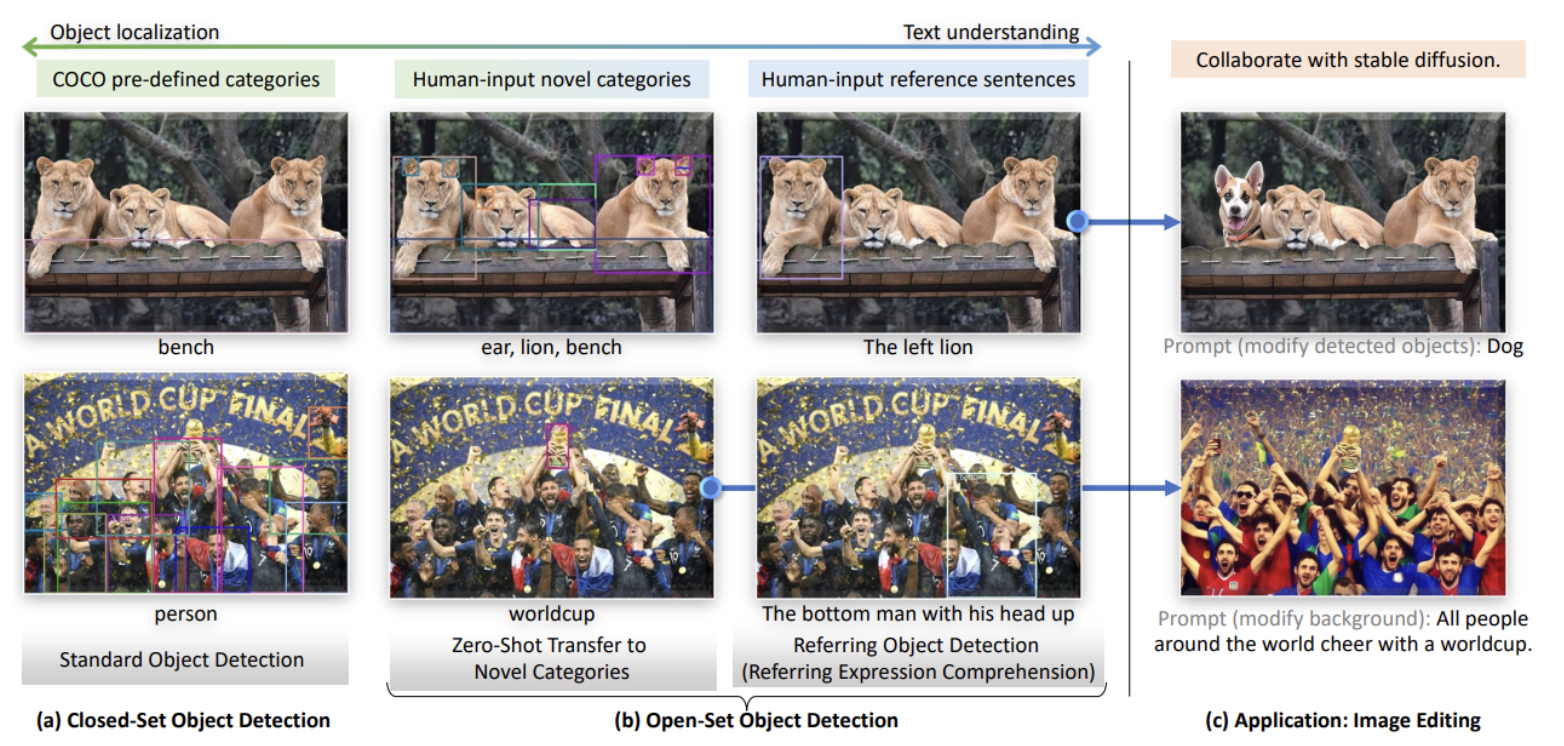
Transformer 기반 detector인 DINO + grounded pre-training을 결합grounded pre-training큰 언어 모델을 미리 학습한 후, 다양한 실세계 환경과 상호작용하며 특정 도메인에 대해 추가적인 지식을 습득하는 것을 의미합니다.
8.[230804]DINO (Emerging Properties in Self-Supervised Vision Transformer)
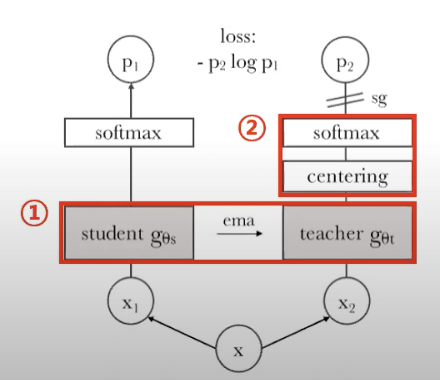
Vision Transformer 의 단점계산량이 많고,inductive bias가 없기 때문에, CNN에 비해 더 많은 데이터가 필요함.unique properties가 나타나지 않는 feature들이 학습됩니다.논문 제안Vit Feature에 self-supervi
9.DETR with Improved DeNoising AnchorBoxes for End-to-End Object Detection (DINO)
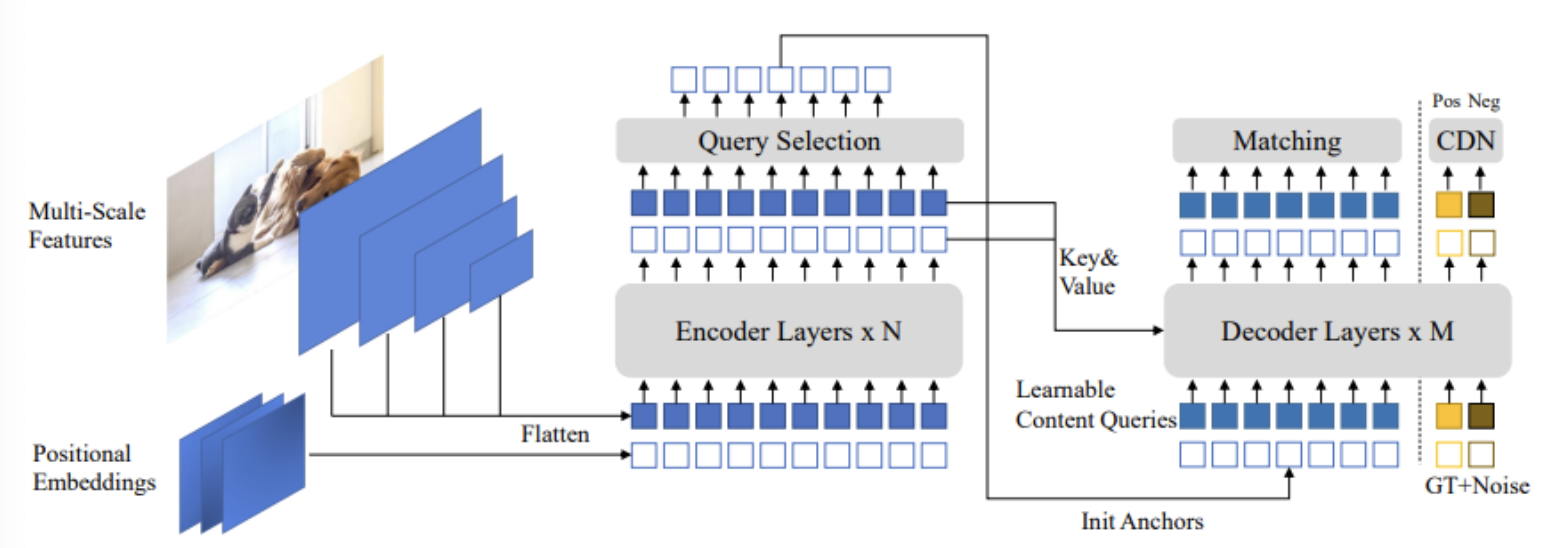
인코더까지는 특별할 것은 없다. 새로운 혼합 쿼리 선택에 의해 앵커를 초기화하고,인코더와 디코더가 결합되는 부분에서 deformable attention을 사용한다. 또한 동적 앵커 박스와 노이즈 제거 훈련, look forward twice 전략을 사용한다.DETR
10.[230804] DAB-DETR : Dynamic Anchor Boxes are Better Queries for DETR 논문 리뷰
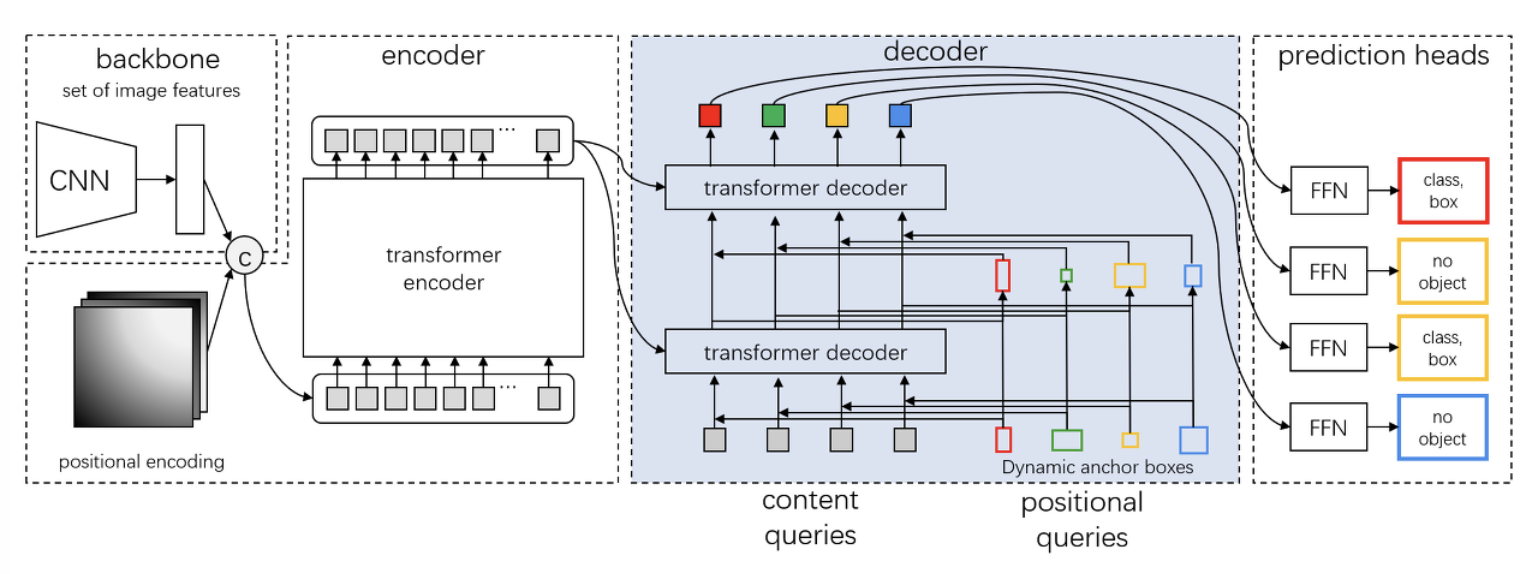
쿼리에 대한 더 깊은 이해를 통해, 동적 앵커 박스를 사용하는 새로운 쿼리 공식을 제시쿼리는 positional 파트(훈련 가능한 쿼리)와 content 파트(디코더 임베딩)로 구성4D 앵커 박스(x,y,w,h)를 사용한다.앵커박스는 계층별로 동적으로 업데이트된다.DE
11.[230804]DN-DETR: Accelerate DETR Training by Introducing Query DeNoising

매칭 파트는 이분 그래프 매칭을 채택해 일반적인 매칭을 학습하고,노이즈 제거 파트는 GT 객체(GT상자-label 쌍)를 재구성하는 것을 목표로 한다.Attention mask는 다음과 같은 목적이 있다.매칭 파트가 노이즈 제거 파트를 볼 수 없도록 함(노이즈 파트가
12.transformer 이전 object detection
Regional Proposal과 Classification이 순차적으로기존에는 이미지에서 object detection을 위해 sliding window방식을 이용Sliding window 방식은 이미지에서 모든 영역을 다양한 크기의 window (differenct
13.[230811] Deformable DETR : Deformable Transformers for End-to-End Object Detection 논문 리뷰
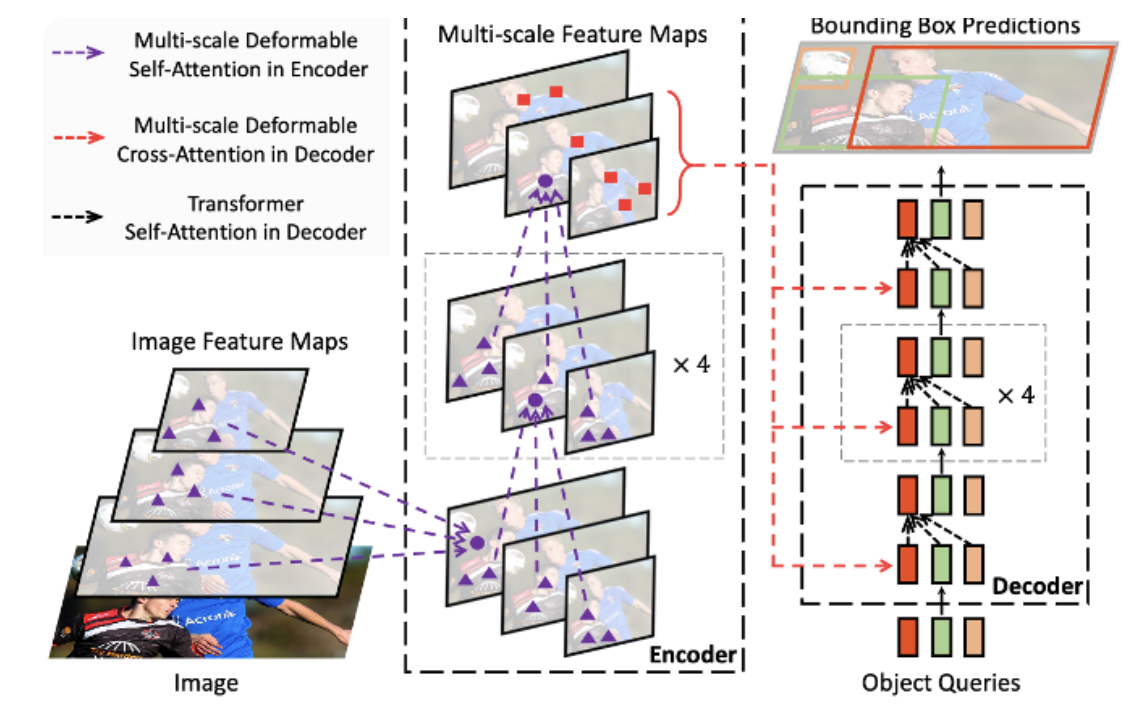
DETR의 문제점 극복느린 수렴 극복DETRAttention weight가 uniform하게 초기화되고 나서, 의미있는 위치에 focus 시키기 위해 학습하는 시간이 매우 길다. (uniform이란, 평균이 0이고 분산이 1인 분포)ex) key가 160개라면, 1/1
14.[230818] Grounded language-image pre-training. (GLIP)
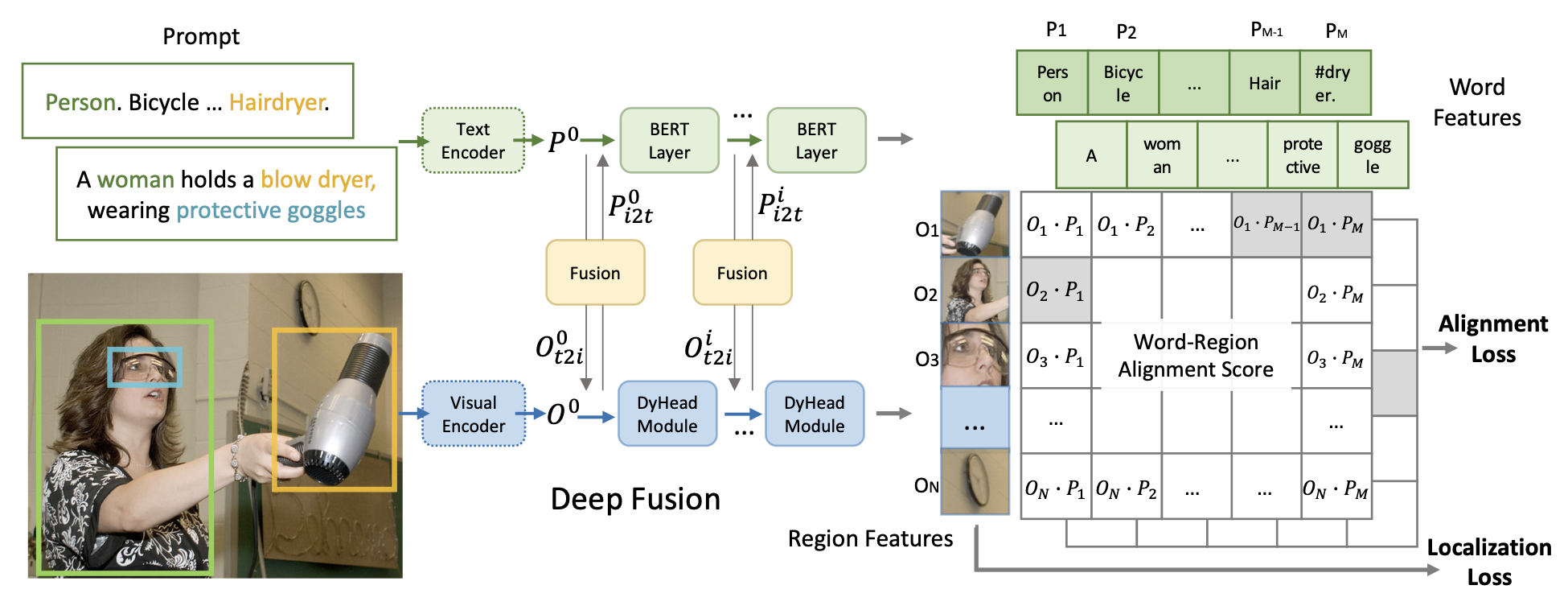
test
15.dynamic Label Assignment Strategy
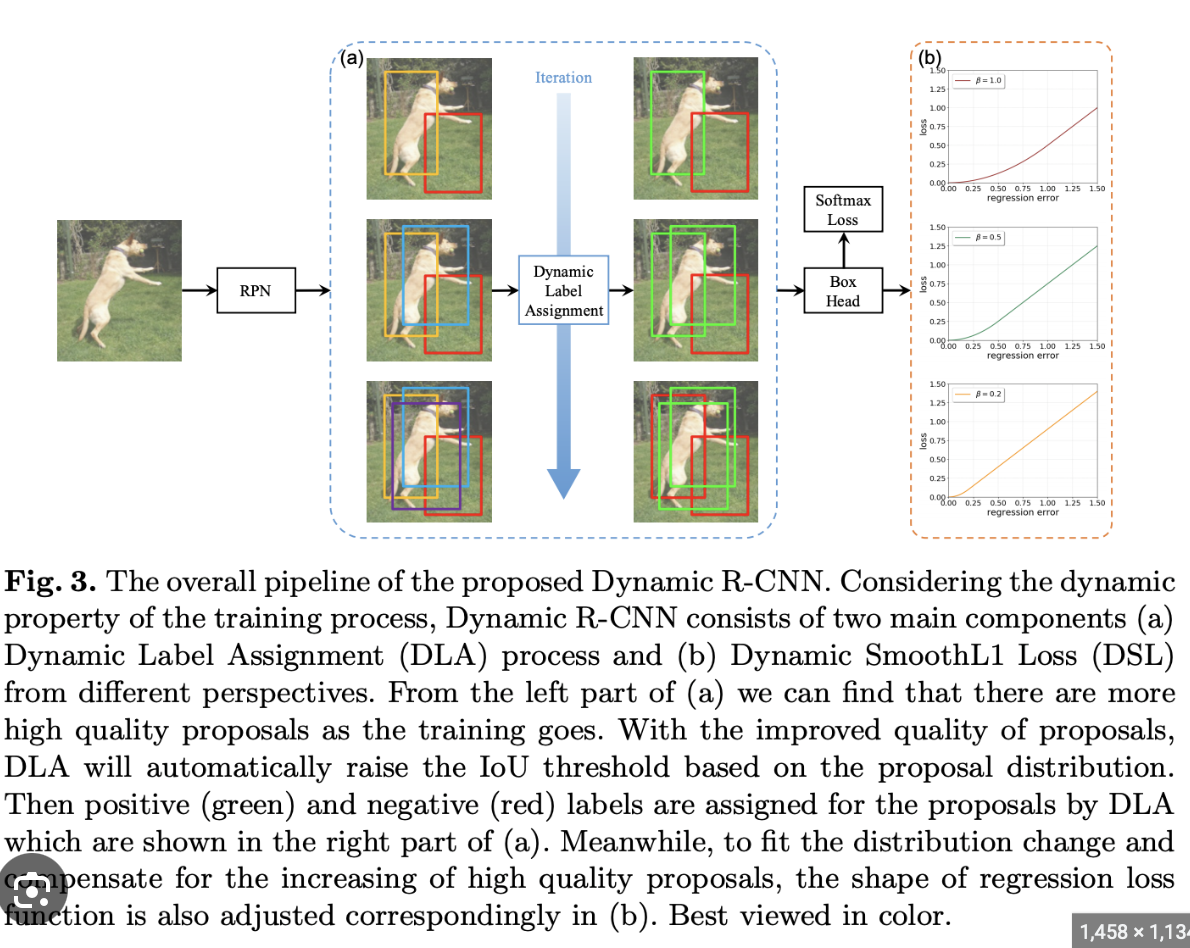
상황: 이미지에 작은 강아지와 큰 고양이가 있습니다. 모델은 이 두 동물을 탐지하고 바운딩 박스를 그립니다.모델이 작은 강아지 주변에 예측된 바운딩 박스와 큰 고양이 주변에 예측된 바운딩 박스를 생성합니다.전통적인 레이블 할당 전략을 사용하면, 각 예측된 바운딩 박스는
16.CSP(Cross Stage Partial) Net

기존 object detection: 연산량 많음, inference time 길다.연산량을 완화시키고, inference time 줄이는 모델이 Cross Stage Partial Network(CSPNet)연상량이 많아지는 이유: 네트워크가 optimaization
17.Label Assignment Strategy
객체 탐지 모델은 이미지 내의 여러 개체를 탐지하려고 할 때, 각각의 개체에 대한 바운딩 박스(bounding box)와 해당 개체의 클래스 레이블을 예측합니다. 이때 모델이 예측하는 여러 바운딩 박스 중에서 실제 정답(ground truth) 바운딩 박스와 얼마나 일
18.anchor-based 모델
Anchor-based 접근법의 핵심 아이디어이미지의 여러 위치와 다양한 크기, 비율에서 사전 정의된 바운딩 박스(이를 '앵커(anchor) 박스'라고 함)를 사용하는 것Anchor-based 모델의 장점 및 특징은 다음과 같습니다:정규화된 예측: 앵커 박스를 사용하면
19.one-stage detector VS two-stage detector
객체 탐지(Object Detection) 모델은 크게 "One-Stage Detector"와 "Two-Stage Detector"로 나뉩니다. 두 접근법은 객체의 위치와 클래스를 동시에 예측하는 방식에 차이가 있습니다.정의: One-stage detector는 객체의
20.dynamic label assignment
Dynamic Label Assignment (DLA)는 객체 탐지에서 최근에 주목받고 있는 개념입니다.전통적인 객체 탐지 모델, 특히 anchor-based 모델은 고정된 기준(예: IoU 임계값)을 사용하여 예측된 바운딩 박스와 ground truth 바운딩 박스
21.YOLO v7
https://openaccess.thecvf.com/content/CVPR2023/papers/Wang_YOLOv7_Trainable_Bag-of-Freebies_Sets_New_State-of-the-Art_for_Real-Time_Object_Detect
22.DETR (End-to-End Object Detection with Transformers)
Transformer는 시퀀스 데이터를 처리하는 뛰어난 능력을 가지고 있어, 이미지의 다양한 부분을 연결하여 전체적인 의미를 파악하는데 더 용이합니다. 객체 탐지에서 먼 객체 간의 관계나 컨텍스트를 더 잘 이해할 수 있는 장점객체들의 위치나 순서는 중요한 정보가 될 수
23.[ RT DETR ] DETRs Beat YOLOs on Real-time Object Detection
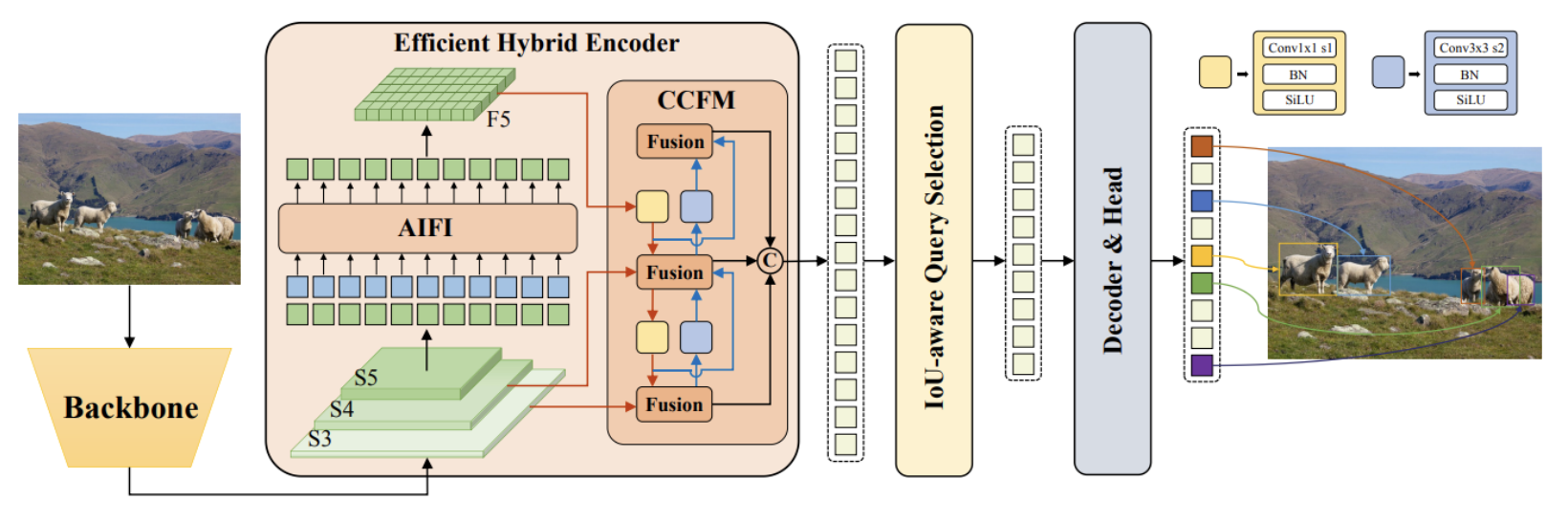
https://arxiv.org/pdf/2304.08069https://kimjy99.github.io/논문리뷰/rt-detr/CNN아키텍처는 초기 2단계에서 1단계로 진화했으며 anchor-based 및 anchor-free 두 가지 detectio