[23,1][4635] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
Large Language model
-1. 들어가기 전에
- https://arxiv.org/pdf/2301.12597
- https://github.com/salesforce/LAVIS/tree/main/projects/blip2
- LAVIS - A One-stop Library for Language-Vision Intelligence
- 10000 stars
바쁘신 분들을 위한 5줄 요약
Image encoder의 representation을Large Language Model의 input으로 사용하기 위해,Image encoder의 representation을 align 하기 위한 연구 ( 부가적으로,Image encoder의 representation자체를 language aware하게 학습하는 방법 자체도 contribution)- frozen pre-trained
Image Encoder와Large Language Model이 있을 때, 이 둘을 그대로 살리면서 ->Vision-Language pretraining을 수행하는 "Generic and efficient(계산 효율적, 학습 파라미터 수 엄청 줄임)"한 방법 제시 - Modality Gap을 lightweight
Querying Transformer(Q-former)을 도입하여 2단게로 학습하였는데 (백문이 불여일견, 아래 그림 3장을 보는게 전부다.) - 첫번째 학습 단계: frozen
Image Encoder로부터, text와 가장 관련있는 visual representation을 Q-former가 배우는 단계 - 두번째 학습 단계: frozen
LLM을 활용해서,Q-Former의 output visual representation이, LLM이 해석가능 하도록 학습시키는 단계
0. Abstract
- 과거 VLM 들은, End-to-end training 접근법을 택했기 때문에 -> pre-training 시 계산량이 많았습니다.
- Modality Gap을 lightweight
Querying Transformer(Q-former) 로 극복함- Q-former은 두 단계로 pre-training 됩니다.
- 학습 결과, zero-shot
자연어 지시 명령 input을 따르는, image-to-text 생성능력을 모델이 갖추게됨!- 예: visual knowledge reasoning / visual conversation
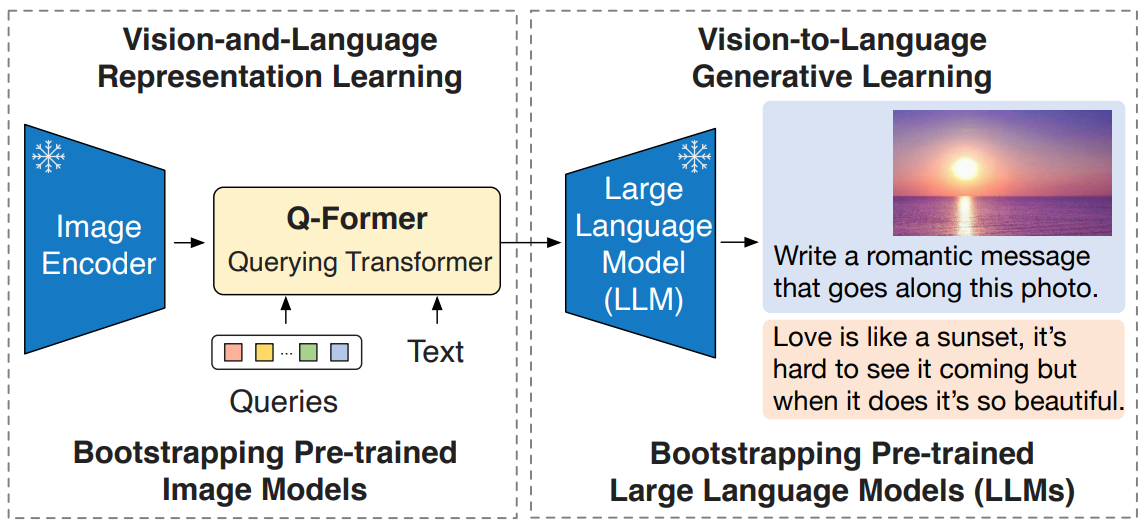
3. Method
- Q-former 첫번째 학습 단계
- frozen
Image Encoder로부터, vision-languagerepresentation learning을 수행 - text와 가장 관련있는 visual representation을 Q-former가 배우는 단계
- frozen
- Q-former 두번째 학습 단계
- frozen
LLM을 활용해서, Vision-to-Languagegenerative learning을 수행 Q-Former의 output visual representation이, LLM이 해석가능 하도록 학습시키는 단계
- frozen
3.1. Model Architecture
-
input 이미지 해상도에 상관없이, 이미지로부터 고정된 개수의 output features를 추출합니다.
-
Q-former은 2개의 transformer submodule로 구성됩니다. (같은 self attention layer을 공유합니다.)
- Image Transformer
- Text Transformer: 학습과정에서 text encoder로도 기능하고, text decoder로도 기능합니다.
- text encoder로써 -> ITC
- text decoder로써 -> ITG
-
우리는 Q-former을 로 초기화한 후, 학습시킵니다.
- 다만, cross-attention layer은 random하게 초기화합니다.
-
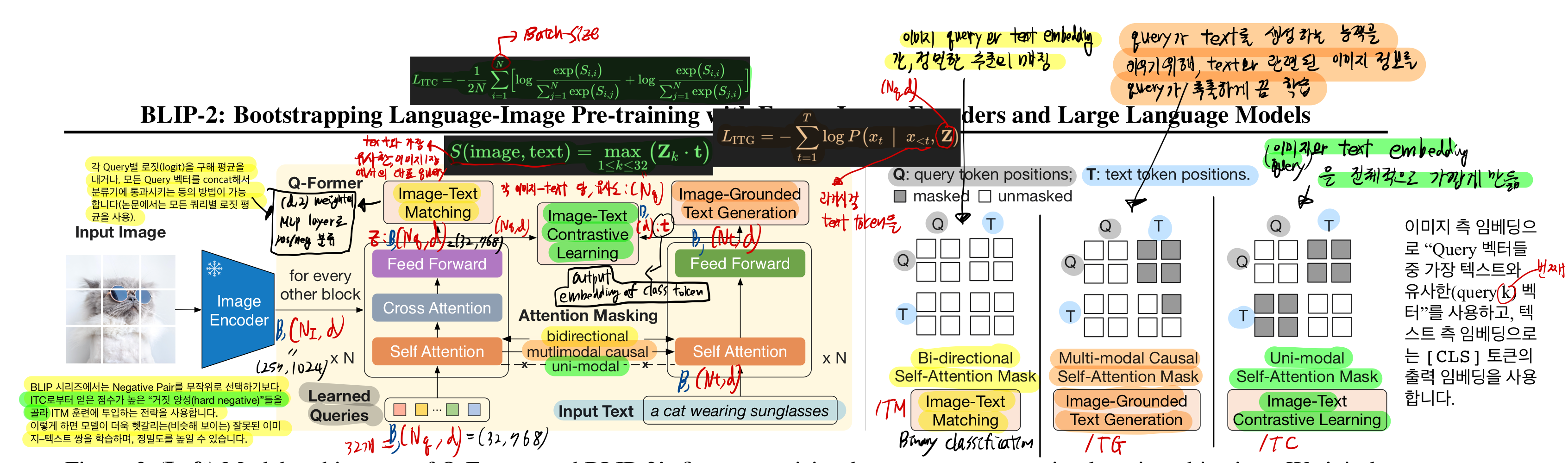
3.2. Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
- Q-former 첫번째 학습 단계
- frozen
Image Encoder로부터, vision-languagerepresentation learning을 수행 - text와 가장 관련있는 visual representation을 Q-former가 배우는 단계
- frozen
- image-text pair (1-1)로 학습함
- 3개의 pre-training objectives를 jointly optimize 합니다.
- 이 때, 같은 input format과 model parameter을 공유합니다.
Image-Text Constrative Learning (ITC) (초록색)
- text transformer은 t를 출력하는데, 이 t는 [CLS] token의 output embedding
- input:
- t와 각 query와의 유사도를 각각 계산한 후, 가장 높은 유사도 값을 Image-text similarity로 선정
- 우리는 image Encoder를 froze시켰기 때문에, GPU에 더 많은 batch size를 배치할 수 있어서,
- 우리는 in-batch negatives를 학습 시 활용합니다.
- 과거 연구에는, batch size가 크지 않았기 때문에, momentum queue(bank)와 같은 기법으로 negatives를 샘플링 하였습니다.
Image-grounded Text Generation (ITG) (주황색)
- Q-former의 query가 text를 생성하는 능력을 갖추도록 하는게 학습목표
- Q-former의 아키텍쳐 구조랑, frozen image encoder와 text-token간 직접적 상호작용을 할 수 없기 때문에,
- text를 생성하는데에 필요한 정보가 queries로부터 반드시 추출되어야만 합니다.
- 그리고 그 queries는 text-tokens에 (self-attention layers를 통해) 전달됩니다.
- 그러므로, queries는 text에 관한 모든 정보를 담은 visual feature을 추출하도록 학습됩니다.
- text를 생성하는데에 필요한 정보가 queries로부터 반드시 추출되어야만 합니다.
- 각 text token은 모든 queries와 이전 text token과 attetion할 수 있습니다.
- ITG 학습에서는, text transformer가 decoder로 쓰였기 때문에, text transformer input으로 를 입력하여
- decoder task 임을 명시합니다. ("이 뒤의 text는 casual으로 생성할 대상" 임을 명시)
Image-Text Matching (ITM) (노란색)
- binary classification 문제입니다.
- image-text pair가 positive(matched)인지 negative(unmatched) 인지 분류하는
hard negative mining strategy를 사용하여 -> informative negative pairs를 생성- 쉽게 말하면, ITC로 부터 점수가 높은 hard negative들을 골라, ITM 훈련에 투입하는 전략을 사용합니다.
- 이렇게 하면, 모델이 더욱 헷갈리는 잘못된 이미지-텍스트 쌍을 구분하는 능력을 갖출 수 있게 됩니다.
3.3. Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
- Q-former 두번째 학습 단계
- frozen
LLM을 활용해서, Vision-to-Languagegenerative learning을 수행 Q-Former의 output visual representation이, LLM가 이해할 수 있는 형식으로 시각 정보를 요약/전달 하는 방식을 학습시키는 단계 (어떤 식으로 Query를 뽑아야 LLM이 쉽게 문장을 생성할 수 있는가?)- LLM의 generative lanuage 능력을 가져다 쓸 수 있게 하기 위함!
- frozen
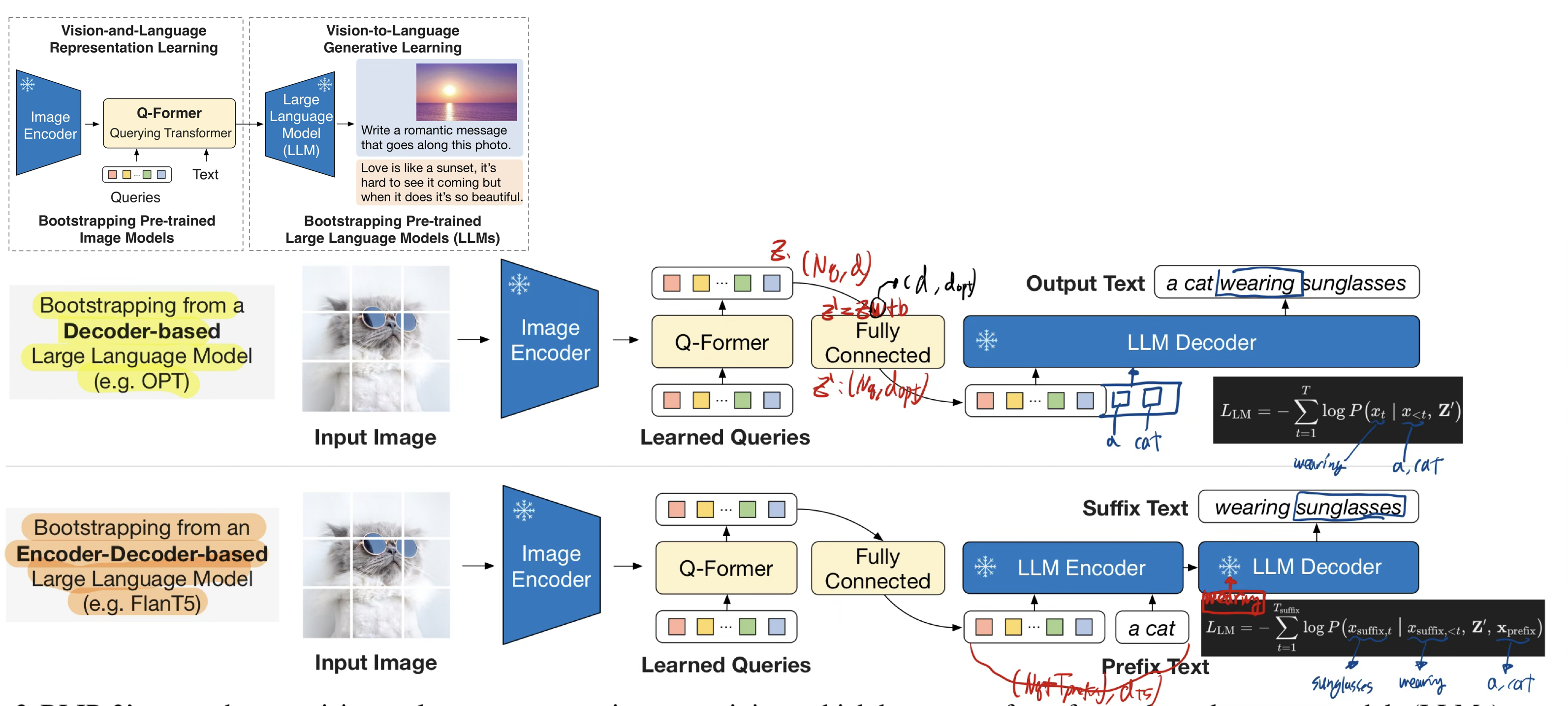
Q-former이 생성한 query embeddings를 input text embeddings 앞에 추가합니다.Q-former이 생성한 query embeddings가 이미 언어와 관련된 이미지 특징을 잘 추출한 상태이기 때문에,- LLM이 vision-language 정렬을 따로 학습할 필요가 없어지고 -> 그래서 우리는 LLM을 froze하여 catastrophic forgetting 문제를 겪지 않아도 됩니다.
3.4. Model Pre-training
- 224 by 224 이미지 를 학습시 사용
- 증강 방법
- random resized cropping
- horizontal flipping
- 증강 방법
4. Experiment
- 더욱 강력한 이미지 인코더(ViT-g)와 더 큰 LLM일수록 성능이 향상된다. (Scabality 확보)
- 1단계(Representation Learning)에서 Q-Former를 먼저 학습해두면, 2단계(Generative Learning)에서 LLM이 시각정보를 수월하게 받아들인다.
- 이미지 캡셔닝(task)에서는 “a photo of”라는 프롬프트를 사용해 LLM을 디코딩하고, Q-Former와 이미지 인코더만 업데이트하여 최첨단 성능을 얻는다.
- VQA 파인튜닝 시, 질문 토큰을 Q-Former에도 입력해 더 관련성 높은 이미지를 파악하게 한다.
- 이미지-텍스트 검색은 1단계 학습 모델만 사용(LLM 없이)
- 전체적으로 BLIP-2는 적은 파라미터와 효율적인 두 단계 학습으로, 다양한 비전-언어 과제에서 높은 성능과 범용성을 지닌다.
5. 한계점
1. In-context Learning 관련 한계
“Recent LLMs can perform in-context learning given few-shot examples. However, our experiments with BLIP-2 do not observe an improved VQA performance when providing the LLM with in-context VQA examples.”
- In-context Learning이란?
- BLIP-2에서의 현상
- BLIP-2 모델에 VQA 태스크(Visual Question Answering)용 몇 개의 예시(“in-context examples”)를 제공해도, 성능이 향상되지 않았습니다.
- 즉, 일반적인 LLM들이 보이는 ‘few-shot prompt’ 활용 능력(“~만큼 예시를 주면 더 잘 맞힌다”)이 BLIP-2에서는 뚜렷하게 관찰되지 않았습니다.
1.1. 원인: Pre-training Dataset 구조의 제한
“We attribute the lack of in-context learning capability to our pre-training dataset, which only contains a single image-text pair per sample. The LLMs cannot learn from it the correlation among multiple image-text pairs in a single sequence.”
단일 시퀀스에 여러 예시가 왜 중요한가?
-
예시 간 연결성 파악
- In-context learning에서는 여러 개의 예시가 한 줄로 이어져 있어야, 모델이 “예시1 → 예시2 → … → 예시N”의 패턴을 같은 컨텍스트에서 순차적으로 살펴볼 수 있습니다.
- 예: [ “Q1: … A1: …”, “Q2: … A2: …”, “Q3: … A3: …” ] 식으로 연결되어 있으면, 모델이 “Q와 A 사이 매핑이 어떤 식으로 이뤄지는지”를 한 덩어리로 볼 수 있습니다.
-
흐름(Sequence)을 통한 규칙 학습
- 모델이 예시들을 하나씩 읽으며, “비슷한 질문 형태에는 비슷한 답변 형태가 따른다” 또는 “질문 속 특정 키워드를 주목해야 하는구나” 같은 일관된 규칙을 시퀀스 내에서 발견할 수 있습니다.
- 이는 모델 내부 파라미터를 업데이트하지 않고도, 입력 텍스트(시퀀스)에 내장된 예시 간 비교로부터 규칙을 추론하는 방식입니다.
-
연속 맥락(Context)
- 일반적으로 자연어 모델은 입력을 왼쪽에서 오른쪽(혹은 양방향)으로 읽으며, “이미 봤던 토큰들”로부터 맥락을 형성합니다.
- 예시들을 하나의 시퀀스에 몰아서 제공해야, 모델이 현재 예시를 해석할 때 이전 예시(토큰들)에서 발견된 패턴을 그대로 참조·활용하기 쉽습니다.
BLIP-2 데이터 구조의 특징: 1 이미지 : 1 텍스트
- BLIP-2가 사전학습한 데이터(예: COCO, LAION 등)는 일반적으로 “한 장의 이미지에 대응되는 하나의 텍스트(캡션)” 형태로 독립된 샘플이 분리되어 있습니다.
- 즉, “이미지1 + 문장1”은 별도의 샘플, “이미지2 + 문장2”는 또 다른 샘플로 개별 처리됩니다.
- 이렇게 한 샘플 = (이미지, 텍스트)로 구획되어 있으면, 모델이 한 시퀀스(한 번의 입력) 안에서 다수의 이미지-텍스트 쌍을 연쇄적으로 볼 기회가 없습니다.
왜 단일 시퀀스에 다중 예시가 없으면 In-context Learning이 어려운가?
-
샘플 간 맥락이 단절
- “(이미지1, 텍스트1)”을 처리한 뒤, 그다음에 “(이미지2, 텍스트2)”를 다른 입력으로 처리한다면, 모델 입장에서는 “이전 샘플이 다음 샘플과 연결되어 있다”는 사실을 알 수 없습니다.
- 모델은 각 샘플을 독립적인 데이터로 인식하므로, 예시들을 서로 비교·대조할 기회가 없습니다.
-
복수의 예시로부터 규칙 추론 불가
- In-context learning의 핵심은 “여러 예시의 Q&A를 한 시퀀스에서 연달아 제시해, 모델이 그 패턴을 즉각적(동적)으로 파악”하는 겁니다.
- 하지만 BLIP-2 데이터 구조처럼, 한 시퀀스(배치)에 이미지-텍스트가 오직 1:1로 들어있으면, 단일 예시만 보고 답을 내야 하는 형태가 됩니다.
- 이때 모델은 “예시 간 차이와 공통점”을 한 자리에서 학습하기 어렵습니다.
-
시퀀스 구조(Interleaving)
- In-context learning을 촉진하려면, (이미지1 + 질문1 + 답1) → (이미지2 + 질문2 + 답2) → … 처럼 한 시퀀스에 여러 쌍을 서로 얽혀(interleaved) 배치해, “연속된 학습 맥락”을 제공해야 합니다.
실제 예시 비교
-
(가) 단일 샘플(현재 BLIP-2)
Input 시퀀스 #1: [이미지1 + 텍스트1] (모델 처리 후 끝) Input 시퀀스 #2: [이미지2 + 텍스트2] (모델 처리 후 끝) ...- 모델은 각 시퀀스를 완전히 독립적으로 본다.
- 시퀀스 #1을 다 처리해도, 시퀀스 #2가 이전 시퀀스와 관련 있다고 생각하지 않는다.
-
(나) Interleaved 샘플(이상적 In-context 구성)
Input 시퀀스: [이미지1, 질문1, 답1, 이미지2, 질문2, 답2, ..., 이미지N, 질문N, 답N] -> 한 번의 입력에서 여러 예시를 순서대로 접함 -> "아, 질문 형태와 답변 간 관계가 이런 식으로 바뀌는구나..." 등 패턴을 추론- 모델이 시퀀스 맨 앞의 예시들을 보고, “아! 이런 유형 질문에는 이렇게 답하는군”하고 이해하면, 맨 뒤의 새 질문에 대해서도 비슷하게 접근하려고 시도함.
- 이렇게 “학습(파라미터 업데이트)” 없이도, 입력 내부 구조를 통해 즉석에서 규칙을 익히는 것이 in-context learning.
1.2. Flamingo 논문의 동일한 관찰
“The same observation is also reported in the Flamingo paper, which uses a close-sourced interleaved image and text dataset (M3W) with multiple image-text pairs per sequence. We aim to create a similar dataset in future work.”
-
Flamingo 논문에서도 비슷한 문제 인지
- Flamingo(2022) 모델도,
다중 이미지-텍스트 쌍이 한 시퀀스에 들어있어야in-context learning이 잘 이루어진다고 주장합니다. - Flamingo가 사용한 M3W라는 데이터셋은 여러 이미지와 텍스트가 서로 얽힌 형식이지만 폐쇄형(공개되지 않음)이므로, BLIP-2 팀은 동일하게 활용하기 어려웠습니다.
- Flamingo(2022) 모델도,
-
향후 과제
- BLIP-2 저자들은 “비슷한(interleaved) 데이터셋”을 만들 계획임을 밝히고 있습니다.
- 즉,
여러 개의 이미지-텍스트 쌍을 한 시퀀스에 배치해in-context learning을 제대로 지원하는 방향을 모색 중이라는 뜻입니다.
