Large Language model
1.Language Conditioned Imitation Learning over Unstructured Data
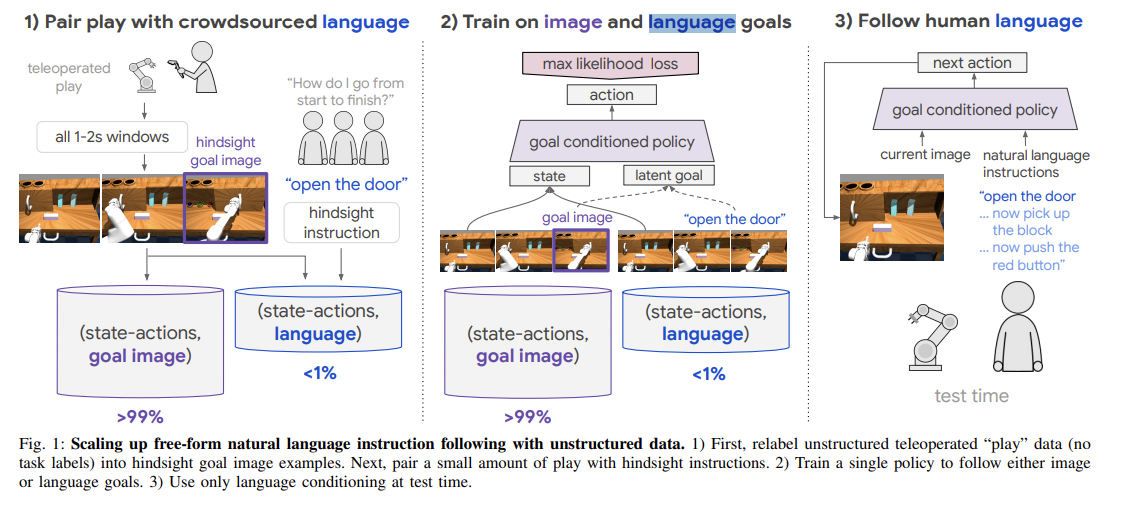
Abstract
2.Language Conditioned Imitation Learning over Unstructured Data

abstract
3.PaLM-E: An Embodied Multimodal Language Model
Abstact -
4.Learning Model Predictive Controllers with Real-Time Attention for Real-World Navigation
abstract
5.RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE
abstract
6.OFA(One For All)
https://github.com/OFA-Sys/OFAOFA는 통합된 시퀀스-시퀀스 사전 훈련 모델로, 영어와 중국어를 지원합니다. 이 모델은 다양한 modalities (교차 모달리티, 비전, 언어)와 tasks (finetuning and prompt tu
7.Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
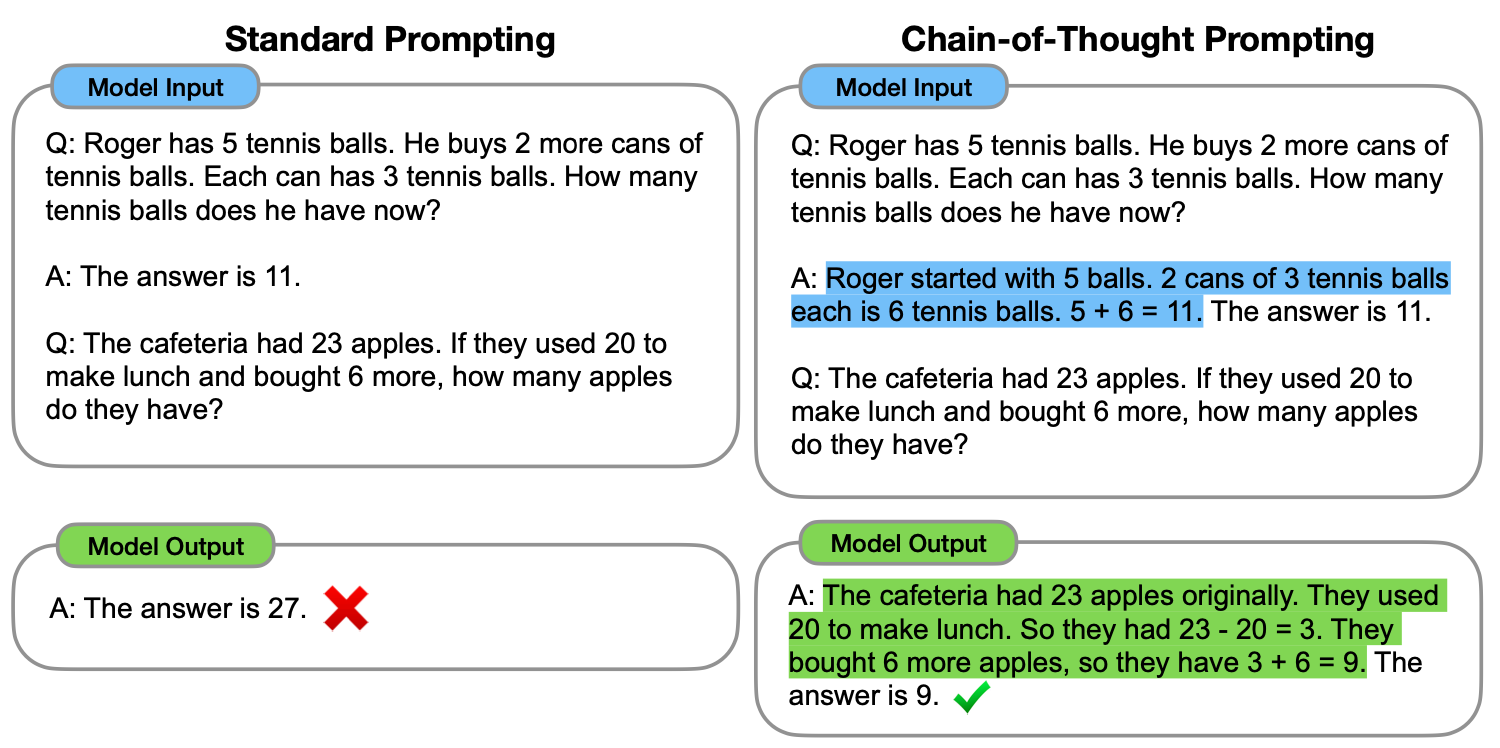
이 논문에서는, "중간 추론 단계의 연속인 -> 사고 과정 체인"을 생성하는 것이 대형 언어 모델이 복잡한 추론을 수행하는 능력을 크게 향상시키는 방법이 될 수 있다는 것을 탐구합니다.특히, 우리는 사고 과정 체인을 몇 가지 교시로 지시하는 간단한 방법인 체인-오브-사
8.Generative Agents: Interactive Simulacra of Human Behavior
이 논문은 컴퓨터 소프트웨어 에이전트를 사용하여 인간 행동을 모방하는 방법을 제안합니다.이 에이전트들은 인간과 같은 일상적인 행동을 수행하며, 예를 들어 일어나서 아침 식사를 하고 일하러 갑니다.또한 예술가나 작가처럼 창작 활동을 하며, 서로 의견을 나누고 대화를 합니
9.Instruction Tuning
이 기술은 모델이 주어진 지침을 정확히 이해하고, 원하는 출력 또는 행동을 생성하도록 튜닝하는 과정에서 사용data pair 예시<Instruction> 다음 질문에 대해 단계별로 추론하여 답변하세요. 식당에 사과가 23개 있었습니다. 점심 식사를 위해 20개를
10.Instruction Tuning - 보충 설명
"LM의 Objective와 사람의 Preference 사이의 Mismatch가 있음"이라는 말은 언어 모델(Language Model, LM)의 기본 학습 목표와 인간이 원하는 출력 사이에 불일치가 존재한다는 것을 의미합니다. 이것이 Instruction Tuning
11.RLHF : Reinforcement Learning with Human Feedback
RLHF는 강화 학습을 이용하여 인간의 피드백을 통해 언어 모델의 출력을 사람이 원하는 방식에 가깝도록 학습하는 과정먼저, 대규모 텍스트 데이터를 사용하여 초기 언어 모델을 사전 학습이 모델은 다양한 입력 프롬프트에 대한 응답을 생성할 수 있습니다.모델이 생성한 여러
12.[23,1][4635] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
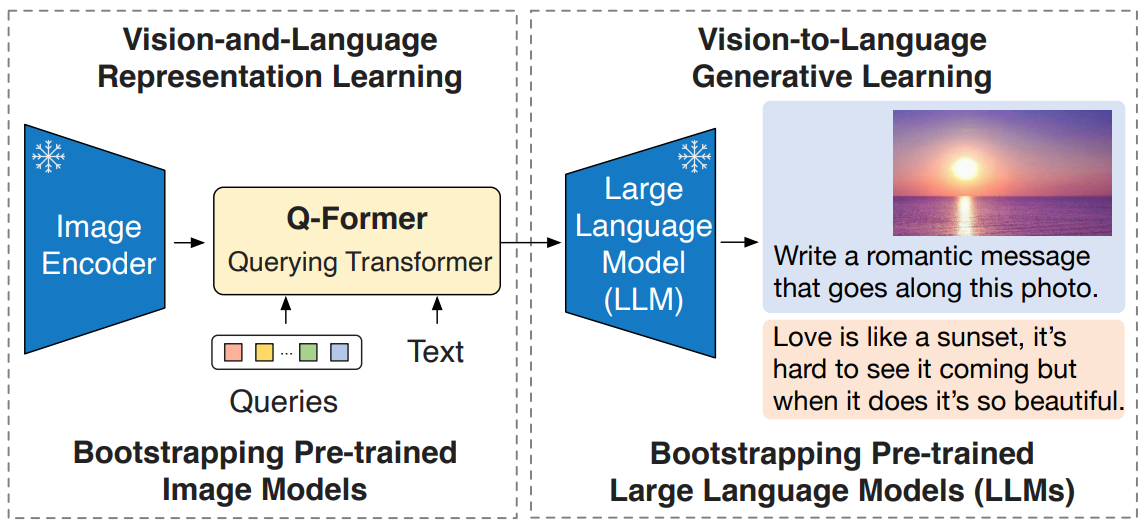
작성중
13.Qwen2.5 Technical Report
대용량 고품질 데이터와 정교한 후처리 기법(대규모 SFT 및 다단계 강화학습)을 통해 모델 성능을 크게 향상시킨 최신 LLM 시리즈 또한, Transformer 기반의 아키텍처와 Grouped Query Attention 같은 혁신적 기법을 도입하여, 입력 텍스트를 토
14.RLHF & DPO & GRPO
0. 표로 비교 | 기법 | 목적 | 동작 방식 | 장점 | 단점 | |:---|:---|:---|:---|:---| | RLHF (Reinforcement Learning from Human Feedback) | - 모델이 인간의 선호에 맞는 응답을 생성하도록 유도 | 1. 사람의 선호 데이터를 기반으로 보상 모델(reward model)을 먼저 학습2...